曹工说Spring Boot源码(6)-- Spring怎么从xml文件里解析bean的
写在前面的话
相关背景及资源:
曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享
曹工说Spring Boot源码(2)-- Bean Definition到底是什么,咱们对着接口,逐个方法讲解
曹工说Spring Boot源码(3)-- 手动注册Bean Definition不比游戏好玩吗,我们来试一下
曹工说Spring Boot源码(4)-- 我是怎么自定义ApplicationContext,从json文件读取bean definition的?
曹工说Spring Boot源码(5)-- 怎么从properties文件读取bean
工程结构图:

整体流程
这次,我们打算讲一下,spring启动时,是怎么去读取xml文件的,bean的解析部分可能暂时涉及不到,因为放到一起,内容就太多了,具体再看吧。
给
ClassPathXmlApplicationContext设置xml文件的路径refresh内部的beanFactory,其实这时候BeanFactory都还没创建,会先创DefaultListableBeanFactoryClassPathXmlApplicationContext调用其loadBeanDefinitions,将新建DefaultListableBeanFactory作为参数传入ClassPathXmlApplicationContext内部会持有一个XmlBeanDefinitionReader,且XmlBeanDefinitionReader内部是持有之前创建的DefaultListableBeanFactory的,这时候就简单了,XmlBeanDefinitionReader负责读取xml,将bean definition解析出来,丢给DefaultListableBeanFactory,此时,XmlBeanDefinitionReader就算完成了,退出历史舞台上面第四步完成后,
DefaultListableBeanFactory里面其实一个业务bean都没有,只有一堆的bean definition,后面ClassPathXmlApplicationContext直接去实例化那些需要在启动过程中实例化的bean。当前,这中间还涉及到使用
beanDefinitionPostProcessor和beanPostProcessor对beanFactory进行处理,这都是后话了。
这次,我们主要讲的部分是,第4步。
入口代码
位置:org.springframework.context.support.AbstractRefreshableApplicationContext
@Override
protected final void refreshBeanFactory() throws BeansException {
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
//创建一个DefaultListableBeanFactory
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
customizeBeanFactory(beanFactory);
// 加载
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
上面调用了
AbstractXmlApplicationContext#loadBeanDefinitions(org.springframework.beans.factory.support.DefaultListableBeanFactory)
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) {
// 创建一个从xml读取beanDefinition的读取器
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// 配置环境
beanDefinitionReader.setEnvironment(this.getEnvironment());
// 配置资源loader,一般就是classpathx下去获取xml
beanDefinitionReader.setResourceLoader(this);
// xml解析的解析器
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
initBeanDefinitionReader(beanDefinitionReader);
// 核心方法,使用beanDefinitionReader去解析xml,并将解析后的bean definition放到beanFactory
loadBeanDefinitions(beanDefinitionReader);
}
xml中xsd、dtd解析器
// xml解析的解析器
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
这个类实现的接口就是jdk里面的org.xml.sax.EntityResolver,这个接口,只有一个方法,主要负责xml里,外部实体的解析:
public interface EntityResolver {
public abstract InputSource resolveEntity (String publicId,
String systemId)
throws SAXException, IOException;
}
大家可能不太明白,我们看看怎么实现的吧:
public class DelegatingEntityResolver implements EntityResolver {
/** Suffix for DTD files */
public static final String DTD_SUFFIX = ".dtd";
/** Suffix for schema definition files */
public static final String XSD_SUFFIX = ".xsd";
private final EntityResolver dtdResolver;
private final EntityResolver schemaResolver;
public DelegatingEntityResolver(ClassLoader classLoader) {
