Python 爬虫-BeautifulSoup
2017-07-26 10:10:11
Beautiful Soup可以解析html 和 xml 格式的文件。
Beautiful Soup库是解析、遍历、维护“标签树”的功能库。使用BeautifulSoup库非常简单,只需要两行代码,就可以完成BeautifulSoup类的创建,这里命名为soup,接下来就可以对soup进行相关处理了。一个BeautifulSoup类对应html或者xml的全部内容。
BeautifulSoup库将任意html文件转换成utf-8格式

一、解析器
BeautifulSoup类创建的时候第二个参数是解析器,上面的代码中用的解析器为‘html.parser’,BeautifulSoup支持的解析器有:

二、BeautifulSoup类的基本元素


- 使用soup.tag来访问一个标签的内容,如:soup.title;soup.a等,这里的返回值为访问标签的第一个出现的值
- 使用soup.tag.name可以得到当前标签的名字,返回值为字符串,如:soup.a.name 会返回字符串 ‘a’,也可以使用soup.a.parent.name来查看 a 标签父母的名字
- 使用soup.tag.attrs可以得到当前标签的属性,返回值为一个字典,如果没有属性会返回一个空字典,如:soup.a.attrs 会返回 a 标签的属性信息
- 使用soup.tag.string可以得到当前标签的字符串,如:soup.a.string 会返回 a 标签的内容字符串
- 内容字符串有两种类型一是NavigableString类型,一种是Comment类型,Comment类型的格式是<p> <!-- This is an comment --></p>,在调用soup.p.string是会返回This is an comment,但是其类型是Comment类型。
三、soup的内容遍历
标签树的遍历有三种方式,即下行遍历,上行遍历和平行遍历。
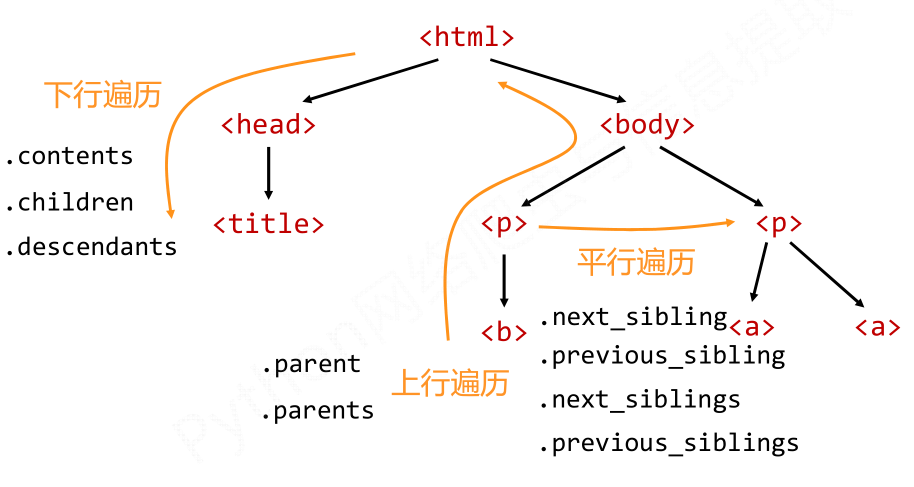
(1)下行遍历属性

举例:
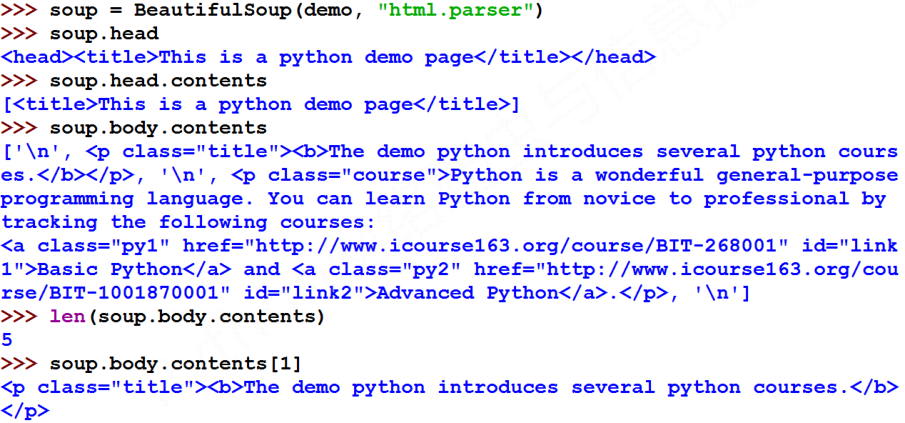
#遍历儿子节点
for child in soup.body.children:
print(child) #遍历子孙节点
for child in soup.body.descendants:
print(child)
值得注意的是子孙节点不仅包含标签,还包含标签之间的字符串类型,这点需要注意与排除。
(2)上行遍历的属性


soup.parent为空,需要进行区分,可以使用for循环对parents进行遍历:

(3)平行遍历的属性
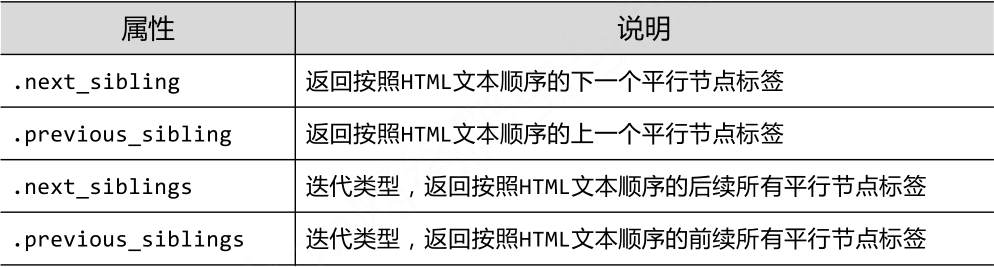
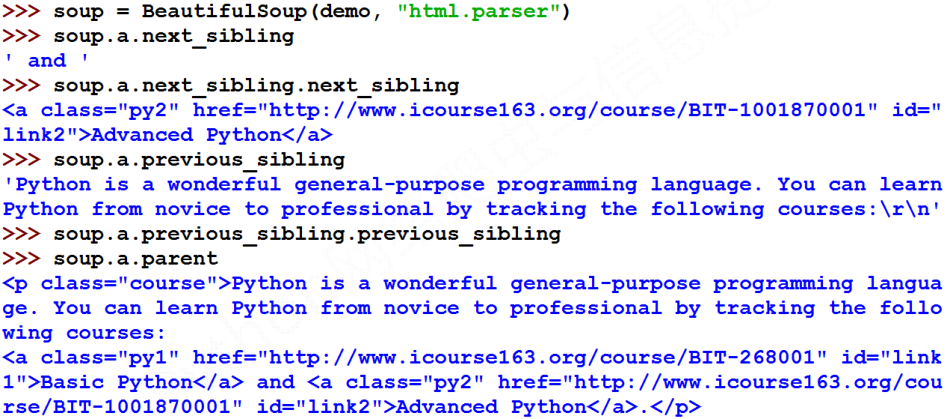
#遍历后续节点
for sibling in soup.a.next_sibling:
print(sibling) #遍历前续节点
for sibling in soup.a.previous_sibling:
print(sibling)
四、信息提取

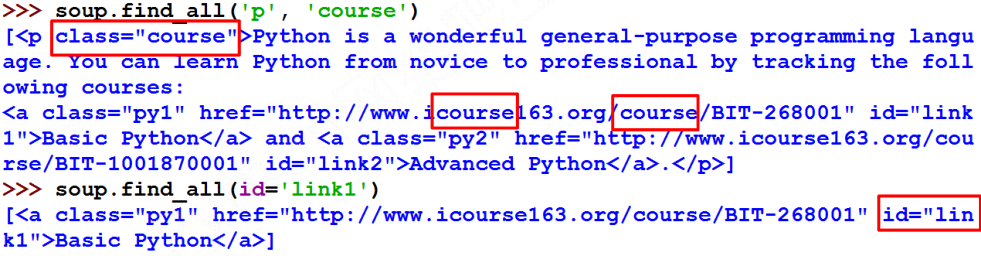
- name : 对标签名称的检索字符串,返回标签name的所有内容,并生成列表,也以使用列表一次查找多个标签;如果标签名称为TRUE,将返回所有的标签信息;也可以使用正则对返回的标签信息做筛选



- attrs: 对标签属性值的检索字符串,可标注属性检索,返回列表,属性值必须精确,如果不提供精确的值得话,会返回空列表,可以使用正则表达式进行非精确的匹配
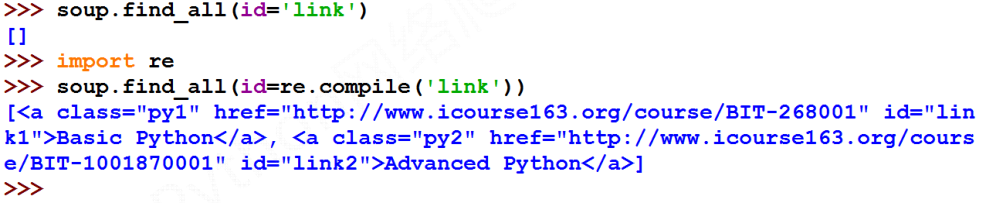
- recursive: 是否对子孙全部检索,默认True

