MongoDB副本集的工作原理
在MongoDB副本集中,主节点负责处理客户端的读写请求,备份节点则负责映射主节点的数据。
备份节点的工作原理过程可以大致描述为,备份节点定期轮询主节点上的数据操作,然后对自己的数据副本进行这些操作,从而保证跟主节点的数据同步。
至于主节点上的所有数据库状态改变的操作,都会存放在一张特定的系统表中。备份节点则是根据这些数据进行自己的数据更新。
oplog
上面提到的数据库状态改变的操作,称为oplog(operation log,主节点操作记录)。oplog存储在local数据库的"oplog.rs"表中。副本集中备份节点异步的从主节点同步oplog,然后重新执行它记录的操作,以此达到了数据同步的作用。
关于oplog有几个注意的地方:
- oplog只记录改变数据库状态的操作
- 存储在oplog中的操作并不是和主节点执行的操作完全一样,例如"$inc"操作就会转化为"$set"操作
- oplog存储在固定集合中(capped collection),当oplog的数量超过oplogSize,新的操作就会覆盖就的操作
下面来看下oplog的一些具体内容,首先删除上一篇的node1-node3文件夹,重新建立副本集,但是这次限制oplogSize为5MB。
mongod.exe --dbpath="c:\mongodb\db\node1" --port= --replSet myReplSet --oplogSize=
mongod.exe --dbpath="c:\mongodb\db\node2" --port= --replSet myReplSet --oplogSize=
mongod.exe --dbpath="c:\mongodb\db\node3" --port= --replSet myReplSet --oplogSize=
然后通过MongoDB shell(连接主节点)插入一些数据
use test
db.person.insert({ "name" : "Will0", "gender" : "Female", "age" : })
db.person.insert({ "name" : "Will1", "gender" : "Female", "age" : })
通过一些命令就可以查看主节点的oplog了,通过oplog可以看到前面两条数据插入操作,备份节点接可以根据这两条记录更新自己的数据集。
use local
show collections
db.oplog.rs.find()

查看oplog表的状态,当前oplog有3条记录,oplog表是一个capped collection(固定大小集合),oplog表的大小是5242880B=5MB。
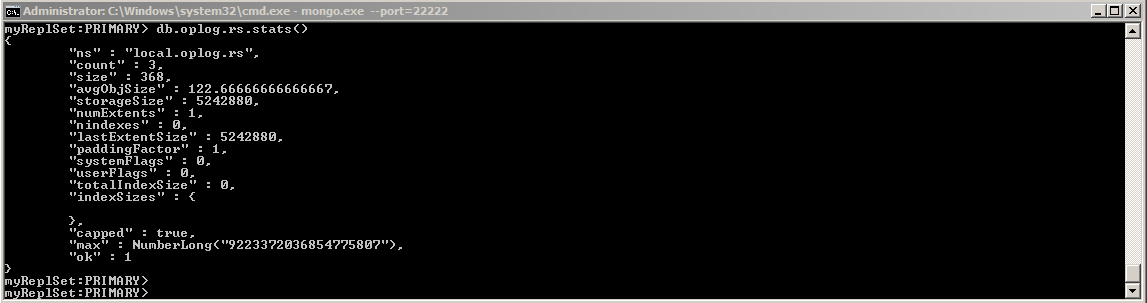
oplog数据结构
下面来分析一下oplog中字段的含义,通过下面的命令取出一条oplog:
db.oplog.rs.find().skip().limit().toArray()
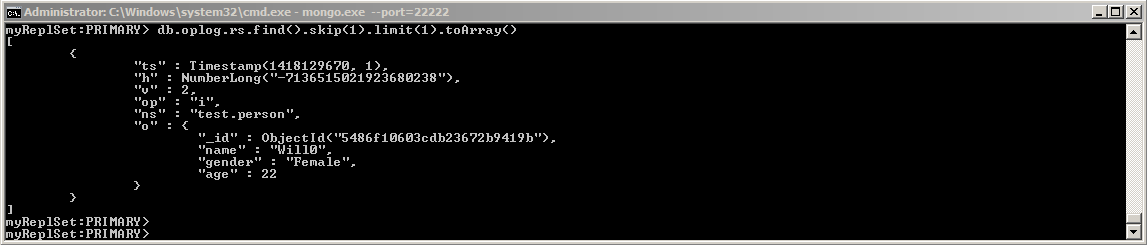
- ts: 8字节的时间戳,由4字节unix timestamp + 4字节自增计数表示。这个值很重要,在选举(如master宕机时)新primary时,会选择ts最大的那个secondary作为新primary
- op:1字节的操作类型
- "i": insert
- "u": update
- "d": delete
- "c": db cmd
- "db":声明当前数据库 (其中ns 被设置成为=>数据库名称+ '.')