this.dtdResolver = new BeansDtdResolver();
this.schemaResolver = new PluggableSchemaResolver(classLoader);
}
// 主要看这里,感觉就是对我们xml里面的那堆xsd进行解析
@override
public InputSource resolveEntity(String publicId, String systemId) throws SAXException, IOException {
if (systemId != null) {
if (systemId.endsWith(DTD_SUFFIX)) {
return this.dtdResolver.resolveEntity(publicId, systemId);
}
else if (systemId.endsWith(XSD_SUFFIX)) {
return this.schemaResolver.resolveEntity(publicId, systemId);
}
}
return null;
}
举个例子,我们xml里一般不是有如下代码吗:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
上面的代码,应该就是去获取和解析上面这里的xsd,方便进行语法校验的。毕竟,这个xml我们也不能随便乱写吧,比如,根元素就是,有且 只能有一个,下面才能有0到多个之类的元素。你要是写了多个根元素,肯定不合规范啊。
接下来,我们还是赶紧切入正题吧,看看XmlBeanDefinitionReader是怎么解析xml的。
XmlBeanDefinitionReader 解析xml
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
String[] configLocations = getConfigLocations();
//这个方法还在:AbstractXmlApplicationContext,获取资源位置,传给 XmlBeanDefinitionReader
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
经过几个简单跳转,进入下面的方法:
org.springframework.beans.factory.support.AbstractBeanDefinitionReader#loadBeanDefinitions(java.lang.String, java.util.Set<org.springframework.core.io.Resource>)
public int loadBeanDefinitions(String location, Set<Resource> actualResources) throws BeanDefinitionStoreException {
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader instanceof ResourcePatternResolver) {
try {
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
// 从资源数组里load bean definition
int loadCount = loadBeanDefinitions(resources);
return loadCount;
}
}
}
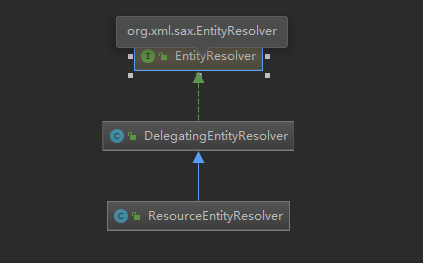
XmlBeanDefinitionReader类图
这里插一句,看看其类图:

总的来说,类似于模板设计模式,一些通用的逻辑和流程,放在AbstractBeanDefinitionReader,具体的解析啊,都是放在子类实现。
我们这里也可以看到,其实现了一个接口,BeanDefinitionReader:
package org.springframework.beans.factory.support;
public interface BeanDefinitionReader {
// 为什么需要这个,因为读取到bean definition后,需要存到这个里面去;如果不提供这个,我读了往哪放
BeanDefinitionRegistry getRegistry();
//资源加载器,加载xml之类,当然,作为一个接口,资源是可以来自于任何地方
ResourceLoader getResourceLoader();
//获取classloader
ClassLoader getBeanClassLoader();
// beanName生成器
BeanNameGenerator getBeanNameGenerator();
// 从资源load bean definition
int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException;
int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException;
int loadBeanDefinitions(String location) throws BeanDefinitionStoreException;
int loadBeanDefinitions(String... locations) throws BeanDefinitionStoreException;
}
我们切回前面,AbstractBeanDefinitionReader实现了大部分方法,除了下面这个:
int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException;
因为,它毕竟只是个抽象类,不负责干活啊;而且,为了能够从不同的resource读取,这个也理应交给子类。
比如,我们这里的XmlBeanDefinitionReader就是负责从xml文件读取;我之前的文章里,也演示了如何从json读取,也是自定义了一个AbstractBeanDefinitionReader的子类。

读取xml文件为InputSource
接着上面的方法往下走,马上就进入到了:
位置:org.springframework.beans.factory.xml.XmlBeanDefinitionReader,插入的参数,就是我们的xml
public int loadBeanDefinitions(EncodedResource encodedResource) {
...
