IO流(字节流,字符流)
一,概述
IO流(input output):用来处理设备之间的数据。
Java对数据的操作是通过流的对象。
Java用于操作流的对象都在IO包中。
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
二,IO流的分类
根据处理数据类型的不同分为:字符流和字节流
根据数据流向不同分为:输入流和输出流
1.1 字符流和字节流
字符流的由来:在早期IO包中存在的都是字节流,因为无论是内存还是硬盘中的文件,它们都是以字节的形式传输或保存。随着编码技术的不断提高,人们陆续创造出了不同的编码表,【如:ASCII(美国信息交换标准代码),gb2312, GBK, unicode(国际标准码表:无论哪个字符都用两个字节表示),utf-8(国际标准码表的优化表:根据字符使用的字节长度来调整字节位数)】,但是当存储数据的计算机和取出数据的计算机使用的编码表不同时,就会造成取出数据的乱码情况。
为了解决这个乱码问题,Java就在字节流的基础上产生了一个字符流,而这个字符流的好处就是当读取数据时可以自己指定编码表。
字节流和字符流的区别:
(1)读写单位不同:字节流以字节(8bit)为单位。字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
字节流:一次读入或读出是8位二进制,分别操作字节和字节数组。字符流:一次读入或读出是16位二进制,分别操作字符,字符数组或字符串。
(2)处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
(3)字节流在操作的时候本身是不会用到缓冲区的,是文件本身的直接操作的;而字符流在操作的时候是会用到缓冲区的,是通过缓冲区来操作文件。(因为一个字符通常是由两个字节组成的,所以当读取了一个字节时,无法查找正确的字符)
结论:只要是处理纯文本数据,就优先考虑使用字符流, 除此之外建议使用字节流。但字节流是通用的。
字节流的抽象基类:InputStream OutputStream
字符流的抽象基类:Reader Writer
注意:由这四个类派生出来的子类名称都是以其父类作为子类名的后缀。
如:InputStream的子类FileInputStream
Reader的子类FileReader
1.2 输入流和输出流
对输入流只能进行读操作,对输出流只能进行写操作,程序中需要根据待传输数据的不同特性而使用不同的流。
三,Java IO体系

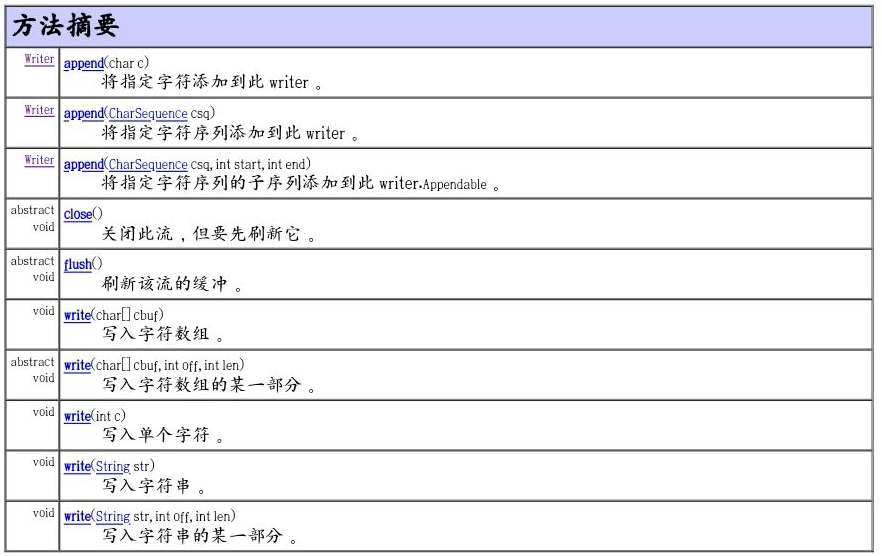
1.1字符流writer
Writer 写入字符流的抽象类。
它的子类有:
BufferedWriter 是一个装饰器为Writer 提供缓冲功能。
CharArrayWriter、StringWriter 是两种基本的介质流,它们分别向Char 数组、String 中写入数据。
FilterWriter 过滤器
PipedWriter 是向与其它线程共用的管道中写入数据,
PrintWriter 和PrintStream 极其类似,功能和使用也非常相似。
OutputStreamWriter 是OutputStream 到Writer 转换的桥梁,它的子类FileWriter 其实就是一个实现此功能的具体类(具体可以研究一SourceCode)。功能和使用和OutputStream 极其类似,后面会有它们的对应图。
构造函数:

方法:
【演示案例】:在硬盘上创建一个文件并写入一些文字数据。
分析:因为是写操作,所以找到一个专门用于操作文件的Writer子类对象,FileWriter,(后缀名是父亲名,前缀名是该流对象的功能)
import java.io.FileWriter;
import java.io.IOException;
public class WriterDome {
public static void main(String[] args) throws IOException {
//创建一个FileWriter对象,该对象一被初始化就必须要明确被操作的文件。
//并且该文件会被创建到指定目录下,如果该目录下已有同名文件,将会被覆盖。
FileWriter fw=new FileWriter("C:\\html\\demo.txt");
fw.write("abcde");
//调用write方法,将字符串写入流中
fw.flush();
//调用flush方法,刷新流对象的缓冲中的数据,将数据刷到目的地。
fw.close();
//调用close方法,关闭流资源,但关闭之前会刷新一次内部缓冲中的数据。
}
}
字符流的异常处理
上述案例中所有的异常都只是进行了抛出处理,这样是不合理的。所以上述代码并不完善,因为异常没有处理。当我们打开流,读和写,关闭流的时候都会出现异常,异常出现后,后面的代码都不会执行了,因此我们要进行异常处理。
异常处理的方法:使用try{} catch(){}finally{}语句。try中放入可能出现异常的语句,catch是捕获异常对象,fianlly是一定要执行的代码
要注意使用try进行异常处理时,将close()方法放在finally中,假设没有放,那么当打开和操作流出现了异常,显然close方法就不会再执行,而导致关闭流失败。
同时还要注意,关闭多个流时,为了避免一个流关闭失败而导致另一个流也无法关闭的情况,所以要将各个流的关闭分别写在不同的try语句中。
【演示案例】: IO异常处理的方式:
import java.io.FileWriter;
import java.io.IOException;
public class WriterDome {
public static void main(String[] args) {
FileWriter fw=null;
try{
fw=new FileWriter("C:\\html\\demo.txt");
fw.write("abcdeljl");
fw.flush(); }catch (IOException e){
System.out.println("写失败");
}
finally {//finally中的代码不管前面try中的代码是否执行成功,finally中的代码总会执行。因此将关闭流的代码放在finally中
try{
fw.close();
}catch (IOException e){
System.out.println("关闭失败");
}
}
}
}
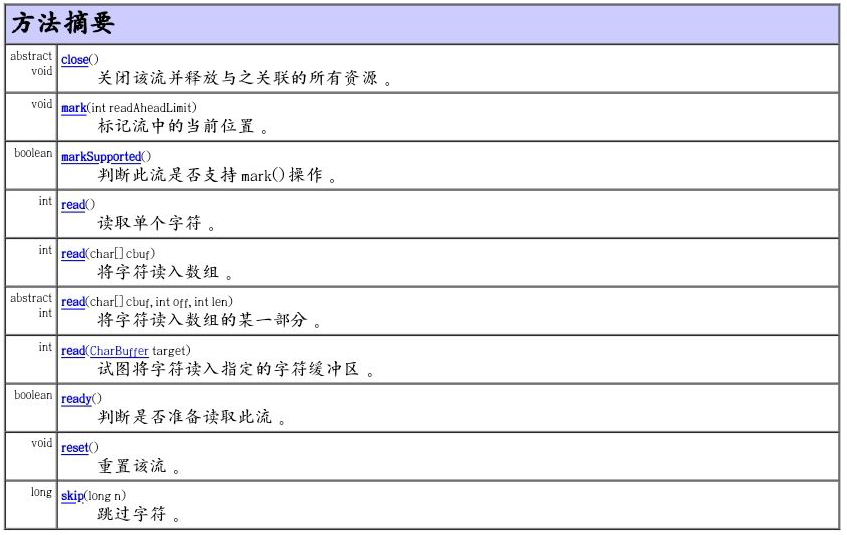
1.2字符流 Reader
Reader 是所有读取字符流的父类,它是一个抽象类。
它的子类有:
BufferedReader 很明显就是一个装饰器,它和其子类(LineNumberReader)负责装饰其它Reader 对象。
CharReader、StringReader是两种基本的介质流,它们分别将Char 数组、String中读取数据。PipedReader 是从与其它线程共用的管道中读取数据。
FilterReader 是所有自定义具体装饰流的父类,其子类PushbackReader 对Reader 对象进行装饰,会增加一个行号。
InputStreamReader 是一个连接字节流和字符流的桥梁,它将字节流转变为字符流。
FileReader可以说是一个达到此功能、常用的工具类,在其源代码中明显使用了将FileInputStream 转变为Reader 的方法。我们可以从这个类中得到一定的技巧。
Reader 中各个类的用途和使用方法基本和InputStream 中的类使用一致。后面会有Reader 与InputStream 的对应关系。
构造函数:

