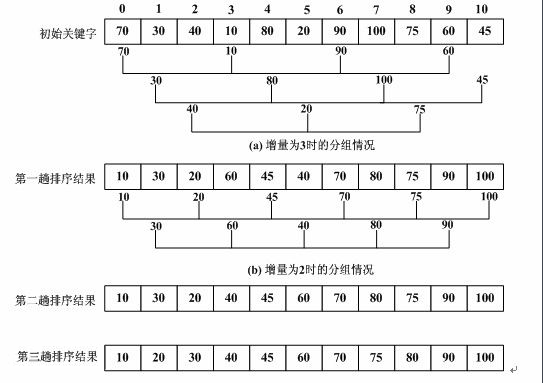
算法篇---Shell排序(希尔)算法
package com.zc.manythread;
/**
*
* @author 偶my耶
*
*/
public class ShellSort {
public static int count = ; public static void shellSort(int[] data) {
// 计算出最大的h值
int h = ;
while (h <= data.length / ) {
h = h * + ;
}
while (h > ) {
for (int i = h; i < data.length; i += h) {
if (data[i] < data[i - h]) {
int tmp = data[i];
int j = i - h;
while (j >= && data[j] > tmp) {
data[j + h] = data[j];
j -= h;
}
data[j + h] = tmp;
print(data);
}
}
// 计算出下一个h值
h = (h - ) / ;
}
} public static void print(int[] data) {
for (int i = ; i < data.length; i++) {
System.out.print(data[i] + "\t");
}
System.out.println();
}
public static void main(String[] args) { int[] data = new int[] { , , , , , , , , };
print(data);
shellSort(data);
print(data); }
}
运行结果:
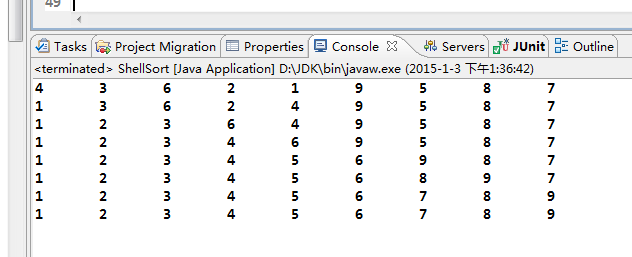
Shell排序是不稳定的,它的空间开销也是O(1),时间开销估计在O(N3/2)~O(N7/6)之间
算法篇---Shell排序(希尔)算法的更多相关文章
- Java常见排序算法之Shell排序
在学习算法的过程中,我们难免会接触很多和排序相关的算法.总而言之,对于任何编程人员来说,基本的排序算法是必须要掌握的. 从今天开始,我们将要进行基本的排序算法的讲解.Are you ready?Let ...
- python数据结构与算法篇:排序
1.冒泡排序(英语:Bubble Sort) 它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成. ...
- 三白话经典算法系列 Shell排序实现
山是包插入的精髓排序排序,这种方法,也被称为窄增量排序.因为DL.Shell至1959提出命名. 该方法的基本思想是:先将整个待排元素序列切割成若干个子序列(由相隔某个"增量"的元 ...
- 贝叶斯个性化排序(BPR)算法小结
在矩阵分解在协同过滤推荐算法中的应用中,我们讨论过像funkSVD之类的矩阵分解方法如何用于推荐.今天我们讲另一种在实际产品中用的比较多的推荐算法:贝叶斯个性化排序(Bayesian Personal ...
- 直接插入排序、折半插入排序、Shell排序、冒泡排序,选择排序
一.直接插入排序 稳定,时间复杂度:最好O(n).最差O(n^2).平均O(n^2).空间复杂度O(1) void InsertSort(int L[], int n) { int i, j,key; ...
- java排序算法(八):希尔排序(shell排序)
java排序算法(八):希尔排序(shell排序) 希尔排序(缩小增量法)属于插入类排序,由shell提出,希尔排序对直接插入排序进行了简单的改进,它通过加大插入排序中元素之间的间隔,并在这些有间隔的 ...
- 排序算法<No.7>【希尔排序】
排序算法进入到第7篇,这个也还是比较基础的一种,希尔排序,该排序算法,是依据该算法的发明人donald shell的名字命名的.1959年,shell基于传统的直接插入排序算法,对其性能做了下提升,其 ...
- Java排序算法(四):Shell排序
[基本的想法] 将原本有大量记录数的记录进行分组.切割成若干个子序列,此时每一个子序列待排序的记录个数就比較少了,然后在这些子序列内分别进行直接插入排序,当整个序列都基本有序时.再对全体记录进行一次直 ...
- 排序算法——Shell排序
二.Shell排序 Shell排序也叫“缩减增量排序”(disminishing increment sort),基于插入排序进行. Shell建议的序列是一种常用但不理想的增量序列:1,...,N/ ...
随机推荐
- 【Struts2】剖析Struts2中的反射技术 ValueStack(值栈)
1,Struts2框架主要组件的处理流程 在说ValueStack之前,笔者先说一说Struts2中常用的组件,struts2中常用组件有strutsPrepareAndExecuteExceptio ...
- 安装Nginx+Tomcat
Centos下安装nginx rpm包 1 在nginx官方网站下载一个rpm包,下载地址是:http://nginx.org/packages/centos/ http://nginx.org/e ...
- iOS 图标
iOS icon是一件很头疼的事情 大致多少张呢,忘记了,下面开发者中心给的一个文档,自己捋捋有多少张 180934.jpg 幸亏不是自己画的,不然要骂姥姥,但是多数的UI是妹子啊,让人家做人家会说: ...
- C#程序证书创建工具 (Makecert.exe)
原文地址:https://msdn.microsoft.com/zh-cn/library/bfsktky3(VS.80).aspx 证书创建工具生成仅用于测试目的的 X.509 证书.它创建用于数字 ...
- Kubernetes(k8s) docker集群搭建
原文地址:https://blog.csdn.net/real_myth/article/details/78719244 一.Kubernetes系列之介绍篇 •Kubernetes介绍 1.背 ...
- 一步一步掌握线程机制(六)---Atomic变量和Thread局部变量
前面我们已经讲过如何让对象具有Thread安全性,让它们能够在同一时间在两个或以上的Thread中使用.Thread的安全性在多线程设计中非常重要,因为race condition是非常难以重现和修正 ...
- openkm预览功能报错:flexpaper License key not accepted(no key passed to viewer)
openkm:6.3.4 使用google浏览器打开,想预览文件,但是pdf.word和图片都不能显示.只是显示空白. 换成IE后,再次尝试,发现了报错信息: 解决方案: 1- Stop openkm ...
- jeecg中的一个上下文工具类获取request,session
通过调用其中的方法可以获取到request和session,调用方式如下: HttpServletRequest request = ContextHolderUtils.getRequest();H ...
- python sort和sorted函数
sort 与 sorted 区别: sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作. list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 ...
- ios7新特性--1
1.用户界面的扁平化 2.UIKit 动态行为支持 应用程序可以设置UIView 对象和其他对象(遵从UIDynamicItem 协议)的动态行为属性.遵从UIDynamicItem协议的对象被称为d ...