flink部署
参考:
https://ververica.cn/developers-resources/
#flink参数
https://blog.csdn.net/qq_35440040/article/details/84992796
spark使用批处理模拟流计算
flink使用流框架模拟批计算
https://ci.apache.org/projects/flink/flink-docs-release-1.8/
https://flink.apache.org/downloads.html#
下载包:
https://flink.apache.org/downloads.html
tar -xzvf flink-1.8.0-bin-scala_2.11.tgz -C /opt/module/
vim /etc/profile
export FLINK_HOME=/opt/module/flink-1.8.0
export PATH=$PATH:$FLINK_HOME/bin
cd /opt/module/flink-1.8.0/conf
mv flink-conf.yaml flink-conf.yaml.bak
vim flink-conf.yaml
jobmanager.rpc.address: Fengfeng-dr-algo1
jobmanager.rpc.port: 6123
jobmanager.heap.size: 1024m
taskmanager.heap.size: 1024m
taskmanager.numberOfTaskSlots: 2
parallelism.default: 2
fs.default-scheme: hdfs://Fengfeng-dr-algo1:9820
#这个是在core-site.xml里配的hdfs集群地址,yarn集群模式主要配这个
vim masters
Fengfeng-dr-algo1
vim slaves
Fengfeng-dr-algo2
Fengfeng-dr-algo3
Fengfeng-dr-algo4
#配置完成后将文件同步到其他节点
scp /etc/profile Fengfeng-dr-algo2:/etc/profile
scp /etc/profile Fengfeng-dr-algo3:/etc/profile
scp /etc/profile Fengfeng-dr-algo4:/etc/profile
scp -r /opt/module/flink-1.8.0/ Fengfeng-dr-algo2:/opt/module
scp -r /opt/module/flink-1.8.0/ Fengfeng-dr-algo3:/opt/module
scp -r /opt/module/flink-1.8.0/ Fengfeng-dr-algo4:/opt/module
启动集群start-cluster.sh
检查TaskManagerRunner服务起来没有:
[root@Fengfeng-dr-algo1 conf]# ansible all -m shell -a 'jps'
Fengfeng-dr-algo3 | SUCCESS | rc=0 >>
20978 DataNode
22386 TaskManagerRunner
22490 Jps
21295 NodeManager
Fengfeng-dr-algo4 | SUCCESS | rc=0 >>
24625 NodeManager
26193 TaskManagerRunner
24180 DataNode
24292 SecondaryNameNode
26297 Jps
Fengfeng-dr-algo2 | SUCCESS | rc=0 >>
26753 Jps
24867 ResourceManager
24356 DataNode
25480 NodeManager
26650 TaskManagerRunner
Fengfeng-dr-algo1 | SUCCESS | rc=0 >>
27216 Jps
24641 NameNode
24789 DataNode
27048 StandaloneSessionClusterEntrypoint
25500 NodeManager
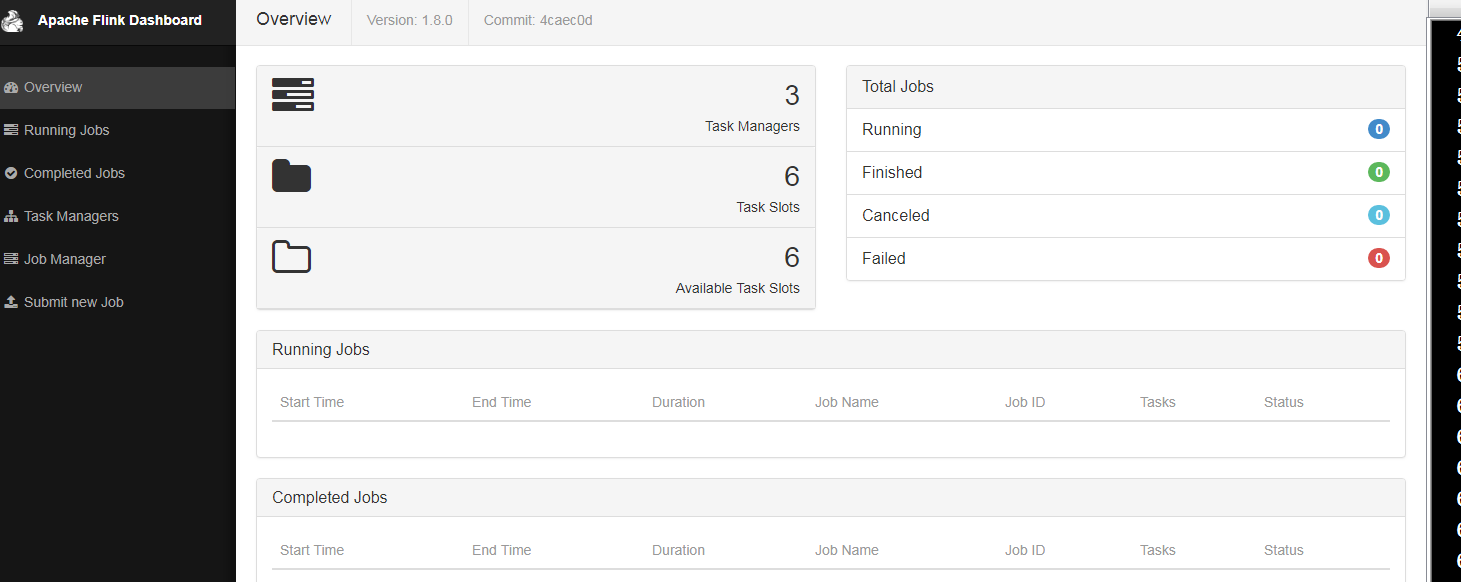
查看WebUI,端口为8081
#运行flink测试,1.txt在hdfs上.
1/ 以standalone模式
flink run /opt/module/flink-1.8.0/examples/batch/WordCount.jar -c wordcount --input /1.txt
2/ 以yarn-cluster模式,需要停掉集群模式stop-cluster.sh
flink run -m yarn-cluster /opt/module/flink-1.8.0/examples/batch/WordCount.jar -c wordcount --input /1.txt