方法:
read方法():一次读取一个字符,读到文件末尾返回-1.
注意:该方法返回的是本次读取到的字符的int形式。所以打印时需有将其转化成char类型。
read(char[] b) 方法:使用缓冲区(关键是缓冲区大小的确定),使用read方法的时候,是将读到的数据装入到字符数组中,然后一次性的操作数组,可以提高效率,流需要读一次就处理一次,因为本次读取的数据会覆盖上次读取的。
注意:该方法返回的是本次读取到的字符的个数。
read(char[] b,int off,int len):查看api文档,b显然是一个char类型数组,当做容器来使用。off,是指定从数组的什么位置开始存字节。len,希望读多少个,其实就是把数组的一部分当做流的容器来使用。告诉容器,从什么地方开始装要装多少。
【演示案例】:从文件中读取内容
import java.io.FileReader;
import java.io.IOException; public class ReaderDemo {
public static void main(String[] args) throws IOException {
FileReader fr=new FileReader("c:\\html\\demo.txt");
/**
* 一次读一个字符。
*/
int ch1=0;//因为read()方法返回的int型数据,所以定义一个int型数据接收
while ((ch1=fr.read())!=-1){
// 调用read()方法,该方法返回的是本次读到的字符的整数型,当本次没有读到字符时,返回的是-1
System.out.println((char) ch1); //强转成char类型
} /**
* 一次读多个字符。
*/
char[] buf=new char[1024];//定义一个字符
int num=0;
while ((num=fr.read(buf))!=-1){
//调用read(char[] ch)方法,将读到的字符都存到ch数组中,该方法返回的是本次读到的字符的个数
//当本次没有读到字符时,返回的是-1
System.out.print(new String(buf,0,num));//将数组中的数据输出
}
fr.close(); }
}
【演示案例】:将C盘的一个文本文档复制到D盘。
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException; public class CopyTxt {
public static void main(String[] args) throws IOException {
FileReader fr=new FileReader("c:\\html\\demo.txt");
FileWriter fw=new FileWriter("D:\\demo\\demo.txt");
char[] buf=new char[1024];
while (fr.read(buf)!=-1){
fw.write(buf);//fw.write(buf,0,num);
fw.flush();
}
fr.close();
fw.close();
}
}
1.3字符缓冲流对象
缓冲区的出现提高了对数据的读写效率,其要结合流才可以使用,所以在创建缓冲流对象之前,必须先有流对象。它是在流的基础上对流的功能进行了增强,或者也可以说是对流对象的装饰。
缓冲流:
上述程序中我们为了提高流的使用效率,自定义了字符数组,作为缓冲区.Java其实提供了专门的字符流缓冲来提高效率.BufferedWriter和BufferedReader
BufferedWriter和BufferedReader类可以通过减少读写次数来提高输入和输出的速度。它们内部有一个缓冲区,用来提高处理效率。查看API文档,发现可以指定缓冲区的大小。其实内部也是封装了字符数组。
显然缓冲区输入流和缓冲区输出流要配合使用。首先缓冲区输入流会将读取到的数据读入缓冲区,当缓冲区满时,缓冲输出流会将数据写出。
注意:当然使用缓冲流来进行提高效率时,对于小文件可能看不到性能in的提升。但是文件稍微大一些的话,就可以看到实质的性能提升了。
缓冲流对象类:BufferedWriter (后缀是父类,前缀是功能)
BufferedReader
缓冲区的原理:1、使用了底层流对象从具体设备上获取数据,并将数据存储到缓冲区的数组内。
2、通过缓冲区的read()方法从缓冲区获取具体的字符数据,这样就提高了效率。
3、如果用read方法读取字符数据,并存储到另一个容器中,直到读取到了换行符时,将另一个容器临时存储的数据转成字符串返回,就形成了readLine()功能。
【演示案例】:模拟BufferedReader的底层代码
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader; class MyBufferedReaderDemo {
private Reader r=null;
public MyBufferedReaderDemo(Reader r){
this.r=r;
}
public String myreadLine() throws IOException {
int str=0;
//定义一个临时容器,原BufferedReader中封装的是字符数组。
//但为了演示方便,此处定义了一个StringBuilder容器。
StringBuilder sb=new StringBuilder();
while ((str=r.read())!=-1){
if (str=='\r') continue;
if (str=='\n') return sb.toString();
sb.append((char)str);
}
if (sb.length()!=0)return sb.toString();
return null;
} public void myclose() throws IOException {
r.close();
}
}
public class MyBufferedReader{
public static void main(String[] args) throws IOException{
FileReader fr=new FileReader("c:\\html\\demo.txt");
MyBufferedReaderDemo mbur=new MyBufferedReaderDemo(fr);
String str=null;
while ((str=mbur.myreadLine())!=null){
System.out.println(new String(str));
}
mbur.myclose();
}
}
上述代码说明,1.BufferedReader中调用的read()方法是来自FileReader的。
2.只要关闭BufferedReader,就关闭了FileReader流对象,是因为在BufferedReader的close方法中,已经调用了FileReader的close方法。
3.BufferedReader就是FileReader流对象的装饰器,其实在BufferedReader中真正操作文件的还是FileReader。
1.3.1 字符流的缓冲区对象BufferedWriter
public class BufferedWriter extends Writer
(1)将文本写入字符输出流(一个数组中),缓冲各个字符,从而提供单个字符、数组和字符串的高效写入。
(2)可以指定缓冲区的大小,或者接受默认的大小。在大多数情况下,默认值就足够大了。
(3)该类在基类的基础上提供了 newLine() 方法,因为并非所有平台都使用换行符 ('\r\n') 来终止各行。因此调用此方法来终止每个输出行,使代码具有跨平台性。
(4)通常 Writer 将其输出立即发送到底层字符或字节流。除非要求提示输出,否则建议用 BufferedWriter 包装所有其 write() 操作可能开销很高的 Writer(如 FileWriters 和 OutputStreamWriters)。例如,
PrintWriter out
= new PrintWriter(new BufferedWriter(new FileWriter("foo.out")));
(5)缓冲 PrintWriter 对文件的输出。如果没有缓冲,则每次调用 print() 方法会导致将字符转换为字节,然后立即写入到文件,而这是极其低效的。
【演示案例】:创建文件并写入内容。
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException; public class BufferWeiterDemo {
public static void main(String[] args) throws IOException {
//创建一个字符写入流对象
FileWriter fw=new FileWriter("c:\\html\\demo.txt");
//为了提高字符写入流的效率,加入缓冲技术。
//将需要提高效率的流对象作为参数提供给缓冲区的构造函数。
BufferedWriter buw=new BufferedWriter(fw); for (int i = 0; i <5; i++) {
buw.write("aaa"+i);
buw.newLine();//作用等同于buw.write("\r\n");但是\r\n只是Windows系统的换行符,因此不具有跨平台性
buw.flush(); //写一次刷新一次,防止意外
}
buw.close();
//关闭缓冲区就是在关闭缓冲区中的流对象
//因为真正实现写操作的是FileWriter对象,真正与文件相关联的也是FileWriter对象
}
}
1.3.2 字符流的缓冲区对象BufferedReader
public class BufferedReader extends Reader
(1)从字符输入流(一个作为缓冲区的数组)中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。
(2)可以指定缓冲区的大小,或者可使用默认的大小。大多数情况下,默认值就足够大了。
(3)在基类的基础上提供了readLine()方法(底层调用了read()方法),读取一个文本行,返回该行内容的字符串,不包括任何终止符。如果已到达流末尾,则返回null。
(4)通常,Reader 所作的每个读取请求都会导致对底层字符或字节流进行相应的读取请求。因此,建议用 BufferedReader 包装所有其 read() 操作可能开销很高的 Reader(如 FileReader 和 InputStreamReader)。例如,
BufferedReader in
= new BufferedReader(new FileReader("foo.in"));
(5)将缓冲指定文件的输入。如果没有缓冲,则每次调用 read() 或 readLine() 都会导致从文件中读取字节,并将其转换为字符后返回,而这是极其低效的。
【演示案例】:通过缓冲区从C盘复制文件到D盘。
import java.io.*;
public class BufferReaderDemo {
public static void main(String[] args) throws IOException {
//创建一个字符读取流对象
FileReader fr=new FileReader("c:\\html\\demo.txt");
//创建一个字符写入流对象
FileWriter fw=new FileWriter("D:\\Demo\\demo.txt");
//为了提高字符流的效率,加入缓冲技术。
//将需要提高效率的流对象作为参数提供给缓冲区的构造函数。
BufferedReader bur=new BufferedReader(fr);
BufferedWriter buw=new BufferedWriter(fw);
String str=null;
while ((str=bur.readLine())!=null){
buw.write(str,0,str.length());
buw.newLine();//因为readLine()方法读取的字符不包括换行符。
buw.flush();
}
bur.close();
buw.close();
}
}
1.3.3字符流的缓冲区对象BufferedWriter 的子类LineNumberReader
它是对缓冲区对象BufferedWriter的功能进行了增强, 是可以跟踪行号的缓冲字符输入流,此类定义了方法setLineNumber()和getLineNumber(),它们分别用于设置和获取当前行号。
setLineNumber()方法:设置当前行号。默认情况下是从0开始的。
getLineNumber()方法:获取当前行号。
【演示案例】:字符流的缓冲区对象BufferedWriter 的子类LineNumberReader
import java.io.FileReader;
import java.io.IOException;
import java.io.LineNumberReader; public class LineNumberReaderDemo {
public static void main(String[] args) throws IOException {
FileReader fr=new FileReader("c:\\html\\demo.txt");
LineNumberReader lnr=new LineNumberReader(fr);
String str=null;
lnr.setLineNumber(100);
while ((str=lnr.readLine())!=null){
System.out.println(lnr.getLineNumber()+":"+str);
}
lnr.close();
}
}
【演示案例】:模拟LineNumberReader的底层代码
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader; class MyLineNumberReader extends BufferedReader{
private int linenumber=0;
//private Reader r;
public MyLineNumberReader(Reader r){
super(r);
}
public void setLinenumber(int i){
this.linenumber=i;
}
public int getLinenumber(){
return linenumber;
}
/*public void close() throws IOException {
super.close();
}*///已被父类实现
public String readLine() throws IOException{
linenumber++;
return super.readLine();
}
}
public class MyLineNumberReaderDemo {
public static void main(String[] args) throws IOException{
FileReader fr=new FileReader("c:\\html\\demo.txt");
MyLineNumberReader mlnr=new MyLineNumberReader(fr);
String str=null;
mlnr.setLinenumber(100);
while ((str=mlnr.readLine())!=null){
System.out.println(mlnr.getLinenumber()+":"+str);
}
mlnr.close();
}
}
1.4字节流InputStream
- InputStream 是所有的输入字节流的父类,它是一个抽象类。
- ByteArrayInputStream、StringBufferInputStream、FileInputStream 是三种基本的介质流,它们分别从Byte 数组、StringBuffer、和本地文件中读取数据。
- PipedInputStream 是从与其它线程共用的管道中读取数据,与Piped 相关的知识后续单独介绍。
- ObjectInputStream 和所有FilterInputStream 的子类都是装饰流(装饰器模式的主角)。

