POJ - 2406 ~SPOJ - REPEATS~POJ - 3693 后缀数组求解重复字串问题
POJ - 2406
题意:
给出一个字符串,要把它写成(x)n的形式,问n的最大值。
这题是求整个串的重复次数,不是重复最多次数的字串
这题很容易想到用KMP求最小循环节就没了,但是后缀数组也能写
后缀数组写法放在后面那一题,SPOJ - REPEATS是求子串类型,KMP就不好处理了
这里放下处理KMP的AC代码:
#include <cstdio>
#include <cstring>
#include <queue>
#include <cmath>
#include <algorithm>
#include <set>
#include <iostream>
#include <map>
#include <stack>
#include <string>
#include <time.h>
#include <vector>
#define pi acos(-1.0)
#define eps 1e-9
#define fi first
#define se second
#define rtl rt<<1
#define rtr rt<<1|1
#define bug printf("******\n")
#define mem(a,b) memset(a,b,sizeof(a))
#define name2str(x) #x
#define fuck(x) cout<<#x" = "<<x<<endl
#define f(a) a*a
#define sf(n) scanf("%d", &n)
#define sff(a,b) scanf("%d %d", &a, &b)
#define sfff(a,b,c) scanf("%d %d %d", &a, &b, &c)
#define sffff(a,b,c,d) scanf("%d %d %d %d", &a, &b, &c, &d)
#define pf printf
#define FRE(i,a,b) for(i = a; i <= b; i++)
#define FREE(i,a,b) for(i = a; i >= b; i--)
#define FRL(i,a,b) for(i = a; i < b; i++)+
#define FRLL(i,a,b) for(i = a; i > b; i--)
#define FIN freopen("data.txt","r",stdin)
#define gcd(a,b) __gcd(a,b)
#define lowbit(x) x&-x
#define rep(i,a,b) for(int i=a;i<b;++i)
#define per(i,a,b) for(int i=a-1;i>=b;--i) using namespace std;
typedef long long LL;
typedef unsigned long long ULL;
const int maxn = 1e6 + ;
const int maxm = 8e6 + ;
const int INF = 0x3f3f3f3f;
const int mod = ; char s[maxn];
int n, nxt[maxn];
void get_nxt() {
int j = -, i = ;
nxt[] = -;
while ( i < n ) {
if ( j == - || s[j] == s[i] ) nxt[++i] = ++j;
else j = nxt[j];
}
}
int main() {
while ( scanf ( "%s", s ) && s[] != '.' ) {
n = strlen ( s );
get_nxt();
if ( n % ( n - nxt[n] ) == ) printf ( "%d\n", n / ( n - nxt[n] ) );
else printf ( "1\n" );
}
return ;
}
SPOJ - REPEATS
题意:
求重复次数最多的连续重复子串
这个也是后缀数组求解的基本问题之一
"重复次数最多的连续重复子串"解法
(摘自罗穗骞的国家集训队论文):
先穷举长度L,然后求长度为L的子串最多能连续出现几次。
首先连续出现1次是肯定可以的,所以这里只考虑至少2次的情况。
假设在原字符串中连续出现2次,记这个子字符串为S,
那么S肯定包括了字符r[0], r[L], r[L*2],r[L*3], ……中的某相邻的两个。
所以只须看字符r[L*i]和r[L*(i+1)]往前和往后各能匹配到多远,
记这个总长度为K,那么这里连续出现了K/L+1次。最后看最大值是多少。如图所示。
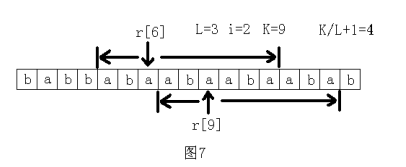
穷举长度 L 的时间是 n,每次计算的时间是 n/L。
所以整个做法的时间复杂 度是 O(n/1+n/2+n/3+……+n/n)=O(nlogn)。
如果读者看到这里还是有点迷,可以点击这里,这篇博客关于这题将的超级详细(而且我的后缀数组板子就是扒这个博主的)
#include <cstdio>
#include <cstring>
#include <queue>
#include <cmath>
