SpringBoot缓存篇Ⅰ--- 缓存抽象
缓存是每一个系统应该考虑的功能,它可以用来加速系统的访问,提升系统性能,例如要经常访问的高频热点数据,例如某一个商品网站的商品信息,商品信息存储在数据库中,若每次访问都要查询数据库的话,这样的操作耗时太大了,所以我们需要做一个缓存中间件,这样我们不需要查询数据库了,直接查询缓存,若缓存中有,可以直接返回,若没有再查询数据库,然后放到缓存中,这样我们的系统性能就得到了很大的提升,因为我们的应用程序和缓存的交互是十分快的。
还有一个应用场景是验证码,验证码是临时性数据,一段时间内有效,用完就可以删除,这样的数据无需存在数据库中,所以可以使用缓存来存储这些临时性数据,等用户使用完后自动让它清除。
一、JSR107(了解)
JSR是Java规范请求,故名思议提交Java规范,大家一同遵守这个规范的话,会让大家‘沟通’起来更加轻松。我们一直使用的JDBC就一个访问数据库的一个规范的例子。JSR-107呢就是关于如何使用缓存的规范。
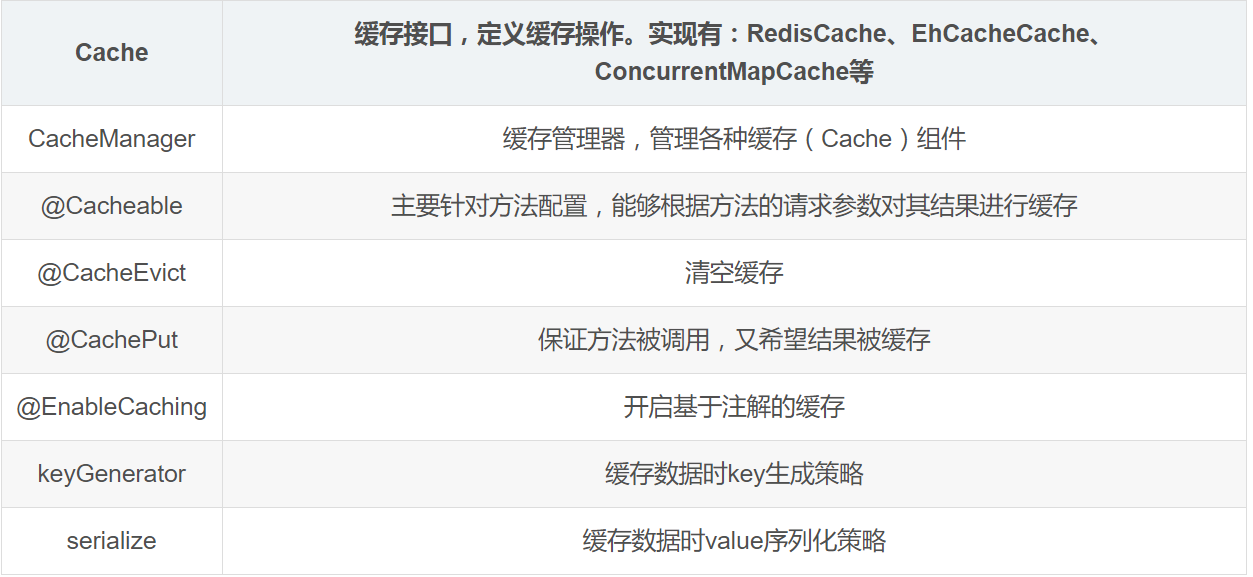
Java Caching定义了5个核心接口,分别是CachingProvider, CacheManager, Cache, Entry和Expiry:
1.CachingProvider定义了创建、配置、获取、管理和控制多个CacheManager。一个应用可以在运行期访问多个CachingProvider。
2.CacheManager定义了创建、配置、获取、管理和控制多个唯一命名的Cache,这些Cache存在于CacheManager的上下文中。一个CacheManager仅被一个CachingProvider所拥有。
3.Cache是一个类似Map的数据结构并临时存储以Key为索引的值。一个Cache仅被一个CacheManager所拥有。
4.Entry是一个存储在Cache中的key-value对。
5.Expiry每一个存储在Cache中的条目有一个定义的有效期。一旦超过这个时间,条目为过期的状态。一旦过期,条目将不可访问、更新和删除。缓存有效期可以通过ExpiryPolicy设置。
使用时需要导入如下包:
<dependency>
<groupId>javax.cache</groupId>
<artifactId>cache-api</artifactId>
</dependency>
JSR107在真正生产开发当中使用的不多,为了简化开发Spring提供了自己的缓存抽象,也定义了一些类似的注解,在实际开发中一般用Spring的缓存抽象。
二、Spring的缓存抽象
Spring框架自身并没有实现缓存解决方案,但是从3.1开始定义了org.springframework.cache.Cache和org.springframework.cache.CacheManager接口,提供对缓存功能的声明,能够与多种流行的缓存实现集成。
几个重要概念&缓存注解
缓存体验
1.搭建基本环境(简单的步骤这里就不给代码演示了)
1).创建department和employee表
2).创建javabean封装数据(简单java实体类)
3).整合mybatis操作数据库
spring.datasource.url=jdbc:mysql://localhost:3306/spring_cache?useUnicode=true&characterEncoding=UTF8&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
#驱动会根据url自行判断
#spring.datasource.driver-class-name=com.mysql.jdbc.Driver
#开启驼峰命名匹配规则
mybatis.configuration.map-underscore-to-camel-case=true
2.缓存快速实现
1).开启基于注解的缓存@EnableCaching
@MapperScan("com.wang.cache.mapper")
@SpringBootApplication
@EnableCaching //开启基于注解的缓存
public class Springboot01CacheApplication {
public static void main(String[] args) {
