xtrabackup原理,整库,单表,部分备份恢复
物理备份xtrabackup原理
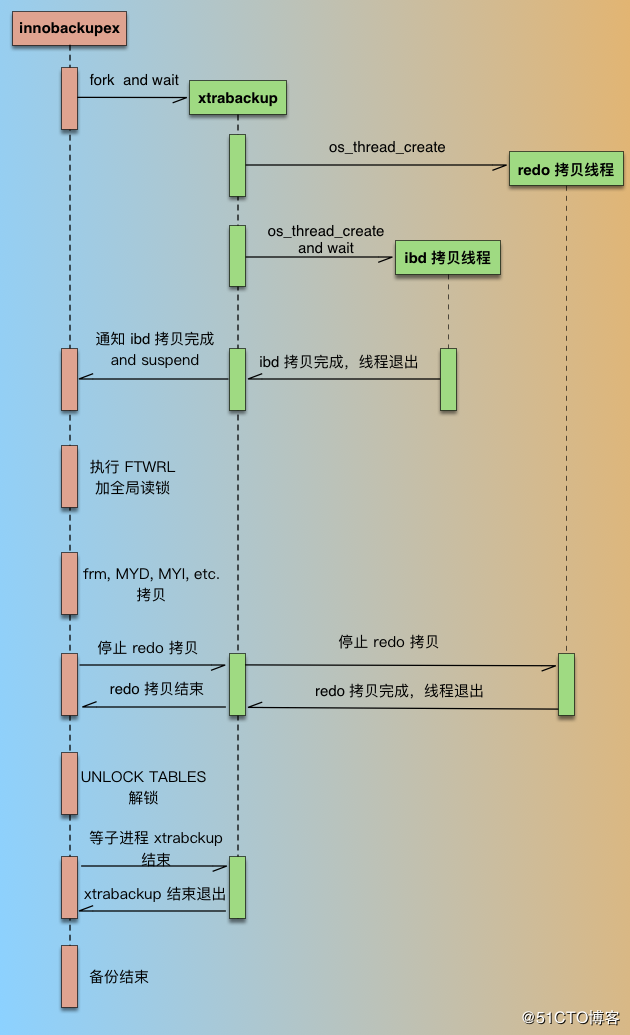
1.innobackupex在执行后会fork一个xtrabackup的进程,然后就等待xtrabackup的ibd数据文件。
2.xtrabackup在备份innoDB相关数据会启动俩个线程进行备份,一个是redo拷贝线程,负责拷贝redo文件在备份开始后新产生的数据文件。redo线程只有一个,在ibd拷贝线程之前启动,在ibd拷贝线程结束后结束。xtrabackup进程开始执行后,先启动redo拷贝线程,从最新的checkpoint点开始顺序拷贝redo日志;然后再启动ibd数据拷贝线程,在xtrabackup拷贝ibd过程中,innobackupex进程一直处于等待状态(等待文件被创建)。
3.xtrabackup拷贝完成ibd后,通知innobackupex(通过创建文件),同时自己进入等待(redo线程仍然进行拷贝);
4.innobackupex收到xtrabackup通知后,执行FLUSH TABLES WITH READ LOCK(FTWRL),去的一致性点位,开始拷贝非ibd文件可选copy或者rsync方式俩种,拷贝非 InnoDB 文件过程中,因为数据库处于全局只读状态,如果在业务的主库备份的话,要特别小心,非 InnoDB 表(主要是MyISAM)比较多的话整库只读时间就会比较长,这个影响一定要评估到。
5.当 innobackupex 拷贝完所有非 InnoDB 表文件后,通知 xtrabackup(通过删文件) ,同时自己进入等待(等待另一个文件被创建)
6.xtrabackup 收到 innobackupex 备份完非 InnoDB 通知后,就停止 redo 拷贝线程,然后通知 innobackupex redo log 拷贝完成(通过创建文件);
7.innobackupex 收到 redo 备份完成通知后,就开始解锁,执行 UNLOCK TABLES;
8.最后 innobackupex 和 xtrabackup 进程各自完成收尾工作,如资源的释放、写备份元数据信息等,innobackupex 等待 xtrabackup 子进程结束后退出。
简略的Xtrabackup流程
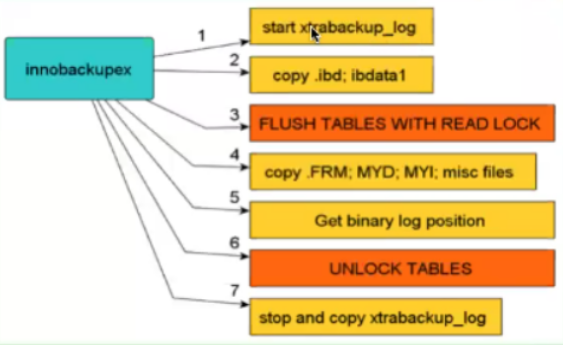
Xtrabackup实质上是利用了InnoDB Crash Recovery机制
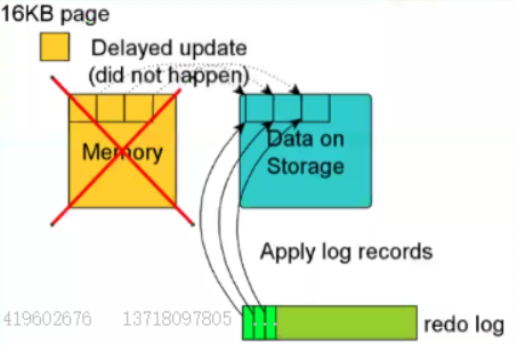
xtrabackup备份原理分析:
对于Innodb,它是基于Innodb的crash recovery功能进行备份。
就把变化过的 log pages 复制走。在全部数据文件复制完成之后,停止复制 logfile。
专注于InnoDB、XtraBackup的热备工具,是C语言开发的程序,专用于备份InnoDB及XtraDB引擎对象
备份集高效、完整、可用
备份任务执行过程中不会阻塞事务
节省磁盘空间,降低网络带宽占用
备份集自动验证机制
恢复更快
[root@mysql1 /]# rpm -ivh percona-xtrabackup-2.2.3-4982.el6.x86_64.rpm
MySQL5.7安装percona-xtrabackup
# rpm -ivh libev-4.15-1.el6.rf.x86_64.rpm
# rpm -ivh percona-xtrabackup-24-2.4.5-1.el6.x86_64.rpm
(system@localhost) [(none)]> create user xtrabk@'localhost' identified by 'onlybackup';
(system@localhost) [(none)]> grant reload,lock tables,process,Replication client,super on *.* to xtrabk@'localhost';
使用xtrabackup命令进行备份
xtrabackup命令有两种模式,--backup(备份模式)和--prepare(恢复准备模式)
--backup指定当前的操作模式,backup就是说要创建备份集
--target-dir指定备份集的存储路径
--defaults-file从MySQL的选项文件中读取参数
[mysql@mysql1 ~]$ xtrabackup --defaults-file=/data/mysqldata/3306/my.cnf --backup --target-dir=/data/mysqldata/backup/full_bak
[mysql@mysql1 ~]$ innobackupex --defaults-file=/data/mysqldata/3306/my.cnf --user=xtrabk --password='onlybackup' /data/mysqldata/backup/
创建增量备份:
