Hadoop自学笔记(三)MapReduce简单介绍
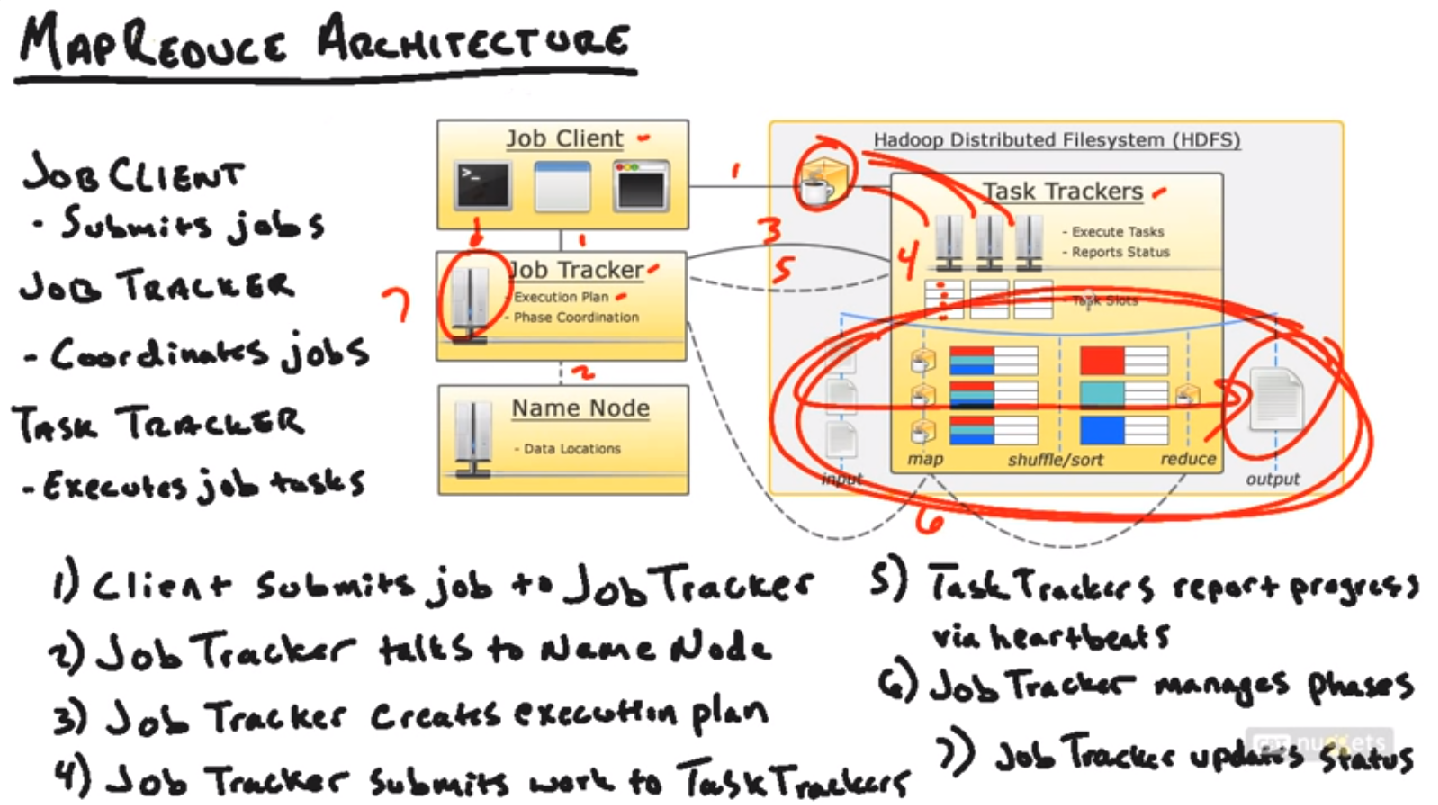
1. MapReduce Architecture
MapReduce是一套可编程的框架,大部分MapReduce的工作都能够用Pig或者Hive完毕。可是还是要了解MapReduce本身是怎样工作的,由于这才是Hadoop的核心,而且能够为以后优化和自己写做准备。
Job Client, 就是用户
Job Tracker和Task Tracker也是一种Master - Slave构建
工作流程(MapReduce Pipeline)
Job Client提交了MapReduce的程序(比方jar包中的二进制文件)。所须要的数据,结果输出位置,提交给Job Tracker. Job Tracker会首先询问Name Node, 所须要的数据都在哪些block里面,然后就近选择一个Task Tracker(离这些所需数据近期的一个task