MyCat的安装及基本使用(MySQL分库分表)
1.Mycat的简介
1.1 数据库集群产生的背景
如今随着互联网的发展,数据的量级也是成指数的增长,从GB到TB到PB。对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求。这个时候NoSQL的出现暂时解决了这一危机。它通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来获取性能上的提升。
但是,在有些场合NoSQL一些折衷是无法满足使用场景的,就比如有些使用场景是绝对要有事务与安全指标的。这个时候NoSQL肯定是无法满足的,所以还是需要使用关系性数据库。如果使用关系型数据库解决海量存储的问题呢?此时就,为了提高查询性能将一个数据库的数据分散到不同的数据库中存储。
- 1、解决单机mysql存储容量有限的问题
- 2、解决单机查询性能不高的问题
- 3、解决mysql服务的高可用问题
1.2 MyCat简介
Mycat 背后是阿里曾经开源的知名产品——Cobar。Cobar 的核心功能和优势是 MySQL 数据库分片,此产品曾经广为流传。Cobar 的思路和实现路径的确不错。基于 Java 开发的,实现了 MySQL 公开的二进制传输协议,巧妙地将自己伪装成一个 MySQL Server,目前市面上绝大多数 MySQL 客户端工具和应用都能兼容。比自己实现一个新的数据库协议要明智的多,因为生态环境在哪里摆着。
Mycat 是基于 cobar 演变而来,对 cobar 的代码进行了彻底的重构,使用 NIO 重构了网络模块,并且优化了 Buffer 内核,增强了聚合,Join 等基本特性,同时兼容绝大多数数据库成为通用的数据库中间件。
简单的说,MyCAT就是:一个新颖的数据库中间件产品支持mysql集群,或者mariadb cluster,提供高可用性数据分片集群。你可以像使用mysql一样使用mycat。对于开发人员来说根本感觉不到mycat的存在。
MyCat支持的数据库:
mysql,oracle,sqlserver等。
1.2MyCat下载及安装
1.2.1 MySQL安装与启动
JDK:要求jdk必须是1.7及以上版本
MySQL:推荐mysql是5.5以上版本
1.2.2 MyCat安装及启动
MyCat的官方网站:
下载地址:
https://github.com/MyCATApache/Mycat-download
第一步:将Mycat-server-1.4-release-20151019230038-linux.tar.gz上传至服务器
第二步:将压缩包解压缩。建议将mycat放到/usr/local/mycat目录下。
tar -xzvf Mycat-server-1.4-release-20151019230038-linux.tar.gz mv mycat /usr/local
第三步:进入mycat目录的bin目录,启动mycat
启动
./mycat start 停止
./mycat stop
mycat 支持的命令{ console | start | stop | restart | status | dump }
Mycat的默认端口号为:8066
1.2.3通过MySQL客户端连接mycat(test/test)
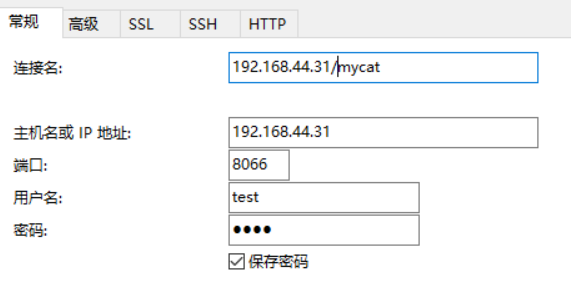
Mycat的默认端口和默认的用户名和密码:在conf目录下面的server.xml文件中。
1.3MyCat分片-海量数据存储解决方案
1.3.1 什么是分片
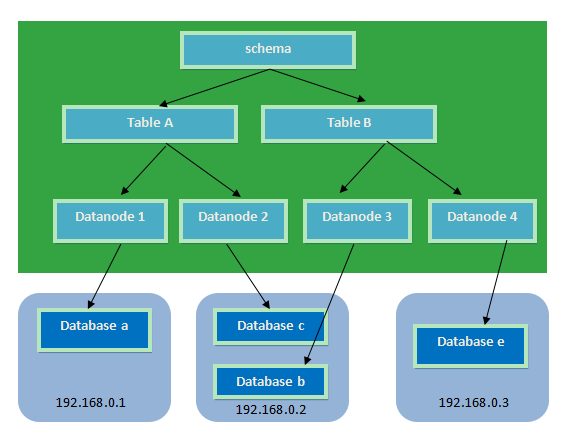
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。
MyCat分片策略:
1.3.2 分片相关的概念
逻辑库(schema) :
前面一节讲了数据库中间件,通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
逻辑表(table):
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
分片表:是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。 总而言之就是需要进行分片的表。
非分片表:一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
分片节点(dataNode)
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