#include <algorithm>
#include <set>
#include <iostream>
#include <map>
#include <stack>
#include <string>
#include <time.h>
#include <vector>
#define pi acos(-1.0)
#define eps 1e-9
#define fi first
#define se second
#define rtl rt<<1
#define rtr rt<<1|1
#define bug printf("******\n")
#define mem(a,b) memset(a,b,sizeof(a))
#define name2str(x) #x
#define fuck(x) cout<<#x" = "<<x<<endl
#define f(a) a*a
#define sf(n) scanf("%d", &n)
#define sff(a,b) scanf("%d %d", &a, &b)
#define sfff(a,b,c) scanf("%d %d %d", &a, &b, &c)
#define sffff(a,b,c,d) scanf("%d %d %d %d", &a, &b, &c, &d)
#define pf printf
#define FRE(i,a,b) for(i = a; i <= b; i++)
#define FREE(i,a,b) for(i = a; i >= b; i--)
#define FRL(i,a,b) for(i = a; i < b; i++)+
#define FRLL(i,a,b) for(i = a; i > b; i--)
#define FIN freopen("data.txt","r",stdin)
#define gcd(a,b) __gcd(a,b)
#define lowbit(x) x&-x
#define rep(i,a,b) for(int i=a;i<b;++i)
#define per(i,a,b) for(int i=a-1;i>=b;--i) using namespace std;
typedef long long LL;
typedef unsigned long long ULL;
const int maxn = 1e6 + ;
const int maxm = 8e6 + ;
const int INF = 0x3f3f3f3f;
const int mod = ; //rnk从0开始
//sa从1开始,因为最后一个字符(最小的)排在第0位
//height从1开始,因为表示的是sa[i - 1]和sa[i]
//倍增算法 O(nlogn)
int wa[maxn], wb[maxn], wv[maxn], ws_[maxn];
int Rank[maxn], height[maxn], sa[maxn], r[maxn];
int n, maxx;
char s[];
//Suffix函数的参数m代表字符串中字符的取值范围,是基数排序的一个参数,如果原序列都是字母可以直接取128,如果原序列本身都是整数的话,则m可以取比最大的整数大1的值
//待排序的字符串放在r数组中,从r[0]到r[n-1],长度为n
//为了方便比较大小,可以在字符串后面添加一个字符,这个字符没有在前面的字符中出现过,而且比前面的字符都要小
//同上,为了函数操作的方便,约定除r[n-1]外所有的r[i]都大于0,r[n-1]=0
//函数结束后,结果放在sa数组中,从sa[0]到sa[n-1]
void Suffix ( int *r, int *sa, int n, int m ) {
int i, j, k, *x = wa, *y = wb, *t;
//对长度为1的字符串排序
//一般来说,在字符串的题目中,r的最大值不会很大,所以这里使用了基数排序
//如果r的最大值很大,那么把这段代码改成快速排序
for ( i = ; i < m; ++i ) ws_[i] = ;
for ( i = ; i < n; ++i ) ws_[x[i] = r[i]]++; //统计字符的个数
for ( i = ; i < m; ++i ) ws_[i] += ws_[i - ]; //统计不大于字符i的字符个数
for ( i = n - ; i >= ; --i ) sa[--ws_[x[i]]] = i; //计算字符排名
//基数排序
//x数组保存的值相当于是rank值
for ( j = , k = ; k < n; j *= , m = k ) {
//j是当前字符串的长度,数组y保存的是对第二关键字排序的结果
//第二关键字排序
for ( k = , i = n - j; i < n; ++i ) y[k++] = i; //第二关键字为0的排在前面
for ( i = ; i < n; ++i ) if ( sa[i] >= j ) y[k++] = sa[i] - j; //长度为j的子串sa[i]应该是长度为2 * j的子串sa[i] - j的后缀(第二关键字),对所有的长度为2 * j的子串根据第二关键字来排序
for ( i = ; i < n; ++i ) wv[i] = x[y[i]]; //提取第一关键字
