【java】详解集合
目录结构:
一,集合概述
1.1什么是集合
集合是对一组存储数据类的统称,相关的类都存放在java.util包中。
Collection:
Map:

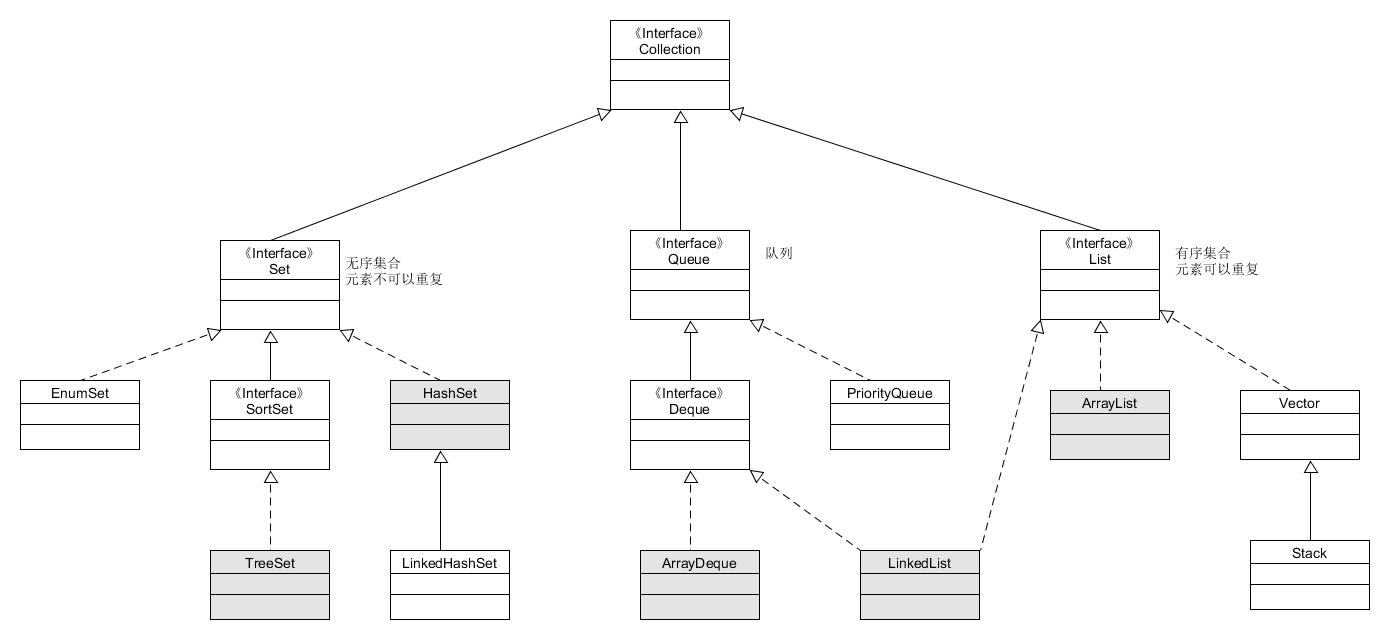
图中灰底的类是比较常用的类,从上面的图片中我们可以看出,
集合分为两大类:Collection和Map
1.2 Collection和Map的区别
Collection接口中存放的是单个元素
Map接口存放的是单对元素
1.3 List和Set的区别
List接口是有序的,其中的元素可以重复
Set接口是无序的,其中的元素不可以重复
1.4 ArrayList和LinkedList的区别
ArrayList的底层实现是动态数组结构的,查找和修改元素方便,增加和删除元素不方便。
LinkedList的底层实现是链表结构,增加和删除元素方便,查找和修改元素不方便。
1.5 HashSet和TreeSet的区别
HashSet的底层是基于HashCode表进行存储的。
TreeSet的底层是基于平衡有序二叉树(又称红黑树)实现的。
1.6 HashMap和TreeMap的区别
HashMap,TreeMap的底层和Set接口中HashSet,TreeSet底层实现结构类似。Set中只能存放单个元素,Map中只能存储单对元素。
1.7 List,Set,Map的比较
List接口是有序的,存储的是单个元素,元素允许重复。
Set接口是无序的,存储的是单个元素,元素不允许重复。
Map接口是采用(key)键-(value)值进行存储,其中key不允许重复,value允许重复。
二,List接口及其常用实现类
List中的元素是有序的。实现List接口中的常用子类有:ArrayList,LinkedList,Stack,Vector
2.1 ArrayList类
由于数组是内存中一段连续的存储空间,因此可以非常方便地通过下标来访问和修改元素。如果在数组的开始和末尾增加或删除元素还比较容易,但是在数组中间增加或是删除某个元素,那么就需要移动其它的元素位置,若数组长度非常大,那么移动的元素就非常多,效率就比较低。
由于ArrayList的底层实现和数组类似,下面通过一个简单的Demo来看一看:
int []arr=new int[10];
/*
* 赋值
*/
for(int i=0;i<arr.length;i++){
arr[i]=i;
}
/*
* 打印
*/
System.out.print("原数组:");
for(int i:arr){
System.out.print(i+" ");// 0 1 2 3 4 5 6 7 8 9
}
System.out.println();
/*
* 移除数组下表为6的元素
*/
int index=5;
for(int i=index;i<arr.length-1;i++){
arr[i]=arr[i+1];
}
/*
* 打印
*/
System.out.print("修改后:");
for(int i:arr){
System.out.print(i+" ");// 0 1 2 3 4 6 7 8 9 9
}
上面的代码移除了原数组下标为6的元素,并且移动了数组4次。
ArrayList的底层是采用动态数组实现的,访问和修改方便,增删不方便。
2.2 LinkedList类
附上一张图片来说明LinkedList和ArrayList的区别
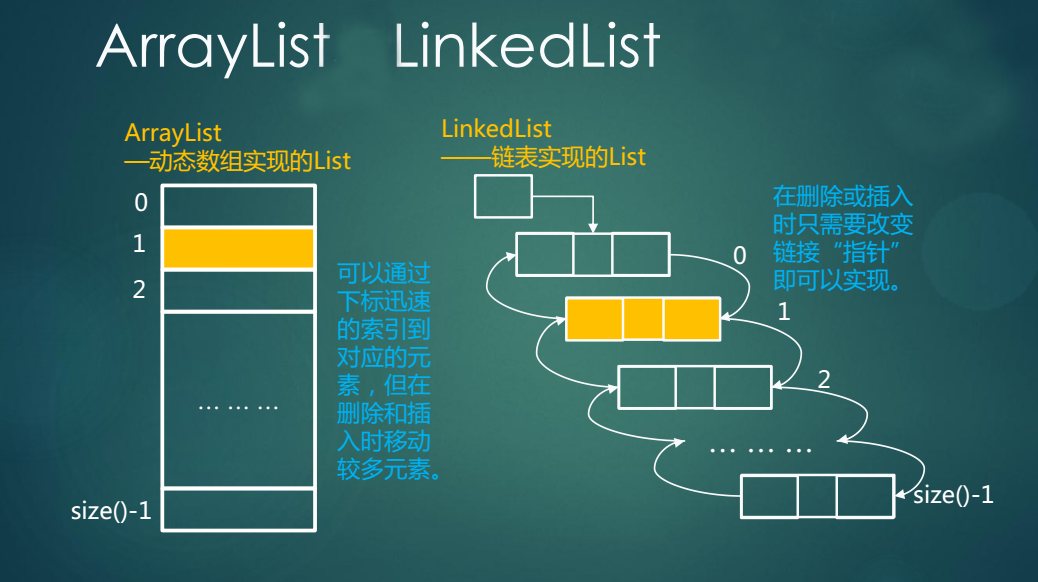