yarn-cluster跑得作业情况可在yarn的web8080端口看
附: flink yarn-cluster跑wordcount结果
[root@fengfeng-dr-algo1 hadoop]# flink run -m yarn-cluster /opt/module/flink-1.8.0/examples/batch/WordCount.jar -c wordcount --input /1.txt
2019-08-15 03:52:50,622 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at oride-dr-algo2/172.28.20.168:8032
2019-08-15 03:52:50,755 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2019-08-15 03:52:50,755 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2019-08-15 03:52:50,922 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2019-08-15 03:52:50,961 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=2}
2019-08-15 03:52:51,410 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/opt/module/flink-1.8.0/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.
2019-08-15 03:52:52,456 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1565840709386_0002
2019-08-15 03:52:52,481 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1565840709386_0002
2019-08-15 03:52:52,481 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
2019-08-15 03:52:52,484 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2019-08-15 03:52:56,776 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
Starting execution of program
Printing result to stdout. Use --output to specify output path.
(abstractions,1)
(an,3)
(and,3)
(application,1)
(at,2)
(be,1)
(broadcast,2)
(called,1)
(can,1)
(deep,1)
(dive,1)
(dynamic,1)
(event,1)
(every,1)
(example,1)
(explain,1)
(exposed,1)
(flink,6)
(has,1)
(implementation,1)
(into,1)
(is,4)
(look,1)
(make,1)
(of,6)
(on,1)
(one,2)
(physical,1)
(runtime,1)
(s,3)
(stack,3)
(state,3)
(the,6)
(this,2)
(types,1)
(up,1)
(what,1)
(a,2)
(about,1)
(apache,3)
(applied,1)
(components,1)
(core,2)
(detail,1)
(evaluates,1)
(first,1)
(how,1)
(in,4)
(it,1)
(job,1)
(module,1)
(multiple,1)
(network,3)
(operator,1)
(operators,1)
(optimisations,1)
(patterns,1)
(post,2)
(posts,1)
(series,1)
(show,1)
(sitting,1)
(stream,2)
(that,2)
(their,1)
(to,2)
(various,1)
(we,2)
(which,2)
Program execution finished
Job with JobID 11307954aeb6a6356cd7b4068f0f2160 has finished.
