DataNode 详解及HDFS 2.X新特性
1. 工作机制
- 一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
- DataNode 启动后向 NameNode 注册,通过后,周期性(1小时)的向 NameNode 上报所有的块信息。
- 心跳是每3秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 DataNode 的心跳,则认为该节点不可用。

==============================
2. 数据完整性
- 当 DataNode 读取 Block 的时候,它会计算 CheckSum。
- 如果计算后的 CheckSum, 与 Block 创建时值不一样, 说明 Block 已经损坏。
- Client 读取其他 DataNode 上的 Block。
- DataNode 在其他文件创建后周期验证 CheckSum;
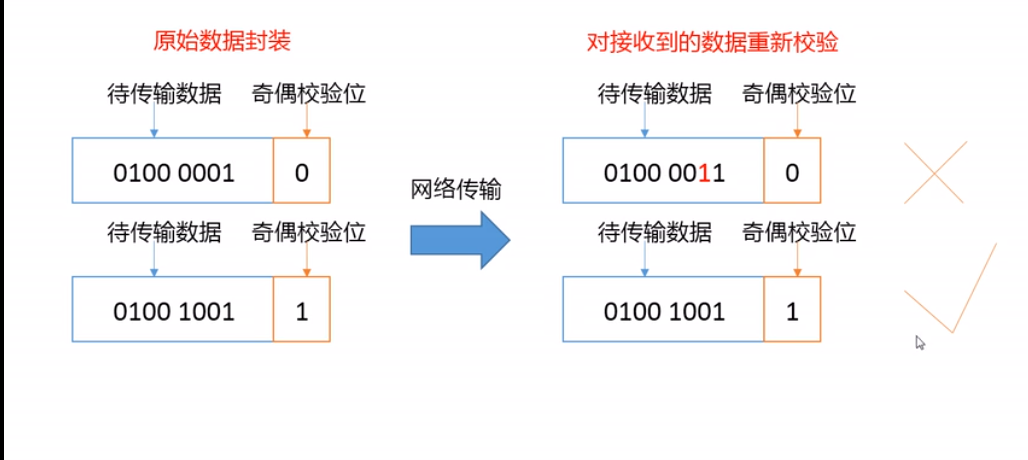
- 奇偶校验示例(实际使用的是CRC校验):
==============================
3. 掉线时限参数设置
- DataNode 进程死亡或者网络故障造成 DataNode 无法与 NameNode 通信;
- NameNode 不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长;
- HDFS 默认的超时时长为10分钟+30秒;
- 如果定义超时时间为 TimeOut, 则超时时长计算公式为:
- TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval;
- "dfs.namenode.heartbeat.recheck-interval"默认为5分钟;
- "dfs.heartbeat.interval"默认为3秒;
4. 服役新节点
- 需求:在原有集群基础上,新增加一个节点。
5. 添加白名单
- 添加到白名单的主机节点,都允许访问 NameNode,不在白名单的主机节点,都会被退出。
6. 黑名单设置
- 在黑名单上的主机都会被强制退出。
7. DataNode 多目录配置
- DataNode 也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本。
// hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
8. HDFS 2.X 新特性
8.1 集群间数据拷贝
scp 实现两个远程主机之间的文件复制
- 推(push):
scp -r hello.txt root@IP:端口/user/noodles/hello.txt - 拉(pull):
scp -r root@IP:端口/user/noodles/hello.txt hello.txt - 两个远程主机之间:
scp -r root@IP1:端口/user/noodles/hello.txt root@IP2:端口/user/test
- 推(push):
采用
distcp命令实现两个 Haoop 集群之间的递归数据复制
bin/hadoop distcp hdfs://IP1:端口1/user/noodles/hello.txt hdfs://IP2:端口2/user/noodles/hello.txt
8.2 小文件存档
- HDFS 存储小文件弊端
- 每个文件均按块存储,每个块的元数据存储在 NameNode 的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽 NameNode 中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128M的块存储,实际使用的是1MB的磁盘空间,而不是128M;
- 解决存储小文件办法之一
- HDFS 存档文件或HAR文件,是一个更高效的文件存档工具。他将文件存入HDFS块,在减少 NameNode 内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对 NameNode 而言却是一个整体,减少了 NameNode 的内存。
- 具体操作步骤:
- 启动YARN进程:
start-yarn.sh - 把"/user/noodles/input"目录里面的所有文件归档成一个名为“input.har”的文件,并把归档后的文件存储到“/user/noodles/output”路径下:
bin/hadoop archive -archiveName input.har -p /user/noodles/input /user/noodles/output
- 启动YARN进程:
8.3 回收站案例
- 开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除,备份等作用。
- 功能参数说明:
- 默认值:
fs.trash.interval=0, 0 表示禁用回收站;其他值表示设置文件的存活时间; - 默认值:
fs.trash.checkpoint.interval=0: 检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。 - 要求:
fs.trash.checkpoint.interval <= fs.trash.interval
- 默认值:
8.4 快照管理
- 快照相当于对目录做一个备份,并不会立即复制所有文件,而是指向同一个文件。当写入发生时,才会发生新文件。
- 开启指定目录的快照功能:
hdfs dfsadmin in -allowSnapshot 路径 - 禁用指定目录的快照功能,默认是禁用:
hdfs dfsadmin -in disallowSnapshot 路径 - 对目录创建快照:
hdfs dfs -createSnapshot 路径 - 创建指定名称的快照:
hdfs dfs -createSnapshot 路径 名称 - 重命名快照:
hdfs dfs -renameSnapshot 路径 旧名称 新名称 - 列出当前用户所有可快照目录:
hdfs lsSnapshottableDir - 比较两个快照目录的不同之处:
hdfs snapshotDiff 路径1 路径2 - 删除快照:
hdfs dfs -deleteSnapshot 路径
- 开启指定目录的快照功能:
DataNode 详解及HDFS 2.X新特性的更多相关文章
- atitit.jQuery Validate验证框架详解与ati Validate 设计新特性
atitit.jQuery Validate验证框架详解与ati Validate 设计新特性 1. AtiValidate的目标1 2. 默的认校验规则1 2.1. 使用方式 1.metadata用 ...
