Spark-2.0原理分析-shuffle过程
shuffle概览
shuffle过程概览
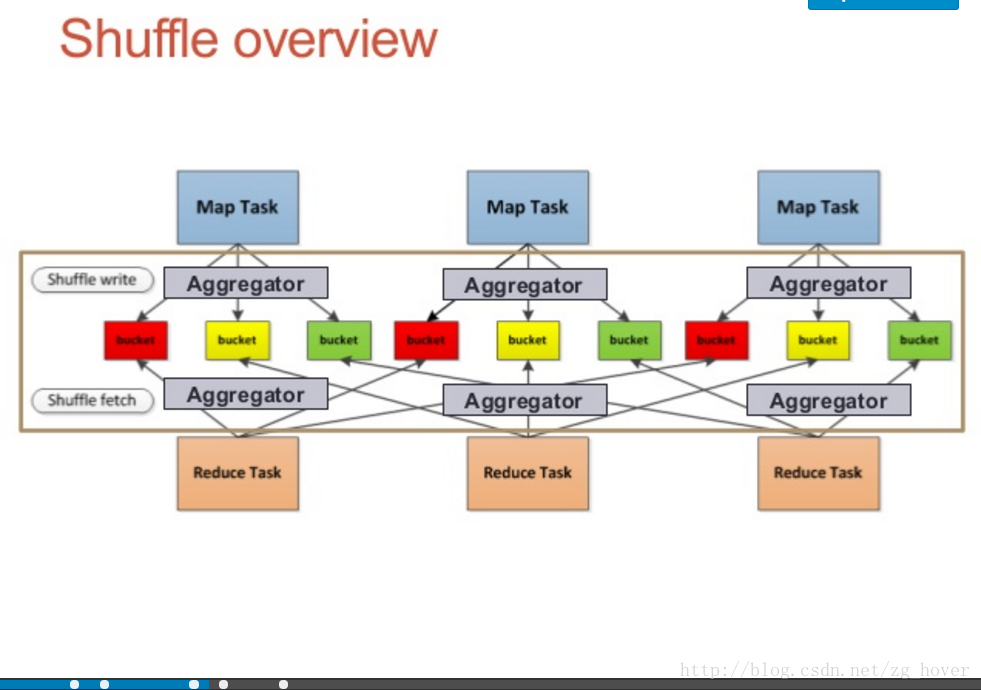
shuffle数据流概览
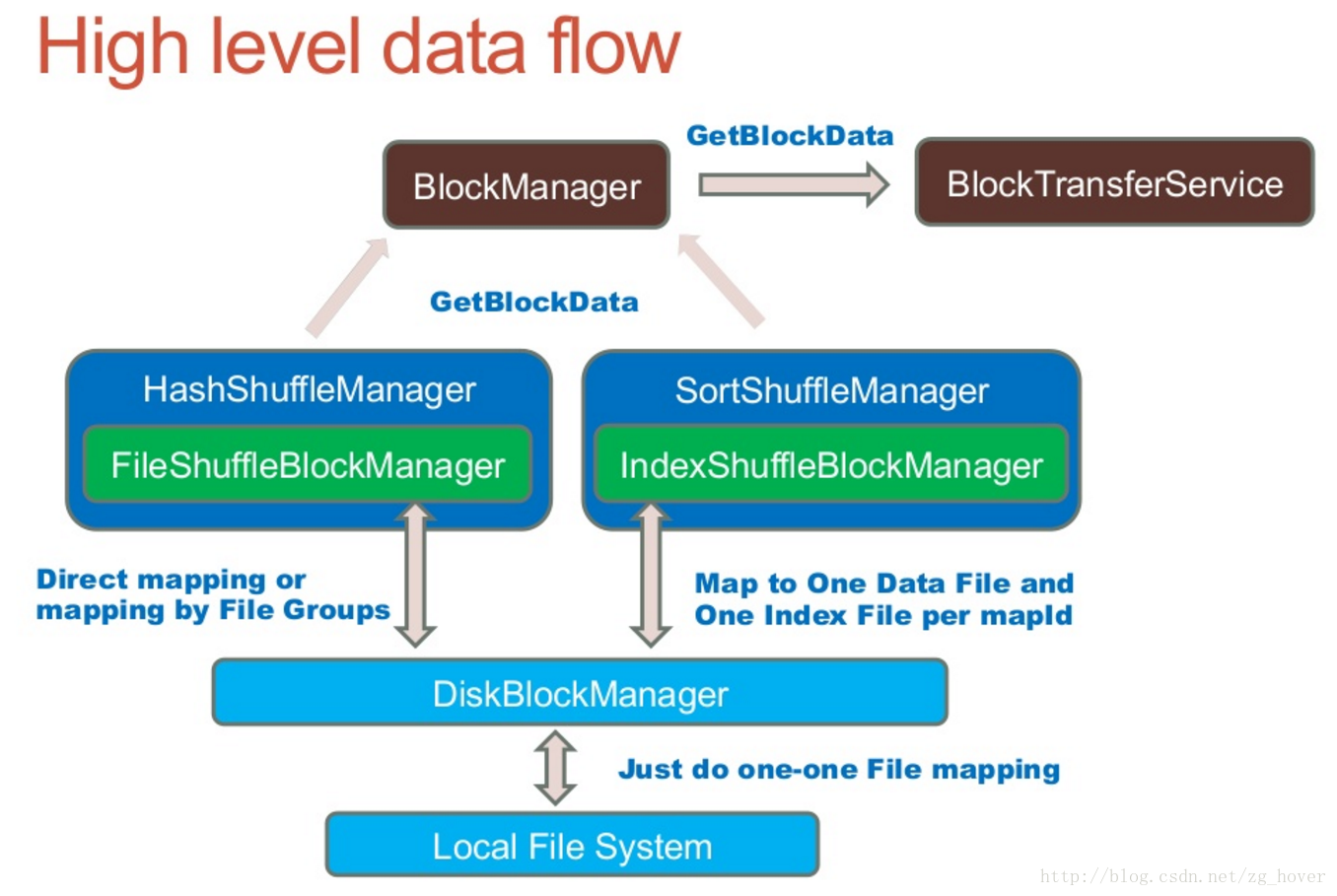
shuffle数据流
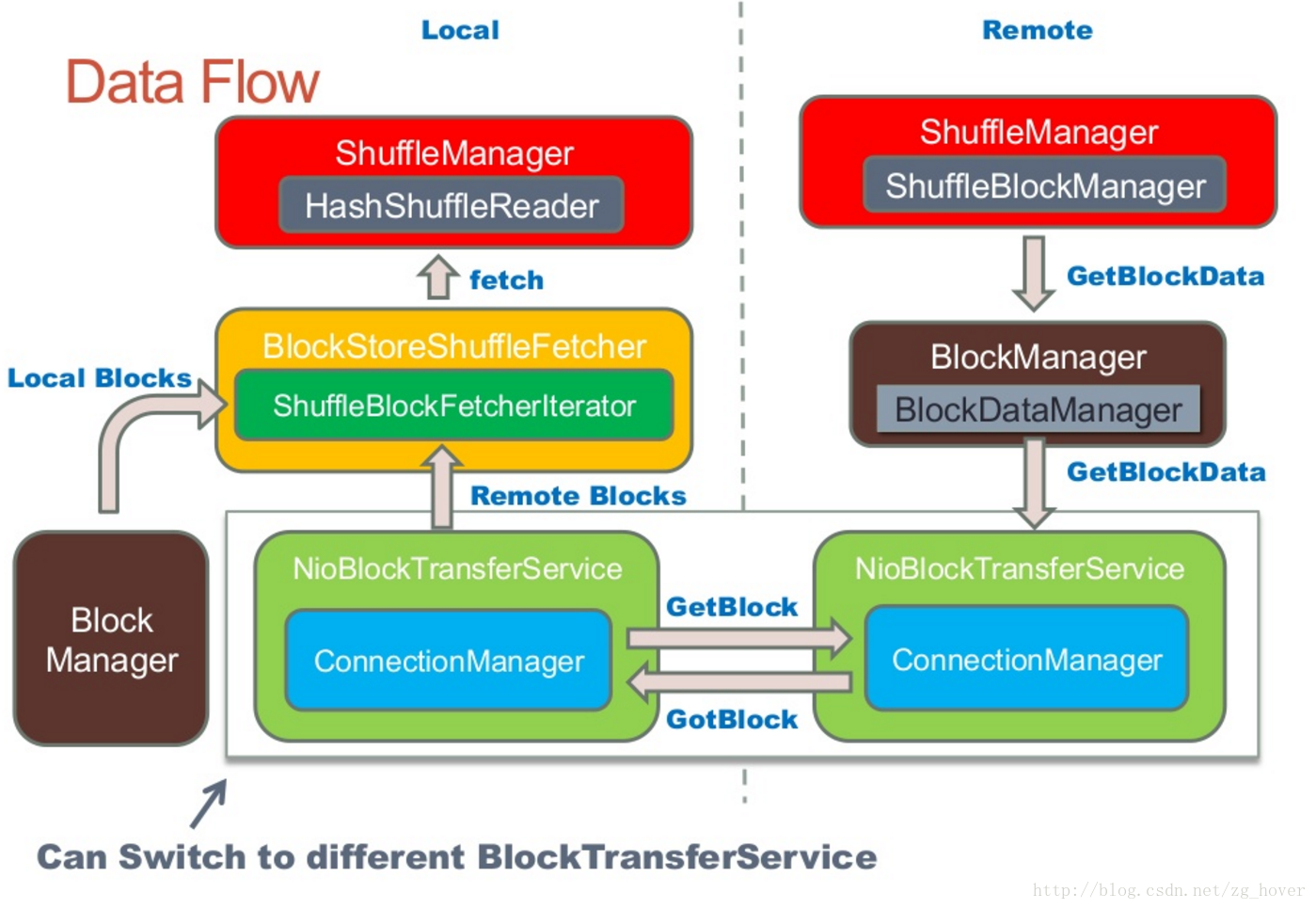
shuffle工作流程
在运行job时,spark是一个stage一个stage执行的。先把任务分成stage,在任务提交阶段会把任务形成taskset,在执行任务。
spark的DAGScheduler根据RDD的ShuffleDependency来构建Stages:
- 例如:ShuffleRDD/CoGroupedRDD有一个ShuffleDependency。
- 很多操作通过钩子函数来创建ShuffleRDD
