golang 服务大量 CLOSE_WAIT 故障排查
- 事故经过
- 排查
- 总结
事故经过
【2019-12-27 18:00 周五】
业务方突然找来说调用我们程序大量提示“触发限流”,但是我们没有收到任何监控报警。紧急查看了下 ServiceMesh sidecar 代理监控发现流量持续在减少,但是监控中没有任何触发限流的 http code 429 占比,如果有触发限流我们会收到报警。
后来通过排查是程序中有一个历史限流逻辑触发了,但是程序中触发限流返回的 http code 是 200,这就完全避开了 sidecar http code 非200 异常指标监控报警。把代码中的限流阈值调了非常大的一个值,统一走 sidecar 限流为准。
猜测本次触发限流可能跟网路抖动有关系,网络抖动导致连接持续被占用,最终 qps 超过限流阈值。因为这个程序最近都没有发布过,再加上业务上也没有突发流量,一切都很常态化。
【2019-12-28 15:30 周六】
相同的问题第二天悄无声息的又出现了,还是业务请求量持续下掉,上游业务方还是提示“触发限流”,同时业务监控环比也在逐步下掉。
以恢复线上问题为第一原则快速重启了程序,线上恢复。
修改了代码,去掉了限流逻辑,就算触发限流也应该第一时间告警出来,这段代码返回 http 200 就很坑了,我们完全无感知。虽然我们知道触发限流是“果”,“因”我们并不知道,但是故障要在第一时间暴露出来才是最重要的。
我们知道这个问题肯定还会出现,要让隐藏的问题尽可能的全部暴露出来,用最快最小的代价发现和解决掉才是正确的方式。
恢复线上问题之后,开始排查相关系统指标,首先排查程序依赖的 DB、redis 等中间件,各项指标都很正常,DB 连接池也很正常,活动连接数个位数,redis 也是。故障期间相关中间件、网络流量均出现 _qps_下降的情况。
当时开始排查网络抖动情况,但是仔细排查之后也没有出现丢包等情况。(仔细思考下,其实网络问题有点不合逻辑,因为相邻两天不可能同时触发同一条链路上的网络故障,而且其他系统都很正常。)
【2019-12-28 22:48 周六】
这次触发了 sidecar http code 非200占比 告警,我们第一时间恢复了,整个告警到恢复只用了几分钟不到,将业务方的影响减少到最低。
但是由于缺少请求链路中间环节日志,很难定位到底是哪里出现问题。这次我们打开了 sidecar 的请求日志,观察请求的日志,等待下次触发。(由于 qps 较高,默认是不打开 sidecar 请求日志)
同时请运维、基础架构、DBA、云专家等开始仔细排查整个链路。查看机器监控,发现故障期间 socket fd 升高到了3w多,随着fd升高内存也在持续占用,但是远没有到系统瓶颈,DB、redis 还是出现故障窗口期间 qps 同步下掉的情况。
这个程序是两台机器,出故障只有一台机器,周五和周六分别是两台机器交替出现 hang 住的情况。但是由于没有保留现场,无法仔细分析。(之所以不能直接下掉一台机器保留现场,是因为有些业务调用并不完全走 sidecar,有些还是走的域名进行调用。所以无法干净的下掉一台机器排查。)
socket fd 升高暂不确定是什么原因造成的。这次已经做好准备,下次故障立即 dump 网路连接,步步逼近问题。
【2019-12-29 18:34 周日】
就在我们排查的此时两台机器前后炸了一遍,迅速 netstat 下连接信息,然后重启程序,现在终于有了一些线索。
回顾整个故障过程,由于我们无法短时间内定位到,但是我们必须转被动为主动。从原来被动接受通知,到主动发现,让问题第一时间暴露出来,快速无感知恢复线上,然后逐步通过各种方式方法慢慢定位。
很多时候,我们排查问题会陷入细节,忽视了线上故障时间,应该以先恢复为第一原则。(故障等级和时间是正比的)
排查
【netstat 文件分析】
到目前为止发现问题没有那么简单,我们开始有备而来,主动揪出这个问题的时候了。做好相应的策略抓取更多的现场信息分析。分析了 netstat 导出来的连接信息。
