Dubbo + Kryo 实现高速序列化
Dubbo 中的序列化
Dubbo RPC 是 Dubbo 体系中最核心的一种高性能、高吞吐量的远程调用方式,可以称之为多路复用的 TCP 长连接调用:
- 长连接:避免了每次调用新建 TCP 连接,提高了调用的响应速度
- 多路复用:单个 TCP 连接可交替传输多个请求和响应的消息,降低了连接的等待闲置时间,从而减少了同样并发数下的网络连接数,提高了系统吞吐量
Dubbo RPC 主要用于两个 Dubbo 系统之间的远程调用,特别适合高并发、小数据的互联网场景。而序列化对于远程调用的响应速度、吞吐量、网络带宽消耗等同样也起着至关重要的作用,是我们提升分布式系统性能的最关键因素之一。
Dubbo 中支持的序列化方式:
- dubbo 序列化:阿里尚未开发成熟的高效 java 序列化实现,阿里不建议在生产环境使用它
- hessian2 序列化:hessian 是一种跨语言的高效二进制序列化方式。但这里实际不是原生的 hessian2 序列化,而是阿里修改过的 hessian lite,它是 dubbo RPC 默认启用的序列化方式
- json 序列化:目前有两种实现,一种是采用的阿里的 fastjson 库,另一种是采用 dubbo 中自己实现的简单 json 库,但其实现都不是特别成熟,而且 json 这种文本序列化性能一般不如上面两种二进制序列化。
- java 序列化:主要是采用 JDK 自带的 Java 序列化实现,性能很不理想。
在通常情况下,这四种主要序列化方式的性能从上到下依次递减。对于 dubbo RPC 这种追求高性能的远程调用方式来说,实际上只有 1、2 两种高效序列化方式比较般配,而第 1 个 dubbo 序列化由于还不成熟,所以实际只剩下 2 可用,所以 dubbo RPC 默认采用 hessian2 序列化。
但 hessian 是一个比较老的序列化实现了,而且它是跨语言的,所以不是单独针对 Java 进行优化的。而 dubbo RPC 实际上完全是一种 Java to Java 的远程调用,其实没有必要采用跨语言的序列化方式(当然肯定也不排斥跨语言的序列化)。
最近几年,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,最典型的包括:
- 专门针对 Java 语言的:Kryo,FST 等等
- 跨语言的:Protostuff,ProtoBuf,Thrift,Avro,MsgPack 等等
这些序列化方式的性能多数都显著优于 hessian2(甚至包括尚未成熟的 dubbo 序列化)
有鉴于此,我们为 dubbo 引入 Kryo 和 FST 这两种高效 Java 序列化实现,来逐步取代 hessian2。
其中,Kryo 是一种非常成熟的序列化实现,已经在 Twitter、Groupon、Yahoo 以及多个著名开源项目(如 Hive、Storm)中广泛的使用。而 FST 是一种较新的序列化实现,目前还缺乏足够多的成熟使用案例。
