R语言与概率统计(三) 多元统计分析(上)


> #############6.2一元线性回归分析
> x<-c(0.10,0.11,0.12,0.13,0.14,0.15,0.16,0.17,0.18,0.20,0.21,0.23)
> y<-c(42.0,43.5,45.0,45.5,45.0,47.5,49.0,53.0,50.0,55.0,55.0,60.0)
> plot(x~y)
> lm.sol<-lm(y ~ x)
> summary(lm.sol) Call:
lm(formula = y ~ x) Residuals:
Min 1Q Median 3Q Max
-2.0431 -0.7056 0.1694 0.6633 2.2653 Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 28.493 1.580 18.04 5.88e-09 ***
x 130.835 9.683 13.51 9.50e-08 *** #所以y=130.835x+28.493,***表示显著性水平,*越多越好
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 #显著性水平 Residual standard error: 1.319 on 10 degrees of freedom
Multiple R-squared: 0.9481, Adjusted R-squared: 0.9429
F-statistic: 182.6 on 1 and 10 DF, p-value: 9.505e-08 ¥F检验,检验所有系数全是0的假设
> new=data.frame(x=0.16)#怎么预测多个数值的结果?
> lm.pred=predict(lm.sol,new,interval='prediction',level=0.95)
> lm.pred
fit lwr upr
1 49.42639 46.36621 52.48657


先求对数,再*100
> X<-matrix(c(
+ 194.5, 20.79, 1.3179, 131.79,
+ 194.3, 20.79, 1.3179, 131.79,
+ 197.9, 22.40, 1.3502, 135.02,
