吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用
import numpy as np from matplotlib import pyplot as plt
from sklearn import neighbors, datasets
from matplotlib.colors import ListedColormap
from sklearn.neural_network import MLPClassifier ## 加载数据集
np.random.seed(0)
# 使用 scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
# 使用前两个特征,方便绘图
X=iris.data[:,0:2]
# 标记值
Y=iris.target
data=np.hstack((X,Y.reshape(Y.size,1)))
# 混洗数据。因为默认的iris 数据集:前50个数据是类别0,中间50个数据是类别1,末尾50个数据是类别2.混洗将打乱这个顺序
np.random.shuffle(data)
X=data[:,:-1]
Y=data[:,-1]
train_x=X[:-30]
train_y=Y[:-30]
# 最后30个样本作为测试集
test_x=X[-30:]
test_y=Y[-30:] def plot_classifier_predict_meshgrid(ax,clf,x_min,x_max,y_min,y_max):
'''
绘制 MLPClassifier 的分类结果 :param ax: Axes 实例,用于绘图
:param clf: MLPClassifier 实例
:param x_min: 第一维特征的最小值
:param x_max: 第一维特征的最大值
:param y_min: 第二维特征的最小值
:param y_max: 第二维特征的最大值
:return: None
'''
plot_step = 0.02 # 步长
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),np.arange(y_min, y_max, plot_step))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘图
ax.contourf(xx, yy, Z, cmap=plt.cm.Paired) def plot_samples(ax,x,y):
'''
绘制二维数据集 :param ax: Axes 实例,用于绘图
:param x: 第一维特征
:param y: 第二维特征
:return: None
'''
n_classes = 3
# 颜色数组。每个类别的样本使用一种颜色
plot_colors = "bry"
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
# 绘图
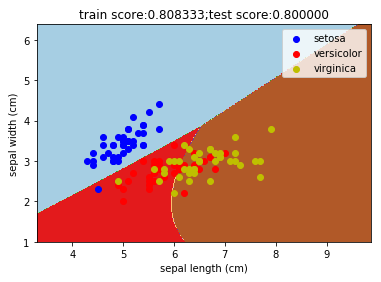
ax.scatter(x[idx, 0], x[idx, 1], c=color,label=iris.target_names[i], cmap=plt.cm.Paired) def mlpclassifier_iris():
'''
使用 MLPClassifier 预测调整后的 iris 数据集
'''
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
classifier=MLPClassifier(activation='logistic',max_iter=10000,hidden_layer_sizes=(30,))
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("train score:%f;test score:%f"%(train_score,test_score))
plt.show() mlpclassifier_iris()
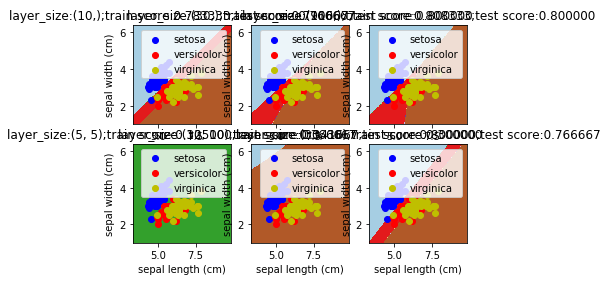
def mlpclassifier_iris_hidden_layer_sizes():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的 hidden_layer_sizes 的影响 :return: None
'''
fig=plt.figure()
# 候选的 hidden_layer_sizes 参数值组成的数组
hidden_layer_sizes=[(10,),(30,),(100,),(5,5),(10,10),(30,30)]
for itx,size in enumerate(hidden_layer_sizes):
ax=fig.add_subplot(2,3,itx+1)
classifier=MLPClassifier(activation='logistic',max_iter=10000,hidden_layer_sizes=size)
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("layer_size:%s;train score:%f;test score:%f"%(size,train_score,test_score))
plt.show() mlpclassifier_iris_hidden_layer_sizes()
def mlpclassifier_iris_ativations():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的 activation 的影响
'''
fig=plt.figure()
# 候选的激活函数字符串组成的列表
ativations=["logistic","tanh","relu"]
for itx,act in enumerate(ativations):
ax=fig.add_subplot(1,3,itx+1)
classifier=MLPClassifier(activation=act,max_iter=10000,hidden_layer_sizes=(30,))
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("activation:%s;train score:%f;test score:%f"%(act,train_score,test_score))