每个ShuffleDependency会map到spark的job的一个stage,然后会导致一个shuffle过程。
为什么shuffle过程代价很大
这是由于shuffle过程可能需要完成以下过程:
- 重新进行数据分区
- 数据传输
- 数据压缩
- 磁盘I/O
shuffle的体系结构
ShuffleManager接口
shuffleManager是spark的shuffle系统的可插拔接口。ShuffleManager将会在driver和每个executor上的SparkEnv中进行创建。可以通过参数spark.shuffle.manager进行设置。
driver通过ShuffleManager来注册shuffle,并且executor通过它来读取和写入数据。
ShuffleWriter
控制shuffle数据输出逻辑。
ShuffleReader
获取shuffle过程中用于ShuffleRDD的数据。
ShuffleBlockManager
管理抽象的bucket和计算数据块之间的mapping过程。
基于sort的shuffle
sort-based的shuffle,会把输入的记录根据目标分区id(partition ids)进行排序。然后写入单个的map输出文件中。为了读取map的输出部分,Reducers获取此文件的连续区域 。当map输出的数据太大而内存无法存放时,输出的排序子集可以保存到磁盘,这些磁盘文件被合并后,生成最终的输出文件。
sort shuffle有两个不同的输出路径来产生map的输出文件:
- 序列化排序(Serialized sorting)
在使用序列化排序时,需要满足以下3个条件:- shuffle不指定聚合(aggregation)或输出排序方法。
- shuffle的序列化程序支持序列化值的重定位(KryoSerializer和Spark SQL的自定义序列化程序目前支持此操作)。
- shuffle产生小于16777216个输出分区。