+ 198.4, 22.67, 1.3555, 135.55,
+ 199.4, 23.15, 1.3646, 136.46,
+ 199.9, 23.35, 1.3683, 136.83,
+ 200.9, 23.89, 1.3782, 137.82,
+ 201.1, 23.99, 1.3800, 138.00,
+ 201.4, 24.02, 1.3806, 138.06,
+ 201.3, 24.01, 1.3805, 138.05,
+ 203.6, 25.14, 1.4004, 140.04,
+ 204.6, 26.57, 1.4244, 142.44,
+ 209.5, 28.49, 1.4547, 145.47,
+ 208.6, 27.76, 1.4434, 144.34,
+ 210.7, 29.04, 1.4630, 146.30,
+ 211.9, 29.88, 1.4754, 147.54,
+ 212.2, 30.06, 1.4780, 147.80),
+ ncol=4, byrow=T,
+ dimnames = list(1:17, c("F", "h", "log", "log100")))#如何改变行和列的名称,如何按列排列数据?
>
> forbes<-data.frame(X)#把矩阵X转化为数据框
> plot(forbes$F, forbes$log100)#画出两个变量之间的散点图,观察是否存在线性趋势;学习
> #如何从数据框里面调取向量。怎么写坐标轴的名字和标题?
> #如何从数据框里面调取向量。怎么写坐标轴的名字和标题?
> lm.sol<-lm(log100~F, data=forbes)
> summary(lm.sol) Call:
lm(formula = log100 ~ F, data = forbes) Residuals:
Min 1Q Median 3Q Max
-0.32261 -0.14530 -0.06750 0.02111 1.35924 Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -42.13087 3.33895 -12.62 2.17e-09 ***