//按第一关键字排序 (原理同对长度为1的字符串排序)
for ( i = ; i < m; ++i ) ws_[i] = ;
for ( i = ; i < n; ++i ) ws_[wv[i]]++;
for ( i = ; i < m; ++i ) ws_[i] += ws_[i - ];
for ( i = n - ; i >= ; --i ) sa[--ws_[wv[i]]] = y[i]; //按第一关键字,计算出了长度为2 * j的子串排名情况
//此时数组x是长度为j的子串的排名情况,数组y仍是根据第二关键字排序后的结果
//计算长度为2 * j的子串的排名情况,保存到数组x
t = x;
x = y;
y = t;
for ( x[sa[]] = , i = k = ; i < n; ++i )
x[sa[i]] = ( y[sa[i - ]] == y[sa[i]] && y[sa[i - ] + j] == y[sa[i] + j] ) ? k - : k++;
//若长度为2 * j的子串sa[i]与sa[i - 1]完全相同,则他们有相同的排名
}
}
void calheight ( int *r, int *sa, int n ) {
int i, j, k = ;
for ( i = ; i <= n; i++ ) Rank[sa[i]] = i;
for ( i = ; i < n; height[Rank[i++]] = k )
for ( k ? k-- : , j = sa[Rank[i] - ]; r[i + k] == r[j + k]; k++ );
}
int minnum[maxn][];
void RMQ() {
int m = ( int ) ( log ( n * 1.0 ) / log ( 2.0 ) );
for ( int i = ; i <= n ; i++ ) minnum[i][] = height[i];
for ( int j = ; j <= m ; j++ )
for ( int i = ; i + ( << j ) - <= n ; i++ )
minnum[i][j] = min ( minnum[i][j - ], minnum[i + ( << ( j - ) )][j - ] );
}
int query ( int a, int b ) {
int k = int ( log ( b - a + 1.0 ) / log ( 2.0 ) );
return min ( minnum[a][k], minnum[b - ( << k ) + ][k] );
}
int calprefix ( int a, int b ) {
int x = Rank[a], y = Rank[b];
if ( x > y ) swap ( x, y );
return query ( x + , y );
}
int main() {
int T;
sf ( T );
while ( T-- ) {
sf ( n );
maxx = , r[n] = ;
for ( int i = ; i < n ; i++ ) {
scanf ( "%s", s );
r[i] = ( int ) s[], maxx = max ( maxx, r[i] );
}
// for ( int i = 0 ; i < n ; i++ ) printf ( "%d%c", r[i], ( i == n - 1 ? '\n' : ' ' ) );
Suffix ( r, sa, n + , maxx + );
calheight ( r, sa, n );
RMQ();
int ans = ;
for ( int i = ; i <= n ; i++ ) {
for ( int j = ; j + i< n ; j += i ) {
int cnt = calprefix ( j, j+i );
int temp = cnt / i + ;
int k = j - ( i - cnt % i );
if ( k >= && calprefix ( k, k + i ) >= i ) temp++;
ans = max ( ans, temp );
}
}
printf ( "%d\n", ans );
}
return ;
}
POJ - 3693:
题意:
要求输出重复次数最多的连续重复子串
若有多个连续重复子串的重复次数相同,输出字典序最小的一个
这题的类型和上一题的类型一样是求重复次数最多的连续重复子串
这题无非是多了一个输出字典序最小的方案而已。
我们在求解的过程中可以将所有方案数存下来,然后通过sa[ ]数组去进行枚举。
(因为sa数组就是通过字典序排序来的)(sa[i]表示字典序排名为i的起始下标)sa[0]表示空串。
#include <cstdio>
#include <cstring>
#include <queue>
#include <cmath>
#include <algorithm>
#include <set>
#include <iostream>
#include <map>
#include <stack>
#include <string>
#include <time.h>
#include <vector>
