【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库数据高性能数据导入迁移实践
SequoiaDB 一款自研金融级分布式数据库产品,支持标准SQL和分布式事务功能、支持复杂索引查询,兼容 MySQL、PGSQL、SparkSQL等SQL访问方式。SequoiaDB 在分布式存储功能上,较一般的大数据产品提供更多的数据切分规则,包括:水平切分、范围切分、主子表切分和多维切分方式,用户可以根据不用的场景选择相应的切分方式,以提高系统的存储能力和操作性能。
为了能够提供简单便捷的数据迁移和导入功能,同时更方便地与传统数据库在数据层进行对接,巨杉数据库支持多种方式的数据导入,用户可以根据自身需求选择最适合的方式加载数据。
本文主要介绍巨杉数据库集中常见的高性能数据导入方法,其中包括巨杉工具矩阵中的 Sdbimprt导入工具,以及使用SparkSQL, MySQL和原生API 接口进行数据导入,一共四种方式。
Sdbimprt工具导入
sdbimprt 是 SequoiaDB 的数据导入工具,是巨杉数据库工具矩阵中重要组成之一,它可以将 JSON 格式或 CSV 格式的数据导入到 SequoiaDB 数据库中。
关于工具说明与参数介绍,请参考:http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1479195620-edition_id-0。
一、示例
下面简单介绍一下如何使用 sdbimprt 工具将 csv 文件导入到 SequoiaDB 集合空间 site 的集合 user_info 中:1. 数据文件名称为“user.csv”,内容如下:
“Jack”,18,”China”“Mike”,20,”USA”
2.导入命令
sdbimprt --hosts=localhost:11810 --type=csv --file=user.csv -c site -l user_info --fields='name string default "Anonymous", age int, country'--hosts:指定主机地址(hostname:svcname)
--type:导入数据格式,可以是csv或json
--file:要导入的数据文件名称
-c(--csname):集合空间的名字
-l(--clname):集合的名字
--fields:指定导入数据的字段名、类型、默认值
二、导入性能优化
下面说明使用 sdbimprt 工具时如何提升导入性能:1. 使用 --hosts 指定多个节点导入数据时,尽量指定多个 coord 节点的地址,用“,”分隔多个地址,sdbimprt 工具会把数据随机发到不同机器上的 coord,起到负载均衡的作用(如图1)。

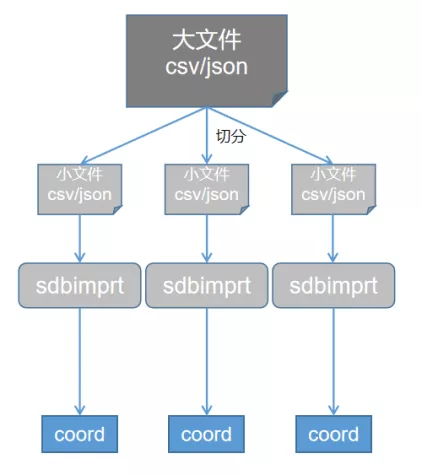
2. 使用 --insertnum(-n) 参数在导入数据时,使用 --insertnum(-n) 参数,可以实现批量导入,减少数据发送时的网络交互的次数,从而加快数据导入速度。取值范围为1~100000,默认值为100。 3. 使用 --jobs(-j) 参数指定导入连接数(每个连接一个线程),从而实现多线程导入。 4. 切分文件sdbimprt 在导入数据时支持多线程并发导入,但读数据时是单线程读取,随着导入线程数的增加,数据读取就成为了性能瓶颈。这种情况下,可以将一个大的数据文件切分成若干个小文件,然后每个小文件对应启动一个 sdbimprt 进程并发导入,从而提升导入性能。如果集群内有多个协调节点,分布在不同的机器上,那么可以在多台机器上分别启动 sdbimprt 进程,并且每个 sdbimprt 连接机器本地的协调节点,这样数据发送给协调节点时避免了网络传输(如图2)。
5. 数据加载完后再建索引对于导入数据量大,且索引多的表,建议先把索引删除,待到数据导入完成后再重建索引,这样有利于加快数据导入。在数据导入的过程中,如果目标表存在大量的索引,数据库除了写入数据外,还需要写入索引文件,这会降低导入数据的性能。此方式对提升其它方式的数据导入速度同样适用。
SparkSQL 导入
SparkSQL 可以方便的读取多种数据源,通过 SequoiaDB 提供的 Spark 连接器,可以使用 SparkSQL 向 SequoiaDB 中写入数据或从中读取数据
关于 SparkSQL 如何与 SequoiaDB 连接,请参考:http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1432190712-edition_id-0。
一、示例
下面举例说明如何将 HDFS 中的 csv 文件通过 SparkSQL 导入 SequoiaDB 集合中,以及如何优化导入性能。 1、将 HDFS 中 csv 文件映射成 spark 的临时表
CREATE TABLEhdfstableUSINGorg.apache.spark.sql.execution.datasources.csv.CSVFileFormatOPTIONS (path "hdfs://usr/local/data/test.csv",header "true")