LinkedList类的底层是采用动态链表实现的,增删方便,访问和修改不方便。
2.3 Stack类
该类的数据存储结构同栈类似,也是后进先出。
Stack类是采用动态数组的方式实现的,该类是一种具有后进先出特性的数据结构,简称LIFO(Last Input First Output)。
Stack类是Vector类的一个子类,它模拟了“栈”这种数据存储结构,Stack类是一个古老的类,也是线程安全、效率较低的一个类。不建议使用Stack类,如果需要“栈”这种结构可以考虑使用ArrayDeque代替。
2.4 Vector类
该类是采用动态数组的方式实现的,与ArrayList类相比,支持线程安全,效率比较低,Java官方推荐使用ArrayList。
到这里都知道Vector和ArrayList都是List的实现类,在上面关于ArrayList的介绍中,我们已经知道了ArrayList其实是基于动态数组结构的,其实Vector和ArrayList类似,也是基于动态数组。ArrayList和Vector对象是采用initialCapacity参数来设置数组的长度,当ArrayList对象和Vector对象添加的元素超过了数组的长度,initialCapacity会自动增加。如果在创建ArrayList和Vector对象的时候不指定initialCapacity的值,默认的长度是10。我们已经知道官方推荐使用ArrayList代替Vector,那么如何解决ArrayList不是线程安全的问题呢?其实JDK官方提供一个Collections的工具类,可以使用该类实现ArrayList的线程安全,比如: ArrayList arrayList= Collections.synchronizedList(new ArrayList(...));
2.5 其它
2.5.1 在List集合中存储自定义数据
在List集合中的数据是按照数组结构存储的,因此如果在List集合中存储自定义类数据的时候,不需要在自定义类中继承或是实现某些特殊的接口。
Student类:
public class Student {
private String name;//姓名
private int age;//年龄
public Student() {
super();
}
public Student(String name, int age) {
super();
setName(name);
setAge(age);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
Student类
TestStudent类:
public class TestStudent{
public static void main(String[] args) {
/*
* 创建一个只能存放Student对象的实现List接口的集合
*/
List<Student> lt=new ArrayList<Student>();
/*
* 增加数据
*/
lt.add(new Student("jame",2001));
lt.add(new Student("john",2002));
lt.add(new Student("Locy",2003));
/*
* 打印数据
*/
for(Student stu:lt){
System.out.println(stu.getName()+","+stu.getAge());
}
}
}