try {
// 读取xml文件为文件流
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
//读取为xml资源
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 解析bean definition去
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
}
}
这里,提一句InputSource,这个类的全路径为:org.xml.sax.InputSource,是jdk里的类。
包名里包括了xml,知道大概是xml相关的类了,包名也包含了sax,大概知道是基于sax事件解析模型。
这方面我懂得也不多,回头可以单独讲解。我们继续正文:
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource) {
try {
int validationMode = getValidationModeForResource(resource);
// 反正org.w3c.dom.Document也是jdk的类,具体不管
Document doc = this.documentLoader.loadDocument(
inputSource, getEntityResolver(), this.errorHandler, validationMode, isNamespaceAware());
// 下边就开始正题了
return registerBeanDefinitions(doc, resource);
}
}
关于documentLoader.loadDocument,大家只要简单知道,是进行初步的解析就行了,主要是基于xsd、dtd等,进行语法检查等。
我这里的堆栈,大家看下:
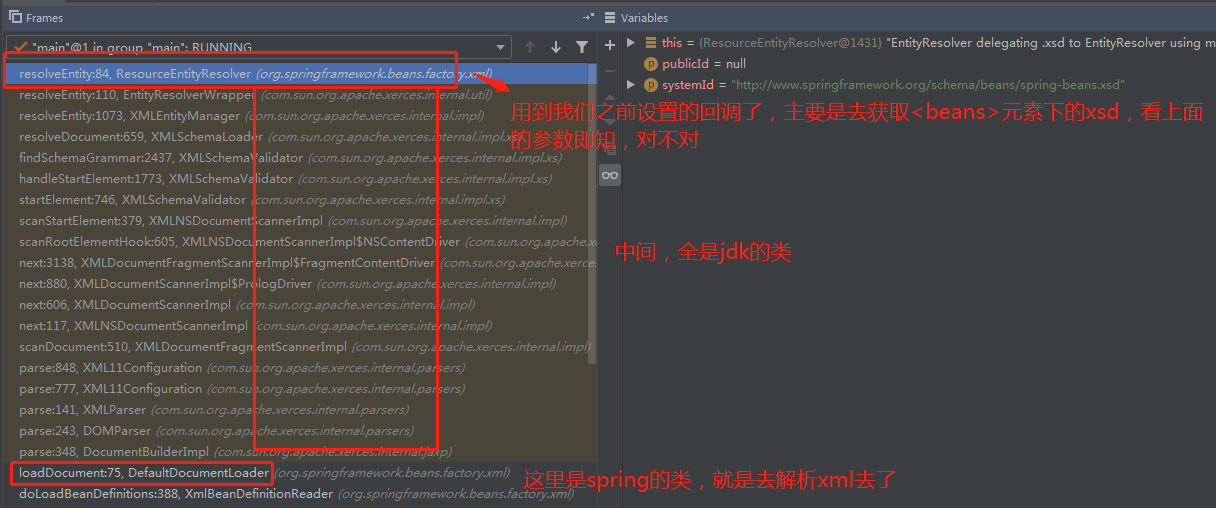
这里,先不深究xml解析的东西(主要是我也不怎么会啊,哈哈哈)
接着走:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
documentReader.setEnvironment(this.getEnvironment());
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
BeanDefinitionDocumentReader
看得出来,XmlBeanDefinitionReader可能觉得工作繁重,于是将具体的工作,交给了BeanDefinitionDocumentReader。
public interface BeanDefinitionDocumentReader {
void setEnvironment(Environment environment);
void registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
throws BeanDefinitionStoreException;
}
核心方法肯定是
void registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
两个参数,Document我们理解,就是代表xml文件;
XmlReaderContext
XmlReaderContext是啥,看样子是个上下文,上下文,一般来说,就是个大杂烩,把需要用到的都会放在里面。
我们看看放了些啥:
public class XmlReaderContext extends ReaderContext {
// 之前的核心类,把自己传进来了
private final XmlBeanDefinitionReader reader;
// org.springframework.beans.factory.xml.NamespaceHandlerResolver,这个也是核心类!
private final NamespaceHandlerResolver namespaceHandlerResolver;
}
public class ReaderContext {
//xml资源本身
private final Resource resource;
//盲猜是中间处理报错后,报告问题
private final ProblemReporter problemReporter;
// event/listener机制吧,方便扩展
private final ReaderEventListener eventListener;`
// 跳过
private final SourceExtractor sourceExtractor;
}
看完了这个上下文的定义,要知道,它是作为一个参数,传给:
org.springframework.beans.factory.xml.BeanDefinitionDocumentReader
void registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
throws BeanDefinitionStoreException;
那,这个参数怎么构造的呢?
那,我们还得切回前面的代码:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
documentReader.setEnvironment(this.getEnvironment());
int countBefore = getRegistry().getBeanDefinitionCount();
// 这里,调用createReaderContext(resource)创建上下文
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
/**
* Create the {@link XmlReaderContext} to pass over to the document reader.
*/
protected XmlReaderContext createReaderContext(Resource resource) {
if (this.namespaceHandlerResolver == null) {
// 创建一个namespacehandler
this.namespaceHandlerResolver = createDefaultNamespaceHandlerResolver();
}
return new XmlReaderContext(resource, this.problemReporter, this.eventListener,
this.sourceExtractor, this, this.namespaceHandlerResolver);
}
namespaceHandlerResolver
这里太核心了,我们看看namespaceHandlerResolver是干嘛的:
public interface NamespaceHandlerResolver {
/**
* Resolve the namespace URI and return the located {@link NamespaceHandler}
* implementation.
