分布式集群HA模式部署
一:HDFS系统架构
(一)利用secondary node备份实现数据可靠性
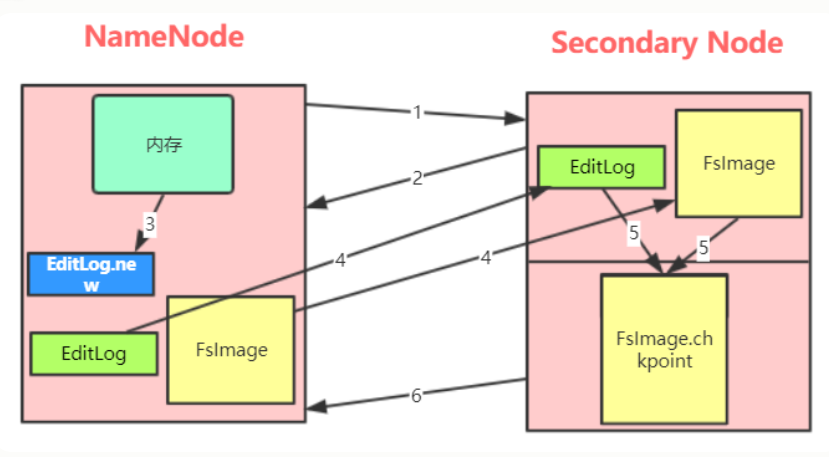
(二)问题:NameNode的可用性不高,当NameNode节点宕机,则服务终止
二:HA架构---提高NameNode服务的可用性
架构中至少有两个NameNode节点 (此处以两个NameNode举例)
(一)两个NN节点在某个时间只能有一个节点正常响应客户端请求,响应请求的必须为ACTIVE状态的那一台。另一台为standby备用
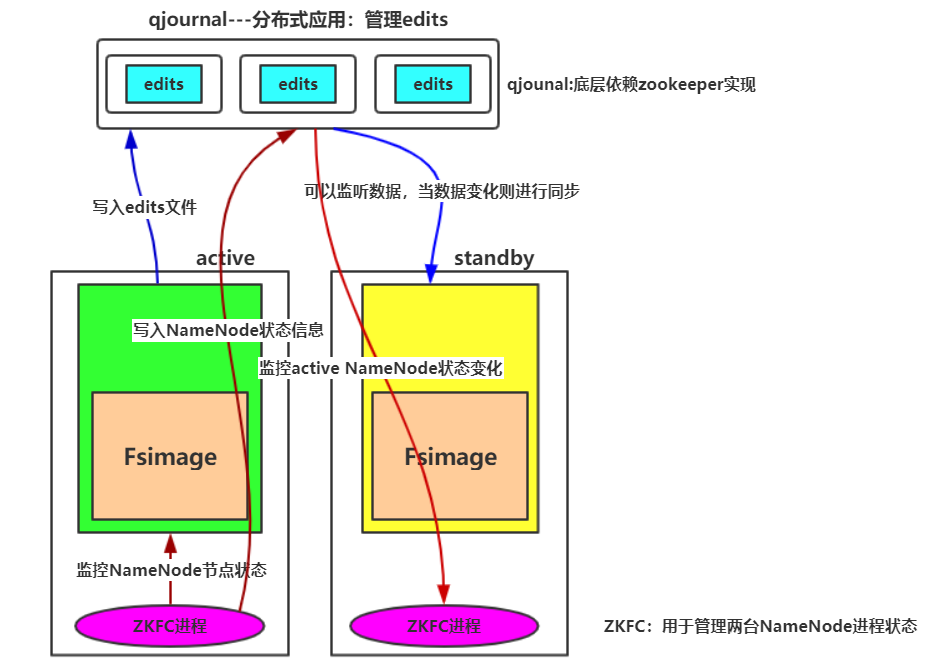
在高可用模式下,这一对NameNode节点,叫做Federation
(二)当active节点宕机,standby状态节点必须能够无缝的切换为active状态。两台NamaNode节点的元数据必须时刻保持一致,才可以实现无缝的切换状态
NameNode最新元数据存放在edits文件(存放少量数据)中,因此将edits日志文件放入zookeeper集群中,用于数据同步(可以保持高可用)