tcp6 0 0 localhost:synapse-nhttp localhost:56696 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:60666 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:39570 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:55682 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:36812 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:58454 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:43694 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:32928 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:60710 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:33418 CLOSE_WAIT
tcp6 0 0 localhost:synapse-nhttp localhost:36980 CLOSE_WAIT
一时蒙蔽,synapse-nhttp 这个是什么程序,当时不确定全是 tcp 网络连接的 fd,情急之下只顾着导出最全的网络信息执行了 netstat -a ,没有带上 -n -p 转换端口为数字同时输出执行程序。_
这个 synapse-nhttp 非常可疑,同时查看了其他 go 程序机器都没有这个连接,为了排查是否程序本身问题,查看了 pre、qa 机器的连接,均都是 synapse-nhttp 这个端口名字。
判断下来 synapse-nhttp 确实是我们自己的程序,但是为什么端口名字会是 synapse-nhttp,后来查询下来发现我们程序使用的 8280 端口就是 synapse-nhttp 默认端口,所以被 netstat 自动人性化解析了。_
由于请求链路经过 sidecar 进来,大量的 CLOSE_WAIT 被动关闭状态,开始怀疑 sidecar 问题,保险起见我们采用排除法先将一个机器的量切到走域名做灰度测试,看是 sidecar 问题还是程序本身问题。
我们发现一个有意思的现象,CLOSE_WAIT 是被动关闭连接的状态,主动关闭连接的状态应该是 FIN_WAIT1。比较了两种状态连接数不是一个数量级,CLOSE_WAIT 将近1w个,而 FIN_WAIT1 只有几个,同时 FIN_WAIT2 只有几十个,TIME_WAIT一个没有。
合理情况下,sidecar 连接的 FIN_WAIT1 状态和本机程序连接的 CLOSE_WAIT 状态应该是一个数量级才对。但是现在明显被动关闭并没有成功完成,要么是上游 sidecar 主动断开了连接,本机程序迟迟未能发送 fin ack,sidecar 端的连接被 tcp keepalive 保活关闭释放了。或者本机程序已经发出 fin ack 但是 sidecar 没有收到,还有一种可能就是,sidecar 端连接在收到 fin ack 前被回收了。
当然,这些只是猜测,为了搞清楚具体什么原因导致只能抓包看 tcp 交互才能得出最终结论。
【tcpdump 包分析】
我们准备好 tcpdump 脚本,定期抓取 tcp 包,现在就在等故障出现了,因为故障一定还会出现。果然在30号下午又出现了,我们一阵激动准备分析dump文件,但是端口抓错了,sidecar 和程序都是本机调用走的是本地环回 lo 虚拟网卡接口,调整脚本在耐心的等待。_
问题又如期而至,我们开始分析包。