tracker,可能是在同一个Node上或者同一个Rack上或者不同rack上),把这个任务发送给该Task Tracker, Task Tracker来真正运行该任务。Task Tracker内部有Task Slots来真正运行这些任务。假设运行失败了。Task Tracker就好汇报给Job Tracker, Job Tracker就再分配给别的Task Tracker来运行。Task Tracker在运行过程中要不断的向Job Tracker汇报。最后Task Tracker运行完毕后,汇报给Job Tracker。Job Tracker就更新任务状态为成功。
注意,当用户提交一个MapReduce任务的时候,不只同一时候把任务提交给Job Tracker,同一时候还会拷贝一份到HDFS的一个公共位置(图中的咖啡位置),由于传递代码和命令相对要easy一些。然后Task Tracker就能够非常方便的得到这些代码。
详细步骤就是图中的7步。
2. MapReduce Internals
Split阶段:依据Input Format。把输入数据切割成小部分,该阶段与Map任务同一时候运行,切割后就放到不同的Mapper里面。
Input Format: 决定了数据怎样被切割放入Mapper。比方Log, 数据库,二进制码,等。
Map阶段:把切割后传入的splits转化成一些key-value对。怎样转化取决于用户代码怎么写的。
Shuffle & Sort阶段:把Map阶段得到的数据归类,然后送给Reducers。
Reduce阶段:把送入的Map数据(Key, Value)依照用户的代码进行整合处理。
Output Format: Reduce阶段处理完后。结果依照此格式放入HDFS的输出文件夹。
Imperative Programming Paradigm: 把计算当做一系列改变程序状态的过程。
也就是程序化编程。更加关注对象和状态。
Functional Programming Paradigm: 大致就是函数化编程,把一系列计算作为一个数学函数。Hadoop使用的是这样的编程范式。