- 反序列化排序(Deserialized sorting)
用来处理所有其他情况。
Sort Shuffle Manager
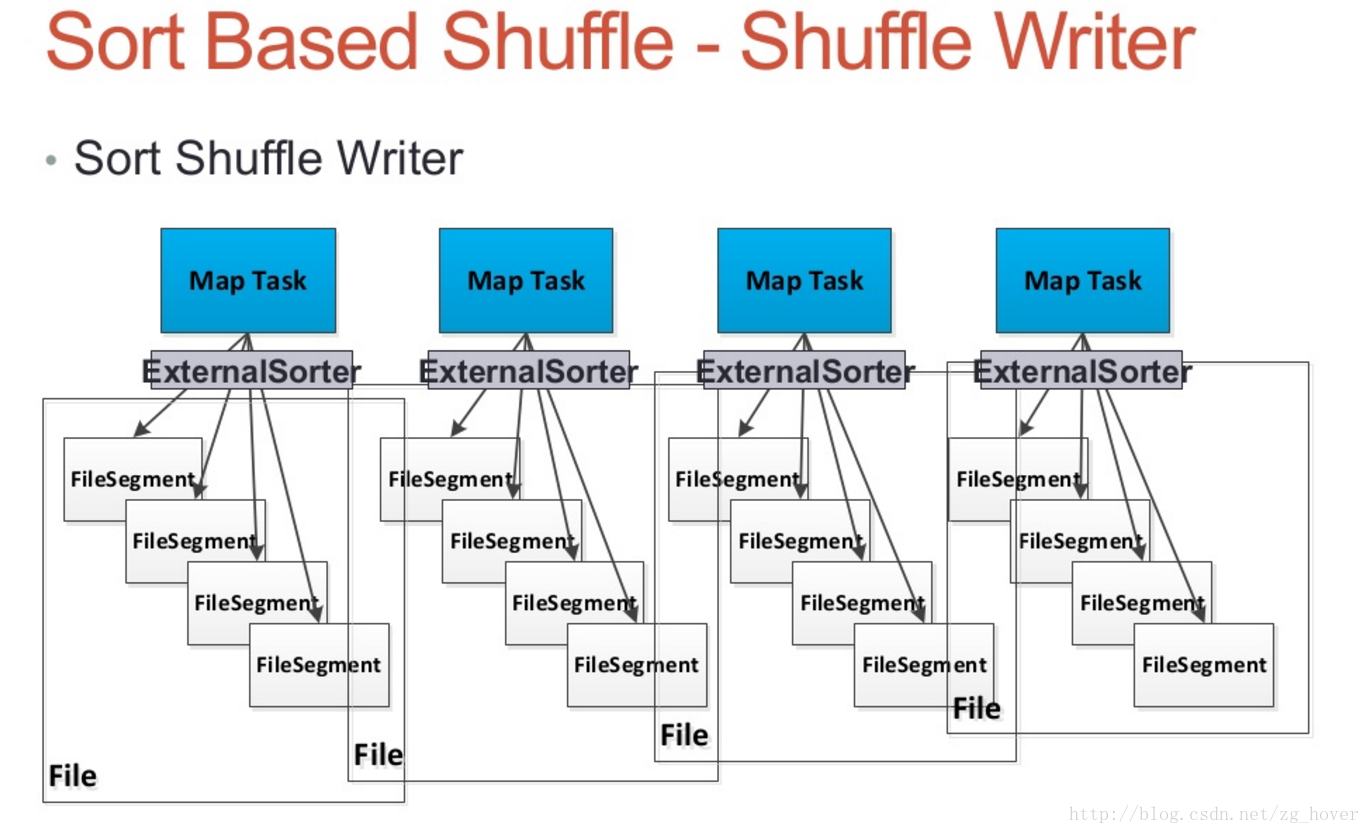
Sort Shuffle Writer
- 每个map任务都会产生一个shuffle数据文件,和一个Index文件
- 通过外部排序类ExternalSorter对数据进行排序
- 若map-side需要进行合并(combine)操作,数据将会按key和分区进行排序,若没有合并操作数据只会根据分区进行排序。
Spark-2.0原理分析-shuffle过程的更多相关文章
- Spark之Task原理分析
在Spark中,一个应用程序要想被执行,肯定要经过以下的步骤: 从这个路线得知,最终一个job是依赖于分布在集群不同节点中的task,通过并行或者并发的运行来完成真正的工作.由此可见 ...
