使用Selenium&PhantomJS的方式爬取代理
前面已经爬取了代理,今天我们使用Selenium&PhantomJS的方式爬取快代理 :快代理 - 高速http代理ip每天更新。
首先分析一下快代理,如下
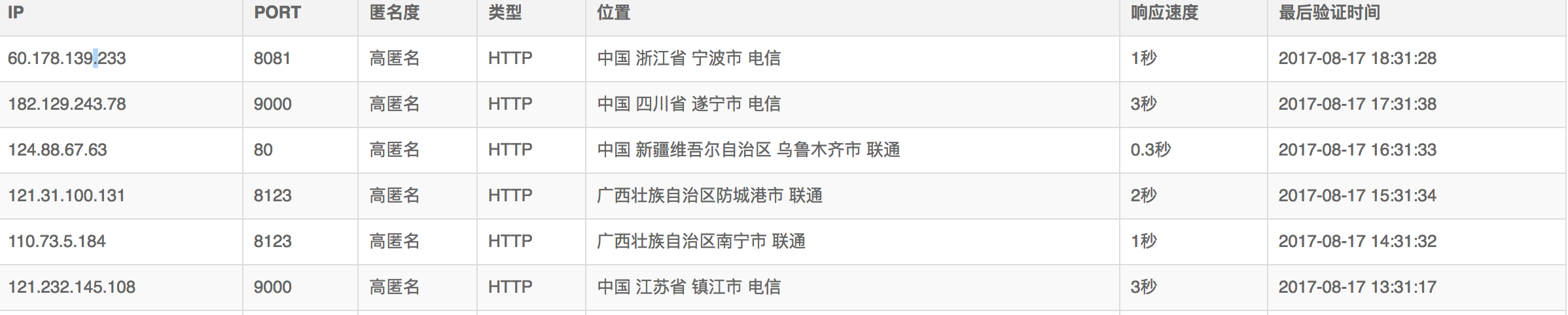
使用谷歌浏览器,检查,发现每个代理信息都在tr里面,每个tr里面包含多个td,就是IP的信息。
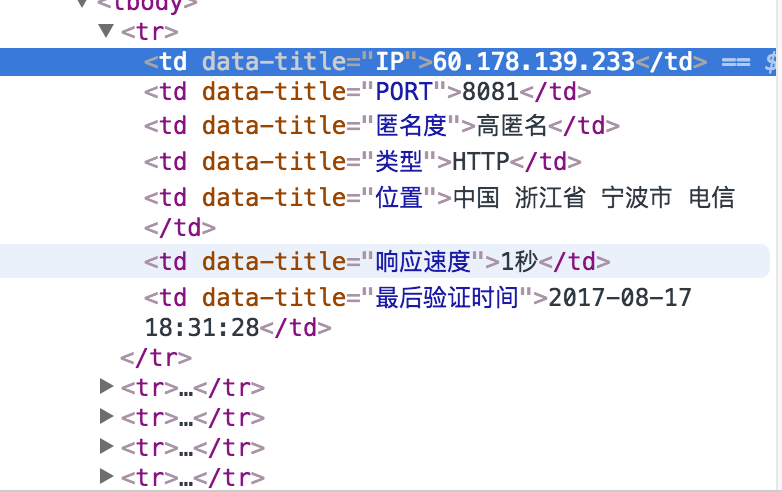
这个结构我们可以通过多种方法抓取,例如bs4、xpath、selenium等
这里我们演示selenium方法。具体解释在下面代码中都有的。
from selenium import webdriver class Item(object):
'''
模拟scrapy框架
写item类
用以表示每个代理
'''
ip = None #IP地址
port = None #端口
anonymous = None #是否匿名
type = None #http 或者https
local = None #物理地址
speed = None #速度 class GetProxy(object):
def __init__(self):
self.starturl = 'http://www.kuaidaili.com/free/inha/'
self.urls = self.get_urls()
self.proxylist = self.get_proxy_list(self.urls)
self.filename = 'proxy.txt'
self.saveFile(self.filename,self.proxylist) def get_urls(self):
'''
:return: 返回代理url列表
'''
urls = []
for i in range(1,3):
url = self.starturl + str(i)
urls.append(url)
return urls def get_proxy_list(self,urls):
'''
爬取代理列表
:param urls:
:return:
'''
browser = webdriver.PhantomJS()
proxy_list = [] for url in urls:
browser.get(url) # 通过get方法打开
browser.implicitly_wait(3)
elements = browser.find_elements_by_xpath('//tbody/tr') #找到每个代理的位置
for element in elements:
item = Item()
item.ip = element.find_element_by_xpath('./td[1]').text
item.port = element.find_element_by_xpath('./td[2]').text
item.anonymous = element.find_element_by_xpath('./td[3]').text
item.local = element.find_element_by_xpath('./td[4]').text
item.speed = element.find_element_by_xpath('./td[5]').text
print(item.ip)
proxy_list.append(item) browser.quit()
return proxy_list def saveFile(self,filename,proxy_list):
'''
将爬取的信息保存到本地
:param filename:
:param proxy_list:
:return:
'''
with open(filename,'w') as f:
for item in proxy_list:
f.write(item.ip + '\t')
f.write(item.port + '\t')
f.write(item.anonymous + '\t')
f.write(item.local + '\t')
f.write(item.speed + '\n\n') if __name__ == '__main__':
Get = GetProxy()
下面我们展示一下爬取的结果

如果用到代理的话,还需要对这些IP进行测试一下。
使用Selenium&PhantomJS的方式爬取代理的更多相关文章
- 使用selenium+phantomJS实现网页爬取
有些网站反爬虫技术设计的非常好,很难采用WebClient等技术进行网页信息爬取,这时可以考虑采用selenium+phantomJS模拟浏览器(其实是真实的浏览器)的方式进行信息爬取.之前一直使用的 ...