有输入,有输出;没有对象没有状态。
为了优化起见,Hadoop还加入了很多其它的一个接口,combine阶段,见下图。主要是在输送到Shuffle/sort阶段前。如今本地进行一次小的Reduce计算。这样能够省非常多带宽(还记得job的代码放入一个公共区域了吗)
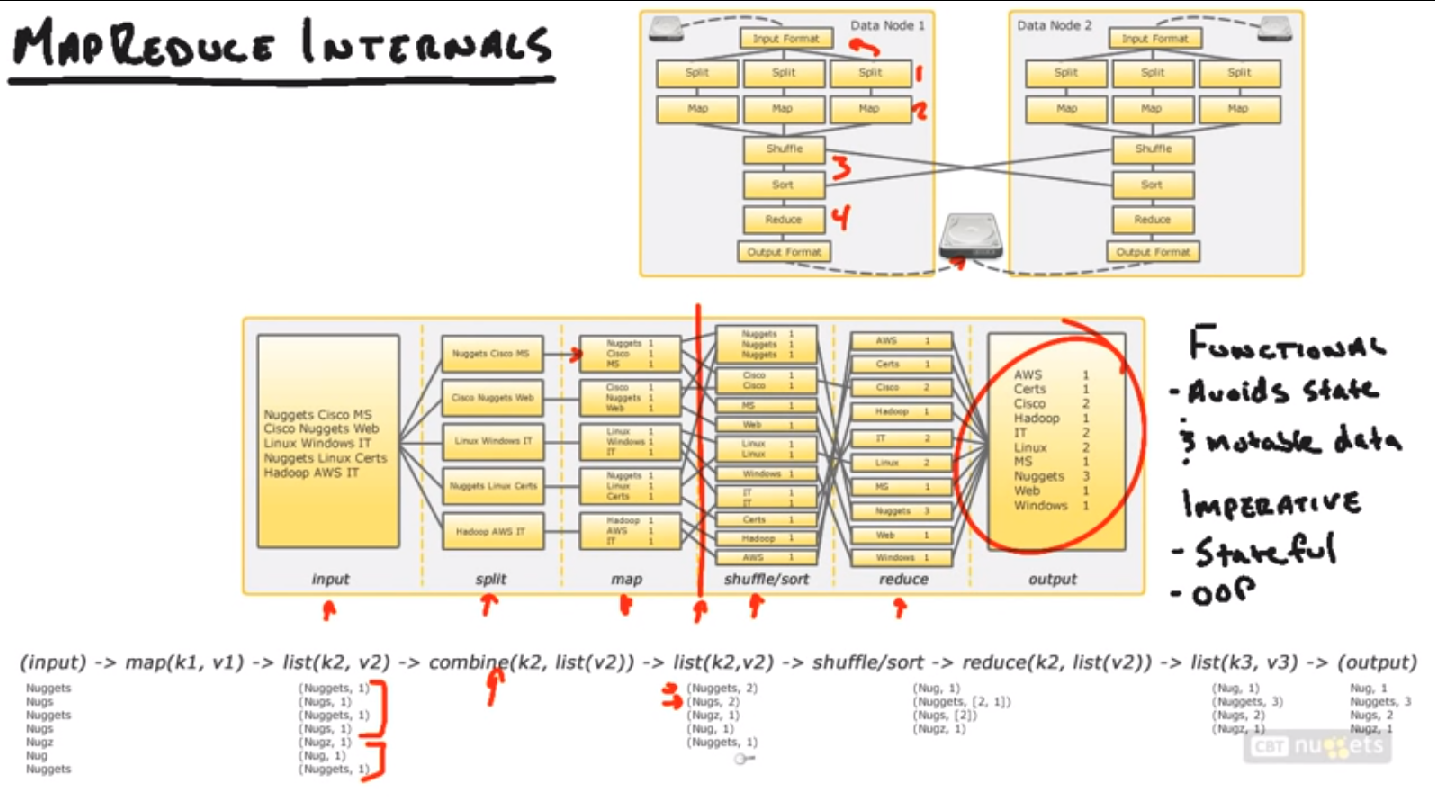
上面的整个过程看上去可能不那么直观,可是这是Hadoop最难理解的部分了。理解了这个流程(Hadoop Pipeline),就更easy理解以后的内容了。
3. MapReduce Example
举样例来说明,在实际的机器操作中Hadoop怎样完毕上述任务。
在Windows环境下安装了一个hyperV软件。里面有四个Hadoop节点。每一个Hadoop节点都是一个Ubuntu环境。
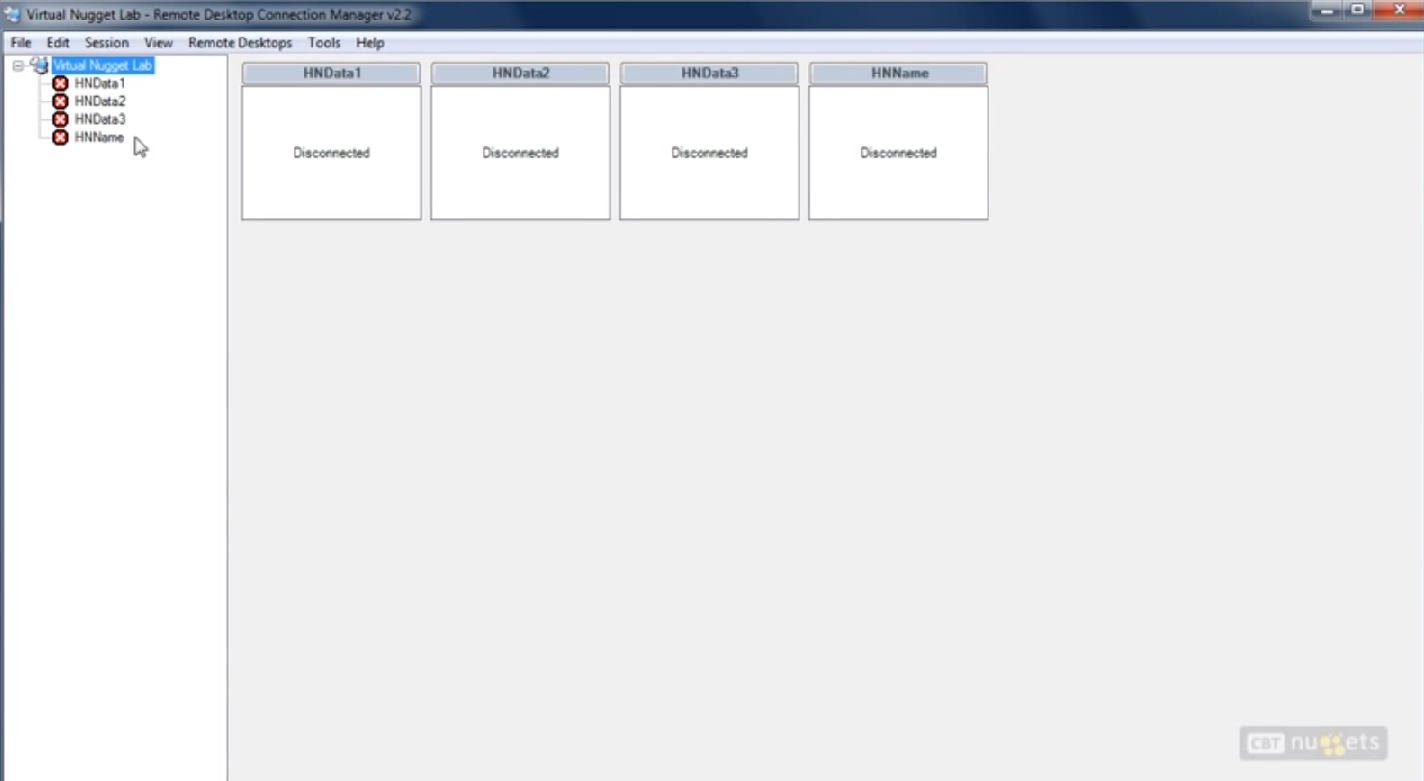
