spring batch初识
Spring Batch是什么?
Spring Batch是一个基于Spring的企业级批处理框架,按照我师父的说法,所有基于Spring的框架都是使用了spring的IoC特性,然后加上自己的一些处理规则。因此,要理解Spring Batch的设计和使用,首先需要理解批处理的机制和特点。
所谓企业批处理就是指在企业级应用中,不需要人工干预,定期读取数据,进行相应的业务处理之后,再进行归档的这类操作。从上面的描述中可以看出,批处理的整个流程可以明显的分为3个阶段:
1、读数据
2、业务处理
3、归档结果数据
另外,从定义中可以发现批处理的一个重要特色就是无需人工干预、定期执行,因此一个批处理框架,需要关注事务的粒度,日志监控,执行方式,资源管理,读数据,处理数据,写数据的解耦等方面。
SpringBatch为我们提供了什么呢?
1、统一的读写接口
2、丰富的任务处理方式、
3、灵活的事务管理及并发处理
4、日志、监控、任务重启与跳过等特性
注意,Spring Batch未提供关于批处理任务调度的功能,因此如何周期性的调用批处理任务需要自己想办法解决,就Java来说,Quartz是一个不错的解决方案,或者写脚本处理之。
Batch框架整体初见
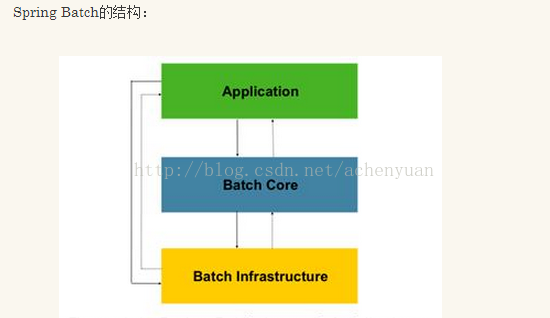
这种分层结构有三个重要的组成部分:应用层、核心层、基础架构层。应用层包含所有的批处理作业,通过Spring框架管理程序员自定义的代码。核心层包含了Batch启动和控制所需要的核心类,如:JobLauncher、Job和step等。应用层和核心层建立在基础构架层之上,基础构架层提供共通的读(ItemReader)、写(ItemWriter)、和服务(如RetryTemplate:重试模块。可以被应用层和核心层使用)。所以使用spring-batch需引入spring-batch-core.jar和spring-batch-infrastructure.jar(建议2.1.8.RELEASE).
Spring Batch执行流程
Batch执行流程:外部控制器调用JobLauncher启动一个Job,Job调用自己的Step去实现对数据的操作,Step处理完成后,再将处理结果一步步返回给上一层。其中Job里会配置一次批次处理数量commin-interval,read读一条传给process一条重复这2个操作直到commin-interval最大值就调用一次writer操作。然后再重复上次操作直到处理完所有的数据。当这个Step的工作完成以后,或是跳到其他Step,或是结束处理。
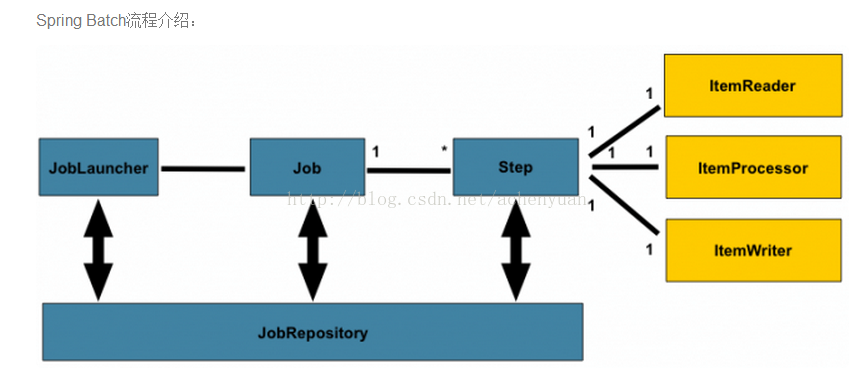
类图介绍
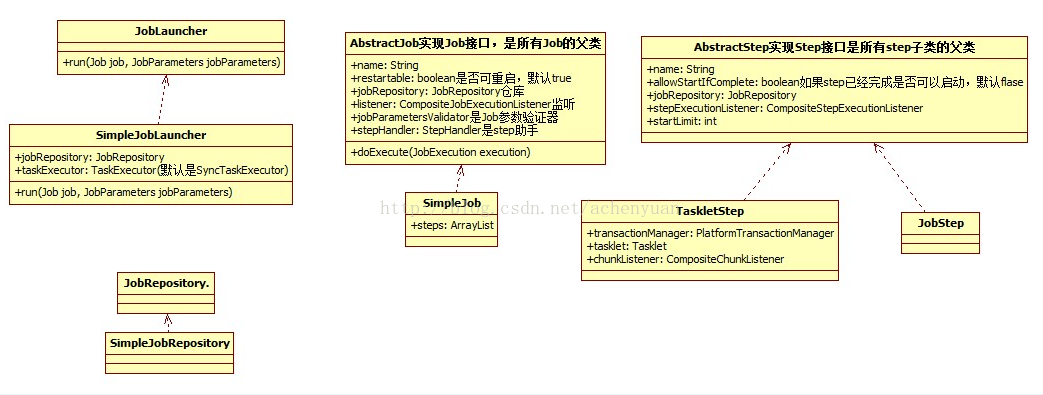
关键类介绍
JobLauncher:接口JobLauncher只有一个子类SimpleJobLauncher.负责整个batch的启动,是入口类。使用run(Jobjob, JobParameters jobParameters)方法,该方法根据JobParameters运行job,其作用就是绑定一组JobParameters到Job上,然后运行该Job。