* @param namespaceUri the relevant namespace URI
* @return the located {@link NamespaceHandler} (may be {@code null})
*/
// 比如解析xml时,我们可能有<bean>,这个是默认命名空间,其namespace就是<beans>;如果是<context:component-scan>,这里的namespace,就是context
NamespaceHandler resolve(String namespaceUri);
}
这个类的用途,就是根据传入的namespace,找到对应的handler。
大家可以去spring-beans.jar包里的META-INF/spring.handlers找一找,这个文件打开后,内容如下:
http\://www.springframework.org/schema/c=org.springframework.beans.factory.xml.SimpleConstructorNamespaceHandler
http\://www.springframework.org/schema/p=org.springframework.beans.factory.xml.SimplePropertyNamespaceHandler
http\://www.springframework.org/schema/util=org.springframework.beans.factory.xml.UtilNamespaceHandler
也可以再去spring-context.jar里找找,里面也有这个文件:
http\://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandler
http\://www.springframework.org/schema/jee=org.springframework.ejb.config.JeeNamespaceHandler
http\://www.springframework.org/schema/lang=org.springframework.scripting.config.LangNamespaceHandler
http\://www.springframework.org/schema/task=org.springframework.scheduling.config.TaskNamespaceHandler
http\://www.springframework.org/schema/cache=org.springframework.cache.config.CacheNamespaceHandler
我列了个表格:
| namespace | handler |
|---|---|
| http://www.springframework.org/schema/c | org.springframework.beans.factory.xml.SimpleConstructorNamespaceHandler |
| http://www.springframework.org/schema/p | org.springframework.beans.factory.xml.SimplePropertyNamespaceHandler |
| http://www.springframework.org/schema/util | org.springframework.beans.factory.xml.UtilNamespaceHandler |
| http://www.springframework.org/schema/context | org.springframework.context.config.ContextNamespaceHandler |
| http://www.springframework.org/schema/task | org.springframework.scheduling.config.TaskNamespaceHandler |
| http://www.springframework.org/schema/cache | org.springframework.cache.config.CacheNamespaceHandler |
比较重要的,我都列在上面了,剩下的jee/lang,我没用过,不知道大家用过没,先跳过吧。
大家可能也有感到奇怪的地方,怎么没有这个namespace的呢,因为它是默认的,所以在程序里是特殊处理的,一会才到它。
接着看核心逻辑:
DefaultBeanDefinitionDocumentReader#doRegisterBeanDefinitions
protected void doRegisterBeanDefinitions(Element root) {
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createHelper(this.readerContext, root, parent);
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}
BeanDefinitionParserDelegate
恩。。。我们已经快疯了,怎么又出来一个类,DefaultBeanDefinitionDocumentReader看来也是觉得自己工作压力太大了吧,这里又弄了个BeanDefinitionParserDelegate。
这个类,没实现什么接口,就是个大杂烩,方法多的一批,主要是进行具体的解析工作,大家可以看看里面定义的字段:
public static final String BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";
public static final String MULTI_VALUE_ATTRIBUTE_DELIMITERS = ",; ";
/**
* Value of a T/F attribute that represents true.
* Anything else represents false. Case seNsItive.
*/
public static final String TRUE_VALUE = "true";
public static final String FALSE_VALUE = "false";
public static final String DEFAULT_VALUE = "default";
public static final String DESCRIPTION_ELEMENT = "description";
public static final String AUTOWIRE_NO_VALUE = "no";
public static final String AUTOWIRE_BY_NAME_VALUE = "byName";
public static final String AUTOWIRE_BY_TYPE_VALUE = "byType";
public static final String AUTOWIRE_CONSTRUCTOR_VALUE = "constructor";
public static final String AUTOWIRE_AUTODETECT_VALUE = "autodetect";
public static final String DEPENDENCY_CHECK_ALL_ATTRIBUTE_VALUE = "all";
public static final String DEPENDENCY_CHECK_SIMPLE_ATTRIBUTE_VALUE = "simple";
public static final String DEPENDENCY_CHECK_OBJECTS_ATTRIBUTE_VALUE = "objects";
public static final String NAME_ATTRIBUTE = "name";
public static final String BEAN_ELEMENT = "bean";
public static final String META_ELEMENT = "meta";
public static final String ID_ATTRIBUTE = "id";
public static final String PARENT_ATTRIBUTE = "parent";
public static final String CLASS_ATTRIBUTE = "class";
public static final String ABSTRACT_ATTRIBUTE = "abstract";
public static final String SCOPE_ATTRIBUTE = "scope";
public static final String SINGLETON_ATTRIBUTE = "singleton";
public static final String LAZY_INIT_ATTRIBUTE = "lazy-init";
public static final String AUTOWIRE_ATTRIBUTE = "autowire";
