day36 爬虫+http请求+高性能
爬虫
参考博客:http://www.cnblogs.com/wupeiqi/articles/5354900.html
http://www.cnblogs.com/wupeiqi/articles/6283017.html
- 基本操作
概要:
- 发送Http请求,Python Http请求,requests
- 提取指定信息,Python 正则表达式,beautifulsoup
- 数据持久化,
Python两个模块
- requests
- beautifulsoup
Http请求相关知识
- 请求:
请求头:
- cookie
请求体:
- 发送内容
- 响应:
响应头
- 浏览器读取
响应体
- 看到的内容
特殊:
- cookie
- csrftoken
- content-type:
content-type:application/url-form....
name=alex&age=18
content-type:application/json
{name:'alex',age:18}
- 性能相关
- 串行: 1个人,一个任务一个任务,空余时间,玩。
- 线程: 10个人,一个任务一个任务,空余时间,玩。
- 进程: 10个家庭,一个任务一个任务,空余时间,玩。
- 【协程】异步非阻塞:1个人,充分利用时间。
- scrapy框架
- 规则
- redis-scrapy组件
内容详细:
- 基本操作,python伪造浏览器发送请求并或者指定内容
pip3 install requests
response = requests.get('http://www.baidu.com')
response.text
pip3 install beautifulsoup4
from bs4 import Beautifulsoup
soup = Beautifulsoup(response.text,'html.parser')
soup.find(name='h3',attrs={'class':'t'})
soup.find_all(name='h3')
示例:爬取汽车之家新闻
- 模块
requests
GET:
requests.get(url="http://www.oldboyedu.com")
# data="http GET / http1.1\r\nhost:oldboyedu.com\r\n....\r\n\r\n"
requests.get(url="http://www.oldboyedu.com/index.html?p=1")
# data="http GET /index.html?p=1 http1.1\r\nhost:oldboyedu.com\r\n....\r\n\r\n"
requests.get(url="http://www.oldboyedu.com/index.html",params={'p':1})
# data="http GET /index.html?p=1 http1.1\r\nhost:oldboyedu.com\r\n....\r\n\r\n"
POST:
requests.post(url="http://www.oldboyedu.com",data={'name':'alex','age':18}) # 默认请求头:url-formend....
data="http POST / http1.1\r\nhost:oldboyedu.com\r\n....\r\n\r\nname=alex&age=18"
requests.post(url="http://www.oldboyedu.com",json={'name':'alex','age':18}) # 默认请求头:application/json
data="http POST / http1.1\r\nhost:oldboyedu.com\r\n....\r\n\r\n{"name": "alex", "age": 18}"
requests.post(
url="http://www.oldboyedu.com",
params={'p':1},
json={'name':'alex','age':18}
) # 默认请求头:application/json
data="http POST /?p=1 http1.1\r\nhost:oldboyedu.com\r\n....\r\n\r\n{"name": "alex", "age": 18}"
补充:
request.body,永远有值
request.POST,可能没有值
beautifulsoup
soup = beautifulsoup('HTML格式字符串','html.parser')
tag = soup.find(name='div',attrs={})
tags = soup.find_all(name='div',attrs={})
tag.find('h3').text
tag.find('h3').get('属性名称')
