[转帖]etcd 在超大规模数据场景下的性能优化
etcd 在超大规模数据场景下的性能优化
http://www.itpub.net/2019/05/27/1958/ 不明觉厉
作者 | 阿里云智能事业部高级开发工程师 陈星宇(宇慕)
划重点
- etcd 优化背景
- 问题分析
- 优化方案展示
- 实际优化效果
本文被收录在 5 月 9 日 cncf.io 官方 blog 中,链接:https://www.cncf.io/blog/2019/05/09/performance-optimization-of-etcd-in-web-scale-data-scenario/

概述
etcd 是一个开源的分布式的 kv 存储系统, 最近刚被 CNCF 列为沙箱孵化项目。etcd 的应用场景很广,很多地方都用到了它,例如 Kubernetes 就用它作为集群内部存储元信息的账本。本篇文章首先介绍我们优化的背景,为什么我们要进行优化, 之后介绍 etcd 内部存储系统的工作方式,之后介绍本次具体的实现方式及最后的优化效果。

优化背景
由于阿里巴巴内部集群规模大,所以对 etcd 的数据存储容量有特殊需求,之前的 etcd 支持的存储大小无法满足要求, 因此我们开发了基于 etcd proxy 的解决方案,将数据转储到了 tair 中(可类比 redis))。这种方案虽然解决了数据存储容量的问题,但是弊端也是比较明显的,由于 proxy 需要将数据进行搬移,因此操作的延时比原生存储大了很多。除此之外,由于多了 tair 这个组件,运维和管理成本较高。因此我们就想到底是什么原因限制了 etcd 的存储容量,我们是否可以通过技术手段优化解决呢?
提出了如上问题后我们首先进行了压力测试不停地像 etcd 中注入数据,当 etcd 存储数据量超过 40GB 后,经过一次 compact(compact 是 etcd 将不需要的历史版本数据删除的操作)后发现 put 操作的延时激增,很多操作还出现了超时。监控发现 boltdb 内部 spill 操作(具体定义见下文)耗时显著增加(从一般的 1ms 左右激增到了 8s)。之后经过反复多次压测都是如此,每次发生 compact 后,就像世界发生了停止,所有 etcd 读写操作延时比正常值高了几百倍,根本无法使用。

etcd 内部存储工作原理
etcd 存储层可以看成由两部分组成,一层在内存中的基于 btree 的索引层,一层基于 boltdb 的磁盘存储层。这里我们重点介绍底层 boltdb 层,因为和本次优化相关,其他可参考上文。
etcd 中使用 boltdb 作为最底层持久化 kv 数据库,boltdb 的介绍如下:
Bolt was originally a port of LMDB so it is architecturally similar.
Both use a B+tree, have ACID semantics with fully serializable transactions, and support lock-free MVCC using a single writer and multiple readers.
Bolt is a relatively small code base (<3KLOC) for an embedded, serializable, transactional key/value database so it can be a good starting point for people interested in how databases work。
如上介绍,它短小精悍,可以内嵌到其他软件内部,作为数据库使用,例如 etcd 就内嵌了 boltdb 作为内部存储 k/v 数据的引擎。
boltdb 的内部使用 B+ tree 作为存储数据的数据结构,叶子节点存放具体的真实存储键值。它将所有数据存放在单个文件中,使用 mmap 将其映射到内存,进行读取,对数据的修改利用 write 写入文件。数据存放的基本单位是一个 page, 大小默认为 4K. 当发生数据删除时,boltdb 不直接将删掉的磁盘空间还给系统,而是内部将他先暂时保存,构成一个已经释放的 page 池,供后续使用,这个所谓的池在 boltdb 内叫 freelist。例子如下:

红色的 page 43, 45, 46, 50 页面正在被使用,而 page 42, 44, 47, 48, 49, 51 是空闲的,可供后续使用。
如下 etcd 监控图当 etcd 数据量在 50GB 左右时,spill 操作延时激增到了 8s。


