机器学习-K最近邻算法
一、介绍
二、编程
练习一(K最近邻算法在单分类任务的应用):
import numpy as np #导入科学计算包
import matplotlib.pyplot as plt #导入画图工具
from sklearn.datasets import make_blobs #导入数据集生成器
from sklearn.neighbors import KNeighborsClassifier #导入KNN分类器(KNN回归树的类)
from sklearn.model_selection import train_test_split #导入数据集拆分工具
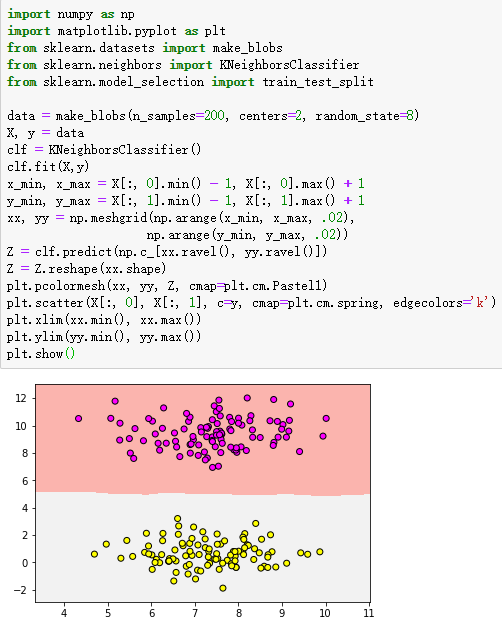
data = make_blobs(n_samples=200, centers=2, random_state=8) #生成样本数为200,分类为2的数据集,随机种子数为8
X, y = data
clf = KNeighborsClassifier() #导入KNN分类器函数
clf.fit(X,y) #训练X和y数据进行训练
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Pastel1)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.spring, edgecolors='k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()
练习二(K最近邻算法处理多元分类):
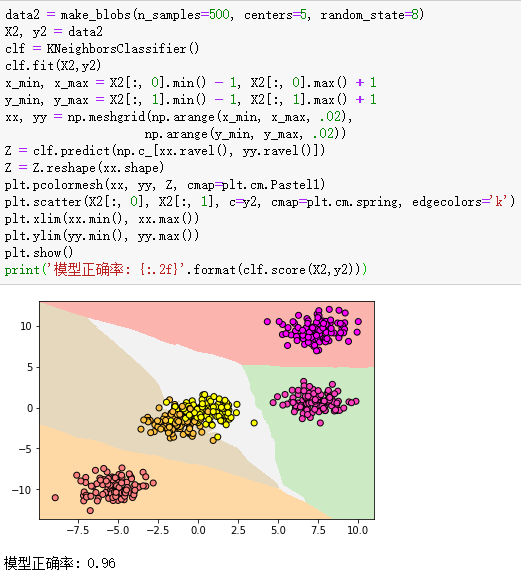
data2 = make_blobs(n_samples=500, centers=5, random_state=8) #生成样本数为500,分数为5的数据集
X2, y2 = data2
clf = KNeighborsClassifier()
clf.fit(X2,y2)
x_min, x_max = X2[:, 0].min() - 1, X2[:, 0].max() + 1
y_min, y_max = X2[:, 1].min() - 1, X2[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Pastel1)
plt.scatter(X2[:, 0], X2[:, 1], c=y2, cmap=plt.cm.spring, edgecolors='k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()
print('模型正确率: {:.2f}'.format(clf.score(X2,y2)))
练习三(K最近邻算法用于回归分析):
from sklearn.datasets import make_regression #导入数据集生成器
from sklearn.neighbors import KNeighborsRegressor
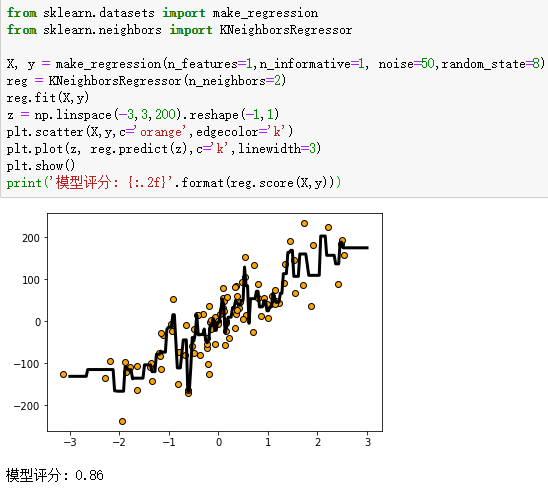
X, y = make_regression(n_features=1,n_informative=1, noise=50,random_state=8) #生成特征数量为1,噪音为50的数据集
reg = KNeighborsRegressor(n_neighbors=2)
reg.fit(X,y)
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,y,c='orange',edgecolor='k')
plt.plot(z, reg.predict(z),c='k',linewidth=3)
plt.show()
print('模型评分: {:.2f}'.format(reg.score(X,y)))
练习四(K最近邻算法项目用于酒的分类):
from sklearn.datasets import load_wine #导入数据模块
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split #导入数据集拆分工具
wine_dataset = load_wine()
knn = KNeighborsClassifier(n_neighbors=1)
X_train, X_test, y_train, y_test = train_test_split(wine_dataset['data'], wine_dataset['target'], random_state=0) #将数据集拆分为训练集和测试集
knn.fit(X_train, y_train)
print('测试数据得分: {:.2f}'.format(knn.score(X_test, y_test)))
print('####################################')
import numpy as np
X_new = np.array([[13.2,2.77,2.51,18.5,96.6,1.04,2.55,0.57,1.47,6.2,1.05,3.33,820]])
prediction = knn.predict(X_new)
print('预测新红酒的分类为: {}'.format(wine_dataset['target_names'][prediction]))

机器学习-K最近邻算法的更多相关文章
- 机器学习【一】K最近邻算法
K最近邻算法 KNN 基本原理 离哪个类近,就属于该类 [例如:与下方新元素距离最近的三个点中,2个深色,所以新元素分类为深色] K的含义就是最近邻的个数.在sklearn中,KNN的K值是通过n ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 《算法图解》——第十章 K最近邻算法
第十章 K最近邻算法 1 K最近邻(k-nearest neighbours,KNN)——水果分类 2 创建推荐系统 利用相似的用户相距较近,但如何确定两位用户的相似程度呢? ①特征抽取 对水果 ...