当active节点宕机,standby节点状态变为active,客户端访问新的节点

(三)两个NameNode节点之间如何检测状态变化
方法1:NameNode在zookeeper中注册各自状态(可以使用短暂连接,若某节点宕机,则数据销毁)
方法2:将1中NameNode节点功能独立出来,在节点所在机器中启动监控进程,用于监控NameNode状态,并写入和监控zookeeper数据
(四)避免状态切换出现brain split现象---fencing机制
当active节点出现故障,则standby会切换状态为active。但是如果原始节点出现的是短暂故障,在一段时间后恢复,则出现两台active机器(出现写edits文件不一致)
解决方法:使ZKFC进程功能增加,当standby NameNode中ZKFC检测检测到原active NameNode节点工作不正常,会先进行下面的工作:
方法1:standby使用ssh 原始active节点 kill -9 namenode进程 即使用ssh远程杀死对方active节点(会返回一个结果信息),方法1中需要使用网络通信,可能在通信中出现故障。因此另一种方法是:
方法2:standby执行自定义shell脚本程序,可以去调用命令关闭原active机器
之后才会将standby状态切换为active状态

三:Hadoop分布式集群HA模式部署
补充:访问该Federation(两个NameNode主机)

hdfs://Federation名称/目录/文件
可以配置多个Federation进行访问(相当于多个集群)
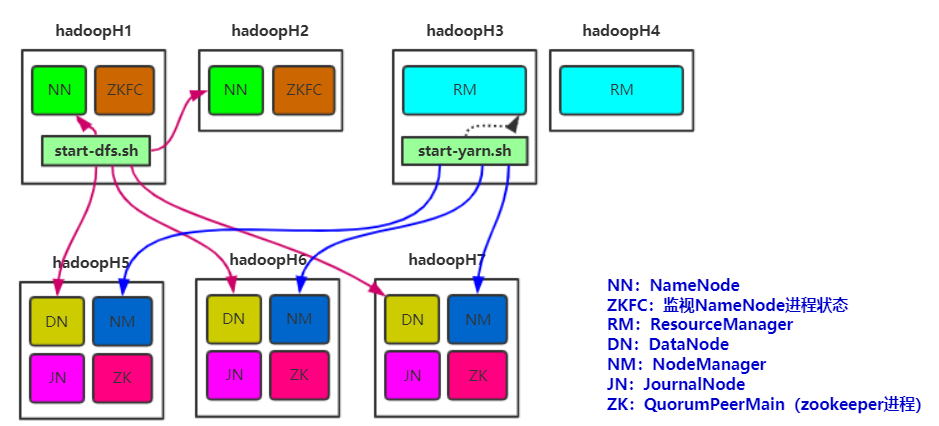
(一)集群机器数分配
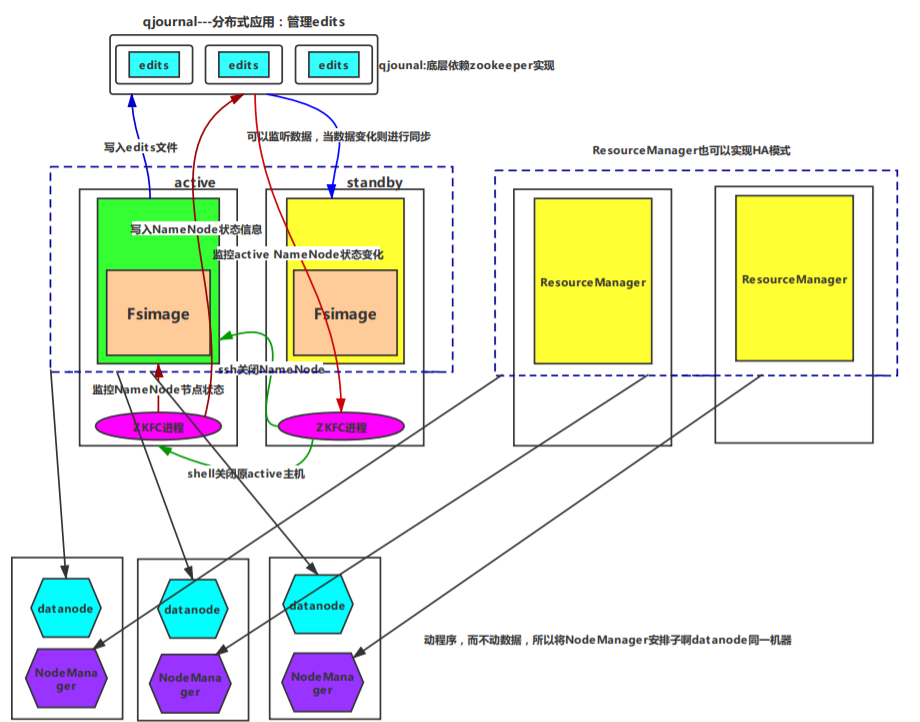
由于zookeeper配置节点与datanode节点无相干性,所以可以进一步将两者放在同一个机器中!
同样,可以对机器节点数再次进行精简
(二)集群规划
主机名 IP 安装的软件 运行的进程
hadoopH1 192.168.58.100 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
hadoopH2 192.168.58.101 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
hadoopH3 192.168.58.102 jdk、hadoop ResourceManager
hadoopH4 192.168.58.103 jdk、hadoop ResourceManager
hadoopH5 192.168.58.104 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
hadoopH6 192.168.58.105 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
hadoopH7 192.168.58.106 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
(三)zookeeper配置文件
修改zoo.cfg文件
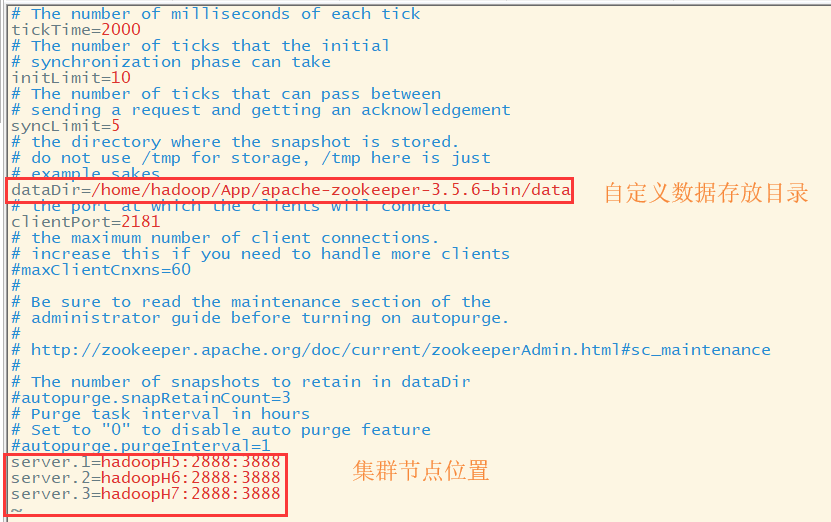
修改myid文件内容
修改各个机器中zookeeper主目录下data目录下的myid内容,对应主机的id
(四)hadoop配置文件
安装zookeeper和Hadoop按照上面配置和以前文章,修改hadoop-env.sh等文件也是按照以前文章配置。下面只讲HA集群所需要修改的
1.修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/App/jdk1..0_80
2.修改core-site.xml文件
<configuration>
<!-- 指定hdfs的nameservice为ns1 --> 指定Federation名称
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.7.1/tmp</value>
</property> <!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoopH5:2181,hadoopH6:2181,hadoopH7:2181</value>
</property>
</configuration>