问题分析
由于发生了用户数据的写入, 因此内部 B+ tree 结构会频繁发生调整(如再平衡,分裂合并树的节点)。spill 操作是 boltdb 内部将用户写入数据 commit 到磁盘的关键一步, 它发生在树结构调整后。它释放不用的 page 到 freelist, 从 freelist 索取空闲 page 存储数据。
通过对 spill 操作进行更深入细致的调查,我们发现了性能瓶颈所在, spill 操作中如下代码耗时最多:
1// arrayAllocate returns the starting page id of a contiguous list of pages of a given size. 2// If a contiguous block cannot be found then 0 is returned. 3func (f *freelist) arrayAllocate(txid txid, n int) pgid { 4 ... 5 var initial, previd pgid 6 for i, id := range f.ids { 7 if id <= 1 { 8 panic(fmt.Sprintf("invalid page allocation: %d", id)) 9 }1011 // Reset initial page if this is not contiguous.12 if previd == 0 || id-previd != 1 {13 initial = id14 }1516 // If we found a contiguous block then remove it and return it.17 if (id-initial)+1 == pgid(n) {18 if (i + 1) == n {19 f.ids = f.ids[i+1:]20 } else {21 copy(f.ids[i-n+1:], f.ids[i+1:]) # 复制22 f.ids = f.ids[:len(f.ids)-n]23 }2425 ...26 return initial27 }2829 previd = id30 }31 return 032}之前 etcd 内部内部工作原理讲到 boltdb 将之前释放空闲的页面存储为 freelist 供之后使用,如上代码就是 freelist 内部 page 再分配的函数,他尝试分配连续的 n个 page页面供使用,返回起始页 page id。 代码中 f.ids 是一个数组,他记录了内部空闲的 page 的 id。例如之前上图页面里 f.ids=[42,44,47,48,49,51]
当请求 n 个连续页面时,这种方法通过线性扫描的方式进行查找。当遇到内部存在大量碎片时,例如 freelist 内部存在的页面大多是小的页面,比如大小为 1 或者 2,但是当需要一个 size 为 4 的页面时候,这个算法会花很长时间去查找,另外查找后还需调用 copy 移动数组的元素,当数组元素很多,即内部存储了大量数据时,这个操作是非常慢的。

优化方案
由上面的分析, 我们知道线性扫描查找空页面的方法确实比较 naive, 在大数据量场景下很慢。前 yahoo 的 chief scientist Udi Manber 曾说过在 yahoo 内最重要的三大算法是 hashing, hashing and hashing!(From algorithm design manual)
因此我们的优化方案中将相同大小的连续页面用 set 组织起来,然后在用 hash 算法做不同页面大小的映射。如下面新版 freelist 结构体中的 freemaps 数据结构。
1type freelist struct {2 ...3 freemaps map[uint64]pidSet // key is the size of continuous pages(span), value is a set which contains the starting pgids of same size4 forwardMap map[pgid]uint64 // key is start pgid, value is its span size5 backwardMap map[pgid]uint64 // key is end pgid, value is its span size6 ...7}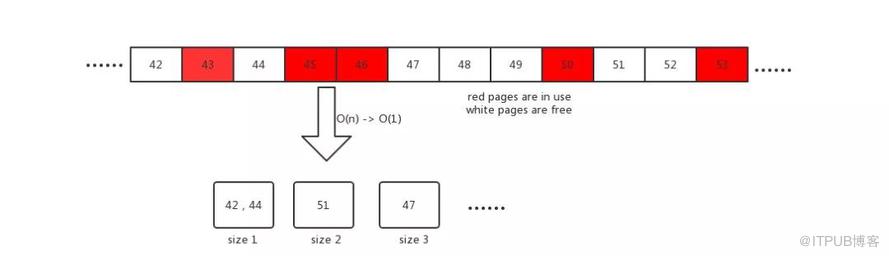
除此之外,当页面被释放,我们需要尽可能的去合并成一个大的连续页面,之前的算法这里也比较简单,是个是耗时的操作 O(nlgn).我们通过 hash 算法,新增了另外两个数据结构 forwardMap 和 backwardMap, 他们的具体含义如下面注释所说。
当一个页面被释放时,他通过查询 backwardMap 尝试与前面的页面合并,通过查询 forwardMap 尝试与后面的页面合并。具体算法见下面mergeWithExistingSpan 函数。
1// mergeWithExistingSpan merges pid to the existing free spans, try to merge it backward and forward 2func (f *freelist) mergeWithExistingSpan(pid pgid) { 3 prev := pid - 1 4 next := pid + 1 5 6 preSize, mergeWithPrev := f.backwardMap[prev] 7 nextSize, mergeWithNext := f.forwardMap[next] 8 newStart := pid 9 newSize := uint64(1)1011 if mergeWithPrev {12 //merge with previous span13 start := prev + 1 - pgid(preSize)14 f.delSpan(start, preSize)1516 newStart -= pgid(preSize)17 newSize += preSize18 }1920 if mergeWithNext {21 // merge with next span22 f.delSpan(next, nextSize)23 newSize += nextSize24 }2526 f.addSpan(newStart, newSize)27}新的算法借鉴了内存管理中的 segregated freelist 的算法,它也使用在 tcmalloc 中。它将 page 分配时间复杂度由 O(n) 降为 O(1), 释放从 O(nlgn) 降为 O(1),优化效果非常明显。