[mysql@mysql2 ~]$ innobackupex --defaults-file=/data/mysqldata/3306/my.cnf --user=xtrabk --password='onlybackup' --incremental --incremental-basedir=/data/mysqldata/backup/2014-07-10_09-29-32 /data/mysqldata/backup_inc
--incremental:告诉xtrabackup这次是要创建增量备份
--incremental-basedir:指定一个全量备份的路径,作为增量备份的基础
--incremental-lsn:指定备份开始时的LSN
XtraBackup本质是基于InnoDB的故障恢复(crash-recovery)机制,先复制InnoDB的数据文件,复制的时候数据仍有可能正在读写,复制出的文件可能是不一致的状态,所以在备份过程中,需要定时扫描日志并作记录,而后通过备份的日志文件执行故障恢复,使文件恢复到一个一致的状态,使数据库达到可用状态。核心就是InnoDB维护的重做日志(redo log)。XtraBackup会在启动时先记录下当前的日志序列号(LSN),然后开始复制数据文件,同时XtraBackup运行一个后台进程,监控着事务日志,并复制新发生的修改。这项操作会在XtraBackup备份执行过程中一直执行,就是log scanned up to信息,以确保记录下所有备份期间数据库发生的修改。接下来是准备进程(prepare process),在这一步中,XtraBackup对复制的数据文件执行故障恢复,将数据库恢复到可用状态
准备恢复(prepare):就是为恢复做准备。备份集没有办法直接拿来用,所有需要一个对备份集做准备的过程
对于xtrabackup对应的参数是--prepare,对于innobackupex对应的参数是--apply-log
执行恢复(copy-back):备份集准备好以后,可以执行恢复了
对于xtrabackup没有特殊说明,简单cp/mv过程,对于innobackupex对应的参数是--copy-back,它的功能是将制定的备份集,恢复到指定的路径下
[mysql@mysql1 ~]$ innobackupex --defaults-file=/data/mysqldata/3306/my.cnf --apply-log --redo-only /data/mysqldata/backup/2014-07-08_16-24-07/
--apply-log从指定的选项文件中读取配置信息并应用日志等,表示要做的是对备份集做恢复的准备工作
--redo-only如果进行准备工作的备份集操作完成后,还有其他增量备份集待处理,那么就必须指定本参数
[mysql@mysql1 ~]$ innobackupex --defaults-file=/data/mysqldata/3306/my.cnf --apply-log /data/mysqldata/backup/2014-07-08_16-24-07/ --incremental-dir=/data/mysqldata/backup_inc/2014-07-08_16-29-44/
注意在备份集进行恢复的准备过程中,不要随意中断该任务,否则有可能导致备份集处于不一致状态。由于XtraBackup是直接在备份集中进行准备,一旦有异常,搞不好想恢复都没办法。建议操作之前,将备份集备份一次。
建议再执行一遍innobackupex --apply-log
[mysql@mysql1 ~]$ innobackupex --defaults-file=/data/mysqldata/3306/my.cnf --apply-log /data/mysqldata/backup/2014-07-08_16-24-07/
执行文件的恢复
[mysql@mysql1 ~]$ innobackupex --defaults-file=/data/mysqldata/3306/my.cnf --copy-back /data/mysqldata/backup/2014-07-08_16-24-07/
XtraBackup支持流(stream)模式,能够直接将备份输出到指定的格式进行处理,比如tar或xbstream
[mysql@mysql1 ~]$ innobackupex --defaults-file=/data/mysqldata/3306/my.cnf --user=xtrabk --password=onlybackup --stream=tar /tmp | gzip -> /data/mysqldata/backup/xtra_fullbackup.tar.gz
[mysql@mysql1 ~]$ more mysql_full_backup_by_xtra.sh
#!/bin/bash
#create by allen
source /data/mysqldata/scripts/mysql_env.ini