F 0.89546 0.01645 54.45 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 0.3789 on 15 degrees of freedom
Multiple R-squared: 0.995, Adjusted R-squared: 0.9946
F-statistic: 2965 on 1 and 15 DF, p-value: < 2.2e-16 > abline(lm.sol)#在散点图上添加直线
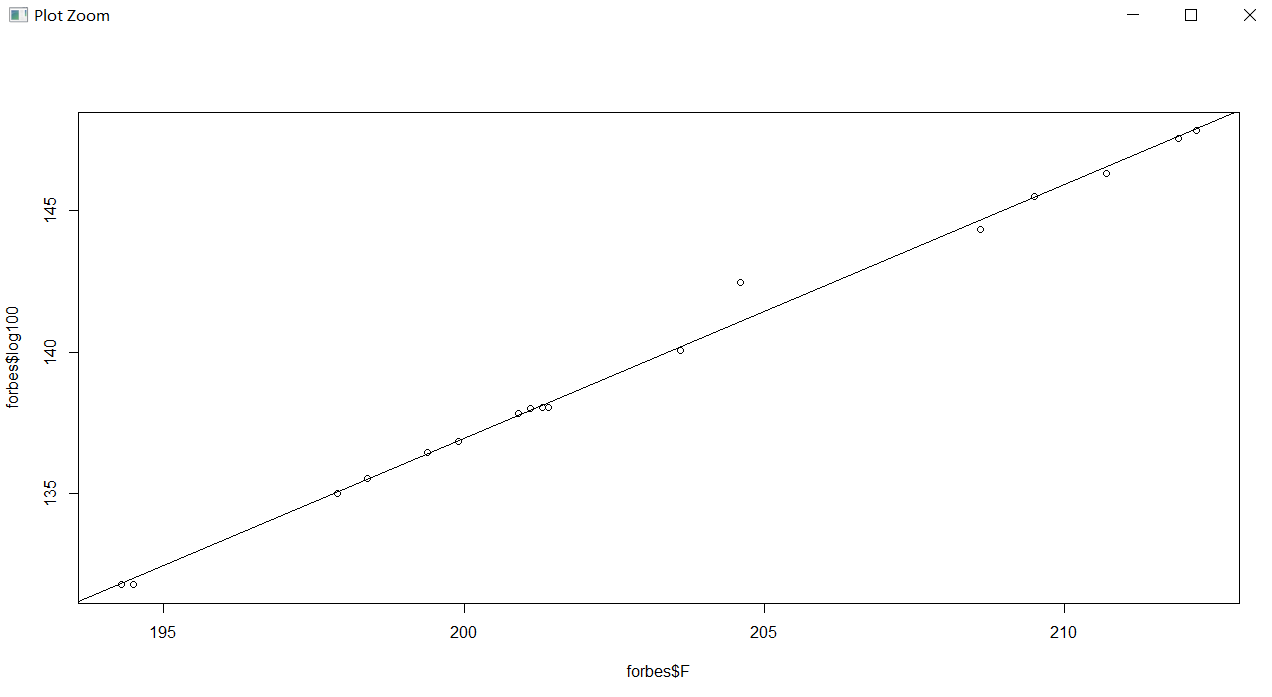
#残差检验
y.res<-residuals(lm.sol);plot(y.res)#画出残差图
text(12,y.res[12], labels=12,adj=1.2)
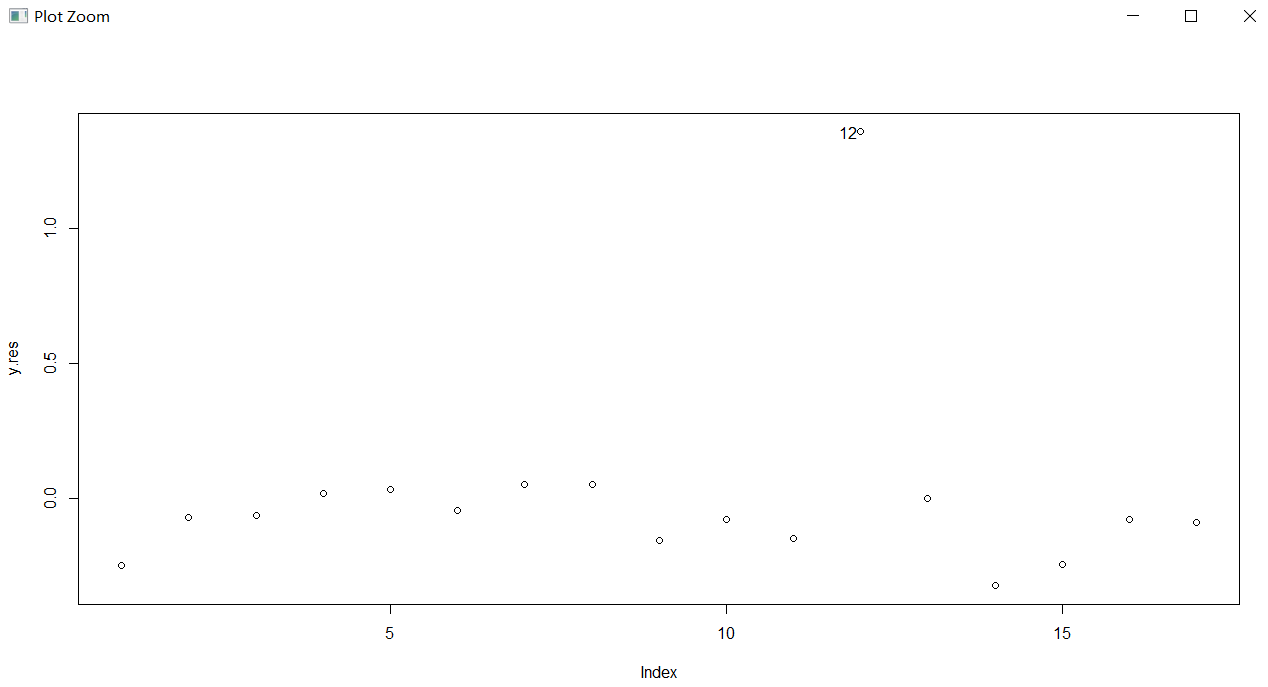
#异常值的判断
library(car)
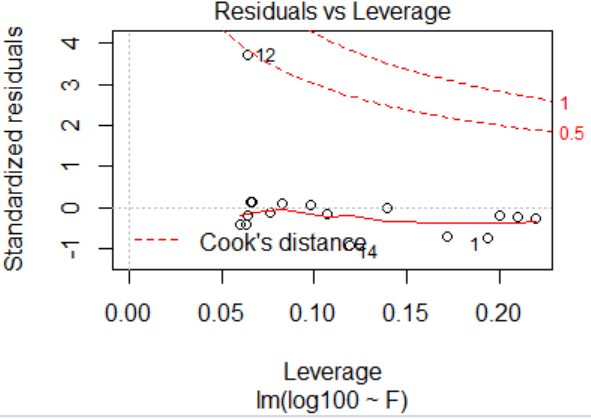
outlierTest(lm.sol)
> outlierTest(lm.sol)
rstudent unadjusted p-value Bonferroni p
12 12.40369 6.1097e-09 1.0386e-07
> plot(lm.sol)
Hit <Return> to see next plot: return
Hit <Return> to see next plot: return
Hit <Return> to see next plot: return
Hit <Return> to see next plot: return
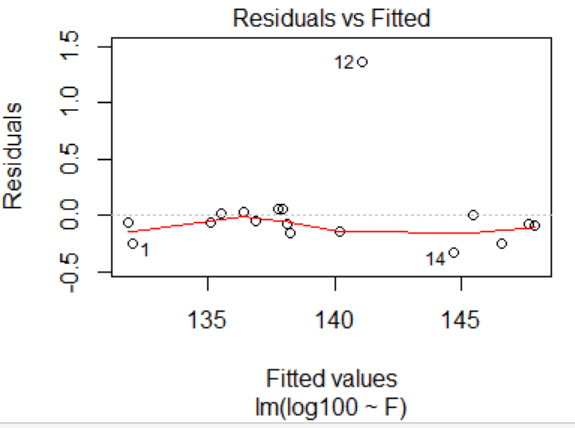
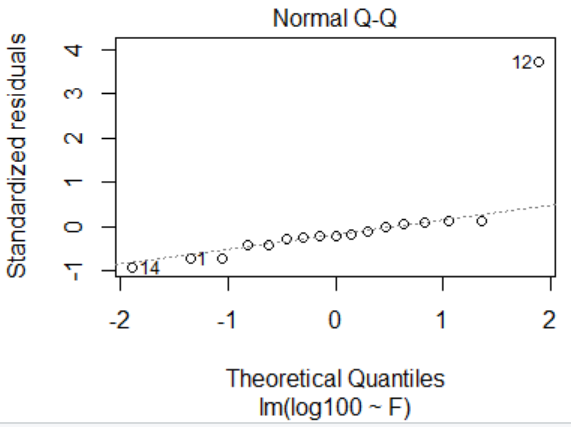
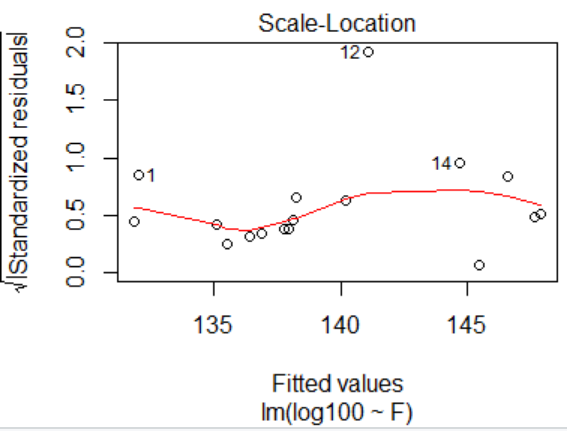
##################################6.6多元回归分析
blood<-data.frame(
X1=c(76.0, 91.5, 85.5, 82.5, 79.0, 80.5, 74.5,
79.0, 85.0, 76.5, 82.0, 95.0, 92.5),