能够看到上面有一个Name Node,还有三个Data Node。
首先,连接上Name Node。而且打开一个Data Node节点。
进入Name Node的Ubuntu系统中。打开一个终端。输入jps,能够看到jvm里面正在运行的东西。
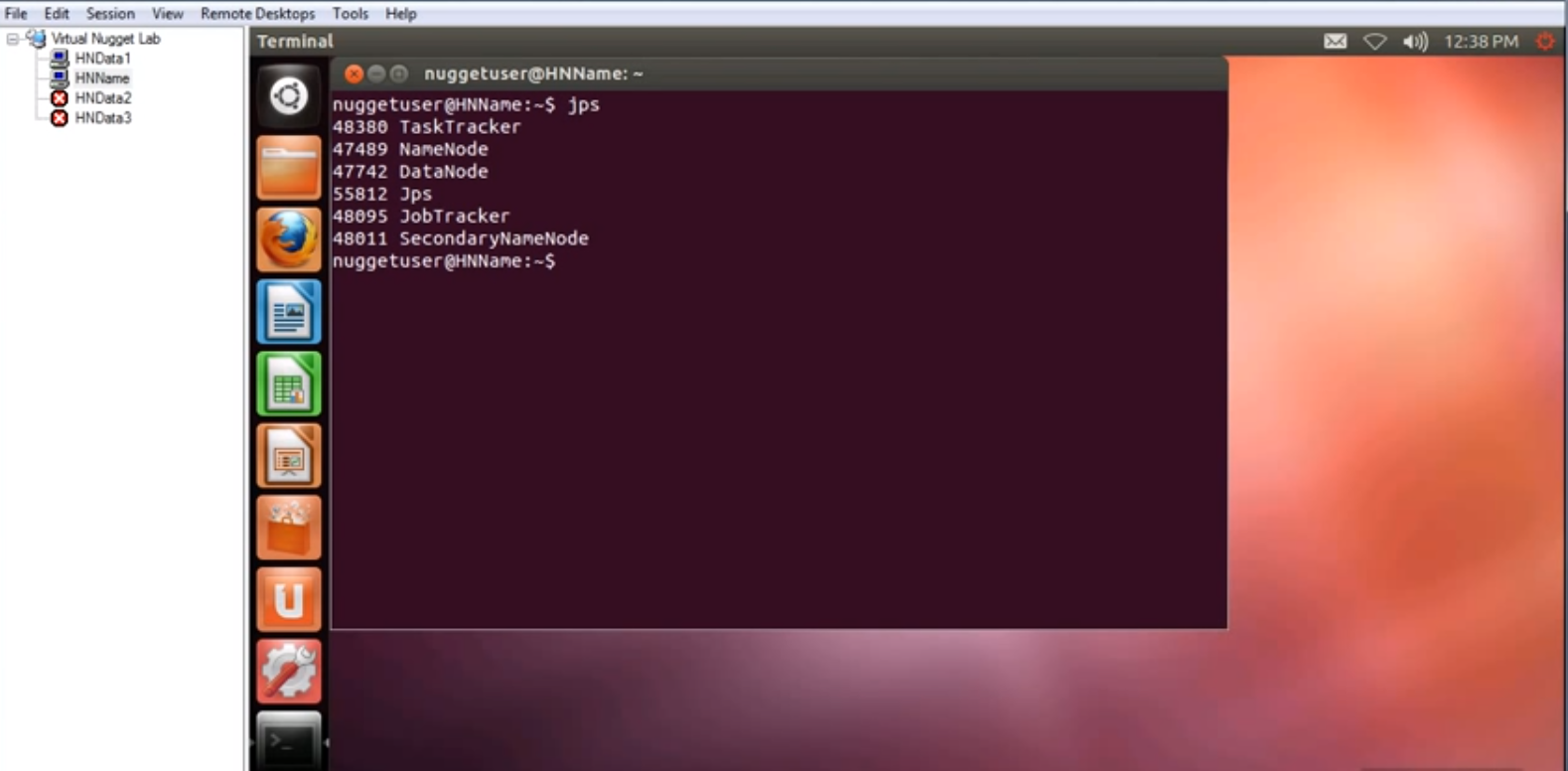
在Data Node机器中运行相同命令,能够看到里面运行着DataNode, Jps, TaskTracker三个内容。
首先进入Data Node的机器里面。到根文件夹以下创建一个文件,叫words.txt,文件内容就是上图中要分析的一些词。
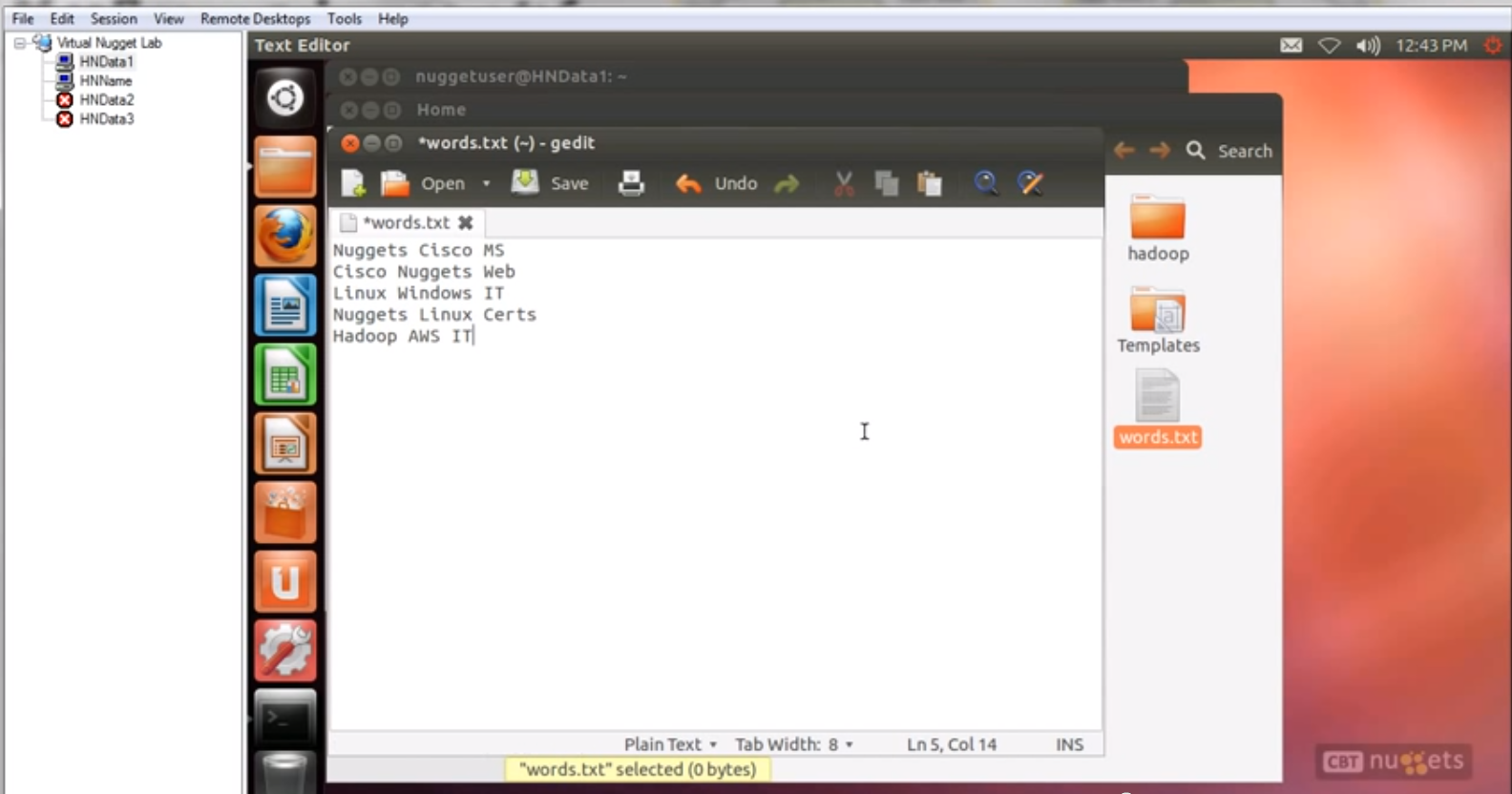
第二步。把这个Words.txt文件放入HDFS中。
首先
hadoop/bin/hadoop fs -ls
查看眼下HDFS中的文件
然后新建一个文件夹
Hadoop/bin/hadoop fs -mkdir /data
