linux大盘格式化分区
Linux 实例的磁盘管理
对于 Linux 系统上的大磁盘,也要采用 GPT 分区格式, 也可以不分区, 把磁盘当成一个整体设备使用。
在 Linux 上一般采用 XFS 或者 EXT4 来做大盘的文件系统。
磁盘的分区管理
在 Linux 上可以采用 parted 来对磁盘进行分区。
- 通过
fdisk -l可以查看磁盘是否存在, 由于使用的是大磁盘,fdisk 不能用来作为分区工具了,而应该使用 parted。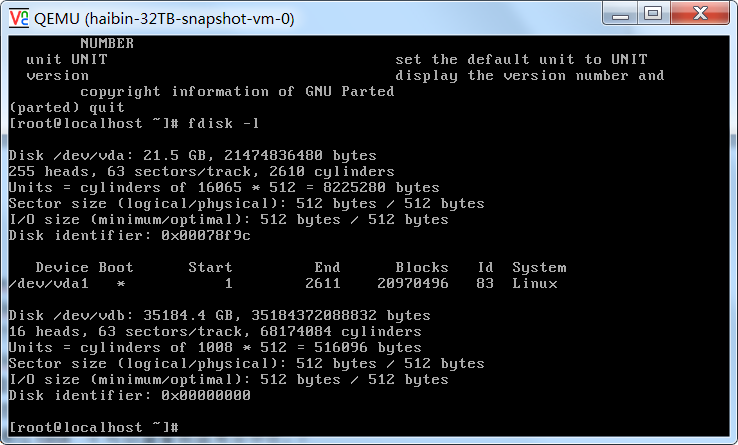
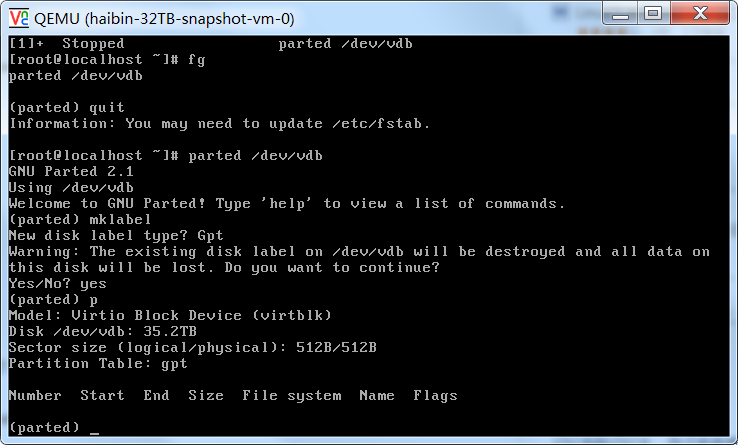
- 使用 parted 对 /dev/vdb 进行分区。首先创建分区表, 选择 GPT 格式的分区表。
parted /dev/vdb
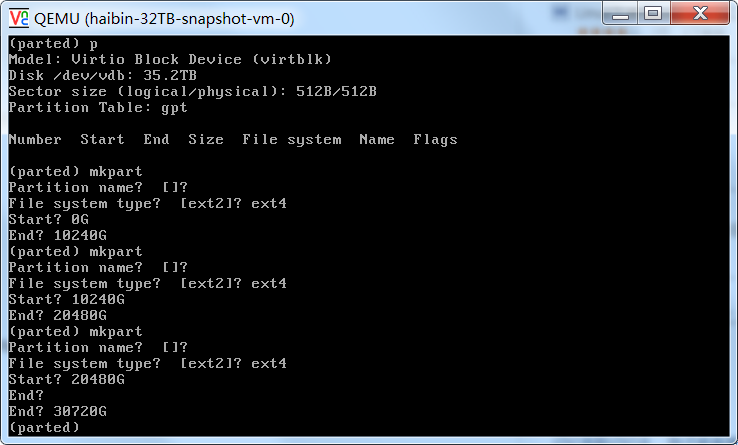
- 创建分区。
EXT4 文件系统格式化
假定 Linux 实例上的大数据盘设备为 /dev/vdb, 可以用如下方式来格式化。以下参数为常用参数, 用户可以根据自己的需要来调整。
/sbin/mke2fs –O 64bit,has_journal,extents,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize /dev/vdb1
下图为格式化 32TB 磁盘的示例, 格式化耗时 10~60 秒。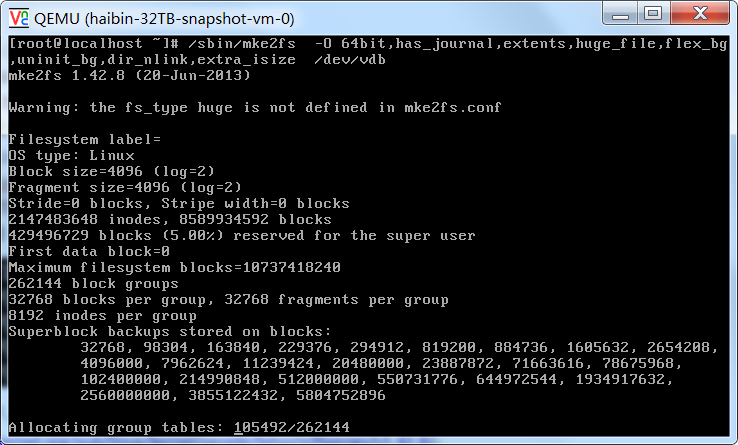
16TB 以上的大盘
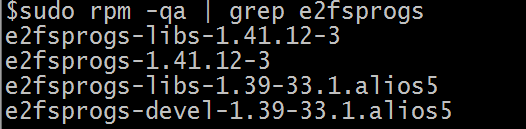
对于 16TB 以上的大盘, 对 ext4 格式化所用的工具包 e2fsprogs 的版本有要求。如果 e2fsprogs 版本太低, 比如:e2fsprogs 1.41.11,会出现如下错误信息:
mkfs.ext4: Size of device /dev/md0 too big to be expressed in 32 bits using a blocksize of 4096.
所以需要把 e2fsprogs 工具包的版本升级到 1.42 以上的版本, 比如:1.42.8。通过如下方式检查 e2fsprogs 的版本:
下载链接如下:
https://www.kernel.org/pub/linux/kernel/people/tytso/e2fsprogs/v1.42.8/
如下方式编译高版本的工具。
wget https://www.kernel.org/pub/linux/kernel/people/tytso/e2fsprogs/v1.42.8/e2fsprogs-1.42.8.tar.gztar xvzf e2fsprogs-1.42.8.tar.gzcd e2fsprogs-1.42.8./configuremakemake install