X2=c(50, 20, 20, 30, 30, 50, 60, 50, 40, 55,
40, 40, 20),
Y= c(120, 141, 124, 126, 117, 125, 123, 125,
132, 123, 132, 155, 147)
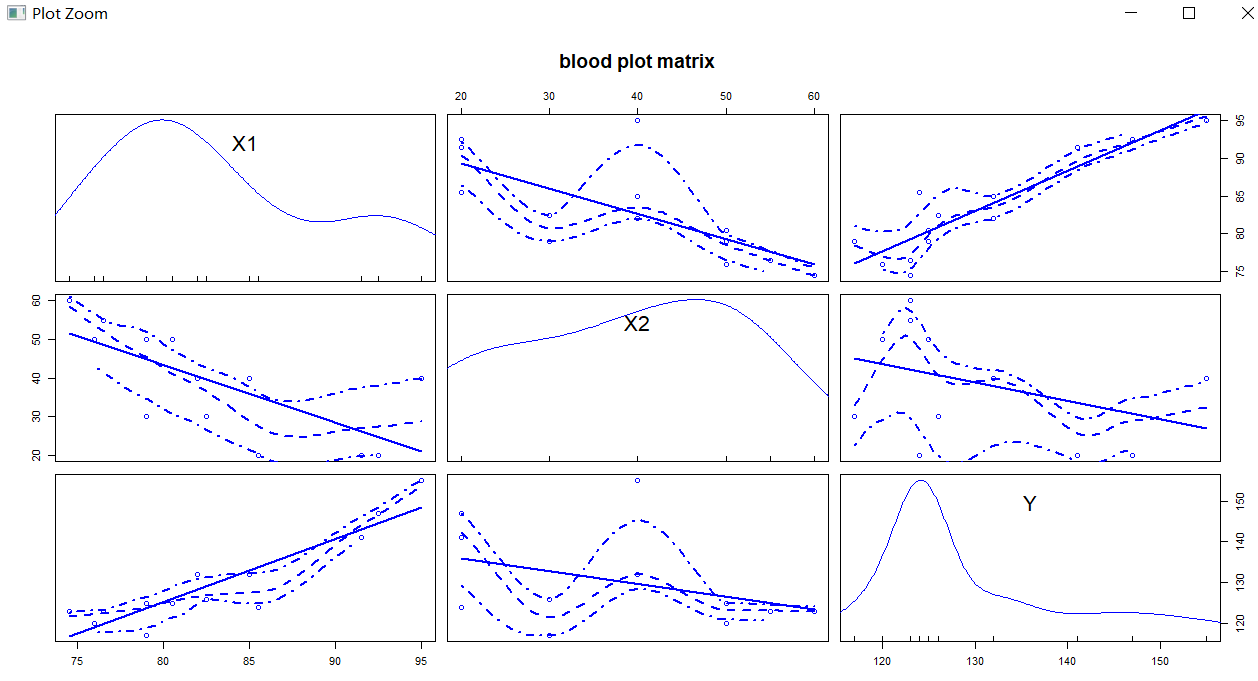
) #多元回归分析时,最好先检查变量之间的相关性
cor(blood)
library(car)
scatterplotMatrix(blood,spread=F,lty.smooth=2,main='blood plot matrix')
> lm.sol<-lm(Y ~ X1+X2, data=blood)
> summary(lm.sol) Call:
lm(formula = Y ~ X1 + X2, data = blood) Residuals:
Min 1Q Median 3Q Max
-4.0404 -1.0183 0.4640 0.6908 4.3274 Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -62.96336 16.99976 -3.704 0.004083 **
X1 2.13656 0.17534 12.185 2.53e-07 ***
X2 0.40022 0.08321 4.810 0.000713 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 2.854 on 10 degrees of freedom
Multiple R-squared: 0.9461, Adjusted R-squared: 0.9354
F-statistic: 87.84 on 2 and 10 DF, p-value: 4.531e-07 > #回归系数的区间估计
> confint(lm.sol)
2.5 % 97.5 %
(Intercept) -100.8411862 -25.0855320
X1 1.7458709 2.5272454
X2 0.2148077 0.5856246
> #6.8预测
> new=data.frame(X1=80,X2=40)#怎么做多组预测?