在面向生产环境的应用中,目前更优先选择 Kryo。
启用 Kryo
在 Provider 和 Consumer 项目启用 Kryo 高速序列化功能,两个项目的配置方式相同
增加 Kryo 依赖

增加配置
注册被序列化类
要让 Kryo 和 FST 完全发挥出高性能,最好将那些需要被序列化的类注册到 dubbo 系统中,例如,我们可以实现如下回调接口:

在注册这些类后,序列化的性能可能被大大提升,特别针对小数量的嵌套对象的时候。
当然,在对一个类做序列化的时候,可能还级联引用到很多类,比如 Java 集合类。针对这种情况,我们已经自动将 JDK 中的常用类进行了注册,所以你不需要重复注册它们(当然你重复注册了也没有任何影响),包括:

由于注册被序列化的类仅仅是出于性能优化的目的,所以即使你忘记注册某些类也没有关系。事实上,即使不注册任何类,Kryo 和 FST 的性能依然普遍优于 hessian 和 dubbo 序列化。
为什么需要手动注册
当然,有人可能会问为什么不用配置文件来注册这些类?这是因为要注册的类往往数量较多,导致配置文件冗长;而且在没有好的 IDE 支持的情况下,配置文件的编写和重构都比 Java 类麻烦得多;最后,这些注册的类一般是不需要在项目编译打包后还需要做动态修改的。
另外,有人也会觉得手工注册被序列化的类是一种相对繁琐的工作,是不是可以用 annotation 来标注,然后系统来自动发现并注册。但这里 annotation 的局限是,它只能用来标注你可以修改的类,而很多序列化中引用的类很可能是你没法做修改的(比如第三方库或者 JDK 系统类或者其他项目的类)。另外,添加 annotation 毕竟稍微的“污染”了一下代码,使应用代码对框架增加了一点点的依赖性。
除了 annotation,我们还可以考虑用其它方式来自动注册被序列化的类,例如扫描类路径,自动发现实现 Serializable 接口(甚至包括 Externalizable)的类并将它们注册。当然,我们知道类路径上能找到 Serializable 类可能是非常多的,所以也可以考虑用 package 前缀之类来一定程度限定扫描范围。
当然,在自动注册机制中,特别需要考虑如何保证服务提供端和消费端都以同样的顺序(或者 ID)来注册类,避免错位,毕竟两端可被发现然后注册的类的数量可能都是不一样的。
无参构造函数和 Serializable 接口
如果被序列化的类中 不包含无参的构造函数,则在 Kryo 的序列化中,性能将会大打折扣,因为此时我们在底层将用 Java 的序列化来透明的取代 Kryo 序列化。所以,尽可能为每一个被序列化的类添加无参构造函数是一种最佳实践(当然一个 Java 类如果不自定义构造函数,默认就有无参构造函数)。
另外,Kryo 和 FST 都不需要被序列化类实现 Serializable 接口,但我们还是建议每个被序列化类都去实现 Serializable 接口,因为这样可以保持和 Java 序列化以及 dubbo 序列化的兼容性,另外也使我们未来采用上述某些自动注册机制带来可能。