ext4 的 lazy init 期间对 IOPS 性能影响
ext4 文件系统有个 lazy init 的功能, 默认是打开的,这个功能会延迟 ext4 文件系统的 metadata 的初始化, 系统后台会发起一个线程持续地初始化 metadata。 所以实例在刚格式化的一段时间内IOPS 会受到影响,例如:对大盘的 IOPS 性能测试的数据就会明显偏低。
所以,如果用户需要在格式化以后马上对大盘的性能进行测试, 需要在格式化的时候取消 lazy_init 的功能。
/sbin/mke2fs –O 64bit,has_journal,extents,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize -E lazy_itable_init=0,lazy_journal_init=0 /dev/vdb1
取消 lazy init 以后,格式化的时间会大幅度的延长, 格式化 32TB 的磁盘可能会需要 10 分钟到 30 分钟。请您根据自身的需要选择是否使用 lazy init 的功能。
XFS 文件系统格式化
XFS 文件系统的格式化要比 ext4简单,默认的格式化命令如下:
mkfs –t xfs /dev/vdb1
在这里就不再叙述了,您可以自己根据需要来调节XFS的参数。
注意事项
不建议使用小盘快照创建大盘
虽然理论上是可以从一个小盘的快照来创建一个大盘, 但是我们不建议您这么做。建议您创建空的大盘。理由如下:
- 因为从小盘的快照创建大盘时, 系统只完成块设备级的磁盘扩容, 并没有实现分区格式和文件系统的自动转换。
- 如果小盘快照中使用的是 MBR 分区格式,以上提到的两种分区工具(Linux上的 parted 和 Windows上的磁盘管理)都无法提供在保留数据的情况下,从 MBR 格式转换为 GPT 格式。所以,就算用户从小盘快照创建了大盘,也需要把原有数据删除,再按照 GPT 格式分区。
如果小盘快照本身就是GPT分区格式,或者您另有强大的分区工具,则不在此列。您可以根据自身情况来选择。
磁盘快照的影响
大盘的数据量很大,而磁盘快照的速度和小盘是一样的, 所以每天用户打快照的时间会成与数据量比例地增长。打快照的速度和数据的增量成正比,脏数据越多, 快照的速度越慢。
linux大盘格式化分区的更多相关文章
- Linux 格式化分区 报错Could not stat --- No such file or directory 和 partprobe 命令
分区的过程正常: [root@db1 /]# fdisk -l Disk /dev/sda: 21.4 GB, 21474836480 bytes 255 heads, 63 sectors/tr ...
