作业3:java对象模型
一 对象表示机制
1 Hotsplot JVM内部对象表示系统
(1)OOP-Klass二分模型
- OOP:Ordinary Object Pointer 或者OOPS。即普通对象指针,描述对象实例信息。
- 职能:表示对象的实例数据,没必要持有任何虚函数(java的重写方法的实现)。
- Klass:Java类的C++对等体,用来描述
- 职能:Klass对象中有VTBL(继承自Klass父类 Klass_ktbl),Klass能根据java对象的实际类型进行C++分发,即OOPS对象只需要通过Klass就能找到所有的虚函数。
(2)Klass向JVM提供两个功能
- 实现语言层面的Java类,Klass_ktbl中实现
- 实现Java对象的分发功能(注意:虚函数是C++实现多态的工具,在运行时根据虚表决定调用合适的函数。这被称作动态分发。java的运行时多态的实现。),Klass子类提供的虚函数实现。
2 Oops模块:OOP框架和Klass框架
(1)Oops模块示意图
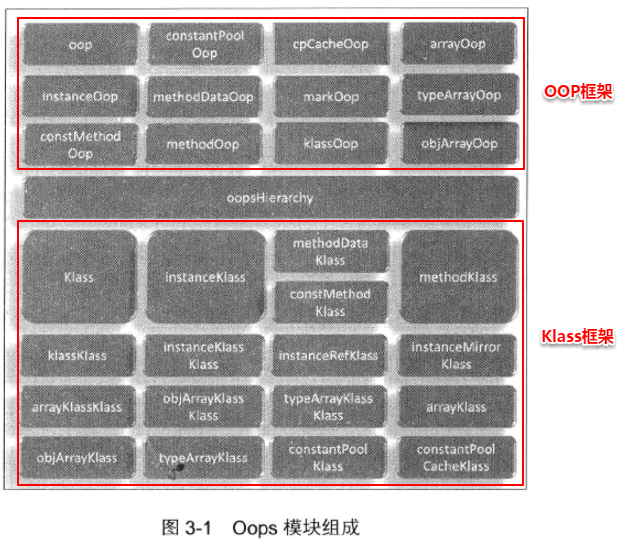
(2)OOP框架框架类层次

3 OOP框架以及对象访问机制
(1)OOP框架类的基类
class oopDesc{
private:
volatile markOop _mark;
union _metadata{
wideKlassOop _klass; // 32位
narrowOop _compressed_klass; // 开启-XX:UseCompressedOops才选用,32位指针
} _metadata; //元数据指针
}
(2)instacneOopDecs或arrayOopDesc又称为对象头,instacneOopDecs对象头包含
- Mark Word:_mark成员



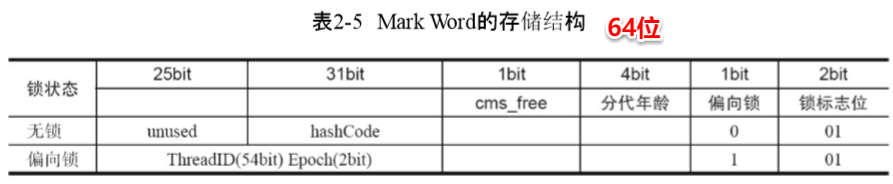
注:互斥量就是Monitor。
参考:《Java并发编程的艺术》 第二章节
- 元数据指针:指向描述类型的Klass对象的指针,Klass对象又包含了实例对象所属类型的元数据。
(3)OOPS对象优化措施:C++内联函数!
普通函数调用原理:执行到函数调用指令时,程序将在函数调用后立即存储该指令的内存地址,并将函数参数复制到堆栈(为此保留的内存块),跳到标记函数起点的内存单元,执行函数代码(也许还需将返回值放入寄存器中),然后跳回到地址被保存的指令。
简言之,普通函数调用需要保护现场(main函数运行到第几行指令进栈)-> 调用函数(复制main函数中的参数副本) -> 恢复现场(出栈返回结果至main函数的第几行指令)。这是存在系统资源开销的,如何将调用函数的代码直接嵌入到主函数就没了这个开销。(参考:https://blog.csdn.net/buptzhengchaojie/article/details/50568789)
内联函数:短小精炼的代码,在编译阶段将函数体嵌入到每一个调用该函数的语句块中,最大程度降低调用开销。
OopDesc中的部分内联函数
// 初始化mark word
inline void oopDesc::init_mark()
// 是否是类实例
omit ...
// 是否是数组
omit ...
// 原子操作设置mark word
inline markOop oopDesc::cas_set_mark(markOop new_mark,markOop old_mard){
// cmpxchg加Lock前缀能够在多核下锁住总线,使得只有单个CPU操作共享内存中的变量.
return (markOop) Atomic::cmpxchg_ptr(new_mark,&_mark,old_mark)
}
// 获取对象对应的类型klass
inline klassOop oopDesc::klass() const{
if(UseCompressedOops){
return (klassOop)decode_heap_oop_not_null(metadata.compressed_klass);
}else{
return metadata.klass;
}
}
参考1:https://www.jianshu.com/p/8c3c0426e4f7
参考2:http://www.lenky.info/archives/2012/11/2028
(4)对象访问定位

