storm并发机制,通信机制,任务提交
一、storm的并发
(1)Workers(JVMs):在一个物理节点上可以运行一个或多个独立的JVM进程。一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上),所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology
(2)Executors(threads):在一个workerJVM进程中运行着多个Java线程。一个executor线程可以执行一个或多个tasks。但一般默认每个executor只执行一个task。一个worker可以包含一个或多个executor,每个component(spout/bolt)至少对应于一个executor,所以可以说executor执行一个compenent(spout/bolt)的子集,同时一个executor只能对应于一个component(spout/bolt)。
(3)Tasks(bolt/spout instances):Task就是具体的处理逻辑对象,每一个Spout和Bolt会被当作很多task在整个集群里面执行。每一个task对应到一个线程,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。
(4)对于并发度的配置, 在storm里面可以在多个地方进行配置,在defaults.yaml,storm.yaml,topology-specific configuration,internal component-specific configuration,external component-specific configuration 中均可以对并发度进行配置
(5)worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大亍machines的数目
executor的数目, component的并发线程数,只能在代码中配置(通过setBolt和setSpout的参数)
(6)tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置Topology的worker数通过config设置,即执行该topology的worker(java)进程数,可以通过storm rebalance命令任意调整。
二、storm的通信机制
worker进程间消息传递机制,消息的接收和处理的大概流程如下图:
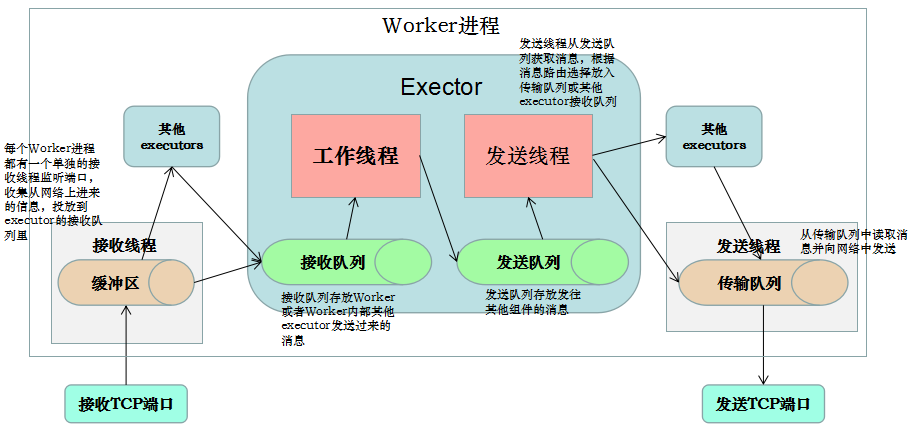
(1)对于worker进程来说,为了管理流入和传出的消息,每个worker进程有一个独立的接收线程[一个worker进程运行一个专用的接收线程来负责将外部发送过来的消息移动到对应的executor线程的incoming-queue中](对配置的TCP端口supervisor.slots.ports进行监听);
(2)对应Worker接收线程,每个worker存在一个独立的发送线程[transfer-queue的大小由参数topology.transfer.buffer.size来设置。transfer-queue的每个元素实际上代表一个tuple的集合],它负责从worker的transfer-queue中读取消息,并通过网络发送给其他worker
(3)每个executor有自己的incoming-queue[executor的incoming-queue的大小用户可以自定义配置。]和outgoing-queue[executor的outgoing-queue的大小用户可以自定义配置]。Worker接收线程将收到的消息通过task编号传递给对应的executor(一个或多个)的incoming-queues;
(4)每个executor有单独的线程分别来处理spout/bolt的业务逻辑,业务逻辑输出的中间数据会存放在outgoing-queue中,当executor的outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到transfer-queue中。
(5)每个worker进程控制一个或多个executor线程,用户可在代码中进行配置。其实就是我们在代码中设置的并发度个数。
三、storm的任务提交
storm的任务提交机制大概如下图:
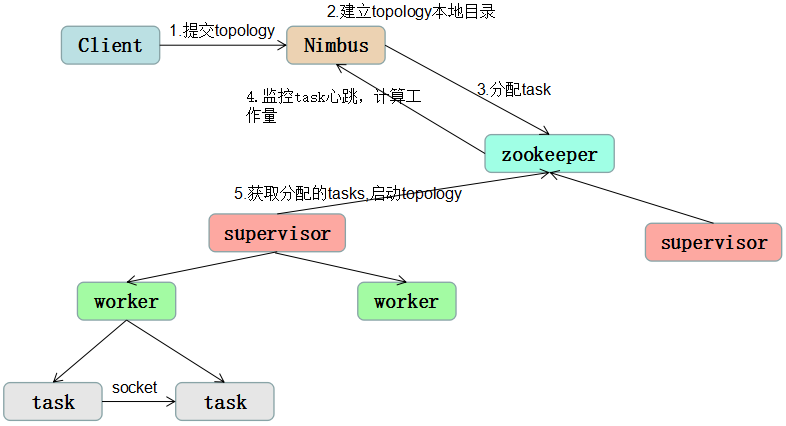
(1)客户端提交topology给nimbus
(2)提交的的jar包会上传到nimbus服务器的nimbus/inbox目录下,submitTopology方法会负责对这个topology进行处理,处理的过程包括对topology和storm的各种校验,首先检查storm的状态是否active,是否有同名的topology已经在storm中运行了(因为spout和bolt会指定id,storm会检查是否有使用了相同id的spout和bolt,注:任何一个id都不能以"_"开头,这种命名方式是系统保留的),之后nimbus还会建立topology的本地目录,nimbus/stormdist/topology-uuid,该目录包含三个文件,stormjar.jar(包含这个topology所有代码的jar包,从nimbus/inbox中移动过来),stormcode.ser(topology对象的序列化),stormconf.ser(运行这个topology的配置)
(3)完成上述检查和建立目录的工作后,nimbus根据topology定义中的parallelism hint参数,来给spout/bolt设定task数目,并且分配对应的task id,最后把分配好的task信息写入到zookeeper的/task目录下
(4)nimbus会在zookeeper上创建taskbeats目录,要求每个task每隔一段时间就要发个心跳信息
(5)nimbus将分配好的任务,写入zookeeper,同时将topology的信息写入zookeeper/storms目录
(6)supervisor定期扫描zookeeper上的storms目录,下载新的任务,根据nimbus指定的任务启动worker工作,同时supervisor还会定期删除不再运行的topology
(7)worker根据分配到的任务,根据task id分辨出哪些spout和bolt,并创建网络连接用来做消息的发送。
storm并发机制,通信机制,任务提交的更多相关文章
- 线程通信机制:共享内存 VS 消息传递
在并发编程中,我们必须考虑的问题时如何在两个线程间进行通讯.这里的通讯指的是不同的线程之间如何交换信息. 目前有两种方式: 1.共享内存 2.消息传递(actor 模型) 共享内存: 共享内存这种方式 ...
- Storm进程通信机制
storm的worker进程之间消息传递机制图: 每个worker都有一个独立的监听进程,监听配置文件中配置过的端口列表supervisor.slots.ports,topology.receiver ...
- Python并发编程之线程消息通信机制任务协调(四)
大家好,并发编程 进入第四篇. 本文目录 前言 Event事件 Condition Queue队列 总结 . 前言 前面我已经向大家介绍了,如何使用创建线程,启动线程.相信大家都会有这样一个想法,线程 ...
- 大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一.并行机制 Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力. 1.组件关系:Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor. ...
- python 之 并发编程(守护进程、互斥锁、IPC通信机制)
9.5 守护进程 主进程创建守护进程 其一:守护进程会在主进程代码执行结束后就立即终止 其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic process ...
- Storm编程模型及Worker通信机制
1.编程模型 2.Worker通信机制
- Storm内部的消息传递机制
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 一个Storm拓扑,就是一个复杂的多阶段的流式计算.Storm中的组件 ...
- Android多线程通信机制
掌握Android的多线程通信机制,我们首先应该掌握Android中进程与线程是什么. 1. 进程 在Android中,一个应用程序就是一个独立的进程(应用运行在一个独立的环境中,可以避免其他应用程序 ...
- 消息通信机制NSNotificationCenter -备
消息通信机制NSNotificationCenter的学习.最近写程序需要用到这类,研究了下,现把成果和 NSNotificationCenter是专门供程序中不同类间的消息通信而设置的,使用起来极为 ...
随机推荐
- 【大数据系列】HDFS文件权限和安全模式、安装
HDFS文件权限 1.与linux文件权限类型 r:read w:write x:execute权限x对于文件忽略,对于文件夹表示是否允许访问其内容 2.如果linux系统用户sanglp使用hado ...
- Redis学习笔记--Redis配置文件redis.conf参数配置详解
########################################## 常规 ########################################## daemonize n ...
- vue2.0笔记《一》列表渲染
内容中包含 base64string 图片造成字符过多,拒绝显示
- Sencha Touch 实战开发培训 视频教程 第二期 第四节
2014.4.14 晚上8:10分开课. 本节课耗时没有超出一个小时,主要讲解了list的一些扩展用法. 本期培训一共八节,前两节免费,后面的课程需要付费才可以观看. 本节内容: List的高级应用 ...
- X-Requested-With导致CSRF失败
在漫漫渗透之路中,眼前一亮的发现一个站.Referer字段没有检查,POST参数中的动态token也没有检查,这不是带一波CSRF的节奏嘛.但是遇到一个之前我没遇到的问题导致我CSRF失败,这个问题或 ...
- 硬件RDMA的驱动配置和测试
author:headsen chen date: 2019-01-18 10:22:20 notice:created by headsen chen himself and not allow ...
- 【BZOJ5094】硬盘检测 概率
[BZOJ5094]硬盘检测 Description 很久很久以前,小Q买了一个大小为n单元的硬盘,并往里随机写入了n个32位无符号整数.因为时间过去太久,硬盘上的容量字眼早已模糊不清,小Q也早已忘记 ...
- sprint boot 配置
来源:https://docs.spring.io/spring-boot/docs/current-SNAPSHOT/reference/htmlsingle/#howto-configure-to ...
- 理解Buffer
Buffer对象是Node.js用来处理二进制数据的一个接口.JavaScript比较擅长处理Unicode数据,对于处理二进制格式的数据(比如TCP数据流),就不太擅长.Buffer对象就是为了解决 ...
- linux安装环境
我用的是Linux ubuntu 3.19.0-25-generic #26~14.04.1-Ubuntu SMP Fri Jul 24 21:16:20 UTC 2015 x86_64 x86_64 ...