附:序列化性能分析与测试
测试环境
- 两台独立服务器
- 4 核 Intel(R) Xeon(R) CPU E5-2603 0 @ 1.80GHz
- 8G 内存
- 虚拟机之间网络通过百兆交换机
- CentOS 5
- JDK 7
- Tomcat 7
- JVM 参数
-server -Xms1g -Xmx1g -XX:PermSize=64M -XX:+UseConcMarkSweepGC
注意: 当然这个测试环境较有局限,故当前测试结果未必有非常权威的代表性
测试脚本
和 dubbo 自身的基准测试保持接近,10 个并发客户端持续不断发出请求:
- 传入嵌套复杂对象(但单个数据量很小),不做任何处理,原样返回
- 传入 50K 字符串,不做任何处理,原样返回(TODO:结果尚未列出)
进行 5 分钟性能测试。(引用 dubbo 自身测试的考虑:“主要考察序列化和网络 IO 的性能,因此服务端无任何业务逻辑。取 10 并发是考虑到 http 协议在高并发下对 CPU 的使用率较高可能会先达到瓶颈。”)
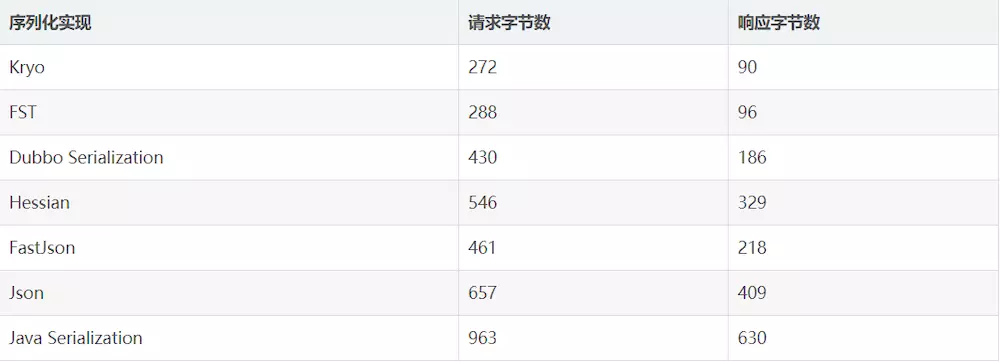
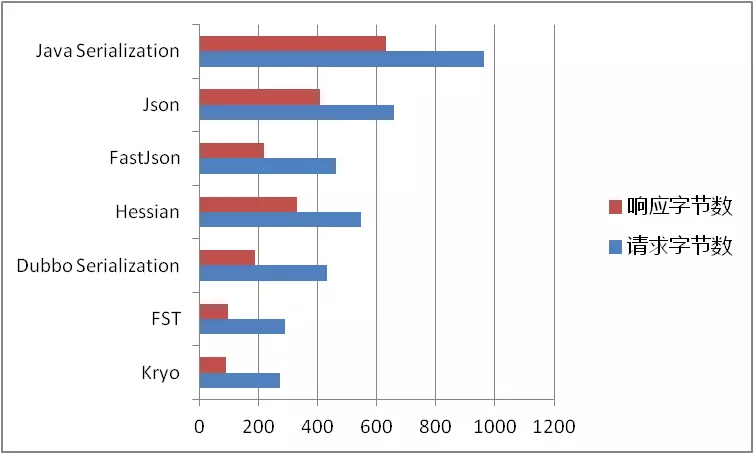
Dubbo RPC 中不同序列化生成字节大小比较
序列化生成字节码的大小是一个比较有确定性的指标,它决定了远程调用的网络传输时间和带宽占用。
针对复杂对象的结果如下(数值越小越好):
Dubbo RPC 中不同序列化响应时间和吞吐量对比

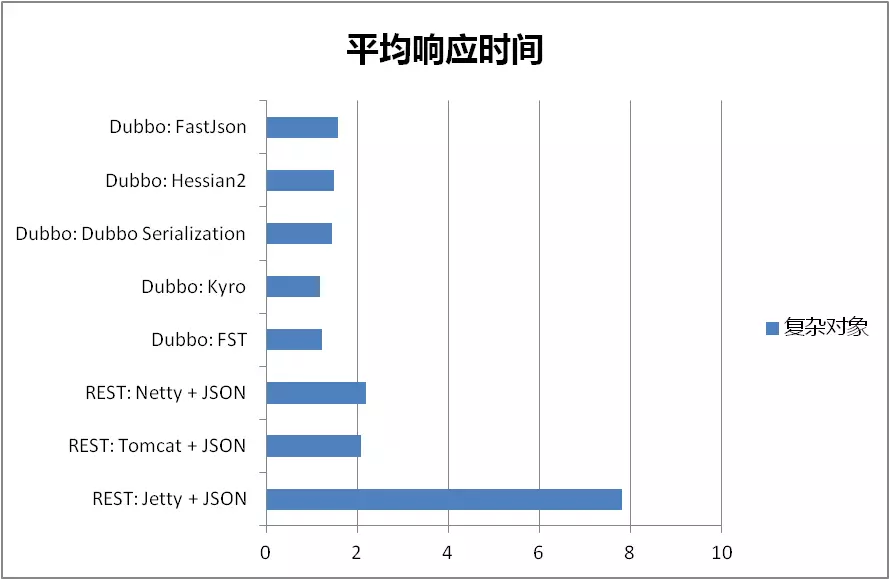

结论
就目前结果而言,我们可以看到不管从生成字节的大小,还是平均响应时间和平均 TPS,Kryo 和 FST 相比 Dubbo RPC 中原有的序列化方式都有非常显著的改进。
转自:https://www.jianshu.com/p/4317532e779a
转载请注明出处!
Dubbo + Kryo 实现高速序列化的更多相关文章
- 分布式RPC框架Dubbo实现服务治理:集成Kryo实现高速序列化,集成Hystrix实现熔断器
Dubbo+Kryo实现高速序列化 Dubbo RPC是Dubbo体系中最核心的一种高性能,高吞吐量的远程调用方式,是一种多路复用的TCP长连接调用: 长连接: 避免每次调用新建TCP连接,提高调用的 ...
- 透过byte数组简单分析Java序列化、Kryo、ProtoBuf序列化
序列化在高性能网络编程.分布式系统开发中是举足轻重的之前有用过Java序列化.ProtocolBuffer等,在这篇文章这里中简单分析序列化后的byte数组观察各种序列化的差异与性能,这里主要分析Ja ...
- 分布式的几件小事(三)dubbo的通信协议与序列化
1.dubbo的通信协议 ①dubbo协议 Dubbo缺省协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况. 特点 : dubbo缺 ...