- Linux系统格式化新磁盘并挂载分区
Linux系统格式化新磁盘并挂载分区 在虚拟机的设置界面中,我们可以选择添加硬盘 添加好硬盘后,我们输入命令fdisk -l 看到有一个未经分区的硬盘 Fdisk命令编辑这个硬盘 输入n创建分区,p选 ...
- linux硬盘的分区、格式化、挂载以及LVM
linux硬盘的分区.格式化.挂载以及LVM 多块硬盘的组合: 硬盘分两种:ide和scsi. ide硬盘: /dev/hda 第一块IDE硬盘 /dev/hdb 第二块IDE硬盘 ... /de ...
- Linux 硬盘格式化、分区、挂载、卸载、删除分区,Linux重新调整分区
目录 Linux 硬盘格式化.分区.挂载.卸载.删除分区 0. 查看挂载情况 1. 查看硬盘信息 2. 创建分区 3. 查看磁盘信息 4. 格式化分区 5. 将分区信息写入fstab, 设置开机自动挂 ...
- linux中硬盘分区、格式化、挂载
已经接触了小半年的linux,基本命令用的还行,就是涉及到深入操作,就显得不够看了,比如linux中的硬盘操作,于是整理了这篇博客. 1. 主分区,扩展分区,逻辑分区的联系和区别 一个硬盘可以有1 ...
- Linux下磁盘分区,格式化以及挂载
测试环境:VMware Workstation / centos7 1.磁盘分区 (1)易于管理和使用: 比如说我们把磁盘分了sda1.sda2.sda3.sda4盘,我们假设sda1盘为系统盘,其他 ...
- Linux系统磁盘分区、删除分区、格式化、挂载、卸载、开机自动挂载的方法总结
Linux系统按照MBR(Master Boot Record)传统分区模式: 注意:传统的MBR(Master Boot Record)分区方式最大只能分2T容量的硬盘,超过2T的硬盘一般采用GPT ...
- 『学了就忘』Linux基础 — 13、Linux系统的分区和格式化
目录 1.Linux系统的分区 (1)磁盘分区定义 (2)两种分区表形式 (3)MBR分区类型 2.Linux系统的格式化 (1)格式化定义 (2)格式化说明 1.Linux系统的分区 (1)磁盘分区 ...
- linux 使用fdisk分区扩容
标签:fdisk分区 概述 我们管理的服务器可能会随着业务量的不断增长造成磁盘空间不足的情况,在这个时候我们就需要增加磁盘空间,本章主要介绍如何使用fdisk分区工具创建磁盘分区和挂载分区,介绍两种情 ...
随机推荐
- python 列表对象的增减
- Python基础:02数字
1:Python标准整数类型等价于C的(有符号)长整型.整数一般以十进制表示,但是Python也支持八进制或十六进制来表示整数.八进制整数以数字“0”开始, 十六进制整数则以“0x”或“0X”开始. ...
- ocilib linux编译安装
1.首先下载ocilib到自己目录 github:https://github.com/vrogier/ocilib 2.在下载instantclient 11.2.2的文件: instantclie ...
- 7-3三个模块 hashlib ,logging,configparser和序列化
一 hashlib 主要用于字符串加密 1 import hashlib md5obj=hashlib.md5() # 实例化一个md5摘要算法的对象 md5obj.update('alex3714' ...
- 基于TableStore的海量气象格点数据解决方案实战
前言 气象数据是一类典型的大数据,具有数据量大.时效性高.数据种类丰富等特点.气象数据中大量的数据是时空数据,记录了时间和空间范围内各个点的各个物理量的观测量或者模拟量,每天产生的数据量常在几十TB到 ...
- @bzoj - 4378@ [POI2015] Pustynia
目录 @description@ @solution@ @accepted code@ @details@ @description@ 给定一个长度为 n 的正整数序列 a,每个数都在 1 到 10^ ...
- poj 1716 Integer Intervals(差分约束)
1716 -- Integer Intervals 跟之前个人赛的一道二分加差分约束差不多,也是求满足条件的最小值. 题意是,给出若干区间,需要找出最少的元素个数,使得每个区间至少包含两个这里的元素. ...
- caffe 下一些参数的设置
weight_decay防止过拟合的参数,使用方式:1 样本越多,该值越小2 模型参数越多,该值越大一般建议值:weight_decay: 0.0005 lr_mult,decay_mult关于偏置与 ...
- 原生js用div实现简单的轮播图
文章地址 https://www.cnblogs.com/sandraryan/ 原生js实现轮播图. 打开页面图片自动轮播,点击prev next按钮切换到上/下一张图片,点击1-5切换到对应图片. ...
- poj 3572 Hanoi Tower
Hanoi Towers Time Limit : 10000/5000ms (Java/Other) Memory Limit : 131072/65536K (Java/Other) Total ...