7.Python使用pandans遇到的坑
1.开始入门Pandas,然后跟着网上的例子,编写以下代码:
import pandas as pd
import datetime
import pandas.io.data as web start = datetime.datetime(2010,1,1)
end = datetime.datetime(2015,8,22) df = web.DataReader('XOM','yahoo',start,end) print(df)
2.一运行报错信息为:ModuleNotFoundError: No module named ' pandas.io.data'
pandas.io.data'

3.查找网上教程,发现pandas.io.data已经用不成了,得替换为pandas_datareader,故在dos命令输入:pip3 install pandas_datareader,在pycharm-setting导入
4.修改后的代码如下所示:
import pandas as pd
import datetime
import pandas_datareader.data as web start = datetime.datetime(2010,1,1)
end = datetime.datetime(2015,8,22) df = web.DataReader('XOM','yahoo',start,end) print(df)
5.依旧报错:ImportError: cannot import name 'is_list_like'
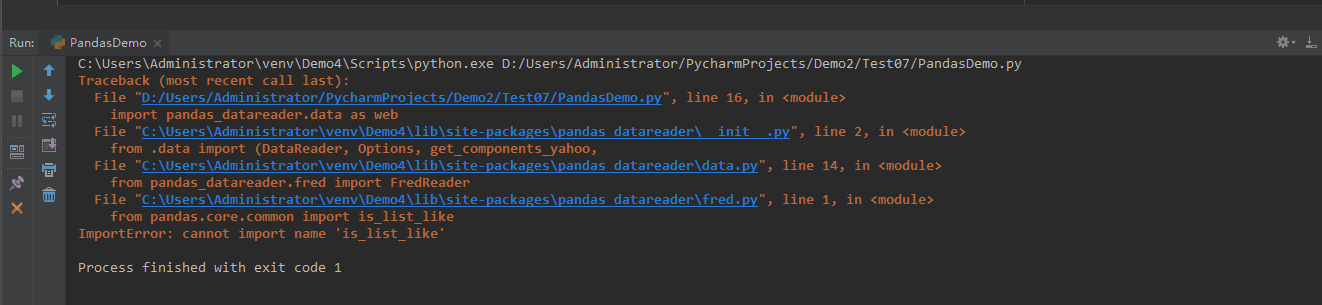
6.查找网上教程后,需要去fred.py中修改信息,在pycharm报错信息中,点击C:\Users\Adinistrator\venv\Demo4\lib\site-packages\pandas_datareader\fred.py中,将from pandas.core.common import is_list_like替换为:from pandas.api.types import is_list_like(正确方式)
7.继续修改代码后,运行,依旧报错,报错信息如下:
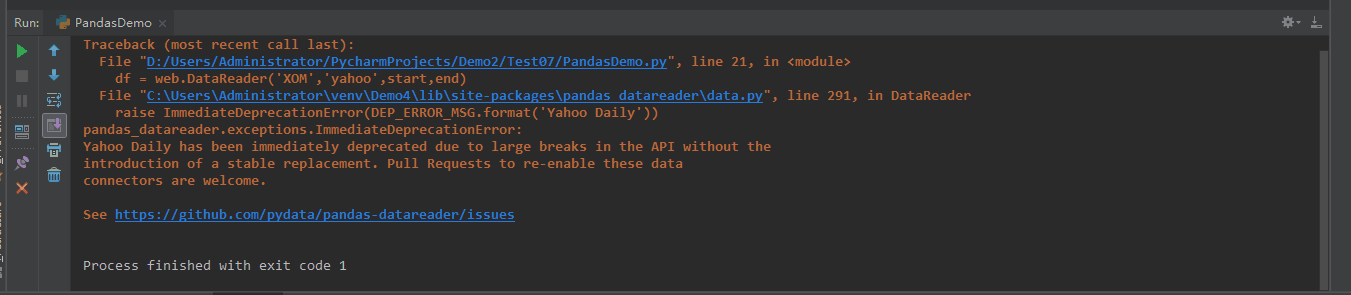
8.依旧寻找教程,发现错误原因为:Yahoo的数据源已经失效,使用另一个数据源即可,最后代码如下所示:
import pandas as pd
import datetime
import pandas_datareader.data as web start = datetime.datetime(2010,1,1)
end = datetime.datetime(2015,8,22) df = web.DataReader('F-F_Research_Data_factors','famafrench',start,end)
print(df)
7.Python使用pandans遇到的坑的更多相关文章
- 关于python数据序列化的那些坑
-----世界上本来没那么多坑,python更新到3以后坑就多了 无论哪一门语言开发,都离不了数据储存与解析,除了跨平台性极好的xml和json之外,python要提到的还有自身最常用pickle模块 ...