3.修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoopH1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoopH1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoopH2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoopH2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置,指定zookeeper节点位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoopH5:8485;hadoopH6:8485;hadoopH7:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.7.1/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/home/App/hadoop/fenceshell/ensure.sh) <!--如果ssh目标主机出错,则ssh没有返回结果,所以配置shell很有必要,可以改变自己的状态-->
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
4.修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoopH3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoopH4</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoopH5:2181,hadoopH6:2181,hadoopH7:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定yarn web访问地址,否则查看application实例信息,出现链接错误-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoopH3:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoopH4:8088</value>
</property>
</configuration>
6.修改slaves
其中start-dfs.sh会去调用core-site.xml获取NameNode信息,本地登陆NamdNode节点,调用slaves文件获取DataNode信息,远程登陆DataNode节点(需要输入密码)。
(slaves是指定子节点的位置,因为要在hadoopH1上启动HDFS、在hadoopH3启动yarn,所以hadoopH1上的slaves文件指定的是datanode的位置,hadoopH3上的slaves文件指定的是nodemanager的位置)
hadoopH5
hadoopH6
hadoopH7
7.配置免密码登陆
其中start-yarn.sh启动hadoopH3,是使用本地启动,不需要远程登陆 hadoopH4的启动需要手动启动,可以修改start-yarn文件使得同start-dfs一样可远程启动备用节点
(1)首先要配置hadoopH1到hadoopH1、hadoopH2、hadoopH5、hadoopH6、hadoopH7的免密码登陆
在hadoopH1中产生一个密钥
ssh-keygen -t rsa
将公钥拷贝到其他节点,包括自己:
ssh-copy-id hadoopH1
ssh-copy-id hadoopH2
ssh-copy-id hadoopH5
ssh-copy-id hadoopH6
ssh-copy-id hadoopH7
(2)配置hadoopH3到hadoopH5、hadoopH6、hadoopH7的免密码登陆
在hadoopH3上生产一对钥匙
ssh-keygen -t rsa
将公钥拷贝到其他节点
ssh-copy-id hadoopH5
ssh-copy-id hadoopH6
ssh-copy-id hadoopH7
(3)两个namenode之间要配置ssh免密码登陆,别忘了配置hadoopH2到hadoopH1的免登陆
在hadoopH2上生产一对钥匙
ssh-keygen -t rsa
将公钥拷贝到HadoopH1
ssh-copy-id -i hadoopH1
(五)将配置好的Hadoop拷贝到其他节点
四:集群启动
(一)启动zookeeper集群(分别在hadoopH5、hadoopH6、hadoopH7上启动zk)
cd /home//hadoop/App/apache-zookeeper-3.5.6-bin/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status