1.4.1字节流对象FileInputStream
public class FileInputStream extends InputStream
用于从文件系统中的某个文件中读取诸如图片,视频,音频之类数据的原始字节流,若要读取字符流,请考虑使用FileReader。

【演示案例】:使用字节流对象读取文件。
import java.io.FileInputStream;
import java.io.IOException; public class FileInputStreamDemo {
public static void main(String[] args) throws IOException { /**
*一次读取一个字节
*/
FileInputStream fis=new FileInputStream("c:\\html\\demo.txt");
int num=0;
while ((num=fis.read())!=-1){
System.out.print((char)num);
}
//因为字节流对象是读一个写一个,所以不存在刷新
fis.close(); /**
* 一次读取多个字节:方法一
*/
FileInputStream fis=new FileInputStream("c:\\html\\demo.txt");
byte[] buf=new byte[1024];//注意:字符流读入的是char[]数组,而字节流读入的是byte[]数组
int num=0;
while ((num=fis.read(buf))!=-1){
System.out.println(new String(buf,0,num));
}
//因为字节流对象是读一个写一个,所以不存在刷新
fis.close(); /**
* 一次读取多个字节:方法一
*/
FileInputStream fis=new FileInputStream("c:\\html\\demo.txt");
int num=fis.available();//返回字节的个数
byte[] buf=new byte[num];//注意:字符流读入的是char[]数组,而字节流读入的是byte[]数组
fis.read(buf);
System.out.println(new String(buf));
//因为字节流对象是读一个写一个,所以不存在刷新
fis.close();
}
}
【演示案例】:使用字节流对象复制图片。
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException; public class CopyPicture {
public static void main(String[] args) throws IOException {
FileInputStream fis=new FileInputStream("c:\\html\\picture.png");
FileOutputStream fos=new FileOutputStream("D:\\demo\\picture.png");
byte[] buf=new byte[1024];
int len=0;
while ((len=fis.read(buf))!=-1){
fos.write(buf,0,len);
}
fis.close();
fos.close(); }
}
1.4.2字节缓冲流BufferedInputStream(装饰)
public class BufferedInputStream extends FilterInputStream
该类为另一个输入流添加一些功能,即缓冲输入以及支持mark和reset方法的能力。在创建BufferedInputStream时会创建一个数组。在读取或跳过流中的字节时,可根据需要从包含的输入流再次填充该内部缓冲区,一次填充多个字节。mark操作记录输入流中的某个点,reset操作使得在从包含的输入流中获取新字节之前,在此读取自最后一次mark操作后读取的所有字节。