public static final String AUTOWIRE_CANDIDATE_ATTRIBUTE = "autowire-candidate";
public static final String PRIMARY_ATTRIBUTE = "primary";
public static final String DEPENDENCY_CHECK_ATTRIBUTE = "dependency-check";
public static final String DEPENDS_ON_ATTRIBUTE = "depends-on";
public static final String INIT_METHOD_ATTRIBUTE = "init-method";
public static final String DESTROY_METHOD_ATTRIBUTE = "destroy-method";
public static final String FACTORY_METHOD_ATTRIBUTE = "factory-method";
public static final String FACTORY_BEAN_ATTRIBUTE = "factory-bean";
public static final String CONSTRUCTOR_ARG_ELEMENT = "constructor-arg";
public static final String INDEX_ATTRIBUTE = "index";
public static final String TYPE_ATTRIBUTE = "type";
public static final String VALUE_TYPE_ATTRIBUTE = "value-type";
public static final String KEY_TYPE_ATTRIBUTE = "key-type";
public static final String PROPERTY_ELEMENT = "property";
public static final String REF_ATTRIBUTE = "ref";
public static final String VALUE_ATTRIBUTE = "value";
public static final String LOOKUP_METHOD_ELEMENT = "lookup-method";
public static final String REPLACED_METHOD_ELEMENT = "replaced-method";
public static final String REPLACER_ATTRIBUTE = "replacer";
public static final String ARG_TYPE_ELEMENT = "arg-type";
public static final String ARG_TYPE_MATCH_ATTRIBUTE = "match";
public static final String REF_ELEMENT = "ref";
public static final String IDREF_ELEMENT = "idref";
public static final String BEAN_REF_ATTRIBUTE = "bean";
public static final String LOCAL_REF_ATTRIBUTE = "local";
...
看出来了么,主要都是xml里面的那些元素的名称。
里面的方法,很多,我们用到了再说。
我们继续回到主线任务:
org.springframework.beans.factory.xml.DefaultBeanDefinitionDocumentReader#parseBeanDefinitions
/**
* Parse the elements at the root level in the document:
* "import", "alias", "bean".
* @param root the DOM root element of the document
*/
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// 一般来说,我们的根节点都是<beans>,这个是默认namespace的
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
// 遍历xml <beans>下的每个元素
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// 判断元素是不是默认命名空间的,比如<bean>是,<context:component-scan>不是
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
//<context:component-scan>,<aop:xxxx>走这边
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
这里,判断一个元素是不是默认命名空间,具体怎么做的呢:
BeanDefinitionParserDelegate#isDefaultNamespace(org.w3c.dom.Node)
public boolean isDefaultNamespace(Node node) {
//调用重载方法
return isDefaultNamespace(getNamespaceURI(node));
}
public static final String BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";
public boolean isDefaultNamespace(String namespaceUri) {
return (!StringUtils.hasLength(namespaceUri) || BEANS_NAMESPACE_URI.equals(namespaceUri));
}
默认namespace时的逻辑
DefaultBeanDefinitionDocumentReader#parseDefaultElement
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}
第一次发现,原来默认命名空间下,才这么几个元素:
import、alias、bean、(NESTED_BEANS_ELEMENT)beans
具体的解析放到下讲,这讲内容已经够多了。
非默认namespace时的逻辑
主要是处理:aop、context等非默认namespace。
BeanDefinitionParserDelegate
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd) {
String namespaceUri = getNamespaceURI(ele);
// 这里,就和前面串起来了,根据namespace找handler
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
我们挑一个大家最熟悉的org.springframework.context.config.ContextNamespaceHandler,大家先看看:
public class ContextNamespaceHandler extends NamespaceHandlerSupport {
public void init() {
// 这个也熟悉吧
registerBeanDefinitionParser("property-placeholder", new PropertyPlaceholderBeanDefinitionParser());
registerBeanDefinitionParser("property-override", new PropertyOverrideBeanDefinitionParser());
registerBeanDefinitionParser("annotation-config", new AnnotationConfigBeanDefinitionParser());
// 这个熟悉吧
registerBeanDefinitionParser("component-scan", new ComponentScanBeanDefinitionParser());
registerBeanDefinitionParser("load-time-weaver", new LoadTimeWeaverBeanDefinitionParser());
registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
registerBeanDefinitionParser("mbean-export", new MBeanExportBeanDefinitionParser());
registerBeanDefinitionParser("mbean-server", new MBeanServerBeanDefinitionParser());
}
}
总之,到了这里,就是根据具体的元素,找对应的处理器了。这些都后面再说了。内容太多了。
总结
大家可以回头再去看看第二章的整体流程,会不会清晰一些了呢?