#define pi acos(-1.0)
#define eps 1e-9
#define fi first
#define se second
#define rtl rt<<1
#define rtr rt<<1|1
#define bug printf("******\n")
#define mem(a,b) memset(a,b,sizeof(a))
#define name2str(x) #x
#define fuck(x) cout<<#x" = "<<x<<endl
#define f(a) a*a
#define sf(n) scanf("%d", &n)
#define sff(a,b) scanf("%d %d", &a, &b)
#define sfff(a,b,c) scanf("%d %d %d", &a, &b, &c)
#define sffff(a,b,c,d) scanf("%d %d %d %d", &a, &b, &c, &d)
#define pf printf
#define FRE(i,a,b) for(i = a; i <= b; i++)
#define FREE(i,a,b) for(i = a; i >= b; i--)
#define FRL(i,a,b) for(i = a; i < b; i++)+
#define FRLL(i,a,b) for(i = a; i > b; i--)
#define FIN freopen("data.txt","r",stdin)
#define gcd(a,b) __gcd(a,b)
#define lowbit(x) x&-x
#define rep(i,a,b) for(int i=a;i<b;++i)
#define per(i,a,b) for(int i=a-1;i>=b;--i) using namespace std;
typedef long long LL;
typedef unsigned long long ULL;
const int maxn = 1e6 + ;
const int maxm = 8e6 + ;
const int INF = 0x3f3f3f3f;
const int mod = ; //rnk从0开始
//sa从1开始,因为最后一个字符(最小的)排在第0位
//height从1开始,因为表示的是sa[i - 1]和sa[i]
//倍增算法 O(nlogn)
int wa[maxn], wb[maxn], wv[maxn], ws_[maxn];
int Rank[maxn], height[maxn], sa[maxn], r[maxn];
int n, maxx;
char s[maxn];
//Suffix函数的参数m代表字符串中字符的取值范围,是基数排序的一个参数,如果原序列都是字母可以直接取128,如果原序列本身都是整数的话,则m可以取比最大的整数大1的值
//待排序的字符串放在r数组中,从r[0]到r[n-1],长度为n
//为了方便比较大小,可以在字符串后面添加一个字符,这个字符没有在前面的字符中出现过,而且比前面的字符都要小
//同上,为了函数操作的方便,约定除r[n-1]外所有的r[i]都大于0,r[n-1]=0
//函数结束后,结果放在sa数组中,从sa[0]到sa[n-1]
void Suffix ( int *r, int *sa, int n, int m ) {
int i, j, k, *x = wa, *y = wb, *t;
//对长度为1的字符串排序
//一般来说,在字符串的题目中,r的最大值不会很大,所以这里使用了基数排序
//如果r的最大值很大,那么把这段代码改成快速排序
for ( i = ; i < m; ++i ) ws_[i] = ;
for ( i = ; i < n; ++i ) ws_[x[i] = r[i]]++; //统计字符的个数
for ( i = ; i < m; ++i ) ws_[i] += ws_[i - ]; //统计不大于字符i的字符个数
for ( i = n - ; i >= ; --i ) sa[--ws_[x[i]]] = i; //计算字符排名
//基数排序
//x数组保存的值相当于是rank值
for ( j = , k = ; k < n; j *= , m = k ) {
//j是当前字符串的长度,数组y保存的是对第二关键字排序的结果
//第二关键字排序
for ( k = , i = n - j; i < n; ++i ) y[k++] = i; //第二关键字为0的排在前面
for ( i = ; i < n; ++i ) if ( sa[i] >= j ) y[k++] = sa[i] - j; //长度为j的子串sa[i]应该是长度为2 * j的子串sa[i] - j的后缀(第二关键字),对所有的长度为2 * j的子串根据第二关键字来排序
for ( i = ; i < n; ++i ) wv[i] = x[y[i]]; //提取第一关键字
//按第一关键字排序 (原理同对长度为1的字符串排序)
for ( i = ; i < m; ++i ) ws_[i] = ;
for ( i = ; i < n; ++i ) ws_[wv[i]]++;
for ( i = ; i < m; ++i ) ws_[i] += ws_[i - ];