节点主机(dataHost)
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
分片规则(rule)
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
1.3.3 MyCat分片配置
(1)配置schema.xml
schema.xml作为MyCat中重要的配置文件之一,管理着MyCat的逻辑库、逻辑表以及对应的分片规则、DataNode以及DataSource。弄懂这些配置,是正确使用MyCat的前提。这里就一层层对该文件进行解析。
table 标签定义了MyCat中的逻辑表 rule用于指定分片规则,auto-sharding-long的分片规则是按ID值的范围进行分片 1-5000000 为第1片 5000001-10000000 为第2片....
dataNode 标签定义了MyCat中的数据节点,也就是我们通常所说的数据分片。
dataHost标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。
1、分别在MySQL服务器 192.168.44.31:3306 上创建3个数据库:分别是db1 db2 db3,另外在 192.168.44.31:3306 上创建数据库db4
2、修改schema.xml如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<!-- 逻辑库 -->
<schema name="ZYTEMPDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- 自动取模分片 -->
<table name="tb_test" dataNode="dn1,dn2,dn3,dn4" rule="auto-sharding-long" />
<!-- 一致性hash分片 -->
<!-- <table name="tb_order" dataNode="dn1,dn2,dn3,dn4" rule="sharding-by-murmur-order" /> -->
</schema> <!-- 分片 -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataNode name="dn4" dataHost="localhost2" database="db4" /> <!-- 物理节点主机 -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.44.31:3306" user="root"
password="root">
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.44.34:3306" user="root"
password="root">
</writeHost>
</dataHost>
</mycat:schema>
(2)配置 server.xml
server.xml几乎保存了所有mycat需要的系统配置信息。最常用的是在此配置用户名、密码及权限。在system中添加UTF-8字符集设置,否则存储中文会出现问号
<property name="charset">utf8</property>
修改user的设置 , 我们这里为 PINYOUGOUDB设置了两个用户
<user name="test">
<property name="password">test</property>
<property name="schemas">ZYTEMPDB</property>
</user>
<user name="root">
<property name="password">root</property>
<property name="schemas">ZYTEMPDB</property>
</user>

1.3.4 MyCat分片测试
连接mycat服务器 ,执行下列语句创建一个表:
CREATE TABLE tb_test (
id BIGINT(20) NOT NULL,
title VARCHAR(100) NOT NULL ,
PRIMARY KEY (id)
) ENGINE=INNODB DEFAULT CHARSET=utf8
插入数据
INSERT INTO TB_TEST(ID,TITLE) VALUES(1,'log1');
INSERT INTO TB_TEST(ID,TITLE) VALUES(2,'log2');
