集成学习中的 stacking 以及python实现
集成学习
Ensemble learning 中文名叫做集成学习,它并不是一个单独的机器学习算法,而是将很多的机器学习算法结合在一起,我们把组成集成学习的算法叫做“个体学习器”。在集成学习器当中,个体学习器都相同,那么这些个体学习器可以叫做“基学习器”。
个体学习器组合在一起形成的集成学习,常常能够使得泛化性能提高,这对于“弱学习器”的提高尤为明显。弱学习器指的是比随机猜想要好一些的学习器。
在进行集成学习的时候,我们希望我们的基学习器应该是好而不同,这个思想在后面经常体现。 “好”就是说,你的基学习器不能太差,“不同”就是各个学习器尽量有差异。
集成学习有两个分类,一个是个体学习器存在强依赖关系、必须串行生成的序列化方法,以Boosting为代表。另外一种是个体学习器不存在强依赖关系、可同时生成的并行化方法,以Bagging和随机森林(Random Forest)为代表。
Stacking 的基本思想
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。
上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。
在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
我们贴一张周志华老师《机器学习》一张图来说一下stacking学习算法。

过程1-3 是训练出来个体学习器,也就是初级学习器。
过程5-9是 使用训练出来的个体学习器来得预测的结果,这个预测的结果当做次级学习器的训练集。
过程11 是用初级学习器预测的结果训练出次级学习器,得到我们最后训练的模型。
如果想要预测一个数据的输出,只需要把这条数据用初级学习器预测,然后将预测后的结果用次级学习器预测便可。
Stacking的实现
最先想到的方法是这样的,
1:用数据集D来训练h1,h2,h3...,
2:用这些训练出来的初级学习器在数据集D上面进行预测得到次级训练集。
3:用次级训练集来训练次级学习器。
但是这样的实现是有很大的缺陷的。在原始数据集D上面训练的模型,然后用这些模型再D上面再进行预测得到的次级训练集肯定是非常好的。会出现过拟合的现象。
那么,我们换一种做法,我们用交叉验证的思想来实现stacking的模型,从这里拿来一张图
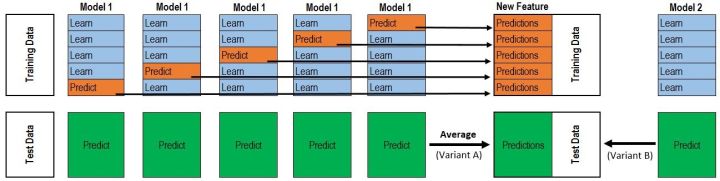
次级训练集的构成不是直接由模型在训练集D上面预测得到,而是使用交叉验证的方法,将训练集D分为k份,对于每一份,用剩余数据集训练模型,然后预测出这一份的结果。重复上面步骤,直到每一份都预测出来。这样就不会出现上面的过拟合这种情况。并且在构造次级训练集的过程当中,顺便把测试集的次级数据也给构造出来了。
对于我们所有的初级训练器,都要重复上面的步骤,才构造出来最终的次级训练集和次级测试集。
构造stacking方法
我们写一个stacking方法,下面是它的实现代码:
import numpy as np
from sklearn.model_selection import KFold
def get_stacking(clf, x_train, y_train, x_test, n_folds=10):
"""
这个函数是stacking的核心,使用交叉验证的方法得到次级训练集
x_train, y_train, x_test 的值应该为numpy里面的数组类型 numpy.ndarray .