SpringApplication.run(Springboot01CacheApplication.class, args);
}
}
2).给方法加上缓存标注
@Service
public class EmpService {
@Autowired
EmployeeMapper employeeMapper; @Cacheable(cacheNames = {"emp"})
public Employee getEmp(Integer id){
return employeeMapper.getEmployeeById(id);
}
}
3).启动项目测试,调用这个方法后,查看日志是否打印,若只在第一次访问的时候打印数据库日志,说明该结果已经被缓存了
@Cacheable属性
cacheNames/value:指定缓存的名字,可以指定将方法的结果放在哪个缓存中,可以是数组的方式指定多个缓存
key:缓存数据使用的key,可以用它来指定,默认使用方法参数的值 1-方法的返回值 编写SpEL #id 参数id的值 #a0 #p0 #root.args[0]
keyGenerator:key的生成器,可以自己指定key的生成器的组件id(key与keyGenerator二选一使用)
/**
* 缓存配置类
*/
@Configuration
public class MyCacheConfig {
@Bean("myKeyGenerator")
public KeyGenerator keyGenerator(){
return new KeyGenerator(){ @Override
public Object generate(Object o, Method method, Object... objects) {
return method.getName()+"["+Arrays.asList(objects) +"]";
}
};
} }
@Cacheable(cacheNames = {"emp"},keyGenerator = "myKeyGenerator")
public Employee getEmp(Integer id){
return employeeMapper.getEmployeeById(id);
}
cacheManager:指定缓存管理器,或者指定缓存解析器(二选一)
condition:自定符合条件的情况下才缓存
@Cacheable(cacheNames = {"emp"},keyGenerator = "myKeyGenerator",condition = "#id>1")
public Employee getEmp(Integer id){
return employeeMapper.getEmployeeById(id);
}
unless:否定缓存,当unless指定的条件为true,方法的返回值不会缓存,可以获取到结果进行判断(#result可以取出结果)
@Cacheable(cacheNames = {"emp"},keyGenerator = "myKeyGenerator",unless = "#a0==2")
public Employee getEmp(Integer id){
return employeeMapper.getEmployeeById(id);
}
sync:是否使用异步模式
@CachePut
@Cacheable调用时机是在方法之前调用,若缓存中有了则调用缓存中的方法,若缓存中没有则调用该方法。
@CachePut的调用时机是在方法之后调用,先调用目标方法,然后将目标方法的结果缓存起来,注意该注解标注后无论是怎么样都会调用目标方法
测试@CachePut缓存:
1). 查询1号员工,查到的结果会放到缓存中
2). 查询之前的结果,看看有没有调用目标查询方法,如没有调用说明已经被缓存了
3). 更新1号员工
@CachePut(value = "emp")
public Employee updateEmp(Employee employee){
System.out.println("updateEmp:"+employee);
employeeMapper.updateEmployee(employee);
return employee;
}