实际优化效果
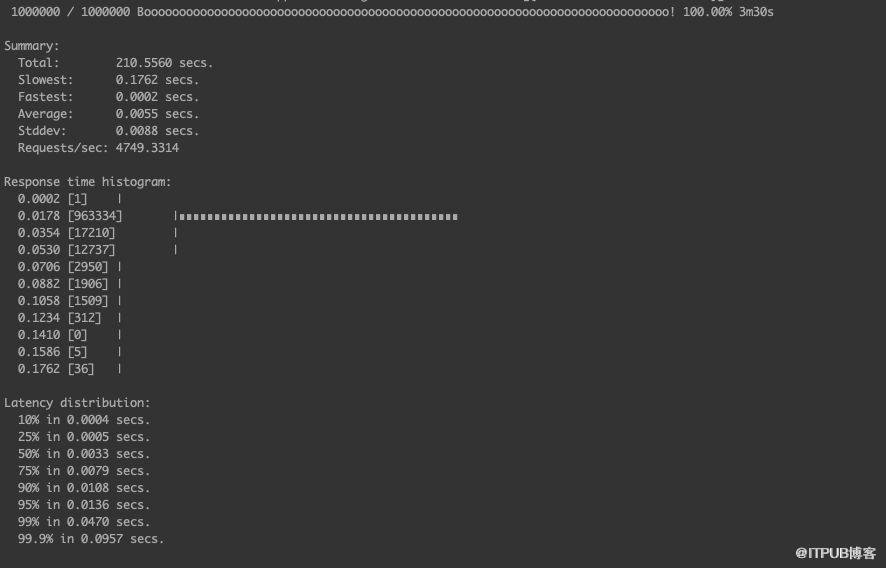
以下测试为了排除网络等其他原因,就测试一台 etcd 节点集群,唯一的不同就是新旧算法不同, 还对老的 tair 作为后端存储的方案进行了对比测试. 模拟测试为接近真实场景,模拟 100 个客户端同时向 etcd put 1 百万的 kv 对,kv 内容随机,控制最高 5000qps,总计大约 20~30GB 数据。测试工具是基于官方代码的 benchmark 工具,各种情况下客户端延时如下:旧的算法时间
有一些超时没有完成测试。

新的 segregated hashmap
etcd over tail 时间
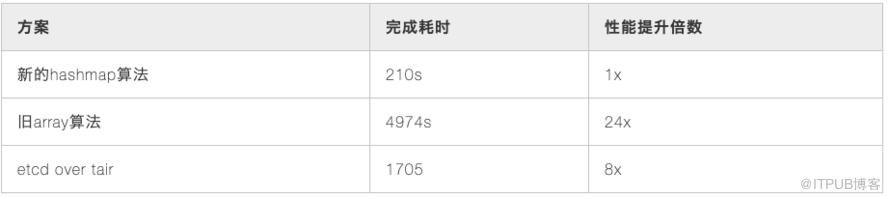
在数据量更大的场景下,并发度更高的情况下新算法提升倍数会更多。