for ( i = n - ; i >= ; --i ) sa[--ws_[wv[i]]] = y[i]; //按第一关键字,计算出了长度为2 * j的子串排名情况
//此时数组x是长度为j的子串的排名情况,数组y仍是根据第二关键字排序后的结果
//计算长度为2 * j的子串的排名情况,保存到数组x
t = x;
x = y;
y = t;
for ( x[sa[]] = , i = k = ; i < n; ++i )
x[sa[i]] = ( y[sa[i - ]] == y[sa[i]] && y[sa[i - ] + j] == y[sa[i] + j] ) ? k - : k++;
//若长度为2 * j的子串sa[i]与sa[i - 1]完全相同,则他们有相同的排名
}
}
void calheight ( int *r, int *sa, int n ) {
int i, j, k = ;
for ( i = ; i <= n; i++ ) Rank[sa[i]] = i;
for ( i = ; i < n; height[Rank[i++]] = k )
for ( k ? k-- : , j = sa[Rank[i] - ]; r[i + k] == r[j + k]; k++ );
}
int minnum[maxn][];
void RMQ() {
int m = ( int ) ( log ( n * 1.0 ) / log ( 2.0 ) );
for ( int i = ; i <= n ; i++ ) minnum[i][] = height[i];
for ( int j = ; j <= m ; j++ )
for ( int i = ; i + ( << j ) - <= n ; i++ )
minnum[i][j] = min ( minnum[i][j - ], minnum[i + ( << ( j - ) )][j - ] );
}
int query ( int a, int b ) {
int k = int ( log ( b - a + 1.0 ) / log ( 2.0 ) );
return min ( minnum[a][k], minnum[b - ( << k ) + ][k] );
}
int calprefix ( int a, int b ) {
int x = Rank[a], y = Rank[b];
if ( x > y ) swap ( x, y );
return query ( x + , y );
}
int q[maxn];
int main() {
int cas = ;
while ( scanf ( "%s", s ) && s[] != '#' ) {
n = strlen ( s ), r[n] = ;;
maxx = ;
for ( int i = ; i < n ; i++ ) {
r[i] = ( int ) s[i], maxx = max ( maxx, r[i] );
}
r[n] = ;
// for ( int i = 0 ; i < n ; i++ ) printf ( "%d%c", r[i], ( i == n - 1 ? '\n' : ' ' ) );
Suffix ( r, sa, n + , maxx + );
calheight ( r, sa, n );
RMQ();
int ans = , num = ;
for ( int i = ; i <= n ; i++ ) {
for ( int j = ; j + i < n ; j += i ) {
int cnt = calprefix ( j, j + i );
int temp = cnt / i + ;
int k = j - ( i - cnt % i );
if ( k >= && calprefix ( k, k + i ) >= i ) temp++;
if ( ans == temp && i != q[num - ] ) q[num++] = i;
else if ( ans < temp ) ans = temp, num = , q[num++] = i;
}
}
int flag = ;
for ( int i = ; i <= n ; i++ ) {
for ( int j = ; j < num ; j++ ) {
if ( calprefix ( sa[i], sa[i] + q[j] ) >= q[j] * ( ans - ) ) {
s[sa[i] + q[j]*ans] = '\0';
printf ( "Case %d: %s\n", cas++, s + sa[i] );
flag = ;
break;
}
}
if ( flag ) break;
}
}
return ;
}
POJ - 2406 ~SPOJ - REPEATS~POJ - 3693 后缀数组求解重复字串问题的更多相关文章
- POJ - 2774~POJ - 3415 后缀数组求解公共字串问题
POJ - 2774: 题意: 求解A,B串的最长公共字串 (摘自罗穗骞的国家集训队论文): 算法分析: 字符串的任何一个子串都是这个字符串的某个后缀的前缀. 求 A 和 B 的最长 公共子串等价于求 ...