【演示案例】:模拟BufferedInputStream底层代码。
1 import java.io.*;
2 class MyBufferedInputStream {
3 private InputStream ins;
4 private int pos=0;
5 private int count=0;
6 private byte[] buf=new byte[1024];
7 public MyBufferedInputStream(InputStream in){
8 this.ins=in;
9 }
10 public int read() throws IOException{
11 if(count==0){
12 count=ins.read(buf);
13 pos=0;
14 }
15 if(count<0) {
16 return -1;
17 }
18 byte b=buf[pos++];
19 count--;
20 return b&255;
21 }
22 public void close()throws IOException{
23 ins.close();
24 }
25 }
26
27 public class FileOutputStreamDemo {
28 public static void main(String[] args) throws IOException {
29 FileOutputStream fos=new FileOutputStream("D:\\demo\\demo.txt");//写
30 FileInputStream fis=new FileInputStream("c:\\html\\demo.txt");//读
31 BufferedOutputStream bos=new BufferedOutputStream(fos);
32 MyBufferedInputStream bis=new MyBufferedInputStream(fis);
33 int buff=0;
34 while ((buff=bis.read())!=-1){
35 bos.write(buff);
36 bos.flush();
37 }
38 bis.close();
39 bos.close();
40 }
41 }
我们知道字节流对象一般读取到的都是一个字节,那为什么read()方法返回的为什么不是byte而是int呢?这是因为字节流对象读取的音频或图片文件,其中数据在底层都是以二进制的形式存储的,但是当字节流对象读取到的某个字节是11111111(8个1)时,转化成十进制就是-1,这与我们判断结束的条件是相同的(while ((num=bis.read(buf))!=-1){}),此时系统就会认为该文件内容已经读取完而停止继续读取,因而造成数据丢失。为了解决这种情况,就将需要返回的数据转化(提升)为int型数据(从一个字节提升为四个字节),并与上255,之后在返回。那为什么要与上255?这是因为byte型-1转化为int型后还是-1,但是与上255(或0xff)之后,数据大小没有变,且解决了-1的问题。
-1的问题解决了,那我们又不得不思考另一个问题,我们每次读取时,都读到的是一个字节,但是返回时返回的是四个字节,这样读取到的文件不就成原来文件的四倍了?所以为了解决这个问题,我们在调用写功能时,其底层又进行了强转(向下转型),因此就解决了文件扩大的问题。
【代码演示】:打印文件中出现次数最多的三个数。
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
public class FindNumber {
public static void main(String[] args) throws IOException {
BufferedReader br=new BufferedReader(new FileReader("c:\\html\\test\\1317.txt"));//将文件加载到输入流中
String num=null;
HashMap<Integer,Integer> hashMap=new HashMap();//定义集合存储键值对,出现的数字作为Key,出现数字的次数作为Value
while ((num=br.readLine())!=null){ //一次读取一行数据
String[] str= num.split(",");//以逗号将各个数字分隔开,分好后的数据存储到数组中
for (String number:str) {//遍历数组
Integer key=Integer.valueOf(number);//因为数组是String类型,所以取出数据后将其元素转化为Interger类型
if (hashMap.containsKey(key)){//对集合进行判断
hashMap.put(key,hashMap.get(key)+1);
}else {
hashMap.put(key,1);
}
}
}
System.out.println(hashMap);
//借用PrioritrQueue的特点,将集合中的数组导入PrioritrQueue中
//重写compare方法,让PrioritrQueue中的元素按从大到小的顺序排列
Comparator<Map.Entry<Integer,Integer>> comparator=new Comparator<Map.Entry<Integer, Integer>>(){
@Override
public int compare(Map.Entry<Integer,Integer> o1, Map.Entry<Integer,Integer> o2) {
return o2.getValue()-o1.getValue();
}
};
PriorityQueue<Map.Entry<Integer,Integer>> priorityQueue=new PriorityQueue(comparator);
Iterator<Map.Entry<Integer,Integer>> iterator=hashMap.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<Integer,Integer> entry=iterator.next();
priorityQueue.add(entry);
}
System.out.println(priorityQueue);
for (int i = 0; i <3; i++) {
Map.Entry<Integer,Integer> entry=priorityQueue.poll();
System.out.println("出现的数字:"+entry.getKey()+" 出现次数:"+entry.getValue());
}
}
}
运行结果:

1.5.输出字节流OutputStream
- OutputStream 是所有的输出字节流的父类,它是一个抽象类。
- ByteArrayOutputStream、FileOutputStream 是两种基本的介质流,它们分别向Byte 数组、和本地文件中写入数据。PipedOutputStream 是向与其它线程共用的管道中写入数据,
- ObjectOutputStream 和所有FilterOutputStream 的子类都是装饰流。
1.5.1字节流对象FileOutputStream
public class FileOutputStream extends OutputStream
用于将某个文件中诸如图片,视频,音频之类数据的原始字节流写入到另一个文件中。

write(int b)方法,一次写出一个字节.
注意:使用write(int b)方法,虽然接收的是int类型参数,但是write 的常规协定是:向输出流写入一个字节。要写入的字节是参数 b 的八个低位。b 的 24 个高位将被忽略。
write(byte[] b),就是使用缓冲.提高效率.查找API文档,将 b.length 个字节从指定的 byte 数组写入此输出流中。
补充:
调用上述方法往文件里写数据,运行多次就会发现,程序每运行一次,老的内容就会被覆盖掉。那么如何不覆盖已有信息,能够往文件里追加信息呢。查看API文档,发现FileOutputStream类中的构造方法中有一个构造可以实现追加的功能FileOutputStream(File file, boolean append) 第二个参数,append - 如果为 true,则将字节写入文件末尾处,而不是写入文件开始处。
问题1: 使用缓冲(字节数组)拷贝数据,拷贝后的文件大于源文件的问题.
测试该方法,拷贝文本文件,仔细观察发现和源文件不太一致。
打开文件发现拷贝后的文件和拷贝前的源文件不同,拷贝后的文件要比源文件多一些内容问题就在于我们使用的容器,这个容器我们是重复使用的,新的数据会覆盖掉老的数据,显然最后一次读文件的时候,容器并没有装满,出现了新老数据并存的情况。所以最后一次把容器中数据写入到文件中就出现了问题。
那么如何避免?使用FileOutputStream 的write(byte[] b, int off, int len)
b 是容器,off是从数组的什么位置开始,len是获取的个数,容器用了多少就写出多少。
1.5.2字节缓冲流 BufferedOutputStream (装饰)
public class BufferedOutputStream extends FilterOutputStream
该类实现缓冲的输出流。通过设置这种输出流,应用程序就可以将各个字节写入底层输出流中,而不必针对每次字节写入调用底层系统。

