Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2
- 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后重建。
-
域名 ip
master 192.168.0.120
slave1 192.168.0.121
slave2 192.168.0.122
-
- 2)Elasticsearch 内置的分词器对中文不友好,会把中文分成单个字来进行全文检索,不能达到想要的结果,在全文检索及新词发展如此快的互联网时代,IK可以进行友好的分词及自定义分词。
- 3)IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版,目前支持最新版本的ES6.X版本。
- 4)IK 带有两个分词器:
- ik_max_word :会将文本做最细粒度的拆分;尽可能多的拆分出词语
- ik_smart:会做最粗粒度的拆分;已被分出的词语将不会再次被其它词语占有
- 5)本篇采用下载IK中文分词器源码后,使用eclipse编译源码方式得到IK分词器安装包,因为以后如果要进行修改IK分词器可以修改完源码自己进行打包安装。
第一步:下载IK中文分词器源代码
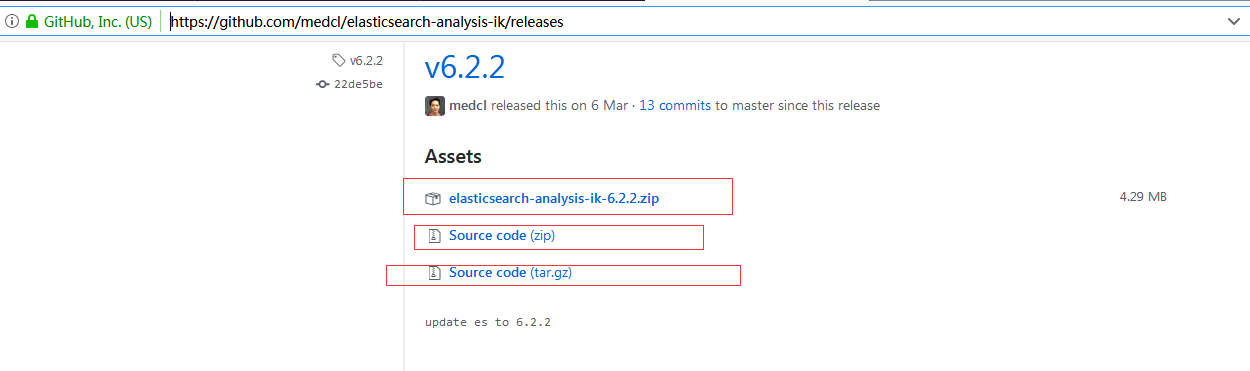
在github中搜索ik,找到"medcl/elasticsearch-analysis-ik",并找到https://github.com/medcl/elasticsearch-analysis-ik/releases,选择自己需要的版本:
或者
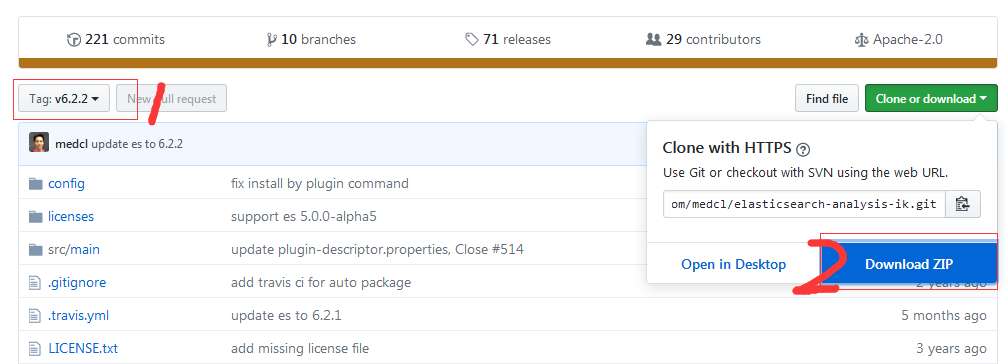
如上图所示,选择和elsticsearch 匹配的版本,并下载zip包。
第二步:解压下载的zip包并使用ecplise打开
①解压elasticsearch-analysis-ik-6.2.2.zip
②打开eclispe导入 maven项目
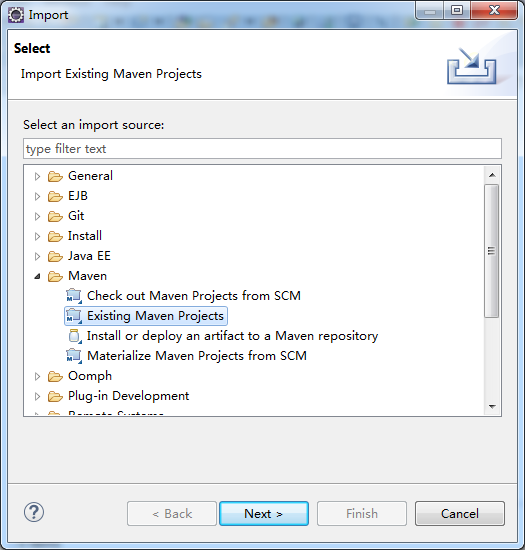
下一步
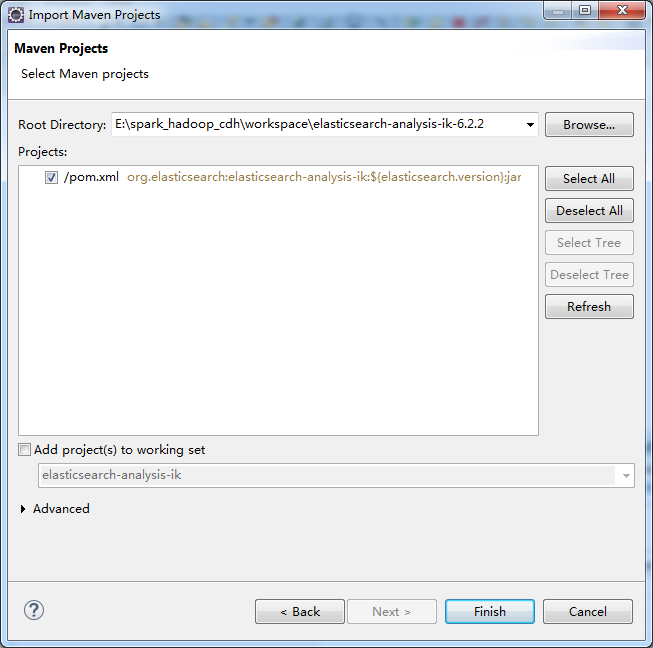
③导入后,使用maven build...编译jar包
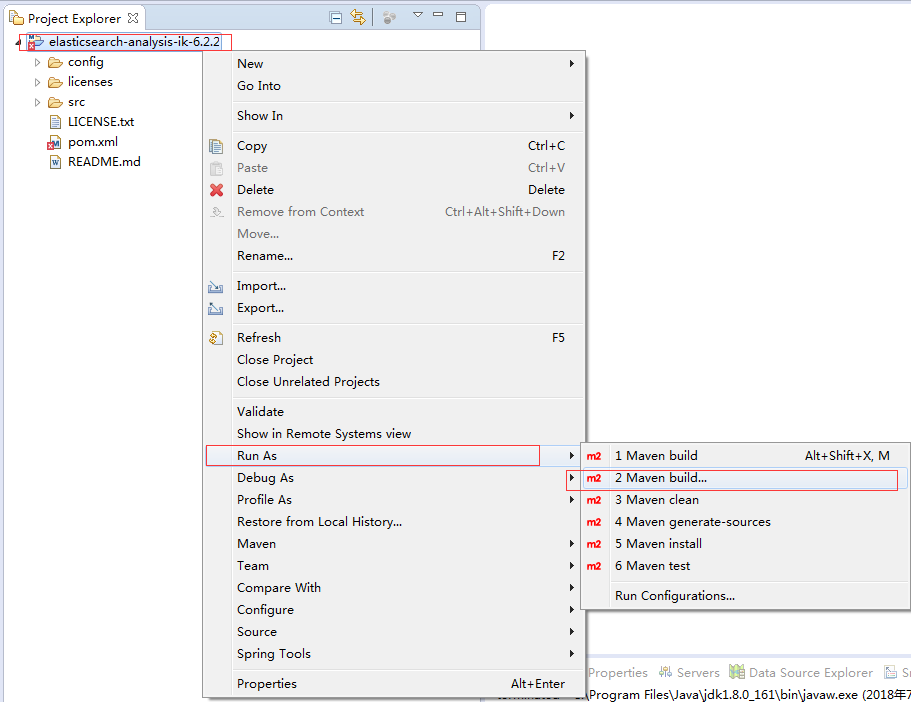
弹出编辑框:
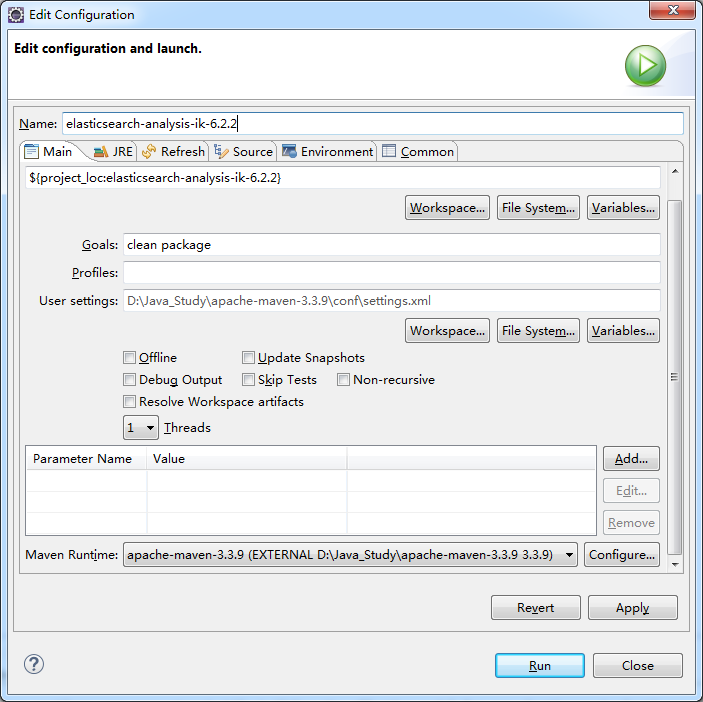
点击“Run”执行
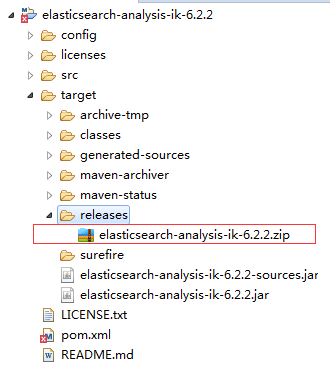
完成后,在target文件夹上右键 选择 Refresh,如图所示:
第三步:分别上传到ES的服务器并分别解压安装
把编译好的jar包上传到master服务器上,
执行命令安装:
[spark@master ~]$ cd /opt/
[spark@master opt]$ unzip elasticsearch-analysis-ik-6.2..zip -d /opt/elasticsearch-6.2./plugins/
Archive: elasticsearch-analysis-ik-6.2..zip
creating: /opt/elasticsearch-6.2./plugins/elasticsearch/
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/plugin-descriptor.properties