- ApacheDubbo
一.什么是ApacheDubbo Apache Dubbo (incubating) |ˈdʌbəʊ| 是一款高性能.轻量级的开源 Java RPC 分布式服务框架,它提供了三大核心能力:面向接口的远 ...
- 在Dubbo中使用高效的Java序列化(Kryo和FST)
在Dubbo中使用高效的Java序列化(Kryo和FST) 作者:沈理 文档版权:Creative Commons 3.0许可证 署名-禁止演绎 完善中…… TODO 生成可点击的目录 目录 序列化漫 ...
- Dubbo的反序列化安全问题——kryo和fst
目录 0 前言 1 Dubbo的协议设计 2 Dubbo中的kryo序列化协议触发点 3 Dubbo中的fst序列化协议触发点 3.1 fst复现 3. 2 思路梳理 4 总结 0 前言 本篇是Dub ...
- [java]序列化框架性能对比(kryo、hessian、java、protostuff)
序列化框架性能对比(kryo.hessian.java.protostuff) 简介: 优点 缺点 Kryo 速度快,序列化后体积小 跨语言支持较复杂 Hessian 默认支持跨语言 较慢 Pro ...
- 基于kryonet的RPC,使用kryo进行序列化
Kryo是一个序列化框架. Kryonet是一个基于kryo的RPC框架,它实现了一套高效简洁的API,它通过NIO实现了TCP和UDP通讯,目前还不支持Http. 自己写了一个测试代码,运行了下,感 ...
- 序列化框架性能对比(kryo、hessian、java、protostuff)
简介: 优点 缺点 Kryo 速度快,序列化后体积小 跨语言支持较复杂 Hessian 默认支持跨语言 较慢 Protostuff 速度快,基于protobuf 需静态编译 Protostuff- ...
随机推荐
- magento中的getBaseUrl函数
(转)本文地址:http://www.popo4j.com/magento/mage_getbaseurl.html 在magento中如果要获取JS,media,skin目录,我们可以使用magen ...
- 线性dp(记忆化搜索)——cf953C(经典好题dag和dp结合)
非常好的题!和spoj 的 Mobile Service有点相似,用记忆化搜索很容易解决 看了网上的题解,也是减掉一维,刚好可以开下数组 https://blog.lucien.ink/archive ...
- 几道51nod上据说是提高组难度的dp题
1409 加强版贪吃蛇 听着懵逼做着傻逼. 每个格子只能经过一次,穿过上下界答案清0,不考虑穿的话就随便dp.如果要穿就是从尽可能上面的位置穿过上界,尽可能下面的位置穿过下界. 那么转移这一列之前找一 ...
- idea从零搭建简单的springboot+Mybatis
需用到的sql /* Navicat MySQL Data Transfer Source Server : localhost root Source Server Version : 80012 ...
- hdu4126_hdu4756_求最小生成树的最佳替换边_Kruskal and Prim
目录 Catalog Solution: (有任何问题欢迎留言或私聊 && 欢迎交流讨论哦 Catalog Problem: Portal: hdu4126 hdu4756 原题目 ...
- python从入门到大神---4、python3文件操作最最最最简单实例
python从入门到大神---4.python3文件操作最最最最简单实例 一.总结 一句话总结: python文件操作真的很简单,直接在代码中调用文件操作的函数比如open().read(),无需引包 ...
- jquery scrollTop() 方法
原文地址:http://www.w3school.com.cn/jquery/css_scrolltop.asp 实例 设置 元素中滚动条的垂直偏移: $(".btn1").cli ...
- k8s 存储 nfs服务
1.所有节点安装nfs yum install nfs-utils -y 2.配置nfs服务端,在master节点上 vim exports /data 10.0.0.0/24(rw,async,no ...
- 大神给你分析HTTPS和HTTP的区别
今天在做雅虎的时候,发现用第三方工具截取不到客户端与服务端的通讯,以前重来没碰到过这种情况,仔细看了看,它的url请求时基于https的,gg了下发现原来https协议和http有着很大的区别.总的来 ...
- vue axios springBoot 跨域session丢失
前端: 在引入axios的地方配置 axios.defaults.withCredentials=true,就可以允许跨域携带cookie信息了,这样每次发送ajax请求后,只要不关闭浏览器,得到的s ...