【演示案例】:使用字节流缓冲对象复制文件。
import java.io.*;
public class FileOutputStreamDemo {
public static void main(String[] args) throws IOException {
FileOutputStream fos=new FileOutputStream("D:\\demo\\demo.txt");//写
FileInputStream fis=new FileInputStream("c:\\html\\demo.txt");//读
BufferedOutputStream bos=new BufferedOutputStream(fos);
BufferedInputStream bis=new BufferedInputStream(fis);
byte[] buf=new byte[];
int num=;
while ((num=bis.read(buf))!=-){
bos.write(buf,,num);
}
bis.close();
bos.close();
}
}
1.6.读取键盘录入
System类包含一些有用的类字短和方法。它不能被实例化。
(InputStream ) 字段in:“标准”输入流 。此流已打开并准备提供输入数据。通常,此流对应于键盘输入或有主机环境或用户指定的另一个输入源。
(OutputStream-PrintStream) 字段out:“标准”输出流。此流已打开棒准备接受输出数据。通常,此流对应于显示器输出或者由主机环境或用户指定的另一个输出目标。
方法:
setIn(InputStream in):重新分配标准输入流。
setout(PrintStream out):重新分配标准输出流。
【演示案例】:通过键盘录入数据。
public class SystemDemo {
public static void main(String[] args)throws IOException {
InputStream in=System.in;//in对象
int num=in.read();//read方法一次只接受一个字节
int num1=in.read();
int num2=in.read();
System.out.println(num);
System.out.println(num1);
System.out.println(num2);
}
}
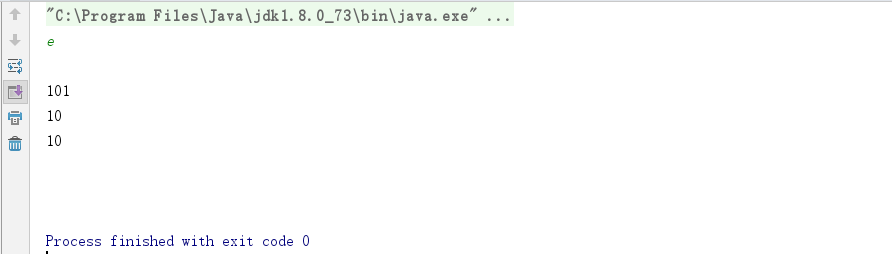
注意:此处只输入了一个字母,却打印出三个数字,说明在windows系统中,换行符是存在的(\r \t)。
【演示案例】:setIn()和setOut()方法的使用。
import java.io.*;
public class SystemDemo {
public static void main(String[] args)throws IOException { System.setIn(new FileInputStream("c:\\html\\demo.txt"));
System.setOut(new PrintStream("D:\\demo\\demo.txt"));
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));//源为键盘录入
BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(System.out));
//目的为c盘文件
String str=null;
while ((str=br.readLine())!=null){
if("over".equals(str))
break;
bw.write(str);
bw.newLine();//换行
bw.flush();
}
br.close();
bw.close();
}
}
1.7 转换流对象(键盘录入,转换编码表)
1.7.1 InputStreamReader是字节流通向字符流的桥梁:
它使用指定的charset读取字节并将其解码为字符。
它使用的字符集可以由名称指定或显示给定,或者可以接受平台默认的字符集。
public class InputStreamReader extends Reader

【演示案例】:通过键盘录入数据(为编码简单,将字节流对象转化为字符流对象)。
import java.io.*;
public class SystemDemo {
public static void main(String[] args)throws IOException {
//获取键盘录入对象
InputStream in=System.in;
//将字节流对象转化为字符流对象,使用:InputStreamReader
//为了提高效率,使用字符缓冲对象。
BufferedReader br=new BufferedReader(new InputStreamReader(in)); //in取代了文件,之前是读取文件中的,现在是读取键盘输入的
String str=null;
while ((str=br.readLine())!=null){
if ("over".equals(str)){
break;
}
System.out.println(str);
}
}
}
1.7.2 OutputStreamWriter是字符流通向字节流的桥梁:它使用指定的charset将要写入流中的字符编码成字节。
public class OutputStreamWriter extends Writer

【演示案例】:通过控制台显示数据(为编码简单,将字符流对象转化为字节流对象)。
import java.io.*;
public class SystemDemo {
public static void main(String[] args)throws IOException {
//获取控制台显示对象
OutputStream out=System.out;
//将字符流对象转化为字字流对象,使用:OutputStreamWriter
//为了提高效率,使用字节缓冲对象。
BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(out));//之前是往文件里写,现在是往控制台写
String str=null;
bw.write("abcd");
bw.flush();//因为是字符中,所以要刷新
bw.close();
}
}
【演示案例】:将键盘录入的信息存储到指定文件中。
import java.io.*;
public class SystemDemo {
public static void main(String[] args)throws IOException {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));//源为键盘录入
BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(new FileOutputStream("c:\\html\\demo.txt"),“utf-8"));
//目的为c盘文件
String str=null;
while ((str=br.readLine())!=null){
if("over".equals(str))
break;
bw.write(str);
bw.newLine();//换行
bw.flush();
}
br.close();
bw.close();
}
}
注意:InputStreamReader可以自定义编码方式,但是它的子类FileReader中不可以自定义,默认为GBK。
【演示案例】:编写异常日志文件。
import java.io.*;
import java.util.Date; public class IOExectionDemo {
public static void main(String[] args) {
try{
int[] arr=new int[];
System.out.println(arr[]);//此处数组越界
}catch (ArrayIndexOutOfBoundsException e){
try{
PrintStream ps=new PrintStream("C:\\html\\execption.txt"); Date d=new Date() ;
//ps.println(d.toString());//同ps.write(d.toString().getBytes()); System.setOut(ps);
//因为此处可能会出现找不到文件异常所以也要进行扑获
//setOut()方法指定输出流,此处指定为C盘的文本文件
e.printStackTrace(System.out);
//printStackTrace()方法的作用是将异常信息输出到指定的输出流中,默认为控制台
}catch (FileNotFoundException fe){
throw new RuntimeException("日志文件创建失败");
}
}
}
}
1.8 打印流(PrintWriter 和PrintStream)
1.8.1PrintStream:
打印字节流,为其他输出流添加了功能,使他们能够方便地打印各种数据值表现形式。与其他输出流不同的是,PrintStream永远不会抛出IOException,异常情况仅设置可通过checkError方法测试的内部标志。另外,PrintStream还支持自动刷新,也意味着PrintStream可通过调用其中的一个print方法,在写入byte数组之后自动调用flush方法,或者也以通过写入一个换行符或字节(‘\n’)。
注意:PrintStream打印的所有字符都使用平台的默认字符编码转换为字节,在需要写入字符而不是字节的情况下,应使用PrintWiter类。
PrintStream是OutputStream类的子类,在OutputStream类中write()方法只接受传进来的参数的最低八位,为了不改变数据原样性,于是在它的子类PrintStream中不仅提供了write()写的方法,还提供了println()打印的方法,该方法的好处是可以传进来的数据进行直接操作,可以在打印时保证数据的原样性。
构造函数:
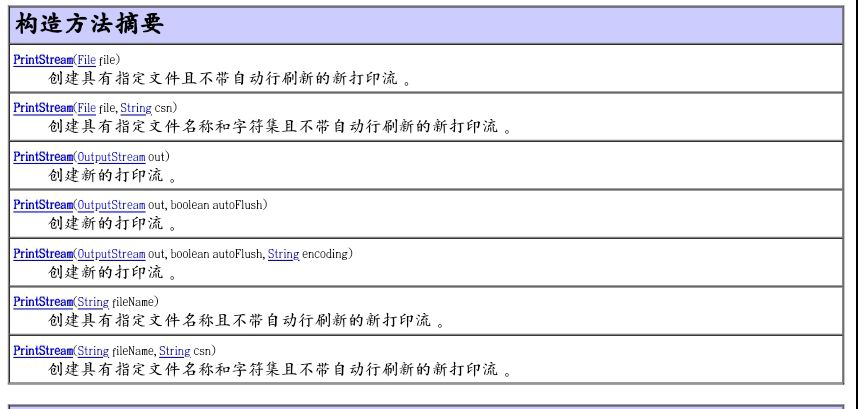
方法:<拥有PrintStream中除write方法外的所有方法。>