- [笔记]《算法图解》第十章 K最近邻算法
K最近邻算法 简称KNN,计算与周边邻居的距离的算法,用于创建分类系统.机器学习等. 算法思路:首先特征化(量化) 然后在象限中选取目标点,然后通过目标点与其n个邻居的比较,得出目标的特征. 余弦相似 ...
- PCB 加投率计算实现基本原理--K最近邻算法(KNN)
PCB行业中,客户订购5000pcs,在投料时不会直接投5000pcs,因为实际在生产过程不可避免的造成PCB报废, 所以在生产前需计划多投一定比例的板板, 例:订单 量是5000pcs,加投3%,那 ...
- K最近邻算法项目实战
这里我们用酒的分类来进行实战练习 下面来代码 1.把酒的数据集载入到项目中 from sklearn.datasets import load_wine #从sklearn的datasets模块载入数 ...
- 秒懂机器学习---k临近算法(KNN)
秒懂机器学习---k临近算法(KNN) 一.总结 一句话总结: 弄懂原理,然后要运行实例,然后多解决问题,然后想出优化,分析优缺点,才算真的懂 1.KNN(K-Nearest Neighbor)算法的 ...
- 图说十大数据挖掘算法(一)K最近邻算法
如果你之前没有学习过K最近邻算法,那今天几张图,让你明白什么是K最近邻算法. 先来一张图,请分辨它是什么水果 很多同学不假思索,直接回答:“菠萝”!!! 仔细看看同学们,这是菠萝么?那再看下边这这张图 ...
- 12、K最近邻算法(KNN算法)
一.如何创建推荐系统? 找到与用户相似的其他用户,然后把其他用户喜欢的东西推荐给用户.这就是K最近邻算法的分类作用. 二.抽取特征 推荐系统最重要的工作是:将用户的特征抽取出来并转化为度量的数字,然后 ...
随机推荐
- url查找参数
function GetUrlParam(paraName) { var url = document.location.toString(); var arrObj = url.split(&quo ...
- dotnet core 集成到 Mattermost 聊天工具
在找了很久的团队交流工具,发现了 Mattermost 最好用,但是还需要做一些定制化的功能,于是就找到了 Mattermost 插件开发,还找到了如何自己写服务集成到 Mattermost 里面 本 ...
- Python 序列求和
#基于Python2.7 多数OJ题库的第一题便是A+B,A+B+C此类求和问题,之前初学Python时是这么做的: while True: try: a,b,c=raw_input().split( ...
- windows系统下的maven项目放到linux系统中运行时报org.apache.commons.dbcp.SQLNestedException: Cannot create PoolableConnection这种异常的解决办法
这个错误的解决办法其实很简单你把连接mysql数据库的那个jar包换成linux版本的就行了: linux版本的连接mysql数据库的jar包链接:http://files.cnblogs.com/f ...
- P3225 [HNOI2012]矿场搭建 题解
这道题挺难的,可以加深对割点的理解,还有,排列组合好重要了,分连通块,然后乘法原理(加法原理计数什么的) 传送门 https://www.luogu.org/problem/P3225 省选oi题 ...
- 将Samba设置为Active Directory域控制器
一 简介 从版本4.0开始,samba可以作为Active Directory(AD)域控制器(DC)运行,如果在生产环境中安装samba,建议运行两个或者多个DC用于故障转移 本文介绍如何让将一个S ...
- leetcode.769旋转字符串
给定两个字符串, A 和 B. A 的旋转操作就是将 A 最左边的字符移动到最右边. 例如, 若 A = 'abcde',在移动一次之后结果就是'bcdea' .如果在若干次旋转操作之后,A 能变成B ...
- 接口自动化测试框架 -- reudom
reudom Automated testing framework based on requests and unittest interface. 基于 Unittest 和 Requests ...
- [ASP.NET Core 3框架揭秘] Options[1]: 配置选项的正确使用方式[上篇]
依赖注入不仅是支撑整个ASP.NET Core框架的基石,也是开发ASP.NET Core应用采用的基本编程模式,所以依赖注入十分重要.依赖注入使我们可以将依赖的功能定义成服务,最终以一种松耦合的形式 ...
- ACM北大暑期课培训第八天
今天学了有流量下界的网络最大流,最小费用最大流,计算几何. 有流量下界的网络最大流 如果流网络中每条边e对应两个数字B(e)和C(e), 分别表示该边上的流量至少要是B(e),最多 C(e),那么,在 ...