> lm.pred=predict(lm.sol,new,interval='prediction',level=0.95)
> lm.pred
fit lwr upr
1 123.9699 117.2889 130.6509
所有代码:
#############6.2一元线性回归分析
x<-c(0.10,0.11,0.12,0.13,0.14,0.15,0.16,0.17,0.18,0.20,0.21,0.23)
y<-c(42.0,43.5,45.0,45.5,45.0,47.5,49.0,53.0,50.0,55.0,55.0,60.0)
plot(x~y)
lm.sol<-lm(y ~ x)
summary(lm.sol)
#6.4做预测
new=data.frame(x=0.16)#怎么预测多个数值的结果?
lm.pred=predict(lm.sol,new,interval='prediction',level=0.95)
lm.pred
######
X<-matrix(c(
194.5, 20.79, 1.3179, 131.79,
194.3, 20.79, 1.3179, 131.79,
197.9, 22.40, 1.3502, 135.02,
198.4, 22.67, 1.3555, 135.55,
199.4, 23.15, 1.3646, 136.46,
199.9, 23.35, 1.3683, 136.83,
200.9, 23.89, 1.3782, 137.82,
201.1, 23.99, 1.3800, 138.00,
201.4, 24.02, 1.3806, 138.06,
201.3, 24.01, 1.3805, 138.05,
203.6, 25.14, 1.4004, 140.04,
204.6, 26.57, 1.4244, 142.44,
209.5, 28.49, 1.4547, 145.47,
208.6, 27.76, 1.4434, 144.34,
210.7, 29.04, 1.4630, 146.30,
211.9, 29.88, 1.4754, 147.54,
212.2, 30.06, 1.4780, 147.80),
ncol=4, byrow=T,
dimnames = list(1:17, c("F", "h", "log", "log100")))#如何改变行和列的名称,如何按列排列数据? forbes<-data.frame(X)#把矩阵X转化为数据框
plot(forbes$F, forbes$log100)#画出两个变量之间的散点图,观察是否存在线性趋势;学习
#如何从数据框里面调取向量。怎么写坐标轴的名字和标题?
lm.sol<-lm(log100~F, data=forbes)
summary(lm.sol)
abline(lm.sol)#在散点图上添加直线 #残差检验
y.res<-residuals(lm.sol);plot(y.res)#画出残差图
text(12,y.res[12], labels=12,adj=1.2) #异常值的判断
library(car)
outlierTest(lm.sol) #去除异常值
i<-1:17; forbes12<-data.frame(X[i!=12, ])
lm12<-lm(log100~F, data=forbes12)
summary(lm12) ##################################6.6多元回归分析
blood<-data.frame(
X1=c(76.0, 91.5, 85.5, 82.5, 79.0, 80.5, 74.5,
79.0, 85.0, 76.5, 82.0, 95.0, 92.5),
X2=c(50, 20, 20, 30, 30, 50, 60, 50, 40, 55,
40, 40, 20),
Y= c(120, 141, 124, 126, 117, 125, 123, 125,
132, 123, 132, 155, 147)
) #多元回归分析时,最好先检查变量之间的相关性
cor(blood)
library(car)
scatterplotMatrix(blood,spread=F,lty.smooth=2,main='blood plot matrix') lm.sol<-lm(Y ~ X1+X2, data=blood)
summary(lm.sol) #回归系数的区间估计
confint(lm.sol) #6.8预测
new=data.frame(X1=80,X2=40)#怎么做多组预测?
lm.pred=predict(lm.sol,new,interval='prediction',level=0.95)
lm.pred
R语言与概率统计(三) 多元统计分析(上)的更多相关文章
- R语言与概率统计(三) 多元统计分析(中)
模型修正 #但是,回归分析通常很难一步到位,需要不断修正模型 ###############################6.9通过牙膏销量模型学习模型修正 toothpaste<-data. ...
- R语言与概率统计(三) 多元统计分析(下)广义线性回归
广义线性回归 > life<-data.frame( + X1=c(2.5, 173, 119, 10, 502, 4, 14.4, 2, 40, 6.6, + 21.4, 2.8, 2. ...