plt.show() mlpclassifier_iris_ativations()

def mlpclassifier_iris_algorithms():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的 algorithm 的影响 :return: None
'''
fig=plt.figure()
algorithms=["lbfgs","sgd","adam"] # 候选的算法字符串组成的列表
for itx,algo in enumerate(algorithms):
ax=fig.add_subplot(1,3,itx+1)
classifier=MLPClassifier(activation="tanh",max_iter=10000,hidden_layer_sizes=(30,),solver=algo)
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("algorithm:%s;train score:%f;test score:%f"%(algo,train_score,test_score))
plt.show() mlpclassifier_iris_algorithms()

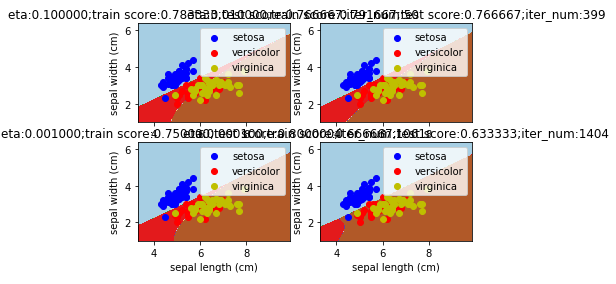
def mlpclassifier_iris_eta():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的学习率的影响
'''
fig=plt.figure()
etas=[0.1,0.01,0.001,0.0001] # 候选的学习率值组成的列表
for itx,eta in enumerate(etas):
ax=fig.add_subplot(2,2,itx+1)
classifier=MLPClassifier(activation="tanh",max_iter=1000000,
hidden_layer_sizes=(30,),solver='sgd',learning_rate_init=eta)
classifier.fit(train_x,train_y)
iter_num=classifier.n_iter_
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("eta:%f;train score:%f;test score:%f;iter_num:%d"%(eta,train_score,test_score,iter_num))
plt.show() mlpclassifier_iris_eta()
吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用的更多相关文章
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 人工智能——基于神经网络算法在智能医疗诊断中的应用探索代码简要展示
#K-NN分类 import os import sys import time import operator import cx_Oracle import numpy as np import ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
随机推荐
- 机器学习作业(七)非监督学习——Matlab实现
题目下载[传送门] 第1题 简述:实现K-means聚类,并应用到图像压缩上. 第1步:实现kMeansInitCentroids函数,初始化聚类中心: function centroids = kM ...
- navicat 连接报2059错误
原因 navicat不支持mysql新版本的加密规则,mysql8 之前的版本中加密规则是mysql_native_password, mysql8之后,加密规则是caching_sha2_passw ...
- ubuntu Redis安装及配置
1.安装 1.1 下载压缩包:wget http://download.redis.io/releases/redis-5.0.4.tar.gz1.2 解压:tar xzf redis-5.0.4.t ...
- http接口的调用
1.按照文档先写入参数,这里主要介绍 Json格式的String字符串,包括拼接数组 String sqr_arry [] = new String[rowList.size()]; for(int ...
- appium+android测试环境安装
1. jdk配置 一.背景 JDK已经更新到12了,但是由于很多工具仍然未及时更新,故推荐最稳定的JDK版本1.8.x: JDK需要配置通常情况下,JDK配置分为三项: JAVA_HOME:某些软件仍 ...
- JS高级---创建正则表达式对象
创建正则表达式对象 两种: 1.通过构造函数创建对象 2.字面量的方式创建对象 正则表达式的作用: 匹配字符串的 //对象创建完毕--- var reg = new RegExp(/\d{5} ...
- IDEA编写shell脚本并运行
1.去官网下载IDEA开发工具 https://www.jetbrains.com/idea/ 2.打开IDEA并安装bashsupport插件 3.安装完插件重启IDEA 4.下载git工具 htt ...
- cat 显示文本、less 分屏显示文本、more 分页显示文件、head 显示文件的前面的内容、cut 切割、paste合并、wc用来对文本进行统计、sort排序、权限、关闭文件、vim的使用
cat 显示文本 -E 显示结尾的$符 -n 对显示的每一行进行编号 -b 对非空行进行编号 -s 对连续的空行进行压缩 tac 倒序显示 less 分屏显示文本 向下翻一屏 空格 向下翻一行 回车 ...
- ORA-01830
问题:varchar2类型转换成date类型 select to_date(INVOICE_DATE,'yyyy-mm-dd') from tab; 提示 ORA-01830: 日期格式图片在转换整个 ...
- ubuntu 离线装包
1,为什么要离线装包 防止有些包官方升级以后导致的不兼容,比如php5和php7,目前已经无法apt-get install php5了, 2,装包以前你得有安装包文件,deb或者是run deb包在 ...