Job:接口Job有个抽象子类AbstractJob扩展了Job功能的属性,下在有很多子类,其中SimpleJob是我们常用的子类,一个job包含若干step。配置批处理任务的领域对象,该对象的作用,第一是做Step的容器,配置该批处理任务需要的Step,以及他们之间的逻辑关系。第二是配置该批处理任务的特征,比方说名字,是否可重启,是否对JobParameters进行验证以及验证规则等。spring batch3.0支持JobScope后,它可以确保一个执行中的job只有一个bean实例,同事我们可以随时为对象注入当前job的上下文实例信息,只要我们设置bean的scope为“job",就可以说使用JobParameters和JobExecutionContext等信息。
<bean id="flatFileItemReader" scope="job" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobParameters['input.file.name']}" />
</bean>
在代码中使用如下:
public class a{
@Value("#{jobParameters[transDate]}")
private String transDate;
}
Step: 接口Step有个抽象子类AbstractStep扩展了Step功能的属性,下面有很多子类,其中TaskletStep是我们常用的子类,一个Step包含一个Tasklet实例,负责具体的事件。这种形式非常自由,开发人员只需要实现Tasklet接口,它有一个方法RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception,返回的是RepeatStatus枚举类,有三种状态:CONTINUABLE和FINISHED,假如是FINISHED,则表示step已经结束,进行下一个step。假如是CONTINUABLE,则表示未完成,不停的循环,直到完成这个step,相当于死循环,不会进行到下一个step,这个状态要小心,也可以直接跑异常,不同执行下面的step,使该job失败,结束job。其中的逻辑完全有自己决定。另一种是Chunk-Oriented形式的,这种形式定义了一个Step的流程必须是“读-处理(可选)-写”。每一个Step只能由一个Tasklet或者一个Chunk构成。在Spring Batch中,更方便的方式是通过JobParameter传入。为了实现该功能,Spring Batch通过自定义scope来达到Job和Step属性的后期绑定(Late Binding)。这是SpringBatch的一个后绑定技术,就是在生成Step的时候,才去创建bean,因为这个时候jobparameter才传过来。如果加载配置信息的时候就创建bean,这个时候jobparameter的值还没有产生,会抛出异常,即抛出初始化bean异常,所有一定要这么设置,其他普通bean就默认设置就行了,只有batch里面的writer,reader,processor等需要配置scope。
<bean id="flatFileItemReader" scope="step" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobParameters['input.file.name']}" />