4 Klass和instanceKlass
(1)Klass类层次结构
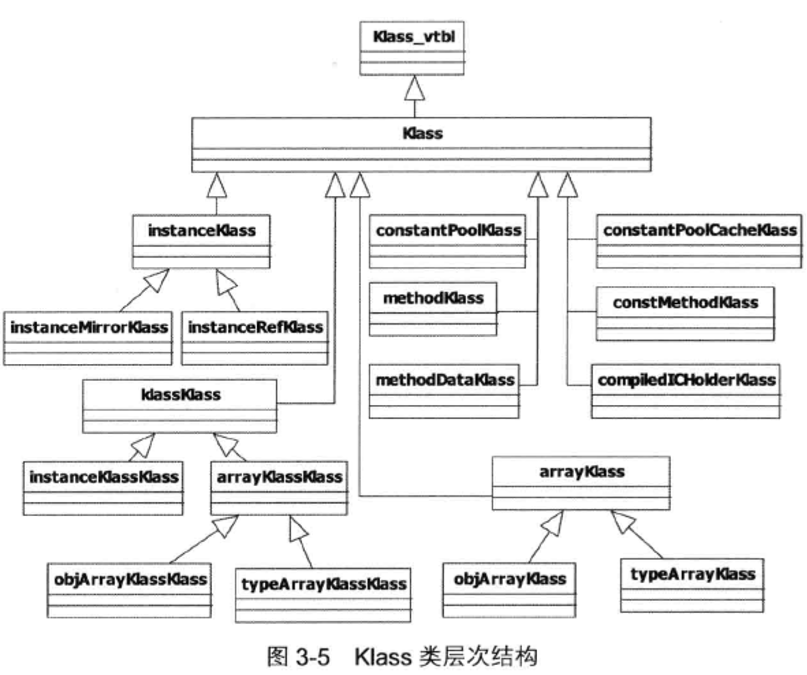
(2)核心数据结构:Klass

对于instance而言,_layout_helper值为正,代表instance的大小
对于数组Klass,_layout_helper值为负,如下图所示:

(3)核心数据结构:instanceKlass
HotSpot 为每一个加载的Java类创建一个instanceKlass对象,用于在JVM层表示Java类。
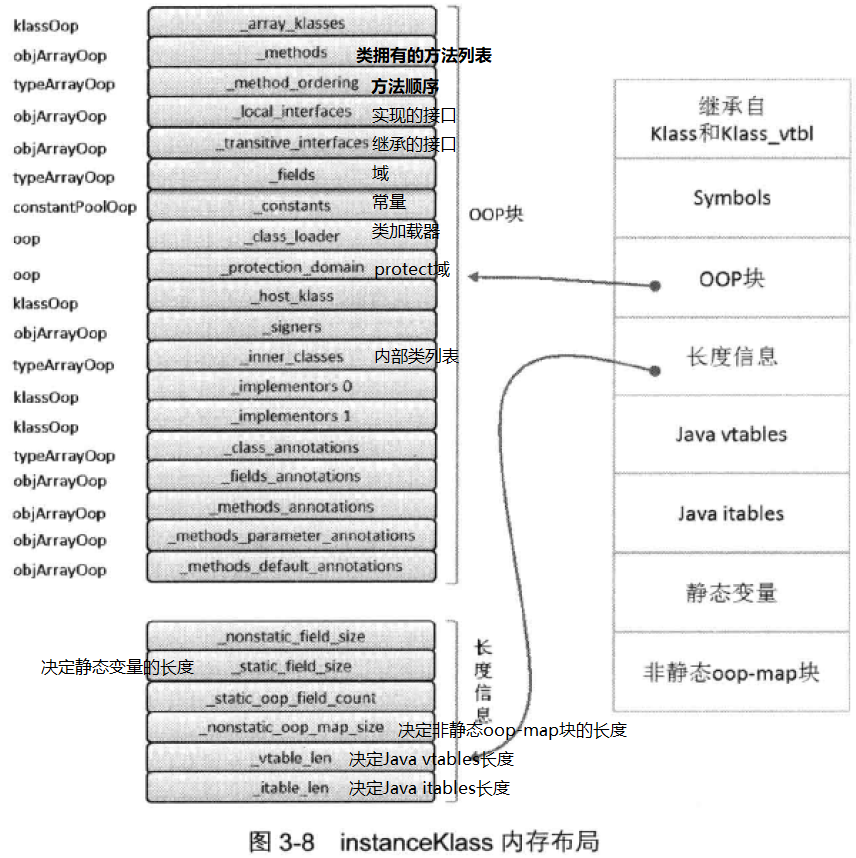
(4)实例数据的存储顺序
默认为longs/doubles、ints、shorts/chars、bytes/booleans、OOPS的顺序分配。
相同宽度的字段总是分配在一起
父类中定义的变量可能出现在子类之前
5 使用HSDB调试HotSpot
(1)如何启动HSDB
jdk目录下输入:java -cp ./lib/sa-jdi.jar sun.jvm.hotspot.HSDB
注:如果遇到sawindbg.dll不存在,参考该地址解决:https://blog.csdn.net/fl_zxf/article/details/42689569
(2)HSDB工具

(3)CLHSDB命令行

二 类的状态转换
1 Class文件
jvm规范(JavaSE 10):https://docs.oracle.com/javase/specs/jvms/se10/jvms10.pdf
ClassFile {
u4 magic; // value 常数: 0xCAFEBABE
u2 minor_version;
u2 major_version; // java8为例 45.0<=version<=52.0
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags; // 访问标识,如public final abstract super interface 等
u2 this_class; // 当前类:记录一个有效的常量池下标
u2 super_class; // 超类,同上
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
(1)常量池
// 常量池项
cp_info{
u1 tag; // 不同的值代表不同的类型,参照下图
u1 info[];
}
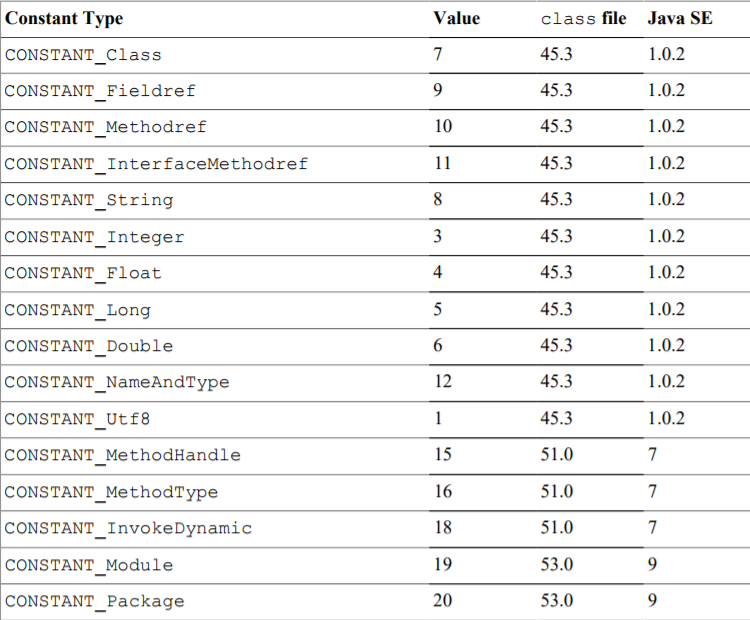
(2)字段表
field_info{
u2 access_flags;
u2 name_index; // 常量池索引,该字段的全限定名
u2 descriptor_index; // 常量池索引,字段的描述符
u2 attributes_count; // 字段附加属性数量
attribute_info attributes[attributes_count];
}