- "n": no op,即空操作,其会定期执行以确保时效性
- ns:操作所在的namespace
- o:操作所对应的document,即当前操作的内容(比如更新操作时要更新的的字段和值)
- o2: 在执行更新操作时的where条件,仅限于update时才有该属性
oplog的大小
capped collection是MongoDB中一种提供高性能插入、读取和删除操作的固定大小集合,当集合被填满的时候,新的插入的文档会覆盖老的文档。
所以,oplog表使用capped collection是合理的,因为不可能无限制的增长oplog。MongoDB在初始化副本集的时候都会有一个默认的oplog大小:
- 在64位的Linux,Solaris,FreeBSD以及Windows系统上,MongoDB会分配磁盘剩余空间的5%作为oplog的大小,如果这部分小于1GB则分配1GB的空间
- 在64的OS X系统上会分配183MB
- 在32位的系统上则只分配48MB
oplog的大小设置是值得考虑的一个问题,如果oplog size过大,会浪费存储空间;如果oplog size过小,老的oplog记录很快就会被覆盖,那么宕机的节点就很容易出现无法同步数据的现象。
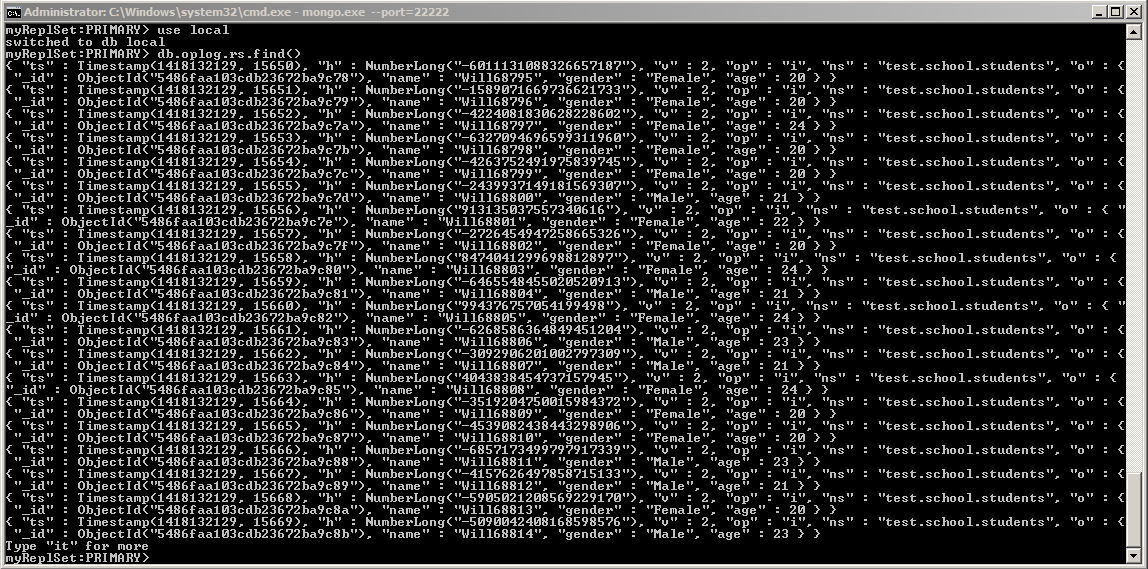
比如,基于上面的例子,我们停掉一个备份节点(port=33333),然后通过主节点插入以下记录,然后查看oplog,发现以前的oplog已经被覆盖了。
for(var i=;i<;i++){
var randAge = parseInt(*Math.random()) + ;
var gender = (randAge%)?"Male":"Female";
db.school.students.insert({"name":"Will"+i, "gender": gender, "age": randAge});
}
接下来重新启动上面停掉的备份节点(port=33333),从server的输出中可以看到,oplog已经太新了,备份节点无法进行同步了。

通过MongoDB shell连接上这个节点,会发现这个节点一直处于RECOVERING状态。

数据同步
在副本集中,有两种数据同步方式:
- initial sync(初始化):这个过程发生在当副本集中创建一个新的数据库或其中某个节点刚从宕机中恢复,或者向副本集中添加新的成员的时候,默认的,副本集中的节点会从离它最近的节点复制oplog来同步数据,这个最近的节点可以是primary也可以是拥有最新oplog副本的secondary节点。
- 该操作一般会重新初始化备份节点,开销较大
- replication(复制):在初始化后这个操作会一直持续的进行着,以保持各个secondary节点之间的数据同步。
initial sync
当遇到上面例子中无法同步的问题时,只能使用以下两种方式进行initial sync了
- 第一种方式就是停止该节点,然后删除目录中的文件,重新启动该节点。这样,这个节点就会执行initial sync