import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream; public class PrintStreamDemo {
public static void main(String[] args) throws IOException {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
PrintStream ps=new PrintStream(System.out);
String str;
while ((str=br.readLine())!=null){
ps.println(str);
}
br.close();
ps.close();
}
}
不用调用fiush就可以自动刷新。输入一行,显示一行。

1.8.2PrintWriter:
打印字符流, 向文本输出流打印对象的格式化表现形式,此类实现了PrintStream中的所有print方法。与PrintStream不同的是,如果启动了自动刷新,则只有在调用println,printf或format方法中的一个方法时,才能完成刷新的操作,而不是每当正好输出换行符才完成,这些方法使用平台自有的行分隔符概念,而不是换行符。
构造函数:

方法:


【代码演示】
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter; public class PrintWriteDemo {
public static void main(String[] args) throws IOException {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
PrintWriter pw=new PrintWriter(System.out);
String str;
while ((str=br.readLine())!=null){
pw.println(str);
pw.flush();
}
br.close();
pw.close();
}
}
PrintWriter默认情况下是不带自动刷新功能的,要通过调用flush方法才能实现刷新功能。另外查看Api文档可知,PrintStream还可以通过构造函数来设置自动刷新的功能。(但只有在调用println,printf或format方法时才能自动刷新)
PrintWriter pw=new PrintWriter(OutputStream os , boolean flag);
PrintWriter pw=new PrintWriter(Writer w , boolean flag);
public class PrintWriteDemo {
public static void main(String[] args) throws IOException {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
PrintWriter pw=new PrintWriter(System.out,true);//注意刷新是对流而言的,如果前面是文件的路径就会报错。必须要将其封装成流对象才可,new File("c:\\html\\test\\d.txt")
String str;
while ((str=br.readLine())!=null){
pw.println(str);
}
br.close();
pw.close();
}
}
1.9序列流(SequenceInputStream)
是InputStream的子类,表示其他输入流的逻辑串联。它从输入流的有序集合开始,并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。
在这之前一个流只能跟一个文件结合,但有了SequenceInputStream类之后,通过SequenceInputStream可以实现一个流跟多个文件结合。应用实例,将多个文件的内容写到一个文件中。
构造函数:

【代码演示】:需要将多个文件(两个以上)合并到一个文件中时。
import java.io.*;
import java.util.Enumeration;
import java.util.Vector; public class SequenceDemo {
public static void main(String[] args) throws IOException {
// SequenceInputStream sis=new SequenceInputStream(new FileInputStream("C:\\html\\d.txt"),new FileInputStream("d:\\html\\d.txt"));
//当要结合的文件大于两个时,使用下面方法
Vector<InputStream> vi=new Vector<>();//先创建一个集合,用来装入多个文件
vi.add(new FileInputStream("c:\\html\\test\\1.txt"));
vi.add(new FileInputStream("c:\\html\\test\\2.txt"));
vi.add(new FileInputStream("c:\\html\\test\\3.txt"));
Enumeration<InputStream> en=vi.elements();//因为SequenceInputStream只接受Enumeration<InputStream>和InputStream类型数据
SequenceInputStream sis=new SequenceInputStream(en);
PrintStream ps=new PrintStream("c:\\html\\test\\4.txt");
byte[] buff=new byte[1024];
int num=0;
while ((num=sis.read(buff))!=-1){//SequenceInputStream的读取方法只能接收byte类型数组,但PrintStream和PrintWriter的print方法不接受byte类型
ps.write(buff,0,num);
//因为PrintWriter的print的方法是接受什么类型就操作什么类型,而此处buff数组是byte类型,因此要将其转为String类型
}
ps.close();
sis.close();
}
}
【代码演示】:将一个文件切割成多个文件。
import java.io.*;
public class SplitFileDemo {
public static void main(String[] args) throws IOException {
BufferedInputStream bos=new BufferedInputStream(new FileInputStream("c:\\html\\test\\1.txt"));//选择要读取的文件
byte[] buff=new byte[10];//定义缓冲区
for (int i = 10;bos.read(buff)!=-1; i++) {//通过for循环将文件进行分割
FileOutputStream fos=new FileOutputStream("c:\\html\\test\\"+i+".txt");
fos.write(buff);
fos.close();
}
bos.close();
}
运行之后文档的变化:
由于在存储文档时用Vector效率比较低,所以一般常会选用ArrayList来存储。
import java.io.*;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.Iterator; public class MergeDemo {
public static void main(String[] args) throws IOException {
ArrayList<InputStream> arrayList=new ArrayList<>(); //定义一个集合来存储要合并的文件
for (int i = 10; i <16 ; i++) {
arrayList.add(new FileInputStream("c:\\html\\test\\"+i+".txt"));
}
Iterator<InputStream> iterator=arrayList.iterator();//因为ArrayList没有返回类型为Enumeration的方法,但SequenceInputStream只接受Enumeration和InputStream类型的数据
Enumeration<InputStream> enumeration=new Enumeration(){ @Override
public boolean hasMoreElements() {
return iterator.hasNext();
} @Override
public Object nextElement() {
return iterator.next();
}
};
SequenceInputStream sis=new SequenceInputStream(enumeration);
FileOutputStream fos=new FileOutputStream("c:\\html\\test\\merge.txt");
byte[] buff=new byte[1024];
int num;
while ((num=sis.read(buff))!=-1){
fos.write(buff,0,num);
}
sis.close();
fos.close();
}
}
1.10 操作对象(ObjectInputStream和ObjectOutputStream)
我们一般情况下新new的对象都是在堆内存中存储的,随着程序运行结束,该对象就会被当作垃圾回收掉。但是ObjectStream流对象却可以将堆内存中的创建出来的对象(及其对象内封装的数据)存储到硬盘中,即使程序运行结束,该信息也不会被清除。而将创建出来的对象存储到硬盘上的这一动作称为对象的持久化存储,或者对象的序列化,可串行性。
作用
ObjectInputStream:将 Java 对象转换成字节序列(IO 字节流)
ObjectOutputStream --> 序列化 --> 写对象,将对象以 “ 二进制/ 字节 ” 的形式写到(文件)
ObjectOutputStream:对象反序列化 (DeSerialization),从字节序列中恢复 Java 对象
ObjectInputStream -->反序列化 -->读对象
序列化原因:序列化以后的对象可以保存到磁盘上,也可以在网络上传输,使得不同的计算机可以共享对象.(序列化的字节序列是平台无关的)
对象序列化的条件:只有实现了 Serializable 接口的类的对象才可以被序列化。Serializable 接口中没有任何的方法(标记接口),实现该接口的类不需要实现额外的方法。如果对象的属性是对象,属性对应类也必须实现 Serializable接口
1.10.1 ObjectOutputStream
ObjectOutputStream 将 Java 对象的基本数据类型和图形写入 OutputStream。可以使用 ObjectInputStream 读取(重构)对象。通过在流中使用文件可以实现对象的持久存储。如果流是网络套接字流,则可以在另一台主机上或另一个进程中读取(重构)对象。
只能将支持 java.io.Serializable 接口的对象写入流中。每个 serializable 对象的类都被编码,编码内容包括类名和类签名、对象的字段值和数组值,以及从初始对象中引用的其他所有对象的闭包。
writeObject 方法用于将对象写入流中。所有对象(包括 String 和数组)都可以通过 writeObject 写入。可将多个对象或基元写入流中。必须使用与写入对象时相同的类型和顺序从相应 ObjectInputstream 中读回对象。
还可以使用 DataOutput 中的适当方法将基本数据类型写入流中。还可以使用 writeUTF 方法写入字符串。
对象的默认序列化机制写入的内容是:对象的类,类签名,以及非瞬态和非静态字段的值。其他对象的引用(瞬态和静态字段除外)也会导致写入那些对象。可使用引用共享机制对单个对象的多个引用进行编码,这样即可将对象的图形恢复为最初写入它们时的形状。
构造函数