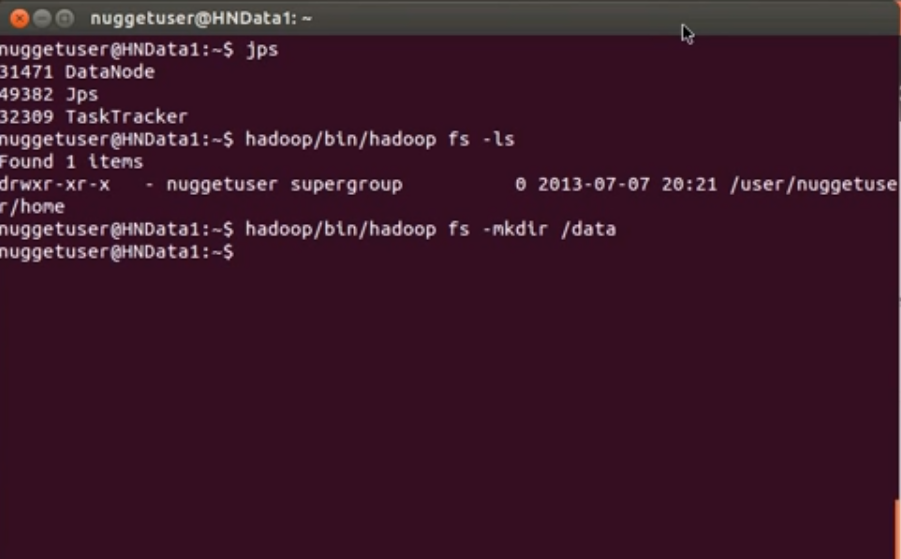
我们能够使用浏览器来看看HDFS中的文件系统
浏览器中输入hnname:50070,打开Web UI

能够再Live Nodes里面看到刚刚新建的data文件夹。运行
hadoop/bin/hadoop fs -copyFromLocal words.txt /data
然后words.txt就复制到/data文件夹下了。能够使用Web UI来验证。
第三步,运行MapReduce 任务。
这个任务是统计单词频率,这个任务已经由现成的jar包写好了,在hadoop/bin/文件夹下,hadoop-examples-1.2.0.jar. 这个文件中面有非常多非常多写好的MapReduce任务。
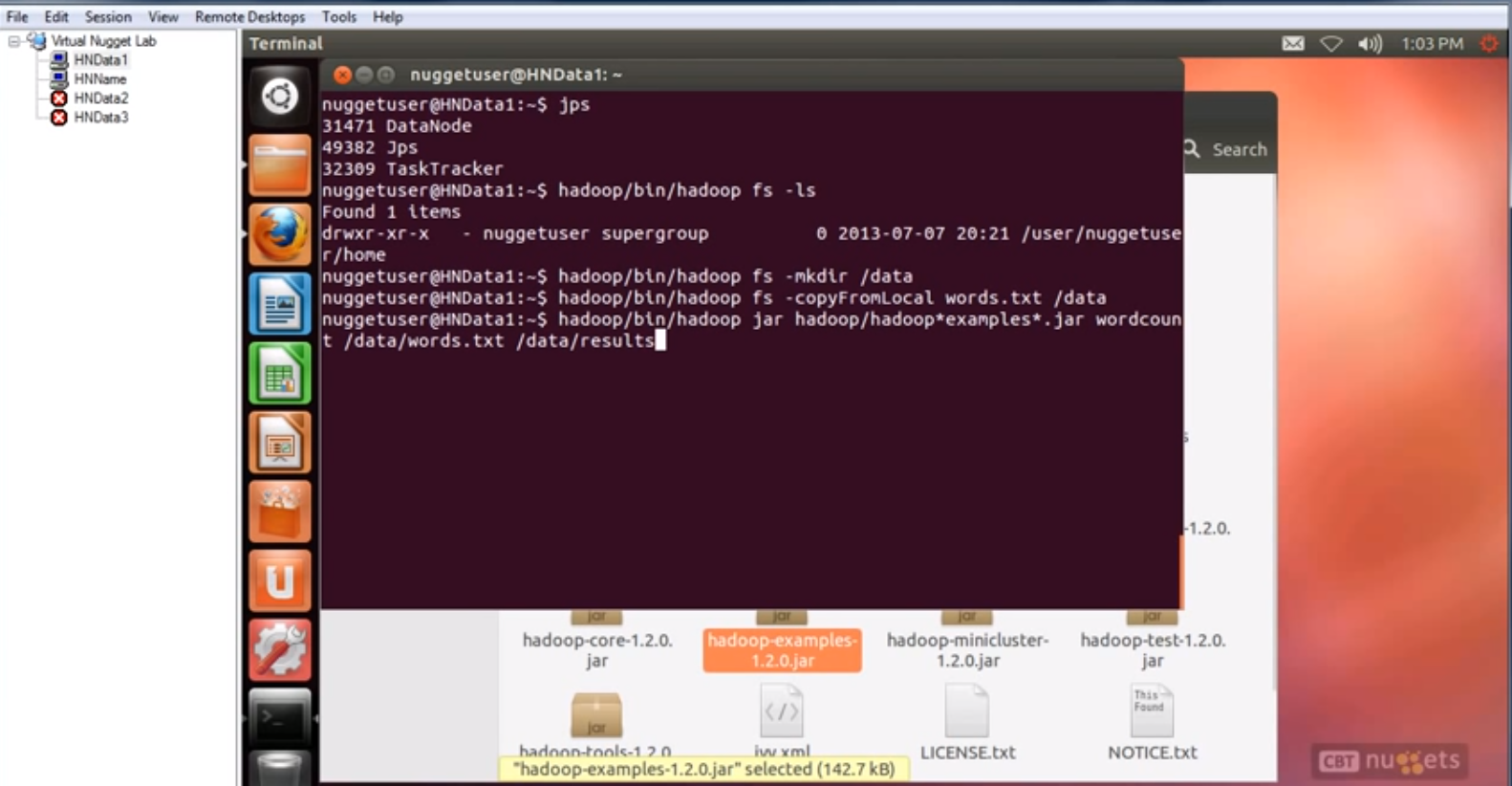
运行命令:
Hadoop/bin/hadoop jar hadoop/hadoop*examples.jar wordcount /data/words.txt /data/results