主要是几个核心类:
XmlBeanDefinitionReader
BeanDefinitionDocumentReader
XmlReaderContext
namespaceHandlerResolver
BeanDefinitionParserDelegate
内容有点多,大家不要慌,我们后面还会进一步讲解的。觉得有帮助的话,点个赞哦。
曹工说Spring Boot源码(6)-- Spring怎么从xml文件里解析bean的的更多相关文章
- 曹工说Spring Boot源码系列开讲了(1)-- Bean Definition到底是什么,附spring思维导图分享
写在前面的话&&About me 网上写spring的文章多如牛毛,为什么还要写呢,因为,很简单,那是人家写的:网上都鼓励你不要造轮子,为什么你还要造呢,因为,那不是你造的. 我不是要 ...
- 曹工说Spring Boot源码(7)-- Spring解析xml文件,到底从中得到了什么(上)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- 曹工说Spring Boot源码(8)-- Spring解析xml文件,到底从中得到了什么(util命名空间)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- 曹工说Spring Boot源码(9)-- Spring解析xml文件,到底从中得到了什么(context命名空间上)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- # 曹工说Spring Boot源码(10)-- Spring解析xml文件,到底从中得到了什么(context:annotation-config 解析)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- 曹工说Spring Boot源码(11)-- context:component-scan,你真的会用吗(这次来说说它的奇技淫巧)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- 曹工说Spring Boot源码(12)-- Spring解析xml文件,到底从中得到了什么(context:component-scan完整解析)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- 曹工说Spring Boot源码(13)-- AspectJ的运行时织入(Load-Time-Weaving),基本内容是讲清楚了(附源码)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- 曹工说Spring Boot源码(14)-- AspectJ的Load-Time-Weaving的两种实现方式细细讲解,以及怎么和Spring Instrumentation集成
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
随机推荐
- HDU_1061:Rightmost Digit
Problem Description Given a positive integer N, you should output the most right digit of N^N. Inp ...
- 微服务开源生态报告 No.2
通常,我们都会通过在 GitHub 上订阅邮件列表,来了解社区动态.这一次,我们联合以上各开源项目的负责人,发布「微服务开源生态报告」,汇集各个开源项目近期的社区动态,帮助开发者们更高效的了解到各开源 ...
- @codeforces - 1149D@ Abandoning Roads
目录 @description@ @solution@ @accepted code@ @details@ @description@ 给定一个 n 点 m 条边的无向连通图,每条边的边权为 a 或 ...
- centos安装php7.18注意
报错–php53-common conflicts with php-common //解决 yum -y install php* --skip-broken 第一步:安装源 yum install ...
- Android实现圆角边框
http://www.cnblogs.com/flyme/archive/2012/06/20/2556259.html android shape的使用 http://www.cnblogs.com ...
- BUAA 169 电话费
http://oj55.bianchengla.com/problem/169/ 还有这个,不怎么好做,最后用栈做出来了. 感觉比较有用的一个数据是: 10 3 1010101010 代码如下: #i ...
- Knative 核心概念介绍:Build、Serving 和 Eventing 三大核心组件
Knative 主要由 Build.Serving 和 Eventing 三大核心组件构成.Knative 正是依靠这三个核心组件,驱动着 Knative 这艘 Serverless 巨轮前行.下面让 ...
- MySQL数据库优化(五)——MySQL查询优化
http://blog.csdn.net/daybreak1209/article/details/51638187 一.mysql查询类型(默认查询出所有数据列)1.内连接 默认多表关联 ...
- OpenStack☞HTTP协议
前言 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议.所有的WWW文件都必须遵守这个标准 HTTP是一个基于TCP/IP通信协议 ...
- @游记@ CQOI2019(十二省联考)
目录 @day - 0@ @day - 1@ @day - 2@ @后记@ 我只是来打酱油哒-- 顶多能进个 E 类继续打酱油. 原本还在互奶 A 队,结果现在--铁定进不了队啦. 对初中生的歧视啊 ...