- selenium&phantomjs实战--漫话爬取
为什么直接保存当前网页,而不是找到所有漫话链接,再有针对性的保存图片? 因为防盗链的原因,当直接保存漫话链接图片时,只能保存到防盗链的图片. #!/usr/bin/env python # _*_ c ...
- 针对源代码和检查元素不一致的网页爬虫——利用Selenium、PhantomJS、bs4爬取12306的列车途径站信息
整个程序的核心难点在于上次豆瓣爬虫针对的是静态网页,源代码和检查元素内容相同:而在12306的查找搜索过程中,其网页发生变化(出现了查找到的数据),这个过程是动态的,使得我们在审查元素中能一一对应看到 ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- python爬虫爬取代理IP
# #author:wuhao # #--*------------*-- #-****#爬取代理IP并保存到Excel----#爬取当日的代理IP并保存到Excel,目标网站xicidaili.co ...
- Python爬虫-代理池-爬取代理入库并测试代理可用性
目的:建立自己的代理池.可以添加新的代理网站爬虫,可以测试代理对某一网址的适用性,可以提供获取代理的 API. 整个流程:爬取代理 ----> 将代理存入数据库并设置分数 ----> 从数 ...
- Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】
练习1-爬取歌曲列表 任务:通过两个案例,练习使用Selenium操作网页.爬取数据.使用无头模式,爬取网易云的内容. ''' 任务:通过两个案例,练习使用Selenium操作网页.爬取数据. 使用无 ...
- 爬虫实例——爬取淘女郎相册(通过selenium、PhantomJS、BeautifulSoup爬取)
环境 操作系统:CentOS 6.7 32-bit Python版本:2.6.6 第三方插件 selenium PhantomJS BeautifulSoup 代码 # -*- coding: utf ...
随机推荐
- 【转】如何使用JMeter测试Java项目
一. Apache JMeter工具 1)简介 JMeter——一个100%的纯Java桌面应用,它是 Apache组织的开放源代码项目,它是功能和性能测试的工具.JMeter可以用于测试静态或者动态 ...
- [Java.web]Web应用结构
以Web应用放在 Tomcat\webapps\ 目录下为例 day01 目录 | |------------- html.jsp.css.js 文件等 |------------- ...
- Window下安装Memecached
原创,如有转载请注明来处! memcached是一套分布式的快取系统,当初是Danga Interactive为了LiveJournal所发展的,但被许多软件(如MediaWiki)所使用.这是一套开 ...
- hadoop中使用hprof工具进行性能分析
在编写完成MapReduce程序之后,调优就成为了一个大问题.如何使用现有工具快速地分析出任务的性能? 对于本地的java应用程序,进行分析可能稍微简单,但是hadoop是一个分布式框架,MapR ...
- python学习 (三十三) Modules
1: 方法一: 导入整个模块 import math class ModulesDemo(): def builtin_modules(self): print(math.sqrt()) m = Mo ...
- node操作mongoDB数据库的最基本例子
连接数据库 var mongo=require("mongodb"); var host="localhost"; var port=mongo.Connect ...
- 【洛谷】P2434 [SDOI2005]区间(暴力)
题目描述 现给定n个闭区间[ai, bi],1<=i<=n.这些区间的并可以表示为一些不相交的闭区间的并.你的任务就是在这些表示方式中找出包含最少区间的方案.你的输出应该按照区间的升序排列 ...
- CentOS7 系统菜单中添加快捷方式
一,在桌面新建一个文件 文件名随意,但必须带有.desktop的后缀名, 以Eclipse为例 vi /usr/share/applications/eclipse.desktop 二,在文件中写入如 ...
- JAVA访问控制变量、类变量、类方法
1.私有:同类中 2.默认:同包中的类 3.保护:同包中的类 子类中(继承性) 4.公有:无范围 创建子类并覆盖方法时,必须考虑原来方法的访问控制: 作为通用的规则,覆盖方法是,新方法的访问控制不能 ...
- Navicat use HTTP Tunnel
Apply OS: Windows, macOS, Linux Apply Navicat Product: Navicat for MySQL, Navicat for PostgreSQL, Na ...