(二)启动journalnode(分别在hadoopH5、hadoopH6、hadoopH7上执行)
cd /home//hadoop/App/hadoop-2.7.1/sbin./hadoop-daemon.sh start journalnode
#运行jps命令检验,hadoopH5、hadoopH6、hadoopH7上多了JournalNode进程



(三)格式化HDFS
#在hadoopH1上执行命令:
hadoop namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置,生成一些文件,我们需要将这个目录下的文件拷贝到standby状态的namenode节点下
可以使用scp -r 命令 例:scp -r ./data/ hadoopH2:/home/hadoop/App/hadoop-2.7.1/
##也可以这样,建议在另一个standby节点机器运行:hadoop namenode -bootstrapStandby

(四)格式化ZKFC(在hadoopH1上执行即可)
hdfs zkfc -formatZK

会在zookeeper集群上生成节点
(五)启动HDFS(在hadoopH1上执行)
start-dfs.sh
(六)启动YARN(在hadoopH3、4上都需要执行)
注意:是在hadoopH3上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
在hadoopH3中使用:start-yarn.sh 在hadoopH4中使用:yarn-daemon.sh start resourcemanager


补充:HA集群中namenode连接不上journalnode,导致namenode启动不了
补充:由于多次格式化导致文件上传出错File***could only be replicated to 0 nodes instead of minReplication (=1)
五:集群启动后验证
(一)节点进程查看
hadoopH1:

hadoopH2:
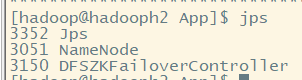
hadoopH3:

hadoopH4:

hadoopH5:

hadoopH6:
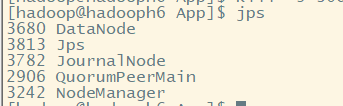
hadoopH7:
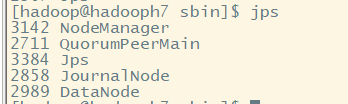
注意:有可能出现集群中datanode节点部分不能启动
直接删除不能启动的节点的集群下namenode和datanode节点存放数据的目录下的数据。再从hadoopH1中再次执行start-dfs.sh即可。
(二)通过浏览器访问
http://192.168.58.100:50070
NameNode 'hadoopH1:9000' (active)
http://192.168.58.101:50070
NameNode 'hadoopH2:9000' (standby)

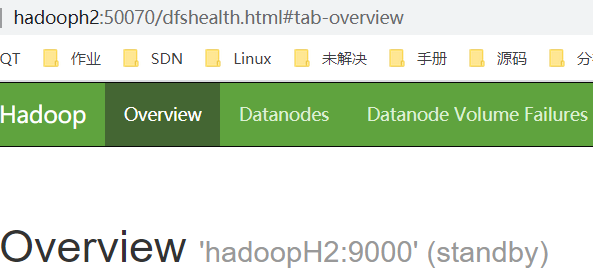
(三)验证HDFS HA
1.首先向hdfs上传一个文件
hadoop fs -mkdir /test
hadoop fs -put jdk-8u241-linux-x64.tar.gz /test/
hadoop fs -ls /