INSERT INTO TB_TEST(ID,TITLE) VALUES(3,'log3'); INSERT INTO TB_TEST(ID,TITLE) VALUES(5000001,'log5000001'); INSERT INTO TB_TEST(ID,TITLE) VALUES(10000001,'log10000001');
此时会发现db1,db2,db3的存储情况如下:
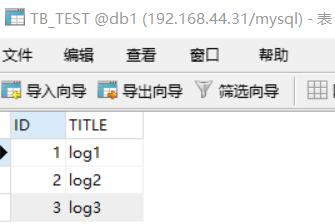


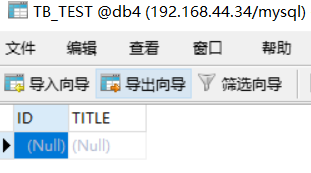
那么为什么会这样存储呢?这就引出了分片规则,因为我们上面的配置文件用的分片规则是 rule="auto-sharding-long"
这种分片规则很显然不是我们常用的,下面就说一下如何配置我们常用的一种分片规则murmur
1.3.5 MyCat分片规则murmur(一致性hash)
(1)rule.xml中的配置
cd /usr/local/mycat/mycat/conf/
vim rule.xml
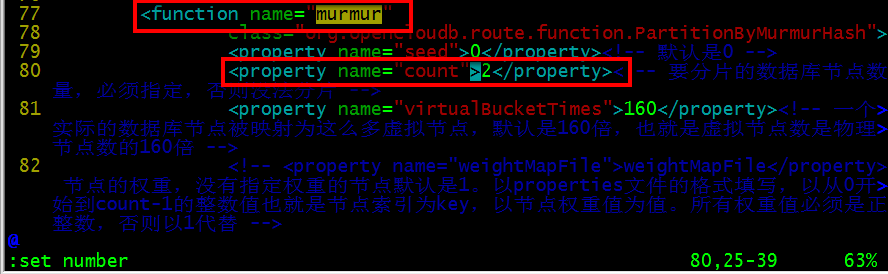
将上图的2改为4,因为我们有四个db:db1,db2,db3,db4。
假设我们有一张order表,按照order_id进行分片,我们新添加一个分片规则:
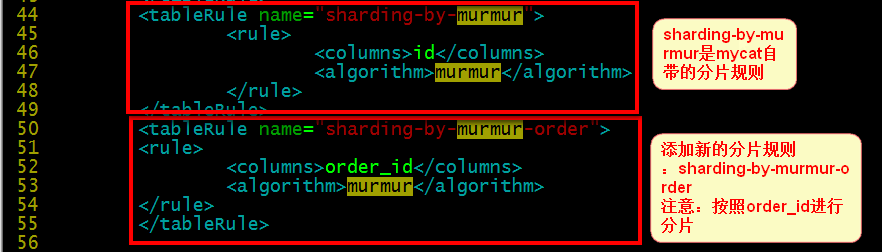
(2)schema.xml的配置
vim schema.xml 编辑schema.xml文件,在tb_test下方添加如下配置:
<table name="tb_order" dataNode="dn1,dn2,dn3" rule="sharding-by-murmur-order" />
(3)重启mycat
cd /usr/local/mycat/mycat/bin/
./mycat restart
(4)连接mycat,创建简单的order表,并插入数据(注意mycat把我们的表名和字段名都变成大写的了)
CREATE TABLE tb_order (
order_id BIGINT(20) NOT NULL,
title VARCHAR(100) NOT NULL ,
PRIMARY KEY (order_id)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(1,'ORDER1');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(2,'ORDER2');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(3,'ORDER3');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(4,'ORDER4');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(5,'ORDER5');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(6,'ORDER6');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(7,'ORDER7');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(8,'ORDER8');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(9,'ORDER9');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(10,'ORDER10');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(11,'ORDER11');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(12,'ORDER12');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(13,'ORDER13');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(14,'ORDER14');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(15,'ORDER15');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(16,'ORDER16');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(17,'ORDER17');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(18,'ORDER18');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(19,'ORDER19');
