从头学pytorch(四) softmax回归实现
FashionMNIST数据集共70000个样本,60000个train,10000个test.共计10种类别.

通过如下方式下载.
mnist_train = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=True, download=True,
transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=False, download=True,
transform=transforms.ToTensor())
softmax从零实现
- 数据加载
- 初始化模型参数
- 模型定义
- 损失函数定义
- 优化器定义
- 训练
数据加载
import torch
import torchvision
import torchvision.transforms as transforms
mnist_train = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=True, download=True,
transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=False, download=True,
transform=transforms.ToTensor())
batch_size = 256
num_workers = 4 # 多进程同时读取
train_iter = torch.utils.data.DataLoader(
mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(
mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
初始化模型参数
num_inputs = 784 # 图像是28 X 28的图像,共784个特征
num_outputs = 10
W = torch.tensor(np.random.normal(
0, 0.01, (num_inputs, num_outputs)), dtype=torch.float)
b = torch.zeros(num_outputs, dtype=torch.float)
W.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
模型定义
记忆要点:沿着dim方向.行为维度0,列为维度1. 沿着列的方向相加,即对每一行的元素相加.
def softmax(X): # X.shape=[样本数,类别数]
X_exp = X.exp()
partion = X_exp.sum(dim=1, keepdim=True) # 沿着列方向求和,即对每一行求和
#print(partion.shape)
return X_exp/partion # 广播机制,partion被扩展成与X_exp同shape的,对应位置元素做除法
def net(X):
# 通过`view`函数将每张原始图像改成长度为`num_inputs`的向量
return softmax(torch.mm(X.view(-1, num_inputs), W) + b)
损失函数定义
假设训练数据集的样本数为\(n\),交叉熵损失函数定义为
\]
其中\(\boldsymbol{\Theta}\)代表模型参数。同样地,如果每个样本只有一个标签,那么交叉熵损失可以简写成\(\ell(\boldsymbol{\Theta}) = -(1/n) \sum_{i=1}^n \log \hat y_{y^{(i)}}^{(i)}\)。
def cross_entropy(y_hat, y):
y_hat_prob = y_hat.gather(1, y.view(-1, 1)) # ,沿着列方向,即选取出每一行下标为y的元素
return -torch.log(y_hat_prob)
https://pytorch.org/docs/stable/torch.html
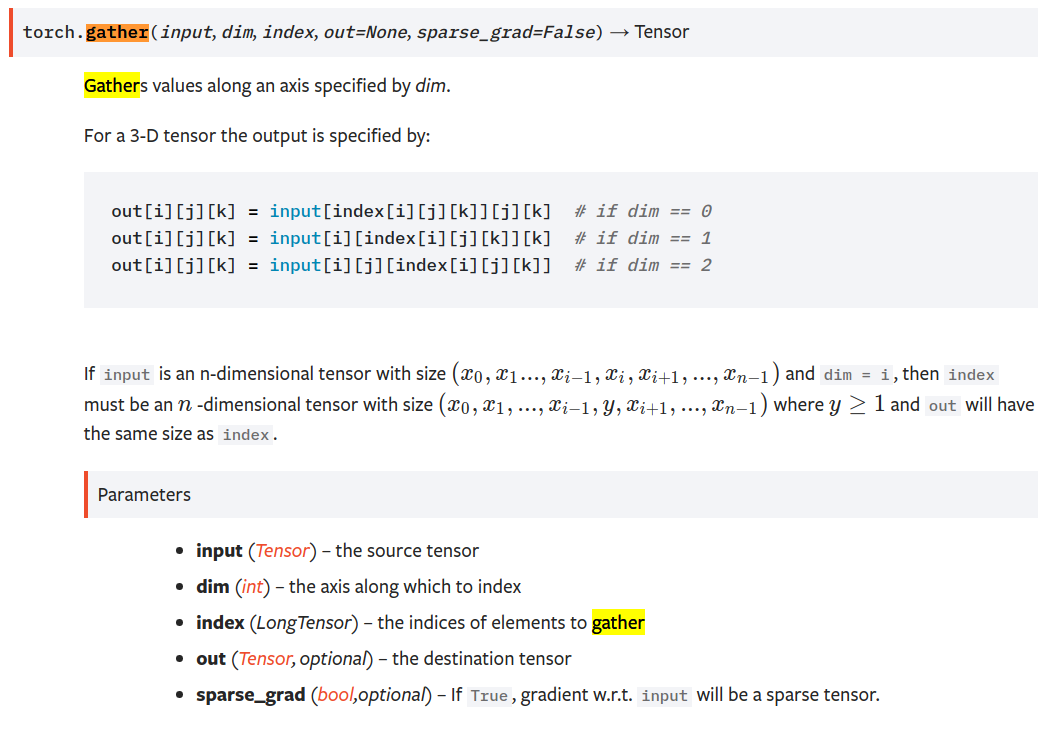
gather()沿着维度dim,选取索引为index的元素
优化算法定义
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data
准确度评估函数
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
训练
- 读入batch_size个样本
- 前向传播,计算预测值
- 与真值相比,计算loss
- 反向传播,计算梯度
- 更新各个参数
如此循环往复.