2. 将 SDB 的集合映射成 spark 的临时表
create temporary table sdbtable (a string,b int,c date)usingcom.sequoiadb.sparkOPTIONS(host 'sdbserver1:11810,sdbserver2:11810,sdbserver3:11810',username 'sdbadmin',password 'sdbadmin',collectionspace 'sample',collection 'employee',bulksize '500');
3. 导入
sparkSession.sql("insert into sdbtable select * from hdfstable");二、导入性能优化
SparkSQL 数据写入有以下两个参数可以优化:
host
尽量指定多个 coord 节点的地址,用“,”分隔多个地址,数据会随机发到不同 coord 节点上,起到负载均衡的作用。
bulksize
该参数默认值为500,代表连接器向 SequoiaDB 写入数据时,以 500 条记录组成一个网络包,再向 SequoiaDB 发送写入请求,可以根据数据的实际大小调整 bulksize 的值。
MySQL 导入
SequoiaDB 以存储引擎的方式与 MySQL 对接,使得用户可以通过 MySQL 的 SQL 接口访问 SequoiaDB 中的数据,并进行增、删、改、查等操作。
关于如何与MySQL对接,请参考:
http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1521595283-edition_id-302。
一、示例
使用 mysql 向 SequoiaDB 导入数据有以下几种方式:1. SQL 文件导入
mysql> source /opt/table1.sql2. CSV 文件导入。mysql 中提供了 load data infile 语句来插入数据:
mysql> load data local infile '/opt/table2.csv' into table table2 fields terminated by ',' enclosed by '"' lines terminated by '\n';二、导入性能优化
提升MySQL的导入性能有如下建议:1. sequoiadb_conn_addr 指定多个地址引擎配置参数“sequoiadb_conn_addr”尽量指定多个coord节点的地址,用“,”分隔多个地址,数据会随机发到不同coord节点上,起到负载均衡的作用。
2. 开启 bulkinsert引擎配置参数“sequoiadb_use_bulk_insert”指定是否启用批量插入,默认值为“ON”,表示启用。配置参数“sequoiadb_bulk_insert_size”指定批量插入时每批的插入记录数,默认值2000。可以通过调整bulkinsert size提高插入性能。
3. 切分文件可以将一个大的数据文件切分为若干个小文件,然后为每个小文件启动一个导入进程,多个文件并发导入,提高导入速度。
API 接口导入
SequoiaDB 提供了插入数据的 API 接口,即“insert”接口。insert 接口会根据传入的参数不同而使用不同的插入方式,如果每次只传入一条记录,则接口也是将记录逐条的发送到数据库引擎,如果每次传入一个包含多条记录的集合或数组,则接口会一次性把这批记录发送到数据库引擎,最后通过引擎一条一条写入数据库中。
因此,insert 接口的两种插入方式的区别在于发送数据到数据库引擎这一过程,一次传入多条记录这种方式称为“bulkinsert”,相对来说会减少数据发送时的网络交互的次数,插入性能更佳。
小结如何达到最大数据加载速度,是数据库迁移/数据导入中常遇到的问题,本文从以下四个方面分别介绍了 SequoiaDB 数据迁移/导入过程中性能最优化的方法:1)基于巨杉工具矩阵 sdbimprt 导入可以采用修改参数 host 指定多个节点、修改连接数、切分文件、修改参数 insertnum、重建索引等等对数据导入速度进行优化。2)基于 MySQL 导入可以采用修改参数 host 地址及 bulksize 进行优化。3)基于 Spark 导入可以采用指定多个协调节点IP、设置 bulkinsert 参数、切分文件进行优化。 4)基于API接口进行优化可以采用 bulkinsert 批量插入数据,减少网络交互。
大家可以参考本文的数据导入方法进行实践验证,从传统数据库迁移到巨杉数据库SequoiaDB。
【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库数据高性能数据导入迁移实践的更多相关文章
- 【巨杉数据库SequoiaDB】24 Hours , 数据库研发实录
出场人物: 08:10 小H,是巨杉数据库引擎研发的一名工程师.7:20 天还蒙蒙亮,小H就起床了,点亮了心爱的光剑,开始了新的一天. 在08:10时候,他已经洗漱完,锻炼好身体,倒好 ...