(3)方法表
method_info{
u2 access_flags; // 与字段表类似,具体参考jvm规范手册
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
(4)属性表
- 类文件、字段和方法都能有属性列表,用于标识它们的一些属性,如:表示内部类、表示过期的、表示运行时注解可见等。其中ConstantValue表示常量,常量的类型由ConstantValue中constantvalue_index指向的类型表示。
attribute_info{
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length]; // 属性
}
2 JVM内部定义的类状态
- unparsable_by_gc:初始值,未解析
- allocated:已分配,未链接
- loaded:已加载,并插入到JVM内部类的层次体系(class hierarchy)
- linked:已连接,未初始化
- being_initialized:正在初始化
- fully_initialized:完成初始化
- initialization_error:初始化过程中出错
3 类加载、连接和初始化过程
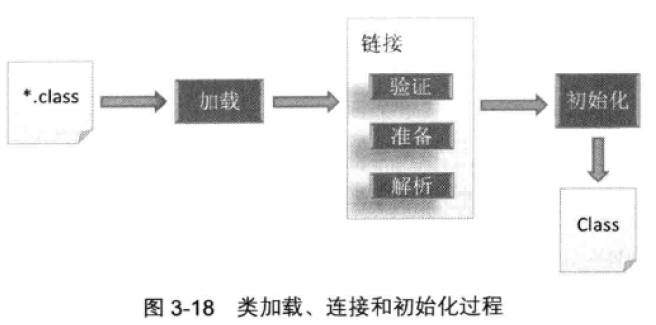
- 加载:从*.class读取字节流,并根据JVM规范解析处类或接口类型的二进制描述格式,并创建相应的类或接口
- 链接:JVM运行时识别有效的类或接口的过程
- 验证:确保类或接口的二进制表示结构的
- 准备:为静态字段分配空间,并初始化这些字段
- 解析:将符号引用转化为直接引用的过程
- 初始化:执行类或接口初始化方法的过程
注:visualvm能进行性能统计:类加载时间等
4 加载
(1)初始化类加载器
- 初始化一些Perf Data计数器()
- 搜索lib库:libverify、libjava和ibzip库
- sun.boot.class.path表示的路径下初始化启动类加载路径 日志输出=> Bootstrap loader class path
- 如果VM选项LazyBootClassLoader,则需要设置meta,日志输出 => Meta index for
调试参数:-XX:TraceClassLoading -XX:TraceClassLoadingPreorder
(2)加载(Classfile模块):从Class文件字节流中提取类型信息。
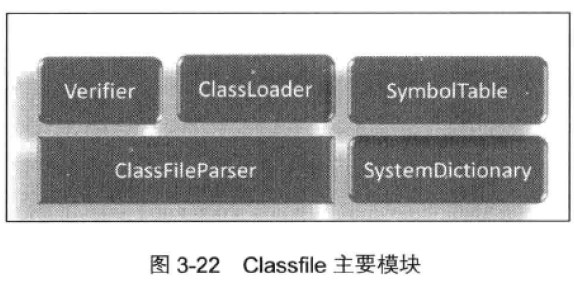
- ClassFileParser:类解析器,解析.class文件,利用ClassFileStream读取.class文件作为输入流,作为ClassFileParser输入
- Verifier:验证器,验证*.class文件中的字节码。每个类都需要创建一个ClassVerifier来验证
- ClassLoader:类加载器
- SystemDictionary:系统字典,记录已加载的类(类、类加载器、公共类klass)
- SymboleTable:字符表,用于快速查找字符串
- 下图为类加载流程图:
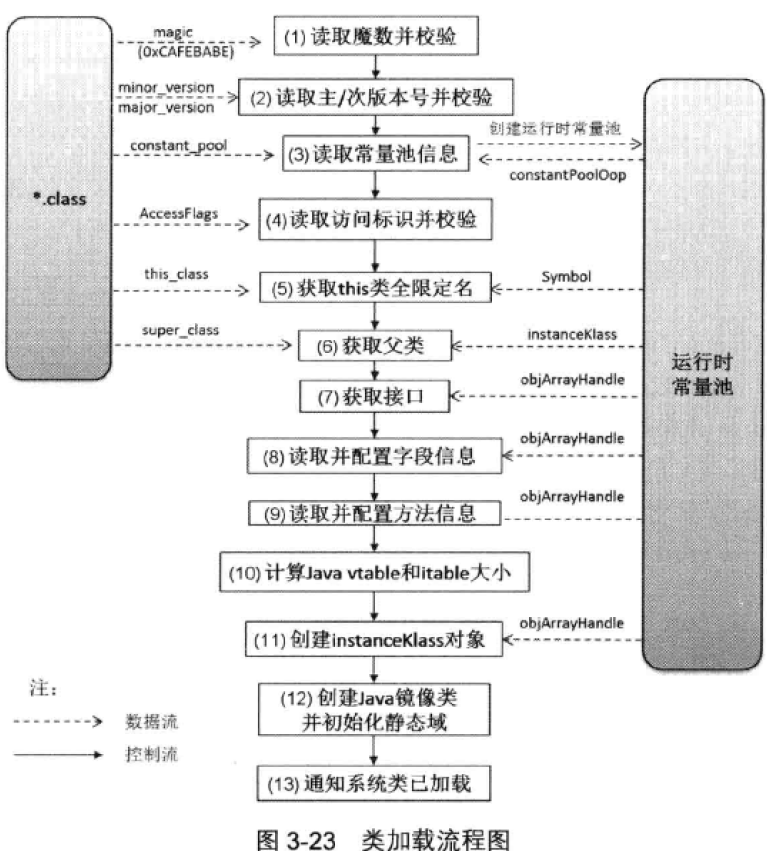
5 链接
Class文件中有个静态常量池,加载成功后,静态常量池中的符号引用转化为直接引用并对接运行时常量池的过程称为解析。当符号引用首次被访问时才去解析(Hotspot,不同JVM有不同实现)。
下图是instanceKlass类中定义了链接过程link_class_impl(),主要步骤如下:

(1) 验证:确保类或接口的二进制信息有效,主要验证method。
- 方法的访问控制
- 参数和静态变量
- 变量是否初始化
- 变量类型检查
- 验证局部变量表
- 堆栈是否被滥用
(2) 准备:分配内存空间并准备好初始化类中的静态变量
- char类型默认为'\u0000'
- byte默认为(byte)0
- boolean默认为0
- float默认为0.0f
- double默认为0.0d
- long默认为0L
(3) 解析:将常量池中的符号引用转换为直接引用,包括类、接口、字段和类方法和接口方法。
最重要的方法解析:
- 方法字节码重写是为了解释器运行性能,向常量池添加缓存(constantPoolCache),并调整相应的字节码的常量池索引重新指向常量池Cache索引。
- 重定位和方法链接:为Java的每个方法配置编译器和解释器的内部入口。
6 初始化:执行初始化方法
(1)触发类初始化的几种情况
- JVM需要引用类或接口的指令时:new getstatic putstatic invokestatic
- 调用java.lang.invoke.MethodHandle实例时,返回结果为REF_getStatic REF_putStatic REF_invokeStatic
- 调用类库中的反射方法时,如Class类或java.lang.reflect包
- 初始化类的子类时
- 类是JVM启动时的初始类
(2)(instanceKlass)类初始化

三 类的创建
1 概述
字节码new表示创建对象,JVM遇到这个指令,从栈顶取得目标对象在常量池中的索引,接着定位目标对象的类型,根据JVM中该类的状态,采取相应的内存分配技术(根据类是否已经初始化),在内存中分配实例空间,并完成实例数据和对象头的初始化。
2 实例化流程
- 快速分配:栈上分配
- 慢速分配:堆上分配