num_epochs, lr = 5, 0.1
def train():
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
#print(X.shape,y.shape)
y_hat = net(X)
l = cross_entropy(y_hat, y).sum() # 求loss
l.backward() # 反向传播,计算梯度
sgd([W, b], lr, batch_size) # 根据梯度,更新参数
W.grad.data.zero_() # 清空梯度
b.grad.data.zero_()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train_acc %.3f,test_acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum/n, test_acc))
train()
输出如下:
epoch 1, loss 0.7848, train_acc 0.748,test_acc 0.793
epoch 2, loss 0.5704, train_acc 0.813,test_acc 0.811
epoch 3, loss 0.5249, train_acc 0.825,test_acc 0.821
epoch 4, loss 0.5011, train_acc 0.832,test_acc 0.821
epoch 5, loss 0.4861, train_acc 0.837,test_acc 0.829
softmax的简洁实现
- 数据加载
- 模型定义及初始化模型参数
- 损失函数定义
- 优化器定义
- 训练
数据读取
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
import torchvision
import torchvision.transforms as transforms
mnist_train = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=True, download=True,
transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=False, download=True,
transform=transforms.ToTensor())
batch_size = 256
num_workers = 4 # 多进程同时读取
train_iter = torch.utils.data.DataLoader(
mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(
mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
模型定义及模型参数初始化
num_inputs = 784 # 图像是28 X 28的图像,共784个特征
num_outputs = 10
class LinearNet(nn.Module):
def __init__(self,num_inputs,num_outputs):
super(LinearNet,self).__init__()
self.linear = nn.Linear(num_inputs,num_outputs)
def forward(self,x): #x.shape=(batch,1,28,28)
return self.linear(x.view(x.shape[0],-1)) #输入shape应该是[,784]
net = LinearNet(num_inputs,num_outputs)
torch.nn.init.normal_(net.linear.weight,mean=0,std=0.01)
torch.nn.init.constant_(net.linear.bias,val=0)
没有什么要特别注意的,注意一点,由于self.linear的input size为[,784],所以要对x做一次变形x.view(x.shape[0],-1)
损失函数定义
torch里的这个损失函数是包括了softmax计算概率和交叉熵计算的.
loss = nn.CrossEntropyLoss()
优化器定义
optimizer = torch.optim.SGD(net.parameters(),lr=0.01)
训练
精度评测函数
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
训练
- 读入batch_size个样本
- 前向传播,计算预测值
- 与真值相比,计算loss
- 反向传播,计算梯度
- 更新各个参数
如此循环往复.
num_epochs = 5
def train():
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X,y in train_iter:
y_hat=net(X) #前向传播
l = loss(y_hat,y).sum()#计算loss
l.backward()#反向传播
optimizer.step()#参数更新
optimizer.zero_grad()#清空梯度
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
train()
输出
epoch 1, loss 0.0054, train acc 0.638, test acc 0.681
epoch 2, loss 0.0036, train acc 0.716, test acc 0.724
epoch 3, loss 0.0031, train acc 0.749, test acc 0.745
epoch 4, loss 0.0029, train acc 0.767, test acc 0.759
epoch 5, loss 0.0028, train acc 0.780, test acc 0.770
从头学pytorch(四) softmax回归实现的更多相关文章
- 【动手学pytorch】softmax回归
一.什么是softmax? 有一个数组S,其元素为Si ,那么vi 的softmax值,就是该元素的指数与所有元素指数和的比值.具体公式表示为: softmax回归本质上也是一种对数据的估计 二.交叉 ...