tag.find('h3').attrs
HTTP请求:
GET请求:
data="http GET /index?page=1 http1.1\r\nhost:baidu.com\r\n....\r\n\r\n"
POST请求:
data="http POST /index?page=1 http1.1\r\nhost:baidu.com\r\n....\r\n\r\nname=alex&age=18"
socket.sendall(data)
示例【github和抽屉】:任何一个不用验证码的网站,通过代码自动登录
1. 按理说
r1 = requests.get(url='https://github.com/login')
s1 = beautifulsoup(r1.text,'html.parser')
val = s1.find(attrs={'name':'authenticity_token'}).get('value')
r2 = requests.post(
url= 'https://github.com/session',
data={
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': val,
'login':'xxxxx',
'password': 'xxxx',
}
)
r2_cookie_dict = r2.cookies.get_dict() # {'session_id':'asdfasdfksdfoiuljksdf'}
保存登录状态,查看任意URL
r3 = requests.get(
url='xxxxxxxx',
cookies=r2_cookie_dict
)
print(r3.text) # 登录成功之后,可以查看的页面
2. 不按理说
r1 = requests.get(url='https://github.com/login')
s1 = beautifulsoup(r1.text,'html.parser')
val = s1.find(attrs={'name':'authenticity_token'}).get('value')
# cookie返回给你
r1_cookie_dict = r1.cookies.get_dict()
r2 = requests.post(
url= 'https://github.com/session',
data={
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': val,
'login':'xxxxx',
'password': 'xxxx',
},
cookies=r1_cookie_dict
)
# 授权
r2_cookie_dict = r2.cookies.get_dict() # {}
保存登录状态,查看任意URL
r3 = requests.get(
url='xxxxxxxx',
cookies=r1_cookie_dict
)
print(r3.text) # 登录成功之后,可以查看的页面
- requests
"""
1. method
2. url
3. params
4. data
5. json
6. headers
7. cookies
8. files
9. auth
10. timeout
11. allow_redirects
12. proxies
13. stream
14. cert
================ session,保存请求相关信息(不推荐)===================
import requests
session = requests.Session()
i1 = session.get(url="http://dig.chouti.com/help/service")
i2 = session.post(
url="http://dig.chouti.com/login",
data={
'phone': "8615131255089",
'password': "xxooxxoo",
'oneMonth': ""
}
)
i3 = session.post(
url="http://dig.chouti.com/link/vote?linksId=8589523"
)
print(i3.text)
"""
- beautifulsoup
- find()
- find_all()
- get()
- attrs
- text
内容:
1. 示例:汽车之家
2. 示例:github和chouti
3. requests和beautifulsoup
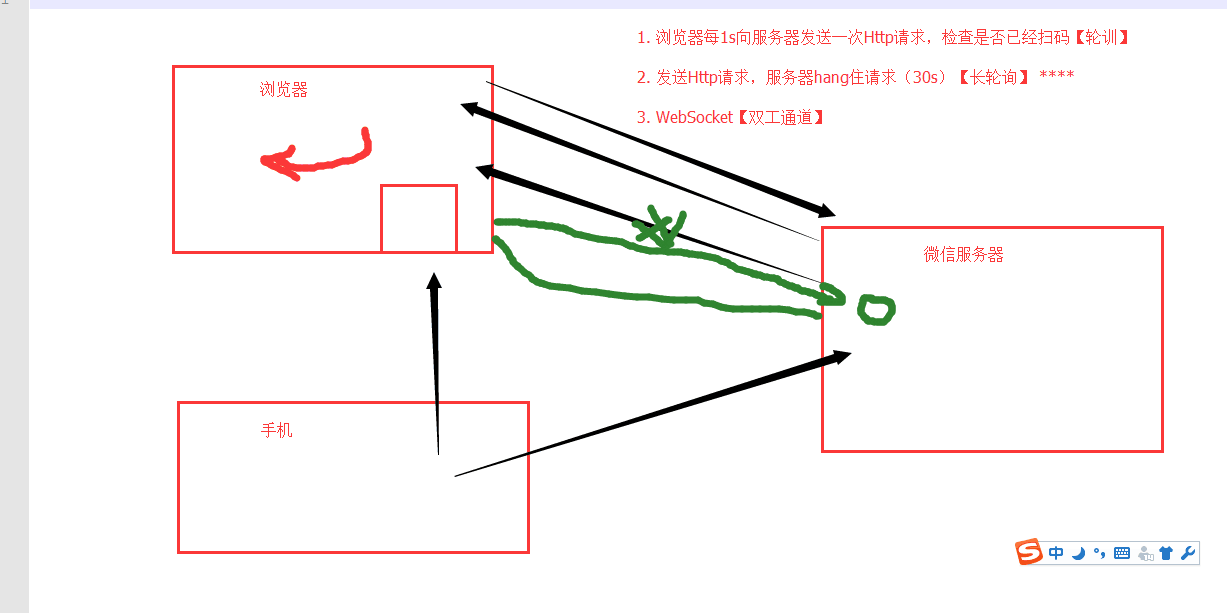
4. 轮询和长轮询
5. Django
request.POST
request.body
# content-type:xxxx
作业:web微信
功能:
1. 二维码显示
2. 长轮询:check_login
3.