- R语言与概率统计(一) 描述性统计分析
#查看已安装的包,查看已载入的包,查看包的介绍 ########例题3.1 #向量的输入方法 w<-c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 6 ...
- R语言与概率统计(二) 假设检验
> ####################5.2 > X<-c(159, 280, 101, 212, 224, 379, 179, 264, + 222, 362, 168, 2 ...
- R语言结合概率统计的体系分析---数字特征
现在有一个人,如何对这个人怎么识别这个人?那么就对其存在的特征进行提取,比如,提取其身高,其相貌,其年龄,分析这些特征,从而确定了,这个人就是这个人,我们绝不会认错. 同理,对数据进行分析,也是提取出 ...
- R语言与概率统计(六) 主成分分析 因子分析
超高维度分析,N*P的矩阵,N为样本个数,P为指标,N<<P PCA:抓住对y对重要的影响因素 主要有三种:PCA,因子分析,回归方程+惩罚函数(如LASSO) 为了降维,用更少的变量解决 ...
- R语言与概率统计(五) 聚类分析
#########################################0808聚类分析 X<-data.frame( x1=c(2959.19, 2459.77, 1495.63, ...
- R语言与概率统计(四) 判别分析(分类)
Fisher就是找一个线L使得组内方差小,组间距离大.即找一个直线使得d最大. ####################################1.判别分析,线性判别:2.分层抽样 #inst ...
- R语言︱数据分组统计函数族——apply族用法与心得
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:apply族功能强大,实用,可以代替 ...
随机推荐
- P3528 [POI2011]PAT-Sticks
题目概述 题目描述 给出若干木棍,每根木棍有特定的颜色和长度.问能否找到三条颜色不同的木棍构成一个三角形. (注意这里所说的三角形面积要严格大于\(0\)) 输入格式 第一行给出一个整数\(k\),表 ...
- ShedLock日常使用
首发于个人博客:ShedLock日常使用 场景模拟 定时器Scheduler在平时使用比较频繁,比如定时数据整理,定时向客户发送问候信息等...,定时任务的配置比较简单,比如在springboot中, ...
- mac系统 flutter从安装到第一个应用
mac系统 安装flutter 分三步: 1. 安装flutter sdk 2. flutter环境变量配置 3. 建立flutter应用 Flutter SDK下载 打开终端执行命令 git clo ...
- CodeForces - 113B Petr# (后缀数组)
应该算是远古时期的一道题了吧,不过感觉挺经典的. 题意是给出三一个字符串s,a,b,求以a开头b结尾的本质不同的字符串数. 由于n不算大,用hash就可以搞,不过这道题是存在复杂度$O(nlogn)$ ...
- hivesql之 table名 with as 转储
可能某个子查询在多个层级多个地方存在重复使用的情况,这个时候我们可以使用 with as 语句将其独立出来,极大提高SQL可读性,简化SQL~ 注:目前 oracle.sql server.hive等 ...
- 2018-2019 ACM-ICPC Nordic Collegiate Programming Contest (NCPC 2018) D. Delivery Delays (二分+最短路+DP)
题目链接:https://codeforc.es/gym/101933/problem/D 题意:地图上有 n 个位置和 m 条边,每条边连接 u.v 且有一个距离 w,一共有 k 个询问,每个询问表 ...
- Java中的集合Collections工具类(六)
操作集合的工具类Collections Java提供了一个操作Set.List和Map等集合的工具类:Collections,该工具类里提供了大量方法对集合元素进行排序.查询和修改等操作,还提供了将集 ...
- hadoop HA+Federation(高可用联邦)搭建配置(一)
hadoop HA+Federation(高可用联邦)搭建配置(一) 标签(空格分隔): 未分类 介绍 hadoop 集群一共有4种部署模式,详见<hadoop 生态圈介绍>. HA联邦模 ...
- JS判断开始时间不能大于检查结束时间
//用来检验检查开始时间不能大于检查结束时间 function checkDate(date){ var startDate = $("#jcrwModel_rwfqsj").va ...
- LINUX 字体查看 字体更改mkfontdir
Linux下字体查看: #fc-list :lang=zh 字体更改: 首先找到相应的字体库:simsun.ttf 宋体 #mkdir -p /usr/share/fonts/truetype //创 ...