总结
这次优化将 boltdb中 freelist 分配的内部算法由 O(n) 降为 O(1), 释放部分从 O(nlgn) 降为 O(1), 解决了在超大数据规模下 etcd 内部存储的性能问题,使 etcd 存储 100GB 数据时的读写操作也像存储 2GB 一样流畅。并且这次的新算法完全向后兼容,无需做数据迁移或是数据格式变化即可使用新技术带来的福利!
目前该优化经过 2 个多月的反复测试, 上线使用效果稳定,并且已经贡献到了开源社区(https://github.com/etcd-io/bbolt/pull/141),在新版本的 boltdb 和 etcd 中,供更多人使用。
[转帖]etcd 在超大规模数据场景下的性能优化的更多相关文章
- etcd 在超大规模数据场景下的性能优化
作者 | 阿里云智能事业部高级开发工程师 陈星宇(宇慕) 概述 etcd是一个开源的分布式的kv存储系统, 最近刚被cncf列为沙箱孵化项目.etcd的应用场景很广,很多地方都用到了它,例如kuber ...
- Spark Tungsten揭秘 Day1 jvm下的性能优化
Spark Tungsten揭秘 Day1 jvm下的性能优化 今天开始谈下Tungsten,首先我们需要了解下其背后是符合了什么样的规律. jvm对分布式天生支持 整个Spark分布式系统是建立在分 ...
- Oracle在Linux下的性能优化
Oracle数据库内存参数的优化 Ø 与oracle相关的系统内核参数 Ø SGA.PGA参数设置 Oracle下磁盘存储性能优化 Ø 文件系统的选择(ext2 ...
- TOP100summit:【分享实录-华为】微服务场景下的性能提升最佳实践
本篇文章内容来自2016年TOP100summit华为架构部资深架构师王启军的案例分享.编辑:Cynthia 王启军:华为架构部资深架构师.负责华为的云化.微服务架构推进落地,前后参与了华为手机祥云4 ...
- 硬核测试:Pulsar 与 Kafka 在金融场景下的性能分析
背景 Apache Pulsar 是下一代分布式消息流平台,采用计算存储分层架构,具备多租户.高一致.高性能.百万 topic.数据平滑迁移等诸多优势.越来越多的企业正在使用 Pulsar 或者尝试将 ...
- Linux 下网络性能优化方法简析
概述 对于网络的行为,可以简单划分为 3 条路径:1) 发送路径,2) 转发路径,3) 接收路径,而网络性能的优化则可基于这 3 条路径来考虑.由于数据包的转发一般是具备路由功能的设备所关注,在本文中 ...
- TI C6000 数据存储处理与性能优化
存储器之于CPU好比仓库之于车间.车间加工过程中的原材料.半成品.成品等均需入出仓库,生产效率再快,如果仓库周转不善,也必然造成生产阻塞.如同仓库需要合理地规划管理一般,数据存储也需要恰当的处理技巧来 ...
- 高并发场景下的httpClient优化使用
1.背景 我们有个业务,会调用其他部门提供的一个基于http的服务,日调用量在千万级别.使用了httpclient来完成业务.之前因为qps上不去,就看了一下业务代码,并做了一些优化,记录在这里. 先 ...
- 特定场景下SQL的优化
1.大表的数据修改最好分批处理. 1000万行的记录表中删除更新100万行记录,一次只删除或更新5000行数据.每批处理完成后,暂停几秒中,进行同步处理. 2.如何修改大表的表结构. 对表的列的字段类 ...
随机推荐
- 《剑指offer》算法题第十天
今日题目: 数组中的逆序对 两个链表的第一个公共节点 数字在排序数组中出现的次数 二叉搜索树的第k大节点 字符流中第一个不重复的字符 1. 数组中的逆序对 题目描述: 在数组中的两个数字,如果前面一个 ...
- CF990G GCD Counting 点分治+容斥+暴力
只想出来 $O(nlogn\times 160)$ 的复杂度,没想到还能过~ Code: #include <cstdio> #include <vector> #includ ...
- 设置Linux自启服务以及优先级
一. 启动优先级 今天有一台服务器没有正常启动,原因是有一个服务没有启动起来,因为A服务需要B服务启动之后才能正常启动,所以需要调整A,B服务的启动顺序.在网上查找了一些资料,总结了一下,以备以后需要 ...
- y7000笔记本 darknet-yolo安装与测试(Ubuntu16.04+Cuda9.0+Cudnn7.1)
https://zhuanlan.zhihu.com/p/41096599 1.先查看是否安装有以下组件,若有先考虑彻底删除再安装(安装严格按照下面顺序进行) 查看nvidia 版本 nvidia-s ...
- TCP 之 TCP_NEW_SYN_RECV状态
概述 以前的TCP请求控制块没有独立的状态,而是依赖于他们的父控制块的状态,也就是TCP_LISTEN状态,现在要把请求控制块加入到全局的ehash中,所以需要一个状态,而TCP_SYN_RECV状态 ...
- Java-JVM 运行时内存结构(Run-Time Data Areas)
Java 虚拟机定义了在程序执行期间使用的各种运行时数据区域. 其中一些数据区域所有线程共享,在 Java 虚拟机(JVM)启动时创建,仅在 Java 虚拟机退出时销毁. 还有一些数据区域是每个线程的 ...
- Python关于%matplotlib inline
Python关于%matplotlib inline %matplotlib inline 是一个魔法函数(Magic Functions).官方给出的定义是:IPython有一组预先定义好的所谓的魔 ...
- centos7编译安装Python 3.6.8 后用pip3出现SSL未配置问题(import ssl失败)解决方法
下载源码编译安装openssl https://www.openssl.org/source/openssl-1.0.2j.tar.gz ./config --prefix=/usr/local/op ...
- SAX解析示例代码和原理
import java.io.File; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; ...
- git——sourceTree
基本操作 修改密码怎么办? Tools → Options → Authentication 修改密码:或者删除账户,重新拉取需用户名.密码,重新输入即可