先指定jar包,再指定程序名wordcount, 再指定输入数据/data/words.txt 最后是输出文件夹/data/results, 没有文件夹会创建一个。
运行完毕后。能够通过Web UI来看运行结果。
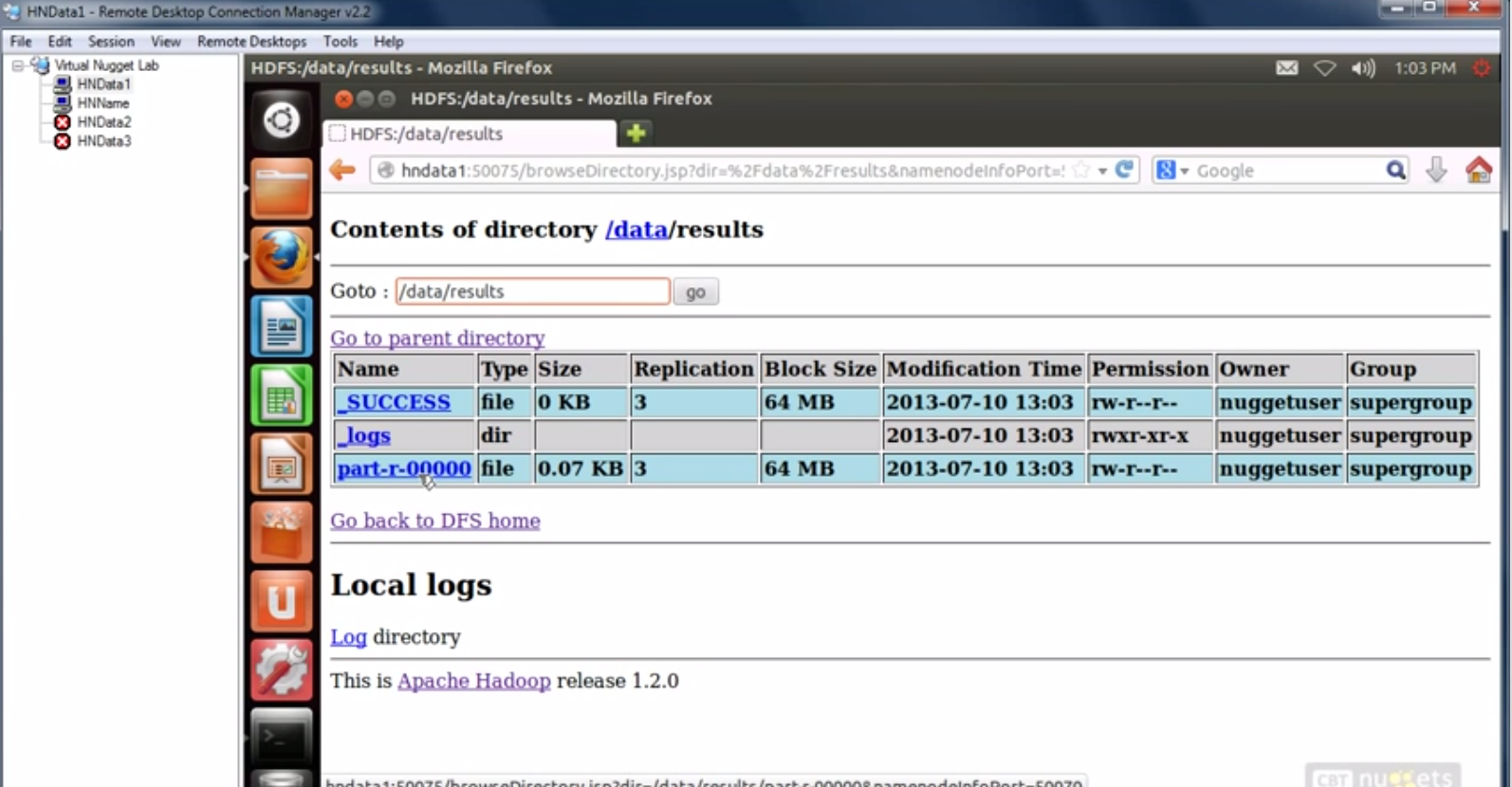
我擦。原来的图片太多了发不了。不得不说删掉几张。
。。。
Hadoop自学笔记(三)MapReduce简单介绍的更多相关文章
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- Hadoop自学笔记(一)常见Hadoop相关项目一览
本自学笔记来自于Yutube上的视频Hadoop系列.网址: https://www.youtube.com/watch?v=-TaAVaAwZTs(当中一个) 以后不再赘述 自学笔记,难免有各类错误 ...