DATA_PATH=/data/mysqldata/backup/mysql_full
DATA_FILE=${DATA_PATH}/xtra_fullbak_`date +%F`.tar.gz
LOG_FILE=${DATA_PATH}/xtra_fullbak_`date +%F`.log
ORI_CONF_FILE=/data/mysqldata/3306/my.cnf
NEW_CONF_FILE=${DATA_PATH}/my_3306_`date +%F`.cnf
MYSQL_PATH=/usr/bin
MYSQL_CMD="${MYSQL_PATH}/innobackupex --defaults-file=${ORI_CONF_FILE} --user=xtrabk --password=onlybackup --stream=tar /tmp"
echo > ${LOG_FILE}
echo -e "=== Jobs started at `date +%F' '%T' '%w` ===\n" >> ${LOG_FILE}
echo -e "=== First cp my.cnf file to backup directory ===" >> ${LOG_FILE}
/bin/cp ${ORI_CONF_FILE} ${NEW_CONF_FILE}
echo > ${LOG_FILE}
echo -e "*** Executed command:${MYSQL_CMD} | gzip > ${DATA_FILE}" >> ${LOG_FILE}
${MYSQL_CMD} | gzip > ${DATA_FILE}
echo -e "*** Executed finished at `date +%F' '%T' '%w` ===" >> ${LOG_FILE}
echo -e "*** Backup file size:`du -sh ${DATA_FILE}` ===\n" >> ${LOG_FILE}
echo -e "--- Find expired backup and delete those files ---" >> ${LOG_FILE}
for tfile in $(/usr/bin/find $DATA_PATH -mtime +6)
do
if [ -d $tfile ] ; then
rmdir $tfile
elif [ -f $tfile ] ; then
rm -f $tfile
fi
echo -e "--- Delete file:$tfile ---" >> ${LOG_FILE}
done
echo -e "\n=== Jobs ended at `date +%F' '%T' '%w` ===\n" >> ${LOG_FILE}
参数值为0到6
每次加1进行恢复测试
使用xtrabackup注意事项
设置一个超时时间,避免无限期的等待。Xtrabackup提供了以下参数实现该功能:
--lock-wait-timeout=SECONDS, ,一旦Flush table with read lock被阻塞超过预定时间,则XtraBackup出错返回退出,该值默认为0,也就是说一旦阻塞,立即返回失败。
--lock-wait-query-type=all|update,该参数允许用户指定,哪类的SQL语句是需要Flush table with read lock等待的,同时用户可以通过--lock-wait-threshold=SECONDS设置等待的时间,如果不在query-type指定的类型范围内或者超过了wait-threshold指定的时间,XtraBackup均返回错误。如果指定update类型,则UPDATE/ALTER/REPLACE/INSERT 均会等待,ALL表示所有的SQL语句。
kill 其他阻塞线程
Kill掉所有阻塞Flush table with read lock的线程:
--kill-long-queries-timeout=SECONDS参数允许用户指定了超过该阈值时间的查询会被Kill,同时也允许用户指定Kill
SQL语句的类型。
--kill-long-query-type=all|select
默认值为ALL,如果选择Select,只有Select语句会被Kill,如果Flush table with read lock是被Update语句阻塞,则XtraBackup不会处理。
创建部分备份(Creating Partial Backups)
部分备份共有三种方式,分别是:
1. 用正则表达式表示要备份的库名及表名(参数为--include)
2. 将要备份的表名或库名都写在一个文本文件中(参数为--tables-file)
3. 将要备份表名或库名完整的写在命令行中(参数为:--databases)。
(译者注:不管你备份哪个库或是哪张表,强烈推荐把mysql库也一起备份,恢复的时候要用。)
使用正则模式匹配备份部分库表,需要使用参数--include
innobackupex --include='test.test*' /backup --user=root --password=msds007