TestStudent类
上面的代码中Student类并没有继承或是实现某些特殊的类或是接口,依然能够存放到ArrayList集合中,这和ArrayList的底层的数据存储结构是有关的。因为ArrayList对每个元素都有唯一的索引下标,只需要把元素放到指定的下标位置即可,而无需Student类去实现或是继承某些特殊的接口或是类。
2.5.2 互调List集合中的两个数据
互调两个数据,笔者在脑海中最开始闪现出来的算法如下:
temp = i;
i=j;
j=temp;
但是我们可以使用List集合中set和get方法,其中set(int index,E element)方法的返回值比较特别:
public E set(int index,E element)
功能:将此列表中指定位置的元素替换为指定的元素
返回值:以前在指定位置的元素
set方法的返回值是被替换掉的元素,我们可以通过这个特点,来快速地实现List接口实现类集合中两个元素的互调。
list.set(i, list.set(j, list.get(i)));
上面的模板实现了互调下标为i的元素和下标为j的元素,下面以LinkedList为例:
public class TestStudent{
public static void main(String[] args) {
/*
* 创建一个只能存放Student对象的实现List接口的集合
*/
List<Student> lt=new LinkedList<Student>();
/*
* 增加数据
*/
lt.add(new Student("jame",2001));
lt.add(new Student("john",2002));
lt.add(new Student("Locy",2003));
/*
* 打印数据
*/
for(Student stu:lt){
System.out.println(stu.getName()+","+stu.getAge());
}
/*
* 互调学生Locy和jame在List集合中位置
*/
lt.set(0, lt.set(2, lt.get(0)));
/*
* 再次打印
*/
System.out.println("-------------------------");
for(Student stu:lt){
System.out.println(stu.getName()+","+stu.getAge());
}
}
}
实现互调List集合中两个元素的位置
最后读者需要注意,使用List和Map接口的实现类可以使用这种方式快速互调两个元素,但是有set接口因为本身存储数据的结构问题,并没有提供这样的方法。
三,Queue接口及其常用实现类
队列(Queue)是常用的数据存储结构,可以将队列看成特殊的线性表,队列限制了对线性表的访问方式:只能从线性表的一段访问(OFFER)元素,从另一端取出(POLL)元素。
队列(Queue)遵循先进先出(First Input First Output 简称FIFO)的原则。
Queue接口下面有一个Deque接口,Deque接口是具有双端队列的特性的接口,Deque接口的实现类是既可以作为模拟队列这种数据结构,又可以作为模拟栈的数据结构。Deque的实现类常见有ArrayDequ和LinkedList,
ArrayDeque的底层是基于动态数组的,在创建ArrayDeque的时候可以通过numElements参数指定数组的长度,如果不指定,那么默认大小是16.