- 学习笔记-React的简单介绍&工作原理
一.React简单介绍 1.React起源于Facebook内部项目,与2013年5月 2.是一个用于构建用户界面的JavaScript库 二.React特点 1.声明式设计-React采用声明范式, ...
- JMeter自学笔记2-图形界面介绍
一.写在前面的话: 上篇我们已经学会了如何安装JMeter和打开JMeter,那么这篇我们将对JMeter的图形界面做一个简单的介绍.大家只要简单的了解即可,无需死记硬背,在今后的学习和使用中慢慢熟悉 ...
- [Docker]学习笔记--简单介绍
学习docker已经有一段时间了,一直没有静下心来好好总结一下. 最近用docker搭了一整套Gitlab的持续集成环境.(会在下一篇中详细的讲解具体步骤,敬请期待) 感觉是时候写点东西和大家一起分享 ...
- Android Studio 学习笔记(三):简单控件及实例
控件.组件.插件概念区分 说到控件,就不得不区分一些概念. 控件(Control):编程中用到的部件 组件(Component):软件的组成部分 插件(plugin): 应用程序中已经预留接口的组件 ...
- Hadoop自学笔记(二)HDFS简单介绍
1. HDFS Architecture 一种Master-Slave结构.包括Name Node, Secondary Name Node,Data Node Job Tracker, Task T ...
- 三、Hadoop学习笔记————从MapReduce到Yarn
Yarn减轻了JobTracker的负担,对其进行了解耦
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
随机推荐
- php基础设计模式 注册树模式、工厂模式、单列模式
废话不多说了,先给大家介绍注册树模式然后介绍工厂模式最后给大家介绍单列模式,本文写的很详细,一起来学习吧. php注册树模式 什么是注册树模式? 注册树模式当然也叫注册模式,注册器模式.之所以我在这里 ...
- Linux下的XAMPP基本配置技巧(设置虚拟主机、添加FTP账户等)
xampp安装好之后就只有一个默认站点及一个默认nobody的ftp账户,这显然不符合我们平时的需求了,那么下面就来讲一下如何设置并管理多个虚拟主机及ftp账户了,至于xampp的安装不在此讨论范围, ...
- SQL - ROW_NUMBER,Rank 添加序号列
百度的时候查到的博客: http://blog.csdn.net/xsfqh/article/details/6663895-------------------------------------- ...
- jquery.gritter.js简介
Gritter 是一个小型的 jQuery 消息通知插件,通知效果如下图所示: 参考网
- python中级---->pymongo存储json数据
这里面我们介绍一下python中操作mangodb的第三方库pymongo的使用,以及简单的使用requests库作爬虫.人情冷暖正如花开花谢,不如将这种现象,想成一种必然的季节. pymongo的安 ...
- 异构GoldenGate 12c 单向复制配置
1.分别在windows2008.linux平台部署oracle 11.2.0.4 2.分别在windows2008.linux平台部署gg. 2.1 windows平台: gg的安装目录位 C:\o ...
- C语言位操作--判断整数是否为2的幂
unsigned int v; // 判断v是否为2的幂 bool f; // f为判断的结果 f = (v & (v - 1)) == 0; // 结果为0表示不是2 的幂 // 改变表示方 ...
- Unity3D 面试ABC
最先执行的方法是: 1.(激活时的初始化代码)Awake,2.Start.3.Update[FixUpdate.LateUpdate].4.(渲染模块)OnGUI.5.再向后,就是卸载模块(TearD ...
- SVG学习笔录(一)
SVG可缩放矢量图形(Scalable Vector Graphics)这项技术,现在越来越让大家熟知,在h5的移动端应用使用也越来越广泛了, 下面让我分享给大家svg学习的经验. HTML体系中,最 ...
- vue--子组件主动获取父组件的数据和方法
子组件主动获取父组件的数据和方法 简单示例: this.$parent.数组 this.$parent.方法 示例: <template> <div id="Header& ...