4). 此时查询员工发现查询的是更新前的数据,原因key默认是传入的employee对象,而查询的key是员工的id,1号员工没有更新查询的缓存,所以应该指定key,保证与查询的key相同,下面有两种指定key的方式:
1.key="#employee.id",使用传入的参数的员工id
2.key="#result.id",使用返回后的id(@Cacheable无法用result,因为是在方法运行之前调用的)
@CachePut(value = "emp",key="#result.id")
public Employee updateEmp(Employee employee){
System.out.println("updateEmp:"+employee);
employeeMapper.updateEmployee(employee);
return employee;
}
重复上述测试步骤,若查询的结果是更新后的数据,并且没有调用查询员工的service方法,说明该注解起作用了,而且同时更新了数据与缓存。
@CacheEvict
属性详解
key :制定要清除的数据,默认传入的参数为key
allEntries = true,指定这个缓存中所有数据
beforeInvocation:缓存的清除默认是否在方法执行之前执行,默认缓存清除操作是在方法运行之后执行
beforeInvocation = true 表示清楚在方法执行之前执行,无论方法是否异常,都会执行清除
@CacheEvict(value = "emp",key="#id"/*,allEntries = true*//*,beforeInvocation = true*/)
public void deleteEmp(Integer id){
System.out.println("delEmp"+id);
//int i = 1/0;
}
@Caching
使用该注解可以配置多个缓存注解:
@Caching(
cacheable = {
@Cacheable(value = "emp",key="#lastName")
},
put = {
@CachePut(value = "emp",key="#result.id"), //将返回的员工id也放到缓存中
@CachePut(value = "emp",key="#result.email")
}
)
public Employee getEmpByLastName(String lastName){
return employeeMapper.getEmpByLastName(lastName);
}
@CacheConfig
该注解是在类上加的,主要作用是抽取缓存的公共配置,在这里配置的缓存将作用于该类的所有方法。
@CacheConfig(cacheNames = "emp") //抽取缓存的公共配置
@Service
public class EmpService { }
SpringBoot缓存篇Ⅰ--- 缓存抽象的更多相关文章
- jQuery2.x源码解析(缓存篇)
jQuery2.x源码解析(构建篇) jQuery2.x源码解析(设计篇) jQuery2.x源码解析(回调篇) jQuery2.x源码解析(缓存篇) 缓存是jQuery中的又一核心设计,jQuery ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - 快速入门
文章目录 1. 声明式缓存 2. Spring Boot默认集成CacheManager 3. 默认的 ConcurrenMapCacheManager 4. 实战演练5. 扩展阅读 4.1. Mav ...
- spring boot 学习(十四)SpringBoot+Redis+SpringSession缓存之实战
SpringBoot + Redis +SpringSession 缓存之实战 前言 前几天,从师兄那儿了解到EhCache是进程内的缓存框架,虽然它已经提供了集群环境下的缓存同步策略,这种同步仍然需 ...
- springboot+redis实现缓存数据
在当前互联网环境下,缓存随处可见,利用缓存可以很好的提升系统性能,特别是对于查询操作,可以有效的减少数据库压力,Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存 ...