2.然后再kill掉active的NameNode
kill - <pid of NN>
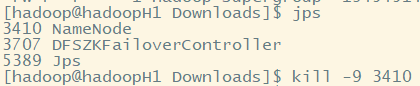
3.通过浏览器访问:http://192.168.58.101:50070
NameNode 'hadoopH2:9000' (active) 这个时候hadoopH2上的NameNode变成了active
4.再执行命令:查看文件
hadoop fs -ls /
刚才上传的文件依然存在!!!
5.手动启动那个挂掉的NameNode
hadoop-daemon.sh start namenode
通过浏览器访问:http://192.168.1.201:50070
NameNode 'hadoopH1:9000' (standby)
(四)验证YARN
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /wordcount/input /wordcount/output
六:hadoop datanode节点超时时间设置
(一)配置项解释
datanode进程死亡或者网络故障造成datanode无法与namenode通信,
namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。
HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的
heartbeat.recheck.interval的单位为毫秒,
dfs.heartbeat.interval的单位为秒。
所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
(二)hdfs-site.xml中的参数设置格式:
<property>
<name>heartbeat.recheck.interval</name>
<value></value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value></value>
</property>
(三)结果测试
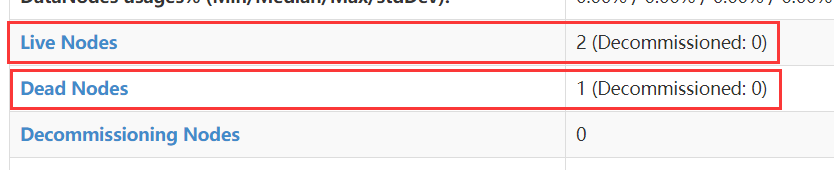
先kill一个datanode节点:
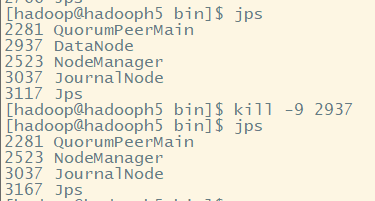
结果查看:

七:HDFS冗余数据块的自动删除
注意:要生成冗余块,则必须设置文件block副本数大于等于2---即一个datanode失效后还存在一个副本,当一个新的节点加入,则会进行数据拷贝!!!
修改hdfs-site.xml文件文件:
<property>
<name>dfs.replication</name>
<value></value> 伪分布指定一个即可
</property>
(一)配置项解释
在日常维护hadoop集群的过程中发现这样一种情况:
某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,
HDFS马上自动开始数据块的容错拷贝;
当该节点重新添加到集群中时,由于该节点上的数据其实并没有损坏,
所以造成了HDFS上某些block的备份数超过了设定的备份数。
通过观察发现,这些多余的数据块经过很长的一段时间才会被完全删除掉,
那么这个时间取决于什么呢?
该时间的长短跟数据块报告的间隔时间有关。
Datanode会定期将当前该结点上所有的BLOCK信息报告给Namenode,
参数dfs.blockreport.intervalMsec就是控制这个报告间隔的参数。
(二)hdfs-site.xml文件中有一个参数:
<property>
<name>dfs.blockreport.intervalMsec</name>
<value></value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
其中3600000为默认设置,3600000毫秒,即1个小时,也就是说,块报告的时间间隔为1个小时,所以经过了很长时间这些多余的块才被删除掉。通过实际测试发现,当把该参数调整的稍小一点的时候(60秒),多余的数据块确实很快就被删除了。
(三)在六的基础上,启动一个新的datanode节点,加入集群
hadoop-daemon.sh start datanode

注意:该节点也是需要配置到namenode节点的slave文件中,需要保持该datanode节点VERSION中集群号同namenode节点VERSION集群号一致。