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(20,'ORDER20');
此时会发现db1,db2,db3,db4的存储情况如下:
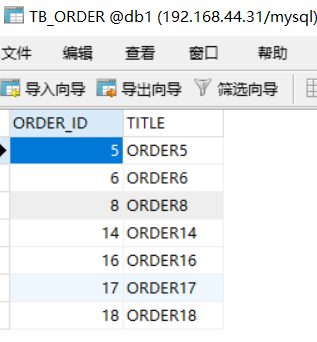
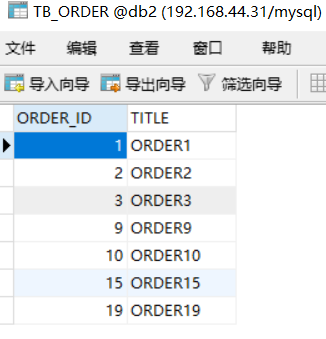
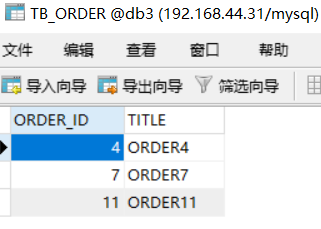
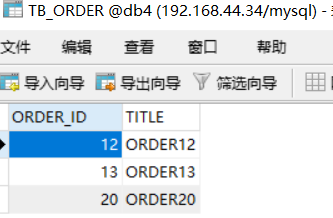
这种分片规则就比较合理了,而且数据越多均分的越匀。另外还有很多分片规则,比如按照时间之类的,有需要的可以自己查一下资料。
MyCat的安装及基本使用(MySQL分库分表)的更多相关文章
- 高可用Mysql架构_Mysql主从复制、Mysql双主热备、Mysql双主双从、Mysql读写分离(Mycat中间件)、Mysql分库分表架构(Mycat中间件)的演变
[Mysql主从复制]解决的问题数据分布:比如一共150台机器,分别往电信.网通.移动各放50台,这样无论在哪个网络访问都很快.其次按照地域,比如国内国外,北方南方,这样地域性访问解决了.负载均衡:M ...
- 你们要的MyCat实现MySQL分库分表来了
❝ 借助MyCat来实现MySQL的分库分表落地,没有实现过的,或者没了解过的可以看看 ❞ 前言 在之前写过一篇关于mysql分库分表的文章,那篇文章只是给大家提供了一个思路,但是回复下面有很多说是细 ...
- mysql分库分表(一)
mysql分库分表 参考: https://blog.csdn.net/xlgen157387/article/details/53976153 https://blog.csdn.net/cleve ...
- Mysql分库分表方案
Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. m ...
- MYSQL分库分表和不停机更改表结构
在MYSQL分库分表中我们一般是基于数据量比较大的时间对mysql数据库一种优化的做法,下面我简单的介绍一下mysql分表与分库的简单做法. .分库分表 很明显,一个主表(也就是很重要的表,例如用户表 ...
- MySQL分库分表备份脚本
MySQL分库备份脚本 #脚本详细内容 [root@db02 scripts]# cat /server/scripts/Store_backup.sh #!/bin/sh MYUSER=root M ...
- 【分库、分表】MySQL分库分表方案
一.Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. ...
- Java互联网架构-Mysql分库分表订单生成系统实战分析
概述 分库分表的必要性 首先我们来了解一下为什么要做分库分表.在我们的业务(web应用)中,关系型数据库本身比较容易成为系统性能瓶颈,单机存储容量.连接数.处理能力等都很有限,数据库本身的“有状态性” ...
- mysql分库分表(二)
mysql分库分表 参考: https://www.cnblogs.com/dongruiha/p/6727783.html https://www.cnblogs.com/oldUncle/p/64 ...
- (转)企业Shell实战-MySQL分库分表备份脚本
本文来自http://www.xuliangwei.com/xubusi/252.html 免费视频讲解见 http://edu.51cto.com/course/course_id-5064.htm ...
随机推荐
- Serf 了解
Introduction to Serf Welcome to the intro guide to Serf! This guide will show you what Serf is, expl ...
- Wordpress网站添加七牛云cdn
1.一个搭建好的网站和