作业3:java对象模型的更多相关文章
- 【JVM】JVM内存结构 VS Java内存模型 VS Java对象模型
原文:JVM内存结构 VS Java内存模型 VS Java对象模型 Java作为一种面向对象的,跨平台语言,其对象.内存等一直是比较难的知识点.而且很多概念的名称看起来又那么相似,很多人会傻傻分不清 ...
- 【转】JVM内存结构 VS Java内存模型 VS Java对象模型
JVM内存结构 我们都知道,Java代码是要运行在虚拟机上的,而虚拟机在执行Java程序的过程中会把所管理的内存划分为若干个不同的数据区域,这些区域都有各自的用途. 其中有些区域随着虚拟机进程的启动而 ...
- java内存结构JVM——java内存模型JMM——java对象模型JOM
JVM内存结构 Java代码是要运行在虚拟机上的,而虚拟机在执行Java程序的过程中会把所管理的内存划分为若干个不同的数据区域,这些区域都有各自的用途.其中有些区域随着虚拟机进程的启动而存在,而有些区 ...
- java对象模型
java对象模型其实就是JVM中对象的内存布局.一个对象本身内在结构的描述信息以字节码的方式存储在方法区中(参见java内存区域),说白了就是class文件.那么如何获取到对象的class信息呢?虚拟 ...
- JVM(八):Java 对象模型
JVM(八):Java 对象模型 本文将学习对象是如何创建的,对象的内存布局,以及如何定位访问一个对象. 对象创建 当虚拟机碰到一个new指令时,首先检查指令参数能否在常量池中定位一个类的符号引用,并 ...
- JVM内存结构 VS Java内存模型 VS Java对象模型
前面几篇文章中, 系统的学习了下JVM内存结构.Java内存模型.Java对象模型, 但是发现自己还是对这三者的概念和区别比较模糊, 傻傻分不清楚.所以就有了这篇文章, 本文主要是对这三个技术点再做一 ...
- 区分 JVM 内存结构、 Java 内存模型 以及 Java 对象模型 三个概念
本文由 简悦 SimpRead 转码, 原文地址 https://www.toutiao.com/i6732361325244056072/ 作者:Hollis 来源:公众号Hollis Java 作 ...
- Java内存模型、JVM内存结构和Java对象模型
JVM内存结构 我们都知道,Java代码是要运行在虚拟机上的,而虚拟机在执行Java程序的过程中会把所管理的内存划分为若干个不同的数据区域,这些区域都有各自的用途.其中有些区域随着虚拟机进程的启动而存 ...
- JVM内存结构、Java内存模型和Java对象模型
Java作为一种面向对象的,跨平台语言,其对象.内存等一直是比较难的知识点.而且很多概念的名称看起来又那么相似,很多人会傻傻分不清楚.比如本文要讨论的JVM内存结构.Java内存模型和Java对象模型 ...
- [转帖]JVM内存结构 VS Java内存模型 VS Java对象模型
JVM内存结构 VS Java内存模型 VS Java对象模型 https://www.hollischuang.com/archives/2509 Java作为一种面向对象的,跨平台语言,其对象.内 ...
随机推荐
- Oracle JDBC 连接池
1.简介 数据库连接池负责分配.管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个:释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据 ...
- tp5 回滚事务记录,其中一条语句报错,全部回滚
#################################### 测试事务 // 启动事务 Db::startTrans(); try { //插入行为表 $data = [ 'userId' ...
- H5本地存储详解
H5之前存储数据一般是通过 cookie ,但是 cookie 存的数据容量比较少.H5 中扩充了文件存储能力,可存储多达 5MB 的数据.现在就实际开发经验来对本地存储 ( Storage ) 的使 ...
- 19 Flutter仿京东商城项目 商品详情 底部浮动导航布局 商品页面布局
效果: widget/JdButton.dart import 'package:flutter/material.dart'; import '../services/ScreenAdaper.da ...
- jemter 90%line的解释
假如: 有10个数: 1.2.3.4.5.6.7.8.9.10 按由大到小将其排列. 求它的第90%百分位,也就是第9个数刚好是9 ,那么他的90%Line 就是9 . 另一组数: 2.2.1. ...
- List 的删除
List 不要在循环中使用remove 删除.可以新加一个List ,把符合条件的元素加入到这个list 中,然后调用removeAll . 比如:(增强for 循环需要判断 list 是否是 nul ...
- Python描述性统计numpy
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets, ...
- protobuf / Consul / 边缘计算 / MEC / CDN / Serverless / GraphQL / 微服务 / 网关 / 云原生 / Serverless (真能造概念啊!!!)
技术概念层出不穷,学吧!记录下自己多这些概念的理解 protobuf: 数据结构而已,类比XML, JSON consul 解决的只是微服务里的服务注册与发现,健康检查等. 边缘计算:可以理解为是指利 ...
- 【UE】常用的UltraEdit使用技巧
Tip 1: Alt+C 列模式可以说最初选择使用这个文本编辑软件,原因很简单,就是因为“她”具有列编辑模式.如果您还不知道什么是列编辑模式的话,我想您应该好好研究一下啦.这是一个超级“赞”的功能.在 ...
- MLE & MAP
MLE & MAP : data / model parameter MLE: (1) keep the data fixed(i.e., it has been observed) and ...