- Python开发过程中17个坑
一.不要使用可变对象作为函数默认值 复制代码代码如下: In [1]: def append_to_list(value, def_list=[]): ...: def_list. ...
- python 库之lxml安装 坑一个
error: command 'C:\\Users\\Admin\\AppData\\Local\\Programs\\Common\\Microsoft\\Visual C++ for Python ...
- python中sqlite问题和坑
import sqlite3 #导入模块 conn = sqlite3.connect('example.db') C=conn.cursor() #创建表 C.execute('''CREATE T ...
- Python读取大文件的"坑“与内存占用检测
python读写文件的api都很简单,一不留神就容易踩"坑".笔者记录一次踩坑历程,并且给了一些总结,希望到大家在使用python的过程之中,能够避免一些可能产生隐患的代码. 1. ...
- influx+grafana自定义python采集数据和一些坑的总结
先上网卡数据采集脚本,这个基本上是最大的坑,因为一些数据的类型不正确会导致no datapoint的错误,真是令人抓狂,注意其中几个key的值必须是int或者float类型,如果你不慎写成了strin ...
- 基于python的Appium自动化测试的坑
真的感谢@虫师 这位来自互联网的老师,让我这个原本对代码胆怯且迷惑的人开始学习自动化测试. 一开始搜索自动化测试的时候,虫师的博客园教程都是在百度的前几位的,我就跟着虫师博客园里面的教程学习.后来学s ...
- Python Django开发遇到的坑(版本不匹配)
这个问题 进入django 后台, 添加,修改都不可以,只有删除可以,那么百分之百是这个问题 对照一下,是你的django 版本低了还是 python版本高了,对照的话就没问题了 这个坑,弄了两天啊! ...
- Python可变数据类型list填坑一则
前提概要 最近写业务代码时遇到一个列表的坑,在此记录一下. 需求 现在有一个普通的rule列表: rule = [["ID",">",0]] 在其他地方经 ...
随机推荐
- mysql 在创建表或者插入时遇到关键字报错
mysql 在创建表或者插入时遇到关键字:比如name,status等.都不报错 解决方法:在字段上加上` 上面这个符号是键盘ecs下面那个符号
- 大白话,讲编程之《ES6系列连载》汇总
如果你经历过2,3年前的前端开发,你一定感受过兼容IE6,7的痛苦,一定用过网页三剑客的dreamweaver编写html,面试的时候面试官一定会问你:会用PS切图吗? 刚开始的时候你发现,web前端 ...
- Python写入CSV文件的问题
这篇文章主要是前几天我处理数据时遇到的三个问题: Python写入的csv的问题 Python2与Python3处理写入写入空行不同的处理方式 Python与Python3的编码问题 其实上面第3个问 ...
- [转载]Java生成Word文档
在开发文档系统或办公系统的过程中,有时候我们需要导出word文档.在网上发现了一个用PageOffice生成word文件的功能,就将这块拿出来和大家分享. 生成word文件与我们编辑word文档本质上 ...
- C++进阶3.字节对齐 联合
C++进阶3.字节对齐 联合 20131011 多益和金山笔试 知识漏洞 20131011 前言: 今天下午是多益网络的笔试,整体感觉还好,但是找到很多的知识漏洞.一直笔试到6:00,然后紧张的从会生 ...
- (MSSQL)sp_refreshview刷新视图失败及更新Table字段失败的问题解决
在近期工作中遇到一个任务,需要批量更改散布在很多Table中的某字段,同时刷新相关视图,但是在执行脚本时,发现了如下问题 更新字段问题 消息 ,级别 ,状态 ,第 行 对象'View_Simple' ...
- django中如何将多个app归到一个目录下。
1.当startapps 生成多个app后,为了便于管理,可新建一个apps目录,把应用全部剪切进apps. 如果是在pycharm中,会提示是否自动更新路径,这里要全部选择取消. QQ群交流:697 ...
- Python中列表生成式和字典生成式练习
(一)列表生成式 练习一:编写名为collatz(number)的函数:实现的功能:参数为偶数时,打印number// 2;参数为奇数时,打印3*number + 1 解析: number = int ...
- [置顶]
不再迷惑,也许之前你从未真正懂得 Scroller 及滑动机制
学习本来就是从困惑中摸索问题答案的过程,能够描述出来问题就已经成功了一半.只要发现了困扰你的东西是什么,那么你就离解答出来不远了.----肯尼斯 R. 莱伯德 一直以来,Android 开发中绕不过去 ...
- iOS开发之如何应对苹果app的ipv6时代?
WWDC2015苹果宣布在ios9支持纯IPv6的网络服务,并且要求2016年提交到app store的应用必须兼容纯IPv6的网络,要求适配的系统版本是ios9以上(包括ios9). 一 背景介绍 ...