- 注意:通过这种方式,sync的时间是根据数据量大小的,如果数据量过大,sync时间就会很长
- 同时会有很多网络传输,可能会影响其他节点的工作
- 第二种方式,停止该节点,然后删除目录中的文件,找一个比较新的节点,然后把该节点目录中的文件拷贝到要sync的节点目录中
通过上面两种方式中的一种,都可以重新恢复"port=33333"的节点。不在进行截图了。
副本集管理
查看oplog的信息
通过"db.printReplicationInfo()"命令可以查看oplog的信息

字段说明:
- configured oplog size: oplog文件大小
- log length start to end: oplog日志的启用时间段
- oplog first event time: 第一个事务日志的产生时间
- oplog last event time: 最后一个事务日志的产生时间
- now: 现在的时间
查看slave状态
通过"db.printSlaveReplicationInfo()"可以查看slave的同步状态

当我们插入一条新的数据,然后重新检查slave状态时,就会发现sync时间更新了

总结
在这篇文章中介绍了副本集的工作原理,通过oplog以及数据同步进一步了解了副本集。
另外,实践中难免会碰到需要修改oplog size的情况,本篇文章没有进行介绍,请参考MongoDB文档中的步骤,修改oplog size
Ps:例子中所有的命令都可以参考以下链接
http://files.cnblogs.com/wilber2013/oplog.js
MongoDB副本集的工作原理的更多相关文章
- MongoDB复制集的工作原理介绍(二)
复制集工作原理 1)数据复制原理 开启复制集后,主节点会在 local 库下生成一个集合叫 oplog.rs,这是一个有限集合,也就是大小是固定的.其中记录的是整个mongod实例一段时间内数据库的所 ...
- MongoDB副本集(一主两从)读写分离、故障转移功能环境部署记录
Mongodb是一种非关系数据库(NoSQL),非关系型数据库的产生就是为了解决大数据量.高扩展性.高性能.灵活数据模型.高可用性.MongoDB官方已经不建议使用主从模式了,替代方案是采用副本集的模 ...
- Mongodb副本集实现及读写分离
前言 地址:https://blog.csdn.net/majinggogogo/article/details/51586409 作者介绍了,mongodb副本集的读写原理,原理是通过代码层来实现. ...
- mongodb副本集原理及部署记录
工作原理 1.副本集之间的复制是通过oplog日志现实的.备份节点通过查询这个集合就可以知道需要进行复制的操作 2.oplog是节点中local库中的一个固定的集合,在默认情况下oplog初始化大小为 ...
- MongoDB 副本集的原理、搭建、应用
概念: 在了解了这篇文章之后,可以进行该篇文章的说明和测试.MongoDB 副本集(Replica Set)是有自动故障恢复功能的主从集群,有一个Primary节点和一个或多个Secondary节点组 ...