cat /tmp/tables.txt
test.t
test.testflashback2
innobackupex --tables-file=/tmp/tables.txt /backup --user=root --password=msds007
innobackupex --databases=test,mysql /backup --user=root --password=msds007
执行preparing partial backups,与恢复独立的表(Restoring Individual Tables)很类似:使用--apply-log和--export参数,并包含上一步生成的时间戳文件夹
innobackupex --apply-log --export /backup/2018-05-10_19-38-44
1)查看备份集中的文件
[root@mydb1 test]# pwd
/backup/2018-05-10_19-38-44/test
[root@mydb1 test]# ll
total 256
-rw-r--r--. 1 root root 390 May 10 19:58 t.cfg
-rw-r--r--. 1 root root 1087 May 10 19:58 testflashback2.cfg
-rw-r--r--. 1 root root 16384 May 10 19:58 testflashback2.exp
-rw-r-----. 1 root root 9030 May 10 19:38 testflashback2.frm
-rw-r-----. 1 root root 98304 May 10 19:38 testflashback2.ibd
-rw-r--r--. 1 root root 16384 May 10 19:58 t.exp
-rw-r-----. 1 root root 8586 May 10 19:38 t.frm
-rw-r-----. 1 root root 98304 May 10 19:38 t.ibd
# mysqlfrm --diagnostic t.frm
# WARNING: Cannot generate character set or collation names without the --server option.
# CAUTION: The diagnostic mode is a best-effort parse of the .frm file. As such, it may not identify all of the components of the table correctly. This is especially true for damaged files. It will also not read the default values for the columns and the resulting statement may not be syntactically correct.
# Reading .frm file for t.frm:
# The .frm file is a TABLE.
# CREATE TABLE Statement:
--server=dba_user:msds007@192.168.1.101 远端服务器,要读取的数据字典
/app/mysqldata/3306/data/test/tt.frm frm源文件放置的本地位置
--user=root --port=2323 Starting the spawned server on port 2323
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY `PRIMARY` (`id`)
) ENGINE=InnoDB;
ALTER TABLE test.t DISCARD TABLESPACE;
After this, copy t.ibd and t.exp ( or t.cfg if importing to MySQL 5.6) files to database’s home, and import its tablespace:
chown mysql:mysql t.ibd t.exp t.cfg
ALTER TABLE test.t IMPORT TABLESPACE;
xtrabackup原理,整库,单表,部分备份恢复的更多相关文章
- Python学习day44-数据库(单表及多表查询)
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- ORACLE表空间offline谈起,表空间备份恢复
从ORACLE表空间offline谈起,表空间备份恢复将表空间置为offline,可能的原因包括维护.备份恢复等目的:表空间处于offline状态,那么Oracle不会允许任何对该表空间中对象的SQL ...