可以很清楚看到 HTTP 请求有进来没有返回的。第一个红框是请求超时,上游主动关闭连接,超时时间大概是1s,服务器正常返回了 fin ack。第二个红框大概是间隔了一分半钟,主动关闭连接,但是直接返回 RST 重置标志,原先的连接其实已经不存在了。
为了验证这个请求为什么没有返回,我们提取 tcpdump 中的 HTTP 请求到后端日志查看发现到了服务器,我们再从 Mysql 服务器请求 sql 中查看发现没有这个请求没有进来,同时我们发现一个规律,故障期间 DB 非活动连接数都有持续跑高现象,非常规律。
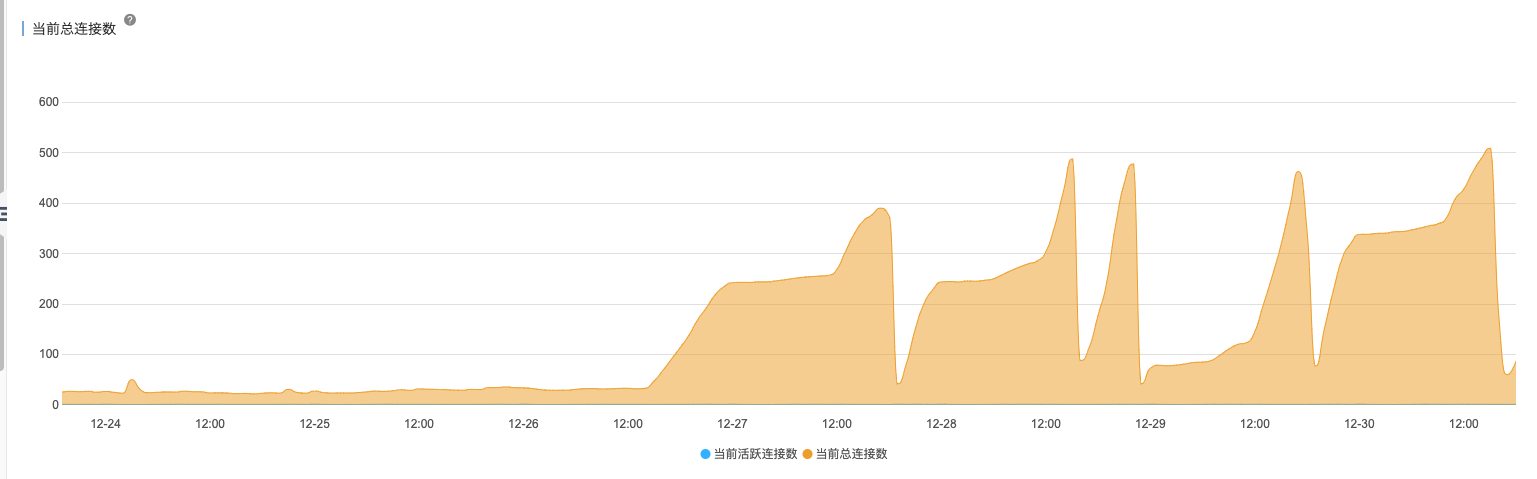
基本上断定是 DB 连接池泄漏,开始排查代码。
发现代码中有一个方法有问题,这个方法之前一直没有业务规则命中,故障前一天26号有一个业务方开始走到这个方法。这个方法有一个隐藏bug,会导致 go 连接无法关闭。
这个bug其实也有go.sql原生库的一半责任。
var r *sql.Rows
if r, err = core.GetDB().NewSession(nil).SelectBySql(query).Rows(); err != nil {
return
}
for r.Next() {
if err = r.Scan(&sum); err != nil {
applog.Logger.Error(fmt.Sprint("xxx", err))
r.Close() // 由于没有主动close连接导致泄漏
return
}
}
sql.Rows 的Scan方法内部由于没有判断查询DB返回的空,就直接转换导致 converting panic 。在加上我们这个方法没有处理 panic 情况,所以命中隐藏bug就会泄漏。
这个方法为什么不主动关闭连接是因为 sql.Rows 扫描到最后会做关闭动作,所以一直以来都很好。
所以真正的问题是由于 连接池泄漏,导致所有的请求 goroutine block 在获取连接地方的地方,这一类问题排查起来非常困难。
总结
1.回顾这整个排查过程,我觉得让系统运行的健康状态透明化才是发现问题的最有效手段,代码不出问题不现实。
2.go.sql 库还谈不上企业级应用,整个连接消耗、空闲和工作时长都是没有监控的,这也是导致这个case无法快速定位的原因。包括go的其他方面都存在很多不完善的地方,尤其是企业级应用套件都很弱,包括_go_原生 dump 内存之后分析的套件。
3.整个排查还是受到了一些噪音干扰,没能坚定核心逻辑和理论。DB 连接跑高为什么没注意到,这一点其实是因为我们一般只看当时故障前后半小时后指标,没有拉长看最近一段时间规律是否有异样,包括 sidecar 流量持续下掉是因为都是存量请求,请求逐渐被 _hang_住,导致量持续下掉,所以看上去感觉请求变少了,因为并没有多出流量。
4.其实线上故障一旦被定位之后,问题本身都很简单,一行不起眼的代码而已。所以我们必须敬畏每一行代码。
作者:王清培(趣头条 Tech Leader)
golang 服务大量 CLOSE_WAIT 故障排查的更多相关文章
- golang 服务诡异499、504网络故障排查
事故经过 排查 总结 事故经过 11-01 12:00 中午午饭期间,手机突然收到业务网关非200异常报警,平时也会有一些少量499或者网络抖动问题触发报警,但是很快就会恢复(目前配置的报警阈值是5% ...
- 【集群实战】NFS服务常见故障排查和解决方法
NFS,全名叫Network File System,中文叫网络文件系统,是Linux.UNIX系统的分布式文件系统的一个组成部分,可实现在不同网络上共享远程文件系统. NFS由Sun公司开发,目前已 ...
- NO11 SSH故障排查思路和netstat命令
本章知识相关考试:1.企业场景面试题:Linux系统如何优化?2.企业场景面试题:SSH服务连不上,如何排查?记住回答技巧: 1 ping 2 telnet 客户端ssh工具:SecureCRT,x ...