</bean>
JobRepository:它会为Spring Batch的运维数据提供一种持久化机制。其为所有的运维数据的提供CRUD的操作接口,并为所有的操作提供事务支持,是存储job及step的仓库。只有一个子类SimpleJobRepository.它有两种存储方式:第一个是通过数据库保存信息,第二个是集合存储。所以当我们使用第一种保存里数据库里要创建对应的表,而对应的表在Jar里有提供sql
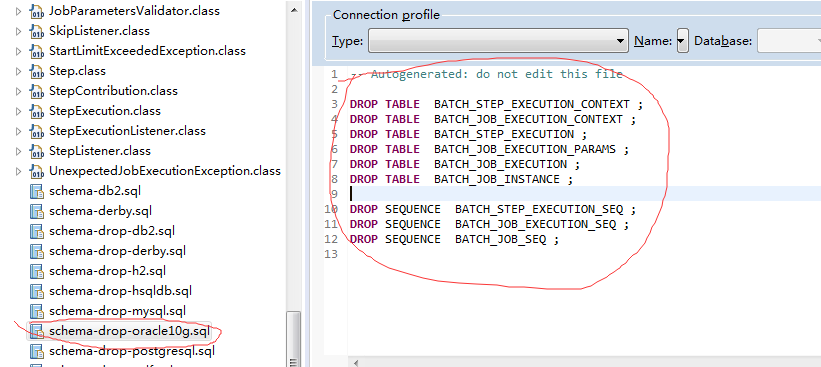
而JobRepositoryFactoryBean和MapJobRepositoryFactoryBean都是JobRepository工厂类,JobReository需要注入到jobLauncher,job和step里
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository"/>
<property name="taskExecutor" ref="batchThreadPoolExecutor"/>
</bean>
<task:executor id="batchThreadPoolExecutor" keep-alive="5" thread-pool="50"/>
job重新启动也是通过JobRepository来实现。
但是,假如批量job执行状态status为completed或者abandoned,而且还有参数,则不能重新启程,需要修改参数,或者重置参数为空,空跑批量job。

ItemReader:提供了读取数据的能力,是数据来源,是单行读取数据,有文件读取方式(FlatFileItemReader,必需配置resource和lineMapper两个属性,其它可选配),和数据库读取方式(AbstractPagingItemReader,必需配置参数queryId,sqlMapCLient, dataSource,其它选配)
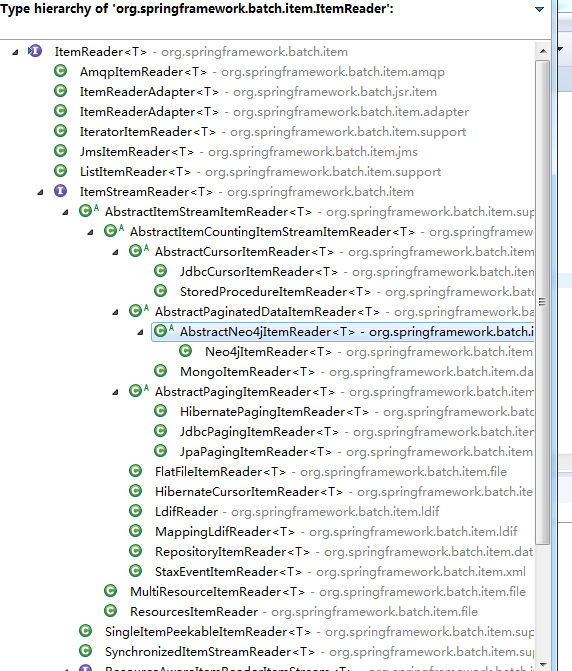
ItemProcessor:我们可以通过它处理自定义的业务逻辑,完成转换、过滤等操作。数据来自reader的数据,也是单行处理。当处理到size=1000(可以自定义)的时候,批量给writer写操作
ItemWriter:提供了写数据的能力,批量化处理。
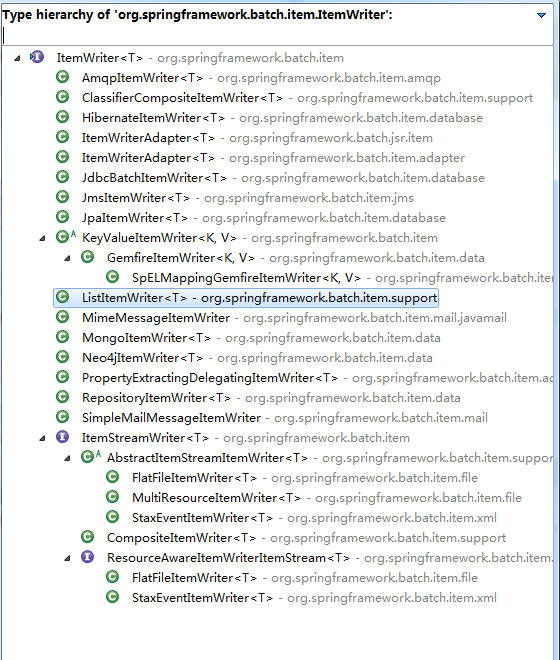
batch监听器,通过监听器,可以监听job,step,reader,processor,writer所有的状态数据,以备以后找错使用

注意:
1,jobName不能重复
2,批量name和定时任务name不能重复
3,批量传参的时候key值不能重复,不然会被覆盖
4,定时任务的实例跟批量的实例不能相同,即不能有相同的id,包括bean中的id
spring batch初识的更多相关文章
- [Spring Batch 系列] 第一节 初识 Spring Batch
距离开始使用 Spring Batch 有一段时间了,一直没有时间整理,现在项目即将完结,整理下这段时间学习和使用经历. 官网地址:http://projects.spring.io/spring-b ...