creating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/extra_main.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/extra_single_word.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/extra_single_word_full.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/extra_single_word_low_freq.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/extra_stopword.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/IKAnalyzer.cfg.xml
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/main.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/preposition.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/quantifier.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/stopword.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/suffix.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/config/surname.dic
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/elasticsearch-analysis-ik-6.2..jar
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/httpclient-4.5..jar
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/httpcore-4.4..jar
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/commons-logging-1.2.jar
inflating: /opt/elasticsearch-6.2./plugins/elasticsearch/commons-codec-1.9.jar
[spark@master opt]$ cd /opt/elasticsearch-6.2.2/plugins/
[spark@master plugins]$ mv elasticsearch/ ik/
slave1,slave2同样安装,这里省略。。
master,slave1,slave2三台服务器安装完成后,重启elasticsearch 即可加载ik分词器。
第四步:测试
1) 删除、创建索引:
curl -Xdelete "http://192.168.0.120:9200/index" curl -Xput "http://192.168.0.120:9200/index"
2)使用index索引创建mapping(对字段‘content’进行中文分词):
curl -XPOST "http://192.168.0.120:9200/index/fulltext/_mapping" -H 'Content-Type: application/json' -d'
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
} }'
3)先添加4条记录:
curl -XPOST "http://192.168.0.120:9200/index/fulltext/1" -H 'Content-Type: application/json' -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}' curl -XPOST "http://192.168.0.120:9200/index/fulltext/2" -H 'Content-Type: application/json' -d'
{"content":"公安部:各地校车将享最高路权"}' curl -XPOST "http://192.168.0.120:9200/index/fulltext/3" -H 'Content-Type: application/json' -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}' curl -XPOST "http://192.168.0.120:9200/index/fulltext/4" -H 'Content-Type: application/json' -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}'
4)执行统计:
curl -XPOST "http://192.168.0.120:9200/index/fulltext/_search" -H 'Content-Type: application/json' -d'
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}'
返回结果:
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": ,
"max_score": 0.6489038,
"hits": [
{
"_index": "index",
"_type": "fulltext",
"_id": "",
"_score": 0.6489038,
"_source": {
"content": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
},
"highlight": {
"content": [
"<tag1>中国</tag1>驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
]
}
},
{
"_index": "index",
"_type": "fulltext",
"_id": "",
"_score": 0.2876821,
"_source": {
"content": "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
},
"highlight": {
"content": [
"中韩渔警冲突调查:韩警平均每天扣1艘<tag1>中国</tag1>渔船"
]
}
}
]
}
}
5)再添加3条记录:
curl -XPOST "http://192.168.0.120:9200/index/fulltext/5" -H 'Content-Type: application/json' -d'
{"content":"俄侦委:俄一辆卡车渡河时翻车 致2名中国游客遇难"}' curl -XPOST "http://192.168.0.120:9200/index/fulltext/6" -H 'Content-Type: application/json' -d'
{"content":"韩国银行面向中国留学生推出微信支付服务"}' curl -XPOST "http://192.168.0.120:9200/index/fulltext/7" -H 'Content-Type: application/json' -d'
{"content":"印媒:中国东北“锈带”在困境中反击"}'
6)重新执行统计:
curl -XPOST "http://192.168.0.120:9200/index/fulltext/_search" -H 'Content-Type: application/json' -d'
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}'
返回结果:
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": ,
"max_score": 0.6785375,
"hits": [
{
"_index": "index",
"_type": "fulltext",
"_id": "",
"_score": 0.6785375,
"_source": {
"content": "印媒:中国东北“锈带”在困境中反击"
},
"highlight": {
"content": [
"印媒:<tag1>中国</tag1>东北“锈带”在困境中反击"
]
}
},
{
"_index": "index",
"_type": "fulltext",
"_id": "",
"_score": 0.47000363,
"_source": {
"content": "韩国银行面向中国留学生推出微信支付服务"
},
"highlight": {
"content": [
"韩国银行面向<tag1>中国</tag1>留学生推出微信支付服务"
]
}
},
{
"_index": "index",
"_type": "fulltext",
"_id": "",
"_score": 0.44000342,
"_source": {
"content": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
},
"highlight": {
"content": [
"<tag1>中国</tag1>驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
]
}
},
{
"_index": "index",
"_type": "fulltext",
"_id": "",
"_score": 0.2876821,
"_source": {
"content": "俄侦委:俄一辆卡车渡河时翻车 致2名中国游客遇难"
},
"highlight": {
"content": [
"俄侦委:俄一辆卡车渡河时翻车 致2名<tag1>中国</tag1>游客遇难"
]
}
},
{
"_index": "index",
"_type": "fulltext",
"_id": "",
"_score": 0.2876821,
"_source": {
"content": "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
},
"highlight": {
"content": [
"中韩渔警冲突调查:韩警平均每天扣1艘<tag1>中国</tag1>渔船"
]
}
}
]
}
}
IK支持自定义配置词库,配置文件在config文件夹下的analysis-ik/IKAnalyzer.cfg.xml,字典文件也在同级目录下,可以支持多个选项的配置,ext_dict-自定义词库,ext_stopwords-屏蔽词库。
同时还支持热更新配置,配置remote_ext_dict为http地址,输入一行一个词语,注意文档格式要为UTF8无BOM格式,如果词库发生更新,只需要更新response header中任意一个字段Last-Modified或ETag即可。
[spark@master config]$ pwd
/opt/elasticsearch-6.2./plugins/ik/config
[spark@master config]$ more IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