Job Runtime: 8448 ms
Accumulator Results:
- f0f87f15adda6b1c2703a30e110db5ed (java.util.ArrayList) [69 elements]
公司:
flink run -p 2 -m yarn-cluster -yn 2 -yqu root.users.airflow -ynm opay-metrics -ys 1 -d -c com.opay.bd.opay.main.OpayOrderMetricsMain bd-flink-project-1.0.jar
flink run -p 2 -m yarn-cluster -yn 2 -yqu root.users.airflow -ynm oride-metrics -ys 1 -d -c com.opay.bd.oride.main.OrideOrderMetricsMain bd-flink-project-1.0.jar
-p,--parallelism <parallelism> 运行程序的并行度。 可以选择覆盖配置中指定的默认值
-yn 分配 YARN 容器的数量(=TaskManager 的数量)
-yqu,--yarnqueue <arg> 指定 YARN 队列
-ynm oride-metrics 给应用程序一个自定义的名字显示在 YARN 上
-ys,--yarnslots <arg> 每个 TaskManager 的槽位数量
-ys,--yarnslots <arg> 每个 TaskManager 的槽位数量
-c,--class <classname> 程序入口类
("main" 方法 或 "getPlan()" 方法)
-m yarn-cluster cluster模式
flink部署的更多相关文章
- Flink部署-standalone模式
Flink部署-standalone模式 2018年11月30日 00:07:41 Xlucas 阅读数:74 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.cs ...
- Flink 部署文档
Flink 部署文档 1 先决条件 2 下载 Flink 二进制文件 3 配置 Flink 3.1 flink-conf.yaml 3.2 slaves 4 将配置好的 Flink 分发到其他节点 5 ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- Flink(二) —— 部署与任务提交
一.下载&启动 官网上下载安装包,执行下列命令即启动完成. ./bin/start-cluster.sh 效果图 Flink部署模式 Standalone模式 Yarn模式 k8s部署 二.配 ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
- Flink的高可用集群环境
Flink的高可用集群环境 Flink简介 Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能. 因现在主要Flink这一块做先关方面的学习, ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
转自:https://www.cnblogs.com/reed/p/7730329.html 今天看到一篇讲得比较清晰的框架对比,这几个框架的选择对于初学分布式运算的人来说确实有点迷茫,相信看完这篇文 ...
- Apache Flink系列(1)-概述
一.设计思想及介绍 基本思想:“一切数据都是流,批是流的特例” 1.Micro Batching 模式 在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定 ...
- Flink运行在yarn上
在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的 Workload.因此 Flink 也支持在 Yarn 上面运行: flink on yarn的前提是:hdfs.yar ...
随机推荐
- Confluence 6 移动一个文件到其他页面
你需要同时具有 添加页面(Add Page),添加附件(Add Attachment)和删除附件(Remove Attachment)空间权限来移动一个附件文件到其他页面. 希望修改附件附加的页面到其 ...
- 顺序表应用2:多余元素删除之建表算法(SDUT 3325)
题解: 每次询问一遍,如果已经存在就不用插入表中了. #include <stdio.h> #include <stdlib.h> #include <string.h& ...
- codeforces402B
Trees in a Row CodeForces - 402B The Queen of England has n trees growing in a row in her garden. At ...
- Marcin and Training Camp
D. Marcin and Training Camp 参考:D. Marcin and Training Camp 思路:首先先确定最大成员的\(a_i\),因为不能够某个成员i认为自己比其他所有成 ...
- BZOJ刷题列表【转载于hzwer】
沿着黄学长的步伐~~ 红色为已刷,黑色为未刷,看我多久能搞完吧... Update on 7.26 :之前咕了好久...(足见博主的flag是多么emmm......)这几天开始会抽时间刷的,每天几道 ...
- 「CF525D」Arthur and Walls
题目链接 戳我 \(Solution\) 如果一个#要更改,那么一个四个格子的正方形只有他一个是#,bfs弄一下就好了 \(Code\) #include<bits/stdc++.h> u ...
- hive序列化和反序列化serde
一.简介 SerDe是Serializer/Deserializer的缩写.SerDe允许Hive读取表中的数据,并将其以任何自定义格式写回HDFS. 任何人都可以为自己的数据格式编写自己的SerDe ...
- Java官方操纵byte数组的方式
java官方提供了一种操作字节数组的方法——内存流(字节数组流)ByteArrayInputStream.ByteArrayOutputStream ByteArrayOutputStream——by ...
- JS基础_原型对象
原型prototype 我们创建的每一个函数,解析器都会向函数中添加一个属性prototype 这个属性,对应着一个对象,这个对象就是我们所谓的原型对象 1.如果函数作为普通函数调用prototype ...
- Location of Docker images in all Operating Systems (Linux, Windows, Redhat, Mac OS X)
原文:http://www.scmgalaxy.com/tutorials/location-of-dockers-images-in-all-operating-systems/ Location ...