- 缓存篇(Cache)~大话开篇
回到占占推荐博客索引 闲话杂淡 想写这篇文章很久了,但总是感觉内功还不太够,总觉得,要写这种编程领域里的心法(内功)的文章,需要有足够的实践,需要对具体领域非常了解,才能写出来.如今,感觉自己有写这种 ...
- 缓存篇(Cache)~第一回 使用static静态成员实现服务器端缓存(导航面包屑)
返回目录 今天写缓存篇的第一篇文章,在写完目录后,得到了一些朋友的关注,这给我之后的写作带来了无穷的力量,在这里,感谢那几位伙伴,哈哈! 书归正传,今天我带来一个Static静态成员的缓存,其实它也不 ...
- 缓存篇(Cache)~第三回 HttpModule实现网页的文件级缓存
返回目录 再写完缓存篇第一回之后,得到了很多朋友的好评和来信,所以,决定加快步伐,尽快把剩下的文章写完,本篇是第三回,主要介绍使用HttpModule实现的文件级缓存,在看本文之前,大家需要限度Htt ...
- 缓存篇~第六回 Microsoft.Practices.EnterpriseLibrary.Caching实现基于方法签名的数据集缓存
返回目录 这一讲中主要是说EnterpriseLibrary企业级架构里的caching组件,它主要实现了项目缓存功能,它支持四种持久化方式,内存,文件,数据库和自定义,对于持久化不是今天讨论的重要, ...
- (转)高性能网站架构之缓存篇—Redis集群搭建
看过 高性能网站架构之缓存篇--Redis安装配置和高性能网站架构之缓存篇--Redis使用配置端口转发 这两篇文章的,相信你已经对redis有一定的了解,并能够安装上,进行简单的使用了,但是在咱们的 ...
随机推荐
- Python网络编程笔记二
使用select模块实现IO多路复用服务端 import socket import select #windows上只支持select.select,不支持poll epoll HOST = &qu ...
- 我的 2019 年 Python 文章榜单
现在是 2020 年的第一天,我相信从昨天开始,各位的信息流里肯定充斥了各式各样的年度盘点/回顾/总结/记录之类的内容.虽然来得稍晚了,但我还是想给诸位送上这一篇文章. 我将在本文中列出自己于 201 ...
- spring boot(二)热部署
1.打开idea的设置界面 File | Settings > Build, Execution, Deployment > Compiler 2.勾选Buildproject antom ...
- 【合集】有标号的DAG图计数(合集)
[合集]有标号的DAG图计数(合集) orz 1tst [题解]有标号的DAG计数1 [题解]有标号的DAG计数2 [题解]有标号的DAG计数3 [题解]有标号的DAG计数4
- Http请求头安全策略
今天在网上浪了许久,只是为了找一个很简单的配置,却奈何怎么都找不到. 好不容易找到了,我觉得还是记录下来的好,或许省得许多人像我一样浪费时间. 1.X-Frame-Options 如果网站可以嵌入到I ...
- 小小知识点(十五)——origin pro 2018 安装和消除demo字样
安装 1.安装过成中选择语言为中文或者英文,安装完成后可在注册表中切换语言. 2.安装过程中使用序列号 中文版:DF2W8-9089-7991320英文版:GF3S4-9089-7991320 3.安 ...
- Linux 查看实时网卡流量的方法 sar nload iftop
1.sar 计量脚本 sar(System Activity Reporter 系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读 ...
- json查询结果绑定
M_Hisorder.doQuery = function (){ $("#dataList").empty(); var data = ""; var url ...
- 【Java基础总结】IO流
字节流 1. InputStream 字节输入流 代码演示 InputStream in = System.in; System.out.println("int read(byte b) ...
- input值
input里面的值为字符串(string)类型,所以用作数的计算的时候需要用Number(mInput.value)进行转换成数值Numbei()类型才可以计算 例如: mInput1.value + ...