- 小记--------spark的worker原理分析及源码分析
- Struts1.2,struts2.0原理分析
struts1原理: 1.首先我们表单提交到action 2.进入到web.xml 3.web.xml拦截*.do 4.交给ActionServlet 5.找到path属性,获得url 6.找到nam ...
- 小记--------spark内核架构原理分析
首先会将jar包上传到机器(服务器上) 1.在这台机器上会产生一个Application(也就是自己的spark程序) 2.然后通过spark-submit(shell) 提交程序 ...
- 彻底搞懂spark的shuffle过程(shuffle write)
什么时候需要 shuffle writer 假如我们有个 spark job 依赖关系如下 我们抽象出来其中的rdd和依赖关系: E <-------n------, ...
- Spark Shuffle 过程
本文参考:http://www.cnblogs.com/cenyuhai/p/3826227.html 在数据流动的整个过程中,最复杂最影响性能的环节,就是 Shuffle 过程,本文将参考大神的博客 ...
- Hadoop计算中的Shuffle过程(转)
Hadoop计算中的Shuffle过程 作者:左坚 来源:清华万博 时间:2013-07-02 15:04:44.0 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解Ma ...
- spark的shuffle和原理分析
概述 Shuffle就是对数据进行重组,由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂. 在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段 ...
- Spark的RDD原理以及2.0特性的介绍
转载自:http://www.tuicool.com/articles/7VNfyif 王联辉,曾在腾讯,Intel 等公司从事大数据相关的工作.2013 年 - 2016 年先后负责腾讯 Yarn ...
随机推荐
- SQL - 根据天来分组比较
SELECT COUNT(*) FROM (SELECT WeixinUserID,CONVERT(varchar(100),CreateTime, 23) AS DT FROM SiteVisite ...
- 【Linux基础学习】Ubuntu 常用命令大全
一.文件目录类 1.建立目录:mkdir 目录名 2.删除空目录:rmdir 目录名 3.无条件删除子目录: rm -rf 目录名 4.改变当前目录:cd 目录名 (进入用户home目录:cd ~:进 ...
- kubernetes 测试 Mariadb gtid 主从复制.
k8s 为 1个master 3个node 下载镜像 : mariadb 镜像版本是10.2.13 (此时10.3还没发布正式版) docker pull mariadb push到私有仓库 dock ...
- Material Design系列第七篇——Maintaining Compatibility
Maintaining Compatibility This lesson teaches you to Define Alternative Styles Provide Alternative L ...
- python中级---->pymongo存储json数据
这里面我们介绍一下python中操作mangodb的第三方库pymongo的使用,以及简单的使用requests库作爬虫.人情冷暖正如花开花谢,不如将这种现象,想成一种必然的季节. pymongo的安 ...
- Trie树的分析与实现
字典树 又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种.典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计.它的优点是:利用字符串的 ...
- Mysql命令行导入sql数据
mysqldump 是在 操作系统命令行下运行的,不是在 MySQL 命令行下运行的. 登陆数据库: 登陆本地mysql : mysql -h localhost -u root -p123456 ...
- 【CF840D】Destiny 分治(线段树)
[CF840D]Destiny 题意:给你一个长度为n的序列,q次询问,每次指定l r k,求[l,r]中出现次数$>\frac {r-l+1} k$的所有数中最小的那个数. $n,q\le 3 ...
- python nose测试框架全面介绍九---各种html报告插件对比
一直在使用Nose-html-reporting,并输出html报告,但今天在使用时发出有点问题:于时,将python目前可能的html报告插件下载后进行对比,如下 一.Nose-html-repor ...
- Spark版本发布历史,及其各版本特性
2016年11月5日 We are proud to announce that Apache Spark won the 2016 CloudSort Benchmark (both Dayto ...