如果输入为pandas的DataFrame类型则会把报错"""
train_num, test_num = x_train.shape[0], x_test.shape[0]
second_level_train_set = np.zeros((train_num,))
second_level_test_set = np.zeros((test_num,))
test_nfolds_sets = np.zeros((test_num, n_folds))
kf = KFold(n_splits=n_folds) for i,(train_index, test_index) in enumerate(kf.split(x_train)):
x_tra, y_tra = x_train[train_index], y_train[train_index]
x_tst, y_tst = x_train[test_index], y_train[test_index] clf.fit(x_tra, y_tra) second_level_train_set[test_index] = clf.predict(x_tst)
test_nfolds_sets[:,i] = clf.predict(x_test) second_level_test_set[:] = test_nfolds_sets.mean(axis=1)
return second_level_train_set, second_level_test_set #我们这里使用5个分类算法,为了体现stacking的思想,就不加参数了
from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,
GradientBoostingClassifier, ExtraTreesClassifier)
from sklearn.svm import SVC rf_model = RandomForestClassifier()
adb_model = AdaBoostClassifier()
gdbc_model = GradientBoostingClassifier()
et_model = ExtraTreesClassifier()
svc_model = SVC() #在这里我们使用train_test_split来人为的制造一些数据
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
train_x, test_x, train_y, test_y = train_test_split(iris.data, iris.target, test_size=0.2) train_sets = []
test_sets = []
for clf in [rf_model, adb_model, gdbc_model, et_model, svc_model]:
train_set, test_set = get_stacking(clf, train_x, train_y, test_x)
train_sets.append(train_set)
test_sets.append(test_set) meta_train = np.concatenate([result_set.reshape(-1,1) for result_set in train_sets], axis=1)
meta_test = np.concatenate([y_test_set.reshape(-1,1) for y_test_set in test_sets], axis=1) #使用决策树作为我们的次级分类器
from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier()
dt_model.fit(meta_train, train_y)
df_predict = dt_model.predict(meta_test) print(df_predict)
输出结果如下(因为是随机划分的,所以每次运行结果可能不一样):
[1 0 1 1 1 2 1 2 2 2 0 0 1 2 2 1 0 2 1 0 0 1 1 0 0 2 0 2 1 2]
构造stacking类
事实上还可以构造一个stacking的类,它拥有fit和predict方法
from sklearn.model_selection import KFold
from sklearn.base import BaseEstimator, RegressorMixin, TransformerMixin, clone
import numpy as np
#对于分类问题可以使用 ClassifierMixin class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds # 我们将原来的模型clone出来,并且进行实现fit功能
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model)
kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156) #对于每个模型,使用交叉验证的方法来训练初级学习器,并且得到次级训练集
out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X, y):
self.base_models_[i].append(instance)
instance = clone(model)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
out_of_fold_predictions[holdout_index, i] = y_pred # 使用次级训练集来训练次级学习器
self.meta_model_.fit(out_of_fold_predictions, y)
return self #在上面的fit方法当中,我们已经将我们训练出来的初级学习器和次级学习器保存下来了
#predict的时候只需要用这些学习器构造我们的次级预测数据集并且进行预测就可以了
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model in base_models]).mean(axis=1)
for base_models in self.base_models_ ])
return self.meta_model_.predict(meta_features)
参考
Introduction to Ensembling/Stacking in Python
A Kaggler's Guide to Model Stacking in Practice
Stacked Regressions : Top 4% on LeaderBoard
集成学习中的 stacking 以及python实现的更多相关文章
- 【集成学习】:Stacking原理以及Python代码实现
Stacking集成学习在各类机器学习竞赛当中得到了广泛的应用,尤其是在结构化的机器学习竞赛当中表现非常好.今天我们就来介绍下stacking这个在机器学习模型融合当中的大杀器的原理.并在博文的后面附 ...
- 集成学习-组合策略与Stacking
集成学习是如何把多个分类器组合在一起的,不同的集成学习有不同的组合策略,本文做个总结. 平均法 对数值型输出,平均法是最常用的策略,解决回归问题. 简单平均法 [h(x)表示基学习器的输出] 加权平均 ...
- Ruby学习中(哈希变量/python的字典, 简单的类型转换)
一. 哈希变量(相当于Python中的字典) 详情参看:https://www.runoob.com/ruby/ruby-hash.html 1.值得注意的 (1). 创建Hash时需注意 # 创建一 ...
- PYTHON替代MATLAB在线性代数学习中的应用(使用Python辅助MIT 18.06 Linear Algebra学习)
前言 MATLAB一向是理工科学生的必备神器,但随着中美贸易冲突的一再升级,禁售与禁用的阴云也持续笼罩在高等学院的头顶.也许我们都应当考虑更多的途径,来辅助我们的学习和研究工作. 虽然PYTHON和众 ...