3.1 LinkedList类
LinkedList是一个比较特殊类,LinkedList和ArrayDeque都同时实现了Deque接口,实现了Deque接口的实体类既可作为栈使用,也可以作为单/双端队列使用。不过LinkedList不仅仅实现了Deque接口,还实现了List接口,也就是说LinkedList类具有三种特性,栈、单/双端队列、List特性。
在前面已经介绍了LinkedList底层是基于链表结构,所以具有插入、删除数据方便,查询数据不方便的特点。
四,Set接口及其常用实现类
Set中的元素是无序的,不允许有重复的元素,而且set和list都是Collection的子接口因此都只能存储单个元素。主要的实现类包括:HashSet()和TreeSet()方法
4.1 HashSet
附上一张关于哈希表的图片
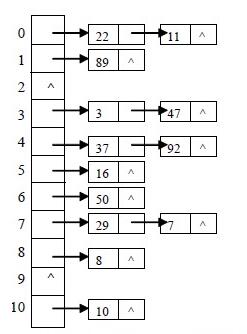
这个里hashCode分配的长度是11,上面的数据对11取余恰好对应其前面的数字。假设目前需要32,那么首先用33对11取余得到0,然后再用33调用equals方法和上面的22,11比是否相等,很显然33不等于22,11,所以33会被分配到11的后面。
HashSet的底层是采用哈希值判断数据在哪个篮子里,然后再用equals方法进行比较看该数据是否存在。
4.1.1 在HashSet中存储自定义数据
在HashSet中存储自定义数据和List接口下的ArrayList(或是LinkedList)不同,因为HashSet的底层是使用HashCode结合equals方法进行管理,因此被存储的数据类必须重写equals和hashCode方法:
下面看一个示例:
public class Student {
private String name;
private int id;
public Student() {
super();
}
public Student(String name, int id) {
super();
setName(name);
setId(id);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
/*
* 该类继承Object,重写其中的hashCode()和equals()方法,按照学号进行比较
*/
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (id != other.id)
return false;
return true;
}
}
Student类
接下来是一个测试类:
public class TestHashSet {
public static void main(String []args){
/*
* 创建一个只能存储Student对象的HashSet对象
*/
HashSet<Student> hst=new HashSet<Student>();
hst.add(new Student("jame",23));
hst.add(new Student("jame",23));
/*
* 打印所有数据,结果只有一个数据,这是因为Set集合不允许存在重复元素
*/
for(Student st:hst){
System.out.println(st);
}
}
}
TestHashSet
学生对象的存储过程和上面的列子类似,当我们存储第一个Student对象的时候,会得到一个HashCode值,通过计算可得出是54。然后在储存第二个对象的时候又会得到一个HashCode值,通过计算也可以得出是54,换句话说,这两个对象在同一个“篮子”里,然后该对象再调用equals(Object obj)方法和“篮子”里以前的对象比较是否相等,如果相等就不存入,如果不相等就存入,显然笔者传入的两个对象是相等的,所以最终只有一个数据。
4.2 TreeSet
TreeSet的底层是基于平衡二叉树(又称为红黑树)的,
由于TreeSet的底层是采用二叉树管理的,被TreeSet存储的元素必须实现java.lang.Comparable接口并且重写compareTo()方法,或在创建集合时传入java.util.Comparator对象并且重写compare()方法
4.2.1 自然排序法
自然排序法就是实现java.lang.Comparable接口,重写compareTo()方法,这是API中大部分类都是实现的,读者可以打开API验证,
public class Student implements Comparable<Student> {
private String name;
private int id;
public Student() {
super();
}
public Student(String name, int id) {
super();
setName(name);
setId(id);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
/*
* 重写Comparable接口中的compareTo方法
* 按照id进行比较
*/
@Override
public int compareTo(Student o) {
return getId()-o.getId();
}
}
Student
public class TestTreeSet {
public static void main(String[] args) {
Set<Student> st=new TreeSet<Student>();
st.add(new Student("johe",21));
st.add(new Student("jake",35));
st.add(new Student("brave",12));
for(Student s:st){
System.out.println(s.getId()+","+s.getName());
}
}
}
TestTreeSet(自然排序法)
4.2.2 比较器
比较器就是在创建集合时传入java.util.Comparator对象,重写compare()方法,其实现原理和自然排序法类似。
public class Student {
private String name;
private int id;
public Student() {
super();
}
public Student(String name, int id) {
super();
setName(name);
setId(id);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}
Student
public class TestTreeSet {
public static void main(String[] args) {
Set<Student> st=new TreeSet<Student>(new Comparator<Student>(){
/*