- 从头学pytorch(一):数据操作
跟着Dive-into-DL-PyTorch.pdf从头开始学pytorch,夯实基础. Tensor创建 创建未初始化的tensor import torch x = torch.empty(5,3 ...
- 从头学pytorch(十四):lenet
卷积神经网络 在之前的文章里,对28 X 28的图像,我们是通过把它展开为长度为784的一维向量,然后送进全连接层,训练出一个分类模型.这样做主要有两个问题 图像在同一列邻近的像素在这个向量中可能相距 ...
- 从头学pytorch(六):权重衰减
深度学习中常常会存在过拟合现象,比如当训练数据过少时,训练得到的模型很可能在训练集上表现非常好,但是在测试集上表现不好. 应对过拟合,可以通过数据增强,增大训练集数量.我们这里先不介绍数据增强,先从模 ...
- 从头学pytorch(三) 线性回归
关于什么是线性回归,不多做介绍了.可以参考我以前的博客https://www.cnblogs.com/sdu20112013/p/10186516.html 实现线性回归 分为以下几个部分: 生成数据 ...
- 从头学pytorch(十九):批量归一化batch normalization
批量归一化 论文地址:https://arxiv.org/abs/1502.03167 批量归一化基本上是现在模型的标配了. 说实在的,到今天我也没搞明白batch normalize能够使得模型训练 ...
- 从头学pytorch(二十):残差网络resnet
残差网络ResNet resnet是何凯明大神在2015年提出的.并且获得了当年的ImageNet比赛的冠军. 残差网络具有里程碑的意义,为以后的网络设计提出了一个新的思路. googlenet的思路 ...
- 从头学pytorch(五) 多层感知机及其实现
多层感知机 上图所示的多层感知机中,输入和输出个数分别为4和3,中间的隐藏层中包含了5个隐藏单元(hidden unit).由于输入层不涉及计算,图3.3中的多层感知机的层数为2.由图3.3可见,隐藏 ...
- 从头学pytorch(二) 自动求梯度
PyTorch提供的autograd包能够根据输⼊和前向传播过程⾃动构建计算图,并执⾏反向传播. Tensor Tensor的几个重要属性或方法 .requires_grad 设为true的话,ten ...
随机推荐
- ZooKeeper Distributed lock
https://segmentfault.com/a/1190000016351095 http://www.dengshenyu.com/java/%E5%88%86%E5%B8%83%E5%BC% ...
- Virtual Judge POJ 1002 487-3279
模拟 #include<iostream> #include<algorithm> #include<string.h> #include<stdio.h&g ...
- 1015 Reversible Primes
1. 题目 2. 抽象建模 无 3. 方法 无 4. 注意点 素数判断(1不是素数) 数值的倒转 5. 代码 #include<stdio.h> #include<math.h> ...
- 题解【洛谷P1514】[NOIP2010]引水入城
题目描述 在一个遥远的国度,一侧是风景秀美的湖泊,另一侧则是漫无边际的沙漠.该国的行政区划十分特殊,刚好构成一个 \(N\) 行 \(M\) 列的矩形,如上图所示,其中每个格子都代表一座城市,每座城市 ...
- Java实现JSONObject对象与Json字符串互相转换
Java实现JSONObject对象与Json字符串互相转换 JSONObject 转 JSON 字符串 Java代码: JSONObject jsonObject = new JSONObject( ...
- C语言数据结构——第三章 栈和队列
三.栈和队列 栈和队列是两种重要的线性结构.从数据结构的角度来看,栈和队列也是线性表,它的特殊性在于栈和队列的基本操作是线性表操作的子集,它们的操作相对于线性表来说是受到限制的,因此,可以称其为限定性 ...
- 快捷键(二):VSCode
1,打开命令板:F1或Ctrl+Chift+P 2,新建文件:Ctrl+N 3,文件间切换:Ctrl+Tab 4,新开界面:Ctrl+Shift+N 5,关闭当前窗口:Ctrl+W 6,关闭界面:Ct ...
- AcWing 858. Prim算法求最小生成树 稀疏图
//稀疏图 #include <cstring> #include <iostream> #include <algorithm> using namespace ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- chomp/undef/标量 --Perl 入门第二章
1.chomp 用途:去掉字符串 末尾的换行符 $text="a line of text \n" chomp($text) #去除行末的换行符 chomp() --本质上是一个 ...