- [转] Linux运维常见故障排查和处理的技巧汇总
作为linux运维,多多少少会碰见这样那样的问题或故障,从中总结经验,查找问题,汇总并分析故障的原因,这是一个Linux运维工程师良好的习惯.每一次技术的突破,都经历着苦闷,伴随着快乐,可我们还是执着 ...
- Linux系统运维故障排查
一.思路 1.处理问题要求 2.一般思路 二.具体问题 1.网络问题 (1)网络不通 (2)网络很慢 2.硬件问题 3.操作系统问题 (1)系统无法正常启动 (2)系统运行慢或死机 4.服务或程序问题 ...
- Atitit.播放系统的选片服务器,包厢记时系统 的说明,教程,维护,故障排查手册p825
Atitit.播放系统的选片服务器,包厢记时系统 的说明,教程,维护,故障排查手册p825 1. 播放系统服务器方面的维护2 1.1. 默认情况下,已经在系统的启动目录下增加了俩个启动项目2 1.2. ...
- CentOS服务器上搭建Gitlab安装步骤、中文汉化详细步骤、日常管理以及异常故障排查
一, 服务器快速搭建gitlab方法 可以参考gitlab中文社区 的教程centos7安装gitlab:https://www.gitlab.cc/downloads/#centos7centos6 ...
- [redis]复制机制,调优,故障排查
在redis的安装目录下首先启动一个redis服务,使用默认的配置文件,作为主服务 ubuntu@slave1:~/redis2$ ./redis-server ./redis.conf & ...
- Linux运维常见故障排查和处理的33个技巧汇总
作为linux运维,多多少少会碰见这样那样的问题或故障,从中总结经验,查找问题,汇总并分析故障的原因,这是一个Linux运维工程师良好的习惯.每一次技术的突破,都经历着苦闷,伴随着快乐,可我们还是执着 ...
随机推荐
- jquery的offset().top和js的offsetTop的区别,以及jquery的offset().top的实现方法
jquery的offset().top和js的offsetTop的区别,以及jquery的offset().top的实现方法 offset().top是JQ的方法,需要引入JQ才能使用,它获取的是你绑 ...
- H3C 使用tracert命令
- childNodes和children
childNodes 返回指定元素的子节点集合,包括HTML节点,所有文本(元素之间的空格换行childNodes会看作文本节点). 通过nodeType来判断节点的类型: 元素 1 属性 2 文本 ...
- Linux 内核存取配置空间
在驱动已探测到设备后, 它常常需要读或写 3 个地址空间: 内存, 端口, 和配置. 特别 地, 存取配置空间对驱动是至关重要的, 因为这是唯一的找到设备被映射到内存和 I/O 空间的位置的方法. 因 ...
- C++Review7_STL、容器、迭代器
我之前的博文中有专门的5篇整理并介绍了STL的概念: STL1——整体介绍:https://www.cnblogs.com/grooovvve/p/10467794.html STL2——泛型编程(模 ...
- Caffe源码-几种优化算法
SGD简介 caffe中的SGDSolver类中实现了带动量的梯度下降法,其原理如下,\(lr\)为学习率,\(m\)为动量参数. 计算新的动量:history_data = local_rate * ...
- 前端——jQuery介绍
目录 jQuery介绍 jQuery的优势 jQuery内容: jQuery版本 jQuery对象 jQuery基础语法 查找标签 基本选择器 层级选择器: 基本筛选器: 属性选择器: 表单筛选器: ...
- windows10 powershell上切换至cmd
前言 在windows10 上是遇到了坑,因为出现了这样的情况!不要说什么盗版,公司买的正版呢. 上图是powershell,下图是 cmd,然后我同样使用powershell 与 cmd,查询nod ...
- org.apache.subversion.javahl.ClientException: Item is not readable 解决办法
在使用eclise安装的插件subclipse查看svn的提交历史记录的时候,提示org.apache.subversion.javahl.ClientException: Item is not r ...
- 洛谷$P4884$ 多少个1? 数论
正解:$BSGS$ 解题报告: 传送门$QwQ$ 首先看到这个若干个一,发现不好表示,考虑两遍同时乘九加一,于是变成$10^n\equiv 9\cdot K+1(mod\ m)$ 昂然后不就是$bsg ...