方法


write(int val)方法只操作一个字节的最末八位,writeInt(int val)操作一个字节的所有位数。
【代码演示】:使用文件实现对象的持久存储
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable; class Person implements Serializable {
String name;
int age;
Person(String name,int age){
this.name=name;
this.age=age;
}
@Override
public String toString() {
return this.name+":"+this.age;
}
}
public class ObjectStreamDemo {
public static void main(String[] args) throws IOException {
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("c:\\html\\test\\odj.txt"));
//因为ObjectOutputStream --> 序列化 --> 写对象,所以是将对象以 “ 二进制/ 字节 ” 的形式写到(文件),因此选用字节流
oos.writeObject(new Person("lisi",39));//注意只有实现了 Serializable 接口的类的对象才可以被序列化
//将对象写入流中,通过在流中使用文件实现对象的持久存储
oos.close();
}
}
注意:运行完后查看文件中的内容,会发现是一些乱码,这是因为创建出来的对象在往硬盘中存储时要进行序列化,因此在硬盘中存储的都是被序列化后的二进制码,而然用文件查看时,文件不会进行反序列化,而是直接根据编码表进行编译,因此编译出来的都是乱码。
1.10.2ObjectInputStream
ObjectOutputStream 将 Java 对象的基本数据类型和图形写入 OutputStream。可以使用 ObjectInputStream 读取(重构)对象。通过在流中使用文件可以实现对象的持久存储。如果流是网络套接字流,则可以在另一台主机上或另一个进程中重构对象。
只能将支持 java.io.Serializable 接口的对象写入流中。每个 serializable 对象的类都被编码,编码内容包括类名和类签名、对象的字段值和数组值,以及从初始对象中引用的其他所有对象的闭包。
writeObject 方法用于将对象写入流中。所有对象(包括 String 和数组)都可以通过 writeObject 写入。可将多个对象或基元写入流中。必须使用与写入对象时相同的类型和顺序从相应 ObjectInputstream 中读回对象。
还可以使用 DataOutput 中的适当方法将基本数据类型写入流中。还可以使用 writeUTF 方法写入字符串。
对象的默认序列化机制写入的内容是:对象的类,类签名,以及非瞬态和非静态字段的值。其他对象的引用(瞬态和静态字段除外)也会导致写入那些对象。可使用引用共享机制对单个对象的多个引用进行编码,这样即可将对象的图形恢复为最初写入它们时的形状。



【代码演示】:将对象从文件中读出来。
import java.io.FileInputStream;
import java.io.ObjectInputStream;
public class ObjectStreamDemo2 {
public static void main(String[] args) throws Exception {
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("c:\\html\\test\\obj.txt"));
Person person=(Person) ois.readObject();
System.out.println(person.toString());
ois.close();
}
}
运行结果:

这是读取的对象在存储到硬盘之后,没有修改过源代码的情况下运行出来的结果图。如果存储之后修改了源代码会发生什么,通过下图我们可以知道,它会报出错:Exception in thread "main" java.io.InvalidClassException: K3.Person; local class incompatible: stream classdesc serialVersionUID = -3862490733995989343, local class serialVersionUID = -1776203517460933646
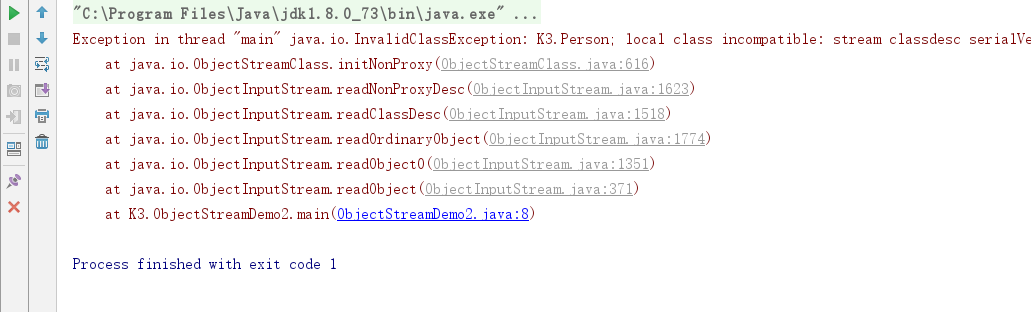
这是因为如果修改过对象的类,那么该对象的序列号就会发生变化,在从文件中读取对象时,因为前后两次序列号不一致就会导致读取失败。
那如果既想存储对象又想在存储之后还可以修改对象类的代码,那该怎么办??答案是自定义序列号!!在实现Serializable 接口的类的前面添加:public static final long serialVersionUID=23L;
class Person implements Serializable {
public static final long serialVersionUID=23L;//自定义序列号
String name;
int age;
Person(String name,int age){
this.name=name;
this.age=age;
}
public String toString() {
return this.name+":"+this.age;
}
}
注意:静态变量不能被序列化,因为静态变量是在方法区中存储的,而只有堆内存中的变量才会被序列化。
如果变量是非静态的,但是也不想进行序列化该怎么办??答案是用修饰符transient修饰变量!!要注意没有被序列化的变量是不会存储到文件中的,只会存储在堆内存中,并随程序运行完而被清除掉。
1.11 管道流(PipedInputStream和PipedOutputStream)
它们的作用是让多线程可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedOutputStream和PipedInputStream配套使用。使用管道通信时,大致的流程是:我们在线程A中向PipedOutputStream中写入数据,这些数据会自动的发送到与PipedOutputStream对应的PipedInputStream中,进而存储在PipedInputStream的缓冲中;此时,线程B通过读取PipedInputStream中的数据。就可以实现,线程A和线程B的通信。
管道输入流和管道输出流可以像管道一样对接上。要注意的是需要加入多线程技术,不建议对这两个对象尝试使用单个线程,这样可能死锁线程。因为在单线程中,先执行read,因为read方法是阻塞式的,没有数据的read方法会让线程一直等待,从而发生死锁。
管道输入流应该连接到管道输出流,管道输出流是管道的发送端。通常,数据由某个线程写入到相应的 PipedOutputStream中,并由其他线程从 PipedInputStream 对象读取。管道输入流包含一个缓冲区,可在缓冲区限定的范围内将读操作和写操作分离开。 如果向连接管道输出流提供数据字节的线程不再存在,则认为该管道已损坏。
连接管道的两种方法:1.通过构造函数PipedInputStream(PipedOutputStream pos)
2.通过方法connect(PipedOutputStream pos)
1.11.1PipedInputStream