- MongoDB副本集的常用操作及原理
本文是对MongoDB副本集常用操作的一个汇总,同时也穿插着介绍了操作背后的原理及注意点. 结合之前的文章:MongoDB副本集的搭建,大家可以在较短的时间内熟悉MongoDB的搭建和管理. 下面的操 ...
- MongoDB副本集的原理,搭建
介绍: mongodb副本集即客户端连接到整个副本集,不关心具体哪一台机器是否挂掉.主服务器负责整个副本集的读写,副本集定期同步数据备份,一旦主节点挂掉,副本节点就会选举一个新的主服务器,这一切对于应 ...
- MongoDB 副本集的常用操作及原理
本文是对MongoDB副本集常用操作的一个汇总,同时也穿插着介绍了操作背后的原理及注意点. 结合之前的文章:MongoDB副本集的搭建,大家可以在较短的时间内熟悉MongoDB的搭建和管理. 下面的操 ...
- (2)MongoDB副本集自动故障转移原理
前文我们搭建MongoDB三成员副本集,了解集群基本特性,今天我们围绕下图聊一聊背后的细节. 默认搭建的replica set均在主节点读写,辅助节点冗余部署,形成高可用和备份, 具备自动故障转移的能 ...
随机推荐
- 【转】MySQL分库分表数据迁移工具的设计与实现
一.背景 MySQL作为最流行的关系型数据库产品之一,当数据规模增大遭遇性能瓶颈时,最容易想到的解决方案就是分库分表.无论是进行水平拆分还是垂直拆分,第一步必然需要数据迁移与同步.由此可以衍生出一系列 ...
- Java注释规范整理
Version:0.9 StartHTML:-1 EndHTML:-1 StartFragment:00000099 EndFragment:00018736 在软件开发的过程中总是强调注释的规范,但 ...
- SAP MM/FI 自动过账实现 OBYC 接口执行
一. 自动过账原理 在MM模块的许多操作都能实现在FI模块自动过账,如PO收货.发票验证(LIV).工单发料.向生产车间发料等等.不用说,一定需要在IMG中进行配置才可以实现自动处理.但SAP实现的这 ...
- matlab中常用的函数
find()函数: 功能:用于返回矩阵中想要的元素的索引值: 用法: index = find(X), 当X为一个矩阵时,返回的index是一个列向量,表示矩阵X中非零值的索引值,这个索引值吧,是按把 ...
- BIO、NIO、AIO系列一:NIO
一.几个基本概念 1.同步.异步.阻塞.非阻塞 同步:用户触发IO操作,你发起了请求就得等着对方给你返回结果,你不能走,针对调用方的,你发起了请求你等 异步:触发触发了IO操作,即发起了请求以后可以做 ...
- (原)关于sdl在部分机器上做视频显示,改变显示窗口大小会崩溃
今天测试人员反应,之前做的视频绘图显示,会在她机器上,会出现崩溃现象,最后我在她机器上对代码进行跟踪,发现在某种情况,确实会崩溃. 最主要的原因是,视频显示窗口变成非活动窗口的时候,sdl内部会循环消 ...
- (转)Live555单线程原理
1. 概述 在live555-Server库中,使用单线程实现了多用户请求视频数据,这似乎多线程才能实现的功能,并且用户请求视频数据各个流程衔接的都十分完美,其执行效率非常高. live555是如何实 ...
- 指定webapi 返回 json 格式 ; GlobalConfiguration.Configuration.Formatters.Clear()
因为 Internet Explorer 和 Firefox 发送了不同的 Accept 头,所以 web API 在响应里就发送了不同的内容类型. 解决方法,在 Global.asax的 App ...
- 精选10款超酷的HTML5/CSS3菜单
今天向大家精选了10款超酷的HTML5/CSS3菜单,给你的网页添加不一样的精彩,一起来围观一下吧. 1.CSS3手风琴菜单 下拉展开带弹性动画 利用CSS3技术可以实现各种各样的网页菜单,我们之前也 ...
- springboot - Constructor、@Autowired、@PostConstruct分析
1.Constructor 构造方法 2.@Autowired 依赖注入 3.@PostConstruct 在依赖注入完成后被自动调用 4. 三者的顺序: 从依赖注入的字面意思就可以知道,要将对象p注 ...