- Spring Batch 专题
如今微服务架构讨论的如火如荼.但在企业架构里除了大量的OLTP交易外,还存在海量的批处理交易.在诸如银行的金融机构中,每天有3-4万笔的批处理作业需要处理.针对OLTP,业界有大量的开源框架.优秀的架 ...
- spring batch批量处理框架
spring batch精选,一文吃透spring batch批量处理框架 前言碎语 批处理是企业级业务系统不可或缺的一部分,spring batch是一个轻量级的综合性批处理框架,可用于开发企业信息 ...
- 【转】大数据批处理框架 Spring Batch全面解析
如今微服务架构讨论的如火如荼.但在企业架构里除了大量的OLTP交易外,还存在海量的批处理交易.在诸如银行的金融机构中,每天有3-4万笔的批处理作业需要处理.针对OLTP,业界有大量的开源框架.优秀的架 ...
- Spring Batch在大型企业中的最佳实践
在大型企业中,由于业务复杂.数据量大.数据格式不同.数据交互格式繁杂,并非所有的操作都能通过交互界面进行处理.而有一些操作需要定期读取大批量的数据,然后进行一系列的后续处理.这样的过程就是" ...
- spring batch资料收集
spring batch官网 Spring Batch在大型企业中的最佳实践 一篇文章全面解析大数据批处理框架Spring Batch Spring Batch系列总括
- Spring Batch学习笔记三:JobRepository
此系列博客皆为学习Spring Batch时的一些笔记: Spring Batch Job在运行时有很多元数据,这些元数据一般会被保存在内存或者数据库中,由于Spring Batch在默认配置是使用H ...
- Spring Batch学习笔记二
此系列博客皆为学习Spring Batch时的一些笔记: Spring Batch的架构 一个Batch Job是指一系列有序的Step的集合,它们作为预定义流程的一部分而被执行: Step代表一个自 ...
- 初探Spring Batch
此系列博客皆为学习Spring Batch时的一些笔记: 为什么我们需要批处理? 我们不会总是想要立即得到需要的信息,批处理允许我们在请求处理之前就一个既定的流程开始搜集信息:比如说一个银行对账单,我 ...
随机推荐
- 将windows目录共享到linux
1.将windows目录共享 2.安装cifs 3. mount -t cifs -o username=电脑登陆用户名,password=电脑登陆用户密码 //127.0.0.1/abc /var ...
- 初识SolrJ开发, schema.xml的配置与服务初始化.
schema.xml位于solr/collection1/conf/目录下,是Solr中用户定义字段类型及字段的配置文件. Solr版本: 4.6.0 第一步: Schema.xml说明 实例sche ...
- android studio Gradle Build速度加快方法
设置离线编译就可以解决这个问题了.如下图所示:
- 条件触发和边缘触发 及 epoll 的长处
条件触发: 仅仅要输入缓冲有数据就会一直通知该事件 边缘触发: 输入缓冲收到数据时仅注冊1次该事件.即使输入缓冲中还留有数据,也不会再进行注冊 水平触发(level-triggered.也被称为条件触 ...
- Python 文件 isatty() 方法
概述 Python 文件 isatty() 方法检测文件是否连接到一个终端设备,如果是返回 True,否则返回 False. 语法 isatty() 方法语法如下: fileObject.isatty ...
- python标准库介绍——29 zlib 模块详解
==zlib 模块== (可选) ``zlib`` 模块为 "zlib" 压缩提供支持. (这种压缩方法是 "deflate".) [Example 2-43 ...
- jmeter 插件下载下载方法
1.进入下载插件网页:https://jmeter-plugins.org/install/Install/ 下载plugin-manager.jar 并放在jmeter 的lib/ext文件夹下 2 ...
- extjs4学习-02-导入相关文件
在WebContent下创建extjs4目录. 将extjs项目文件中的resource文件夹和ext-all.js.ext-all.js.ext-all-debug.js文件拷贝进去.
- js判断客户端是否是IOS系统
在手机端应用的开发中,经常会碰到IOS系统跟Android系统去访问同一个内容时的展示效果不同,这时候我们需要区别对待,下面代码就是用js判断手机终端是否IOS系统: //判断是否为ios系统:是IO ...
- django-TDD
1.什么是TDD: 测试驱动开发(Test-Driven Development) 它的总体思想是在写“实现”之前先写针对实现的“测试”,由于编写测试的时候 你要思考很多的可能性能,更多的思考也就意味 ...