- HDFS体系结构(NameNode、DataNode详解)
hadoop项目地址:http://hadoop.apache.org/ NameNode.DataNode详解 (一)分布式文件系统概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配 ...
- (转载)详解7.0带来的新工具类:DiffUtil
[Android]详解7.0带来的新工具类:DiffUtil 标签: diffutil 2017-04-17 18:21 226人阅读 评论(0) 收藏 举报 分类: Android学习笔记(94) ...
- 细解JavaScript ES7 ES8 ES9 新特性
题记:本文提供了一个在线PPT版本,方便您浏览 细解JAVASCRIPT ES7 ES8 ES9 新特性 在线PPT ver 本文的大部分内容译自作者Axel Rauschmayer博士的网站,想了解 ...
- 【图文详解】HDFS基本原理
本文主要详述了HDFS的组成结构,客户端上传下载的过程,以及HDFS的高可用和联邦HDFS等内容.若有不当之处还请留言指出. 当数据集大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区,并 ...
- HDFS DataNode详解
1. datanode介绍 1.1 datanode datanode是负责当前节点上的数据的管理,具体目录内容是在初始阶段自动创建的,保存的文件夹位置由配置选项{dfs.data.dir}决定 1. ...
- Hadoop(10)-HDFS的DataNode详解
1.DataNode工作机制 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳. 2)DataNode启 ...
- 详解VMware 虚拟机中添加新硬盘的方法
一.VMware新增磁盘的设置步骤 (建议:在设置虚拟的时候,不要运行虚拟机的系统,不然添加了新的虚拟磁盘则要重启虚拟机) 1.选择“VM”----“设置”并打开,将光标定位在“硬盘(SCSI)”这一 ...
- HDFS 2.X新特性
1 集群间数据拷贝 1.scp实现两个远程主机之间的文件复制 scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt // 推 push scp ...
随机推荐
- cursor: hand和cursor:pointer的区别
cursor:hand 与 cursor:pointer 的效果是一样的,都像光标指向链接一样,光标变成手行. cursor:hand :IE完全支持.但是在firefox是不支持的,没有效果. cu ...
- chrome扩展开发实战入门之二-自动搜索
目标:产生随机数,用于百度搜索:像看电视一样观看搜索结果 参考上一篇,新建目录hellocrx,其中三个文件:manifest.json content_script.js 和jquery-3.4. ...
- springBoot怎样访问静态资源?+静态资源简介
1.静态资源 怎样通过浏览器访问静态资源? 注意:不需要加static目录.因为只是告诉springboot目录,而不是静态资源路劲. 这时访问路径就需要加上/static
- FHS 层级文件系统
- leetcode解题报告(4):Search in Rotated Sorted ArrayII
描述 Follow up for "Search in Rotated Sorted Array": What if duplicates are allowed? Would t ...
- unix/linux 进程间文件锁
转自 http://www.cnblogs.com/hjslovewcl/archive/2011/03/14/2314333.html 有三种不同的文件锁,这三种都是“咨询性”的,也就是说它们依靠程 ...
- poj 1458 Common Subsequence ——(LCS)
虽然以前可能接触过最长公共子序列,但是正规的写应该还是第一次吧. 直接贴代码就好了吧: #include <stdio.h> #include <algorithm> #inc ...
- 5.4.2 mapFile读写和索引
5.4.2 mapFile (1)定义 MapFile即为排序后的SequeneceFile,将sequenceFile文件按照键值进行排序,并且提供索引实现快速检索. (2)索引 索 ...
- 【java中的static关键字】
文章转自:https://www.cnblogs.com/dolphin0520/p/3799052.html 一.static关键字的用途 在<Java编程思想>P86页有这样一段话: ...
- oracle OPEN FOR [USING] 语句
目的: 和ref cursor配合使用, 可以将游标变量分配给不同的SQL (而不是在declare中把游标给定死), 增加处理游标的灵活性语法: declare type type_c ...