- POJ - 3294~Relevant Phrases of Annihilation SPOJ - PHRASES~Substrings POJ - 1226~POJ - 3450 ~ POJ - 3080 (后缀数组求解多个串的公共字串问题)
多个字符串的相关问题 这类问题的一个常用做法是,先将所有的字符串连接起来, 然后求后缀数组 和 height 数组,再利用 height 数组进行求解. 这中间可能需要二分答案. POJ - 3294 ...
- poj 3693 后缀数组 重复次数最多的连续重复子串
Maximum repetition substring Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8669 Acc ...
- [POJ 2774] Long Long Message 【后缀数组】
题目链接:POJ - 2774 题目分析 题目要求求出两个字符串的最长公共子串,使用后缀数组求解会十分容易. 将两个字符串用特殊字符隔开再连接到一起,求出后缀数组. 可以看出,最长公共子串就是两个字符 ...
- poj 1743 男人八题之后缀数组求最长不可重叠最长重复子串
Musical Theme Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 14874 Accepted: 5118 De ...
- poj 2774 最长公共子串 后缀数组
Long Long Message Time Limit: 4000MS Memory Limit: 131072K Total Submissions: 25752 Accepted: 10 ...
- 【Poj-3693】Maximum repetition substring 后缀数组 连续重复子串
POJ - 3693 题意 SPOJ - REPEATS的进阶版,在这题的基础上输出字典序最小的重复字串. 思路 跟上题一样,先求出最长的重复次数,在求的过程中顺便纪录最多次数可能的长度. 因为sa数 ...
- hiho一下123周 后缀数组四·重复旋律
后缀数组四·重复旋律4 时间限制:5000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi平时的一大兴趣爱好就是演奏钢琴.我们知道一个音乐旋律被表示为长度为 N 的数构成的数列.小Hi ...
- hiho一下122周 后缀数组三·重复旋律
后缀数组三·重复旋律3 时间限制:5000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi平时的一大兴趣爱好就是演奏钢琴.我们知道一个音乐旋律被表示为长度为 N 的数构成的数列.小Hi ...
随机推荐
- [原创]Delphi 文件函数:ForceDirectories() 函数和 CreateDir函数
引用单元:SysUtils function ForceDirectories(Dir: string): Boolean; //创建多级目录 父目录不必存在 (Force 有暴力.强制的 ...
- Delphi 日期函数列表
引用单元 :DateUtils CompareDate 比较两个日期时间值日期部分的大小CompareDateTime 比较两个日期时间值的大小CompareTime 比较两个日期时间值时间部分的大小 ...
- 官网下载 Linux 上需要的 MySQL的步骤
1.输入MySQL 官网地址 https://dev.mysql.com/ 选择 download ->Community->MySQL Community Server 点击 MyS ...
- PHP rand() 函数
定义和用法 rand() 函数生成随机整数. 提示:如果您想要一个介于 10 和 100 之间(包括 10 和 100)的随机整数,请使用 rand (10,100). 提示:mt_rand() 函数 ...
- centos 服务器编译安装apache+php
1.检查服务器中是否自带httpd,如果/etc/httpd/httpd.conf,说明系统自带httpd服务,需要卸载或关闭服务,不要让他影响到本次安装的服务启动 可以用 service httpd ...
- FILE_OBJECT
https://msdn.microsoft.com/en-us/library/windows/hardware/ff545834(v=vs.85).aspx The FILE_OBJECT str ...
- ES6 学习 -- 字符串模板
ES5及以前,动态操作dom结构时,要多个字符串和变量拼接,如果不换行处理,则需要写很长的代码,不利于阅读理解,如果进行换行写入,则需要一堆的"+"号来连接文本与变量,写起来非常麻 ...
- 关于jquery的一些插件
1.fullPage.js插件 fullPage.js 是一个基于 jQuery 的插件,它能够很方便.很轻松的制作出全屏网站.如今我们经常能见到全屏网站,在手机上也经常能看到一些活动页面.这些网站用 ...
- Hadoop Pig组件
- c++ constructors not allowed a return type错误问题
出现这样的问题 constructors not allowed a return type,是因为类定义或者申明时,结束的地方忘了加个' ; ' 错误的举例如: class ClassName{ } ...