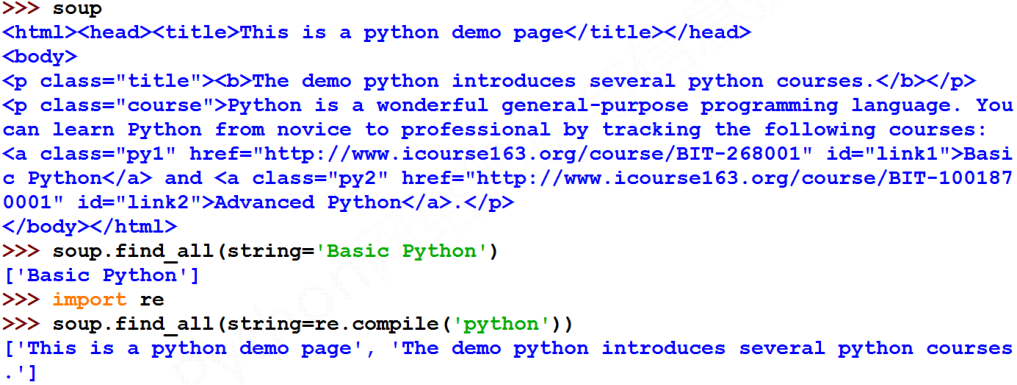
- string: <>…</>中字符串区域的检索字符串,需要加上string=‘’进行检索
简写方式:

扩展方法:

Python 爬虫-BeautifulSoup的更多相关文章
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- python爬虫---BeautifulSoup的用法
BeautifulSoup是一个灵活的网页解析库,不需要编写正则表达式即可提取有效信息. 推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前 ...
- Python爬虫--beautifulsoup 4 用法
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构, 每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSo ...
- python爬虫BeautifulSoup库class_
因为class是python的关键字,所以在写过滤的时候,应该是这样写: r = requests.get(web_url, headers=headers) # 向目标url地址发送get请求,返回 ...
- python爬虫 BeautifulSoup
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码. Bea ...
- Python爬虫 | Beautifulsoup解析html页面
引入 大多数情况下的需求,我们都会指定去使用聚焦爬虫,也就是爬取页面中指定部分的数据值,而不是整个页面的数据.因此,在聚焦爬虫中使用数据解析.所以,我们的数据爬取的流程为: 指定url 基于reque ...
- Python 爬虫 —— BeautifulSoup
from bs4 import BeautifulSoup % 首字母大写,显然这是一个类 1. BeautifulSoup 类 HTML 解析类(parser) r = requests.get(. ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
随机推荐
- Django初级手册2-管理界面的使用及定制
管理界面的使用 管理界面的URL,帐号和密码在第一次输入syncdb时建立 http://127.0.0.1:8000/admin/ 将app加入管理界面 编辑polls/admin.py from ...
- LibSVM源码剖析(java版)
之前学习了SVM的原理(见http://www.cnblogs.com/bentuwuying/p/6444249.html),以及SMO算法的理论基础(见http://www.cnblogs.com ...
- python json-json.loads()函数中的字符串需要是严格的json串格式,不能包含单引号
先看下json的dumps()和loads()函数的定义 json.dumps():将一个Python对象编码成JSON字符串.把字典对象转换成json串 json.loads():将JSON格式字符 ...
- Linux基础命令---ckconfig
chkconfig 启动或者关闭系统服务,设置服务的运行级别,该指令并不会立刻启动或者停止服务,而是在开机的时候发生效果. chkconfig提供了一个简单的命令行工具,用于维护/etc/rc[0-6 ...
- 让前端独立于后端进行开发,模拟数据生成器Mock.js
让前端独立于后端进行开发,模拟数据生成器Mock.jsMock.js 是一款模拟数据生成器,旨在帮助前端攻城师独立于后端进行开发,帮助编写单元测试. Home · nuysoft/Mock Wiki ...
- ELK学习笔记之ELK分析syslog日志
0x00 配置FIlebeat搜集syslog并发送至 #配置 mv /etc/filebeat/filebeat.yml /etc/filebeat/filebeat.yml.bak vim /et ...
- java安全体系之JCA、JCE、JAAS、JSSE及其关系
首先.如果是运行在internet上的系统,并且如果是个涉及到利益性的系统,不可避免的会遭受各种攻击(我们公司的很多系统从OS到DB到webapp就实时有收到攻击和破解),所以尽可能保证安全性将不再是 ...
- 20165211 2017-2018-2 《Java程序设计》第4周学习总结
20165211 2017-2018-2 <Java程序设计>第4周学习总结 教材学习内容总结 本周,我学习了书本上第五.六两章的内容,以下是我整理的主要知识. 第五章 子类与继承 子类与 ...
- C简介与环境配置
C 语言是一种通用的高级语言,最初是由丹尼斯·里奇在贝尔实验室为开发 UNIX 操作系统而设计的.C 语言最开始是于 1972 年在 DEC PDP-11 计算机上被首次实现. 在 1978 年,布莱 ...
- Android内核和Linux内核的区别
1.Android系统层面的底层是Linux,并且在中间加上了一个叫做Dalvik的Java虚拟机,从表面层看是Android运行库.每个Android应用都运行在自己的进程上,享有Dalvik虚拟机 ...