[spark@master config]$
参考:
《https://blog.csdn.net/moxiong3212/article/details/79338586》
《https://www.cnblogs.com/gaoxu387/p/7889626.html》
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十一)定制一个arvo格式文件发送到kafka的topic,通过Structured Streaming读取kafka的数据
将arvo格式数据发送到kafka的topic 第一步:定制avro schema: { "type": "record", "name": ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- 微信emoji表情编码 、MySQL 存储 emoji 表情符号字符集
相关资料 微信emoji表情编码 微信用户名显示「emoji表情」 PHP处理微信中带Emoji表情的消息发送和接收(Unicode字符转码编码) MySQL 存储emoji表情 MySQL 存储 e ...
- Android内存机制分析——堆和栈
昨天用Gallery做了一个图片浏览选择开机画面的功能,当我加载的图片多了就出现OOM问题.以前也出现过这个问题,那时候并没有深究.这次打算好好分析一下Android的内存机制. 因为我以前是做VC+ ...
- 蜗牛—ORACLE基础之学习(二)
如何创建一个表,这个表和还有一个表的结构一样但没有数据是个空表,旧表的数据也插入的 create table newtable as select * from oldtable 清空一个表内的数据 ...
- DELPHI之崩溃地址排错代码查看 转
http://www.cnblogs.com/enli/archive/2009/01/15/1376540.html 最近研究了一下HOOK技术,想抓取某些游戏的包,因此需要注入DLL,结果老是有异 ...
- .Net Discovery系列之三 深入理解.Net垃圾收集机制(上)
前言: 组成.Net平台一个很重要的部分----垃圾收集器(Garbage Collection),今天我们就来讲讲它.想想看没有GC,.Net还能称之为一个平台吗?各种语言虽然都被编译成MSIL,但 ...
- android中Bitmap的放大和缩小的方法
android中Bitmap的放大和缩小的方法 时间 2013-06-20 19:02:34 CSDN博客原文 http://blog.csdn.net/ada168855/article/det ...
- Git:远程仓库的使用
查看当前的远程库 要查看当前配置有哪些远程仓库,可以用git remote 命令,它会列出每个远程库的简短名字.在克隆完某个项目后,至少可以看到一个名为origin 的远程库,Git 默认使用这个名字 ...
- redis实现秒杀demo
代码 package com.prosay.redis; import java.util.List; import redis.clients.jedis.Jedis; import redis.c ...
- win7 64位系统及开发环境重装后的总结
前言 话说来这家公司之后就一直使用这个系统,现在感觉这系统跑的实在是有点慢了,运行,调试各种浪费时间呀,不过也用了将近20个月了,这也可以说是我用的最久的一个系统了.由于新项目即将拉开战幕,所以自己趁 ...
- 推荐一款移动端的web UI控件 -- mobiscroll
用mobiscroll 可实现ios系统自带的选择器控件效果,支持几乎所有的移动平台(iOS, Android, BlackBerry, Windows Phone 8, Amazon Kindle) ...