- 决策树(中)-集成学习、RF、AdaBoost、Boost Tree、GBDT
参考资料(要是对于本文的理解不够透彻,必须将以下博客认知阅读): 1. https://zhuanlan.zhihu.com/p/86263786 2.https://blog.csdn.net/li ...
- sklearn中调用集成学习算法
1.集成学习是指对于同一个基础数据集使用不同的机器学习算法进行训练,最后结合不同的算法给出的意见进行决策,这个方法兼顾了许多算法的"意见",比较全面,因此在机器学习领域也使用地非常 ...
- 《机器学习Python实现_10_10_集成学习_xgboost_原理介绍及回归树的简单实现》
一.简介 xgboost在集成学习中占有重要的一席之位,通常在各大竞赛中作为杀器使用,同时它在工业落地上也很方便,目前针对大数据领域也有各种分布式实现版本,比如xgboost4j-spark,xgbo ...
- 集成学习算法汇总----Boosting和Bagging(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- [白话解析] 通俗解析集成学习之bagging,boosting & 随机森林
[白话解析] 通俗解析集成学习之bagging,boosting & 随机森林 0x00 摘要 本文将尽量使用通俗易懂的方式,尽可能不涉及数学公式,而是从整体的思路上来看,运用感性直觉的思考来 ...
随机推荐
- webgote的例子(4)Sql注入(SelectGET)
SQL Injection (Select/GET) 本章内容 (查询显示中要注意的错误) 这里面我们看一下 movie的数值,选择表单中的当我们选择的二个的时候 move的值也变成了第二个,选择表单 ...
- windows安装linux虚拟机、修改apt源
记录一下windows安装虚拟机以及初始配置的一些坑. 安装VMware Workstation 直接百度搜索VMware,选择合适的版本下载: 按照一般软件的安装步骤安装VMware Worksta ...
- keepalived主备切换后的arp问题【转】
使用keepalived的时候主机挂了,备机显示绑定了VIP.但是此时实际还是不能访问.其实就是网关的arp缓存没有刷新. 在服务器上执行一下就行了 arping -I eth0 -c 5 -s ...
- Python递归 — — 二分查找、斐波那契数列、三级菜单
一.二分查找 二分查找也称之为折半查找,二分查找要求线性表(存储结构)必须采用顺序存储结构,而且表中元素顺序排列. 二分查找: 1.首先,将表中间位置的元素与被查找元素比较,如果两者相等,查找结束,否 ...
- python RSA加密解密及模拟登录cnblog
1.公开密钥加密 又称非对称加密,需要一对密钥,一个是私人密钥,另一个则是公开密钥.公钥加密的只能私钥解密,用于加密客户上传数据.私钥加密的数据,公钥可以解密,主要用于数字签名.详细介绍可参见维基百科 ...
- Homestead在windows7 下的搭建
遇到的问题有 1.Homestead 的版本问题,教程git版本是 v5,最新是v7的,如果用最新,就要求vagrant的版本是 2.0的: 2.启动homestead后,出现 No input fi ...
- java通过jdbc插入中文到mysql显示异常(问号或者乱码)
转自:https://blog.csdn.net/lsr40/article/details/78736855 首先本人菜鸡一个,如果有说错的地方,还请大家指出予批评 对于很多初学者来说,中文字符编码 ...
- webStorage,离线缓存
一.webStorage 1.目标 1.了解cookie的不足之处,引入webstorage的概念 2.学习并且掌握webstorage有哪两种 3.学习并且掌握sessionStorag ...
- 使用Python快速查询所有指定匹配KEY的办法
import redis redis_ip = '10.10.14.224' redis_port = 18890 # 配置redis的连接办法 # http://blog.csdn.net/u010 ...
- vim 图册
网上看到的一些图,感觉不错,分享一下 我现在感觉配置文件,很多没有必要,反而很花哨,但是这些基础的东西,反而很高效,实在 VIM的列编辑操作 删除列 1.光标定位到要操作的地方. 2.CTRL+v 进 ...