- Innodb单表数据物理恢复
本文将介绍使用物理备份恢复Innodb单表数据的方法 前言: 随着innodb的普及,innobackup也成为了主流备份方式.物理备份对于新建slave,全库恢复的需求都能从容应对. 但当面临单表数 ...
- java对mysql数据库进行单表筛选备份、还原操作
最近在做的一个项目需要对mysql数据库中的单个表格进行备份 其中,一部分表格需要进行筛选备份(例如对最近插入的1000条记录进行备份) 思路:java调用系统命令完成备份操作 假设现在有数据库tes ...
- mysql 主从单库单表同步 binlog-do-db replicate-do-db
方案一:两边做主从. SELECT SUM(DATA_LENGTH)+SUM(INDEX_LENGTH) FROM information_schema.tables WHERE TABLE_SCHE ...
- mysql查看整库个表详情
information_schema.tables字段说明 字段 含义 Table_catalog 数据表登记目录 Table_schema 数据表所属的数据库名 Table_name 表名称 Tab ...
- mysql 单表批量备份sh文件
#!/bin/bashDBS=$(mysql -u root -padmin -e 'use database; show tables;' | awk '{ print $1 }');for tab ...
- [转]数据库中间件 MyCAT源码分析——跨库两表Join
1. 概述 2. 主流程 3. ShareJoin 3.1 JoinParser 3.2 ShareJoin.processSQL(...) 3.3 BatchSQLJob 3.4 ShareDBJo ...
- 如何用Percona XtraBackup进行MySQL从库的单表备份和恢复【转】
前提 应该确定采用的是单表一个表空间,否则不支持单表的备份与恢复. 在配置文件里边的mysqld段加上 innodb_file_per_table = 1 环境说明: 主库:192.168.0.1 从 ...
随机推荐
- Linux设备驱动程序 之 工作队列
工作队列可以把工作推后,交给一个内核线程去执行–这个下半部分总是会在进程上下文中执行:通过工作队列执行的代码占尽进程上下文的优势:最重要的是工作队列允许重新调度甚至睡眠: 在工作队列和软中断/task ...
- mongoose 安装及配置
MongoDB是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方>案.MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据 ...
- Hype-v创建服务器实例
1.创建虚拟交换机,如下图所示(虚拟交换机,只需要创建一次,后面增加服务器实例的时候,只需要选择这个虚拟交换机就可以了,不用每次都创建) 2.服务器主网络共享给虚拟交换机,如下图所 3.虚拟交换机的I ...
- Jquery.Data()和HTML标签的data-*属性
Jquery.Data()和HTML标签的data-*属性 一.总结 一句话总结: 在页面中用到要用标签存数据还是用HTML标签的data-*属性,这样 不会破坏html本身的结构 1.使用HTML标 ...
- PHP魔术方法和魔法变量详解
一.魔术常量 __LINE__ 文件中的当前行号.__FILE__ 文件的完整路径和文件名.如果用在被包含文件中,则返回被包含的文件名. 自 PHP 4.0.2 起,__FILE__ 总是包含一个绝对 ...
- [转][echarts]地图轮播
代码片断: 来自:https://blog.csdn.net/qq_36947128/article/details/90899564 function Play(){ chart.dispatchA ...
- linux下如何交叉编译util-linux?
1. 获取源码 wget https://mirrors.edge.kernel.org/pub/linux/utils/util-linux/v2.34/util-linux-2.34.tar.xz ...
- 如何用CSS3来实现卡片的翻转特效
CSS3实现翻转(Flip)效果 动画效果 效果分析 当鼠标滑过包含块时,元素整体翻转180度,以实现“正”“反”面的切换. HTML分析 分析:.container,.flip为了实现动画效果做准备 ...
- ubuntu18 bluebooth
QDBusPendingReply: type ManagedObjectList is not registered with QtDBus 19:36:14: The program has un ...
- MySQL表的创建与维护
一.导入测试数据 [root@server ~]# wget https://launchpadlibrarian.net/24493586/employees_db-full-1.0.6.tar.b ...