(四)恢复被kill的datanode节点
hadoop-daemon.sh start datanode
八:HA的Java API访问
只需要修改路径,其他操作基本一致。
以HDFS上传文件为例:
package cn.hadoop.ha; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; public class HdfsUtilHA {
public static void main(String[] args) throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://ns1/"), conf, "hadoop");
fs.copyFromLocalFile(new Path("C:\\eula.1028.txt"), new Path("hdfs://ns1/"));
}
}
注意:要将core-site.xml和hdfs-site.xml放入项目src目录下。

分布式集群HA模式部署的更多相关文章
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
- LVS负载均衡集群--NAT模式部署
目录: 一.企业群集应用概述 二.负载均衡群集架构 三.负载均衡群集工作模式分析 四.关于LVS虚拟服务器 五.NAT模式 LVS负载均衡群集部署 一.企业群集应用概述 1.群集的含义 Cluster ...
- LVS负载均衡集群--DR模式部署
目录: 一.LVS-DR数据包流向分析 二.DR 模式的特点 三.LVS-DR中的ARP问题 四.DR模式 LVS负载均衡群集部署 一.LVS-DR数据包流向分析 1.为方便进行原理分析,将clien ...
- mongo分布式集群搭建手记
一.架构简介 目标 单机搭建mongodb分布式集群(副本集 + 分片集群),演示mongodb分布式集群的安装部署.简单操作. 说明 在同一个vm启动由两个分片组成的分布式集群,每个分片都是一个PS ...
- mongodb分布式集群搭建手记
一.架构简介 目标单机搭建mongodb分布式集群(副本集 + 分片集群),演示mongodb分布式集群的安装部署.简单操作. 说明在同一个vm启动由两个分片组成的分布式集群,每个分片都是一个PSS( ...
- Ambari安装之部署3个节点的HA分布式集群
前期博客 Ambari安装之部署单节点集群 其实,按照这个步骤是一样的.只是按照好3个节点后,再做下HA即可. 部署3个节点的HA分布式集群 (1)添加机器 和添加服务的操作类似,如下图 之后的添加a ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
随机推荐
- 菜鸡发现腾讯视频bug
腾讯视频bug 我看一个将夜,出现三生三世? 这是为啥? 发现bug,会得到奖励吗? 不会像dnf一样游戏自己的bug,然后出现伤害999,把我号封了. 我这样会被封号吗?我应该怎么做才不会被封?好慌 ...
- java中list的sort()功能如何使用?如果倒序如何正序?
list.sort()接收一个Comparable接口,其中compare方法是必须实现的,int compare(T o1, T o2);,它接受两个参数:o1,o2. o2表示list排序前的前值 ...
- 《C/C++实现Console下的加载进度条模拟[美观版]》
前言 有时候我们会遇到在CMD或DOS控制台上出现的加载进度条,虽然不是如网页和软件写的美观.但确确实实也有着自己的特色.而且,一个好看的加载进度条也能增加用户使用控制台程序的体验!所以,拿来研究 ...
- 安装python 第三方库(whl,py格式)
注意:在python环境中输入 help('modules') 可以列出所有已经安装的模块 1.windows平台下: 1..1安装whl文件 安装 ...
- PWA(Progressive web apps),渐进式 Web 应用
学习博客:https://www.jianshu.com/p/098af61bbe04 学习博客:https://www.zhihu.com/question/59108831 官方文档:https: ...
- 0226 rest接口设计
背景 为了更方便的书写和阐述问题,文章中按照第一人称的角度书写.作为一个以java为主要开发语言的工程师,我所描述的都是java相关的编码和设计. 工程师的静态输出就是代码和文 ...
- [Contract] Solidity address payable 转换与数组地址
address payable --> address address payable addr1 = msg.sender; address addr2 = addr1; // 隐式转 a ...
- 【查阅】Chrome快捷键
高频简要Chrome快捷键整理 记录一下Chrome常用快捷键方便查询熟悉,提高工作效率. 在我认为比较高频有用的快捷键,会加粗和标记. 在日常中熟练使用快捷键能帮助我们提高工作效率. 一 .F区单键 ...
- python基础之字典功能
python中字典是个很重要的功能,使用键值(key-value)存储,具有极快的查找速度.值得注意的是,字典的key要为不可变对象,比如字符串.字母,但不能是可变的,比如列表等. 1.字典的定义: ...
- PHP操作mysql(mysqli + PDO)
[Mysqli面向对象方式操作数据库] 添加.修改.删除数据 $mysqli ','test'); $mysqli->query('set names utf8'); //添加数据 $resul ...