- 检测是否已经扫码
- 扫码之后201,头像: base64:.....
- 点击确认200,response.text redirect_ur=....
4. 可选,获取最近联系人信息
安装:
twsited
scrapy框架
课堂代码:https://github.com/liyongsan/git_class/tree/master/day36
day36 爬虫+http请求+高性能的更多相关文章
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- HTTP请求中的User-Agent 判断浏览器类型的各种方法 网络爬虫的请求标示
我们知道,当用户发送一个http请求的时候,浏览的的版本信息也包含在了http请求信息中: 如上图所示,请求 google plus 请求头就包含了用户的浏览器信息: User-Agent:Mozil ...
- fake-useragent,python爬虫伪装请求头
在编写爬虫进行网页数据的时候,大多数情况下,需要在请求是增加请求头,下面介绍一个python下非常好用的伪装请求头的库:fake-useragent,具体使用说明如下: 1.在scrapy中的使用 第 ...
- 爬虫、请求库selenium
阅读目录 一 介绍 二 安装 三 基本使用 四 选择器 五 等待元素被加载 六 元素交互操作 七 其他 八 项目练习 一 介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决r ...
- 爬虫、请求库requests
阅读目录 一 介绍 二 基于GET请求 三 基于POST请求 四 响应Response 五 高级用法 一 介绍 #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,req ...
- python爬虫#网络请求requests库
中文文档 http://docs.python-requests.org/zh_CN/latest/user/quickstart.html requests库 虽然Python的标准库中 urlli ...
- python 爬虫001-http请求过程
HTTP 请求流程 一次完整的HTTP请求过程从TCP三次握手建立连接成功后开始,客户端按照指定的格式开始向服务端发送HTTP请求,服务端接收请求后,解析HTTP请求,处理完业务逻辑,最后返回一个HT ...
- python爬虫添加请求头和请求主体
添加头部信息有两种方法 1.通过添加urllib.request.Request中的headers参数 #先把要用到的信息放到一个字典中 headers = {} headers['User-Agen ...
随机推荐
- python .bat
传值给.bat os.system('%s %s %s %s %s' % ('image_dispose.bat', change_photo,dic['width'], '-resize', cha ...
- C# 使用windows服务发送邮件
最近做了一个使用 C# 写了一个发送邮件的 windows 服务,在这里记录一下. 首先使用 Visual Studio 2015 创建一个 windows 服务项目. 然后在设计器上面右击添加安装程 ...
- java反射之构造方法(三)
一. 1. 二.获取类的构造方法信息. ######################################################################## 三.
- PKU 3267 The Cow Lexicon(动态规划)
题目大意:给定一个字符串和一本字典,问至少需要删除多少个字符才能匹配到字典中的单词序列.PS:是单词序列,而不是一个单词 思路: ...
- filebeat+logstash通过zabbix微信报警
一.安装软件: 1.在要收集日志的机器上安装filebeat: 1).下载安装: cd /usr/local/src wget https://artifacts.elastic.co/downloa ...
- IOS开发-数据库总结
关于数据存储概念: 数据结构: 基本对象:NSDictionary.NSArray和NSSet这些对象. 复杂对象:关系模型.对象图和属性列表多种结构等. 存储方式: 内存:内存存储是临时的,运行时有 ...
- JS与JAVA数据类型的区别
JavaScript与Java数据类型的区别 阅读目录 Number String Boolean Null Undefined Object 今天开始正式认真学习js,虽然在平常j2ee开发中也 ...
- Django学习笔记之Django QuerySet的方法
一般情况下,我们在写Django项目需要操作QuerySet时一些常用的方法已经满足我们日常大多数需求,比如get.filter.exclude.delete神马的感觉就已经无所不能了,但随着项目但业 ...
- Elasticsearch+Kibana+Logstash安装
安装环境: [root@node- src]# cat /etc/redhat-release CentOS Linux release (Core) 安装之前关闭防火墙 firewalld 和 se ...
- 20145103 《Java程序设计》第7周学习总结
20145103<Java程序设计>第7周学习总结 教材学习内容总结 第十三章 时间与日期 13.1 认识时间与日期 就目前来说,即使标注为GMT(无论是文件说明,或者是API的日期时间字 ...