- JindoFS解析 - 云上大数据高性能数据湖存储方案
JindoFS背景 计算存储分离是云计算的一种发展趋势,传统的计算存储相互融合的的架构存在一定的问题, 比如在集群扩容的时候存在计算能力和存储能力相互不匹配的问题,用户在某些情况下只需要扩容计算能力或 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 分布式数据库千亿级超大表优化实践
01 引言 随着用户的增长.业务的发展,大型企业用户的业务系统的数据量越来越大,超大数据表的性能问题成为阻碍业务功能实现的一大障碍.其中,流水表作为最常见的一类超大表,是企业级用户经常碰到的性能瓶颈. ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 四步走,快速诊断数据库集群状态
1.背景 SequoiaDB 巨杉数据库是一款金融级分布式数据库,包括了分布式 NewSQL.分布式文件系统与对象存储.与高性能 NoSQL 三种存储模式,分别对应分布式在线交易.非结构化数据和内容管 ...
- 【巨杉数据库Sequoiadb】点燃深秋,巨杉数据库亮相DTC数据技术嘉年华大会
2019年11月15日,第九届数据技术嘉年华大会在北京隆重召开,本次大会以 “开源 • 智能 • 云数据 - 自主驱动发展 创新引领未来” 为主题,探索数据价值,共论智能未来.SequoiaDB 巨 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库的并发 malloc 实现
本文由巨杉数据库北美实验室资深数据库架构师撰写,主要介绍巨杉数据库的并发malloc实现与架构设计.原文为英文撰写,我们提供了中文译本在英文之后. SequoiaDB Concurrent mallo ...
- 【巨杉数据库SequoiaDB】社区分享 | SequoiaDB + JanusGraph 实践
本文来自社区用户投稿,感谢小伙伴的技术分享 项目背景 大家好!在春节这段时间里,由于一直在家,所以花时间捣鼓了一下代码,自己做了 SequoiaDB 和 JanusGraph 的兼容扩展工作. 自己觉 ...
- 【巨杉数据库SequoiaDB】为“战疫” 保驾护航,巨杉在行动
2020年,我们经历了一个不平静的新春,在这场大的“战疫”中,巨杉数据库也积极响应号召,勇于承担新一代科技企业的社会担当,用自己的行动助力这场疫情防控阻击战! 赋能“战疫”快速响应 巨杉数据库目前服务 ...
- 【巨杉数据库SequoiaDB】省级农信国产分布式数据库应用实践
本文转载自<金融电子化> 原文链接:https://mp.weixin.qq.com/s/WGG91Rv9QTBHPsNVPG8Z5g 随着移动互联网的迅猛发展,分布式架构在互联网IT技术 ...
随机推荐
- 获取tensorflow中变量的值
names=[i.name for i in tf.all_variables()]for i in names: print i ker=tf.get_default_graph().get_ten ...
- Linux运维--15.OpenStack vm使用keepalived 实现负载均衡
外接mariadb集群 实现负载均衡 实验环境 10.0.1.27 galera1 10.0.1.6 galera2 10.0.1.23 galera3 10.0.1.17 harpoxy1 hapr ...
- NServiceBus 入门到精通(一)
什么是NServiceBus?NServiceBus 是一个用于构建企业级 .NET系统的开源通讯框架.它在消息发布/订阅支持.工作流集成和高度可扩展性等方面表现优异,因此是很多分布式系统基础平台的理 ...
- Cesium案例解析(四)——3DModels模型加载
目录 1. 概述 2. 代码 3. 解析 4. 参考 1. 概述 Cesium自带的3D Models示例,展示了如何加载glTF格式三维模型数据.glTF是为WebGL量身定制的数据格式,在网络环境 ...
- 使用JDBC获取数据库中的一条记录并封装为Bean
比如我数据库中存入的是一条一条的用户信息,现在想取出一个人的个人信息,并封装为Bean对象,可以使用queryForObject来获取数据并通过new BeanPropertyRowMapper(Be ...
- Django csrf校验
引入: 通常,钓鱼网站本质是本质搭建一个跟正常网站一模一样的页面,用户在该页面上完成转账功能 转账的请求确实是朝着正常网站的服务端提交,唯一不同的在于收款账户人不同. 如果想模拟一个钓鱼网站,就可是给 ...
- C#设计模式学习笔记:(5)原型模式
本笔记摘抄自:https://www.cnblogs.com/PatrickLiu/p/7640873.html,记录一下学习过程以备后续查用. 一.引言 很多人说原型设计模式会节省机器内存,他们说 ...
- 并发编程之J.U.C的第二篇
并发编程之J.U.C的第二篇 3.2 StampedLock 4. Semaphore Semaphore原理 5. CountdownLatch 6. CyclicBarrier 7.线程安全集合类 ...
- opencv —— threshold、adaptiveThreshold 固定阈值 & 自适应阈值 进行图像二值化处理
阈值化 在对图像进行处理操作的过程中,我们常常需要对图像中的像素做出取舍与决策,直接剔除一些低于或高于一定值的像素. 阈值分割可以视为最简单的图像分割方法.比如基于图像中物体与背景之间的灰度差异,可以 ...
- 常用Content-type对照表
文件扩展名 Content-type .html text/html .xhtml text/html .gif image/gif .png image/png .jpg image/jpeg 更加 ...