1.11.1PipedOutputStream
【代码演示】
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream; //不建议对这两个管道流对象尝试使用单个线程,这样可能死锁线程,所以此处运用多线程
class Read implements Runnable{//读线程
private PipedInputStream in;
public Read(PipedInputStream in){
this.in=in;
}
@Override
public void run() {
try{
byte[] buff=new byte[1024];
int num;
while ((num=in.read(buff))!=-1){//返回的是字节数组
System.out.println(new String(buff,0,num));
}
}catch (IOException e){
System.out.println("读取失败");
}finally {
try{
in.close();
}catch (IOException ee){
System.out.println("读取失败");
}
}
}
}
class Write implements Runnable{//写线程
private PipedOutputStream out;
public Write(PipedOutputStream out){
this.out=out;
}
@Override
public void run() {
try{
out.write("写入的数据内容".getBytes());//注意写入的参数类型
}catch (IOException e2){
System.out.println("写入失败");
}finally {
try{
out.close();
}catch (IOException e22){
System.out.println("读取失败");
}
}
}
}
public class PipedStreamDemo {
public static void main(String[] args) throws IOException {
PipedInputStream pis=new PipedInputStream();//创建两个管道流
PipedOutputStream pos=new PipedOutputStream();
pis.connect(pos);//将两个管道流进行连接
Read r=new Read(pis);//创建两个线程
Write w=new Write(pos);
new Thread(r).start();//启动线程
new Thread(w).start();
}
}
分析运行过程:假设两个线程开启后,Read线程先抢到执行权,当Read线程执行到PipedIntputStream流的read方法时,因为PipedInputStream流中没有数据,所以Read线程因read方法读取数据失败而被阻塞,然后执行权被Write线程抢占,并通过PipedOutputStream的write方法将数据内容写到PipedInputStream流中,当Read线程重新抢到执行权时,就可继续执行read方法。
IO流(字节流,字符流)的更多相关文章
- IO流(字节流,字符流,缓冲流)
一:IO流的分类(组织架构) 根据处理数据类型的不同分为:字节流和字符流 根据数据流向不同分为:输入流和输出流 这么庞大的体系里面,常用的就那么几个,我们把它们抽取出来,如下图: 二:字符字节 ...
- IO 复习字节流字符流拷贝文件
/* 本地文件 URL 文件拷贝 *//*文本文件拷贝 可以通过 字符流,也可以通过字节流*/ /*二进制文件拷贝 只可以通过字节流*//* 希望这个例子能帮助搞懂 字符流与字节流的区别 */ imp ...
- Java之IO流(字节流,字符流)
IO流和Properties IO流 IO流是指计算机与外部世界或者一个程序与计算机的其余部分的之间的接口.它对于任何计算机系统都非常关键, 因而所有 I/O 的主体实际上是内置在操作系统中的.单独的 ...
- IO—》字节流&字符流
字节流 一.字节输出流OutputStream OutputStream此抽象类,是表示输出字节流的所有类的超类.操作的数据都是字节,定义了输出字节流的基本共性功能方法. FileOutputStre ...
- java 输入输出IO流 字节流| 字符流 的缓冲流:BufferedInputStream;BufferedOutputStream;BufferedReader(Reader in);BufferedWriter(Writer out)
什么是缓冲流: 缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率. 图解: 1.字节缓冲流BufferedInputStr ...
- -1-4 java io java流 常用流 分类 File类 文件 字节流 字符流 缓冲流 内存操作流 合并序列流
File类 •文件和目录路径名的抽象表示形式 构造方法 •public File(String pathname) •public File(String parent,Stringchild) ...
- java IO流 之 字符流
字符是我们能读懂的一些文字和符号,但在计算机中存储的却是我们看不懂的byte 字节,那这就存在关于字符编码解码的问题.所以在学习Io流的字符流前我们先了解些关于编码问题. 一.字符集与字符编码 1.什 ...
- java io流(字符流) 文件打开、读取文件、关闭文件
java io流(字符流) 文件打开 读取文件 关闭文件 //打开文件 //读取文件内容 //关闭文件 import java.io.*; public class Index{ public sta ...
- io系列之字符流
java中io流系统庞大,知识点众多,作为小白通过五天的视频书籍学习后,总结了io系列的随笔,以便将来复习查看. 本篇为此系列随笔的第一篇:io系列之字符流. IO流 :对数据的传输流向进行操作,ja ...
- JAVA之IO流(字符流)
字符流InputStreamReader和OutputStreamWriter是Writer和Read的子类:是字节流通向字符流的桥梁,也就是可以把字节流转化为字符流. InputStreamRead ...
随机推荐
- [bzoj4824][洛谷P3757][Cqoi2017]老C的键盘
Description 老 C 是个程序员. 作为一个优秀的程序员,老 C 拥有一个别具一格的键盘,据说这样可以大幅提升写程序的速度,还能让写出来的程序 在某种神奇力量的驱使之下跑得非常快.小 Q 也 ...
- Python-直接存储类实例作为序列的元素
如果我们需要存储的数据有很多属性,并且存储的数量很多,可选择定义一个类来表示数据类型,而类的实体作为单个的成员进行存储,这样做的好处是可以只存储一个容器,而不需要每次都存储大量的数据,并且可以限制对数 ...
- 演示共享布局 Demonstrating Shared Layouts 精通ASP-NET-MVC-5-弗瑞曼 Listing 5-10
- 定时任务莫名停止,Spring 定时任务存在 Bug??
Hello~各位读者新年好!这里楼下小黑哥给大家拜个年,祝大家蒸蒸日上烫烫烫,年年有余屯屯屯. 那年那 Bug 春节放假,小黑哥坐上高铁回家,突然想到一次生产问题.那是小黑哥参加工作第一年,那一年国庆 ...
- 对于kvm配置ssh
首先我们要让自己的机器开启ssh服务 首先更新源 sudo apt-get update 安装ssh服务 sudo apt-get install openssh-server 检测是否已启动 ps ...
- ubutun安装停留在界面
这几天都在折腾,都在出问题记录一下 ubuntu安装时停留在界面,怎么办解决方法:重新开机,光标选中“Install Ubuntu” ,按“e”,进入grub界面,将倒数第二行中的“quiet spl ...
- git使用的常见命令汇总
git的简单介绍 git是分布式版本控制工具 git 的基本操作指令 git init 初始化git仓库 git add 文件名 git add . 把文件 添加到 git 暂存区中 git stat ...
- Docker和Kubernetes
Docker和Kubernetes Docker Docker是一个容器的开放平台,但它不是最早的.自20世纪70年代以来,容器平台一直存在.他们的开发可以追溯到Unix中的chroot系统调用.在2 ...
- 浅显易懂的前端知识点(二)——HTTP协议基础
HTTP 协议的初印象: 是基于 TCP/IP 协议的应用层协议,不涉及数据包的传输,主要规定了客户端和服务器之间的通信格式,默认使用 80 端口. 1 HTTP 协议 0.9 版(1991 年) 是 ...
- HDU-5902-GCD is Funny解题笔记
Alex has invented a new game for fun. There are n integers at a board and he performs the following ...