* 重写Comparator接口总compare()方法
*/
@Override
public int compare(Student o1, Student o2) {
return o1.getName().compareTo(o2.getName());
}
});
st.add(new Student("johe",21));
st.add(new Student("jake",35));
st.add(new Student("brave",12));
for(Student s:st){
System.out.println(s.getId()+","+s.getName());
}
}
}
TestTreeSet(选择器)
自然排序法可以重复利用,比较器只能使用一次。
4.3 Set集合中迭代器
对Set集合中的数据的遍历、修改和有点不同,List集合既可以调用add或是get等等方法来实现,也可以创建迭代器(Iterator)来实现,但是Set集合是通过迭代器来实现的。
如:
Set<String> st=new HashSet<String>();
st.add("abc");
st.add("ab");
st.add("ac");
//创建迭代器
Iterator<String> it=st.iterator();
while(it.hasNext()){
System.out.print(it.next()+" ");//abc ac ab
}
五,Map接口
Map是采用键-值进行数据存储的。相比读者肯定知道Map集合和Set集合非常相似,其实Set集合的实现就是基于Map集合。在Set集合的源码中,将Set集合存储的值放到Map集合的Key上,然后将Value值设置为一个无意义的Object对象,这样就显示了Set集合。
5.1 TreeMap,HashMap
TreesMap的底层实现和TreeSet类似
HashMap的底层实现和HashSet类似
5.2 在Map中互调两个数据
由于Map集合中的“ V put(K key, V value) ”方法和List集合中的“ E set(int index, E element) ”功能类似,并且put方法的返回值是以前与key关联的值。
map.put(i,map.put(j,map.get(i)));
看一个实例:
public class TestMap {
public static void main(String[] args) {
/*
* create a Map value
*/
Map<Integer,String> mp=new HashMap<Integer,String>();
/*
* put value
*/
mp.put(1, "a");
mp.put(2, "b");
mp.put(3, "c");
/*
* print mp value
*/
System.out.println("before:"+mp);
/*
* exchange two value from one to another
*/
int i=1;
int j=3;
mp.put(i,mp.put(j,mp.get(i)));
/*
* print mp value
*/
System.out.println("after:"+mp);
}
}
TestMap
5.3 Map转化其它集合的方法
Map中提供了三种方法将Map集合转化为其它集合的方法,分别是 Set<Map.Entry<K,V>> entrySet() , Set<K> keySet() , Collection<V> values() 方法
5.3.1 keySet()方法的使用
public class TestEntrySet {
public static void main(String[] args) {
/*
* 创建一个将Integer和String关联起来的Map对象
*/
Map<Integer,String> hp=new TreeMap<Integer,String>();
hp.put(1, "a");
hp.put(2, "b");
/*
* 获得Set视图
*/
Set<Integer> set=hp.keySet();
/*
* 使用增加版For循环打印
*/
for(Integer i:set){
System.out.println(hp.get(i));
}
/*
* 使用迭代器再次打印
*/
Iterator<Integer> it=set.iterator();
while(it.hasNext()){
System.out.println(hp.get(it.next()));
}
}
}
使用keySet()获得Set视图
5.3.2 entrySet()方法的使用
public class TestEntrySet {
public static void main(String[] args) {
/*
* 创建一个将Integer和String关联起来的Map对象
*/
Map<Integer,String> hp=new TreeMap<Integer,String>();
hp.put(1, "a");
hp.put(2, "b");
/*
* Map.Entry<k,v>对象
* 其中有getKey(),getValue(),setValue()等等操作方法
*/
Set<Map.Entry<Integer, String>> set=hp.entrySet();
/*
* 使用增加版For循环打印
*/
for(Map.Entry<Integer, String> i:set){
System.out.println(i.getKey()+"="+i.getValue());
}
}
}
使用entrySet方法获得Map.Entry<k,v>
5.3.3 values()方法的使用
public class values{
public static void main(String[] args) {
/*
* 创建一个将Integer和String关联起来的Map对象
*/
Map<Integer,String> hp=new TreeMap<Integer,String>();
hp.put(1, "a");
hp.put(2, "b");
/*
* 使用values()方法,获得只能是键-值对中的值,也就是所有key对应value的一个集合
*/
Collection<String> c=hp.values();
/*
* 使用增加版For循环打印
*/
for(String i:c){
System.out.println(i);
}
}
}
获得键-值对的值集合
【java】详解集合的更多相关文章
- Java 详解 JVM 工作原理和流程
Java 详解 JVM 工作原理和流程 作为一名Java使用者,掌握JVM的体系结构也是必须的.说起Java,人们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成:Java ...
- 逆向工程生成的Mapper.xml以及*Example.java详解
逆向工程生成的接口中的方法详解 在我上一篇的博客中讲解了如何使用Mybayis逆向工程针对单表自动生成mapper.java.mapper.xml.实体类,今天我们先针对mapper.java接口中的 ...
- java基础详解-集合
一.集合组成 java集合主要由Map和Collection组成,Collection主要类图如下(图片来源于网络,懒得画图): 从上图中能很明显的看出来Collection下主要是Set.List和 ...
- Floyd算法(三)之 Java详解
前面分别通过C和C++实现了弗洛伊德算法,本文介绍弗洛伊德算法的Java实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3. 弗洛伊德算法的代码说明 4. 弗洛伊德算法的源码 转载请注明 ...
- Prim算法(三)之 Java详解
前面分别通过C和C++实现了普里姆,本文介绍普里姆的Java实现. 目录 1. 普里姆算法介绍 2. 普里姆算法图解 3. 普里姆算法的代码说明 4. 普里姆算法的源码 转载请注明出处:http:// ...
- Kruskal算法(三)之 Java详解
前面分别通过C和C++实现了克鲁斯卡尔,本文介绍克鲁斯卡尔的Java实现. 目录 1. 最小生成树 2. 克鲁斯卡尔算法介绍 3. 克鲁斯卡尔算法图解 4. 克鲁斯卡尔算法分析 5. 克鲁斯卡尔算法的 ...
- 邻接矩阵有向图(三)之 Java详解
前面分别介绍了邻接矩阵有向图的C和C++实现,本文通过Java实现邻接矩阵有向图. 目录 1. 邻接矩阵有向图的介绍 2. 邻接矩阵有向图的代码说明 3. 邻接矩阵有向图的完整源码 转载请注明出处:h ...
- 邻接矩阵无向图(三)之 Java详解
前面分别介绍了邻接矩阵无向图的C和C++实现,本文通过Java实现邻接矩阵无向图. 目录 1. 邻接矩阵无向图的介绍 2. 邻接矩阵无向图的代码说明 3. 邻接矩阵无向图的完整源码 转载请注明出处:h ...
- Dijkstra算法之 Java详解
转载:http://www.cnblogs.com/skywang12345/ 迪杰斯特拉算法介绍 迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个节点到其他节点的最短路径. 它的主 ...
随机推荐
- 定制加载loading 图片
项目中要使用一个动态加载图片,找了好久都没有合适的最后发现了这个网站,自由定制需要的gif图片,完全免费啊 http://preloaders.net/en/
- GPUImage简单滤镜使用之色阶(三)
色阶是表示图像亮度强弱的指数标准,图像的色彩丰满度和精细度是由色阶决定的.在GPUImage中GPUImageLevelsFilter提供了此功能. GPUImageLevelsFilter定义了修改 ...
- [Canvas]New Running Dog
欲看效果请下载后用Chrome浏览器打开index.html观看,下载地址:https://files.cnblogs.com/files/xiandedanteng/51-NewRunningDog ...
- Mybatis源码分析之SqlSession和Excutor(二)
通过上一篇文章的分析我们,我初步了解了它是如何创建sessionFactory的(地址:Mybatis源码分析之SqlSessionFactory(一)), 今天我们分析下Mybatis如何创建Sql ...
- mssql批量删除数据库里所有的表
go declare @tbname varchar(250) declare #tb cursor for select name from sysobjects where objectprope ...
- Android 如何预置APK M
前言 欢迎大家我分享和推荐好用的代码段~~ 声明 欢迎转载,但请保留文章原始出处: CSDN:http://www.csdn.net ...
- C++ 第十一课 标准c内存函数
calloc() 分配一个二维储存空间 free() 释放已分配空间 malloc() 分配空间 realloc() 改变已分配空间的大小 calloc 语法: #include <st ...
- JQuery Sparkline 说明文档
来自:http://wenku.baidu.com/link?url=G2JoOrHKrwinFAY03-QpigyvZ2Jg_fZ0JKRtEcnX7jCPyeb4F9cBSC6gT1xKt2XAy ...
- 记:青岛理工ACM交流赛筹备工作总结篇
这几天筹备青岛理工ACM交流赛的过程中遇到了不少问题也涨了不少经验.对非常多事也有了和曾经不一样的看法, 一直在想事后把这几天的流水帐记一遍,一直没空直到今天考完C++才坐下来開始动笔.将这几天的忙 ...
- CENTOS7更换YUM源为163源
访问地址为:http://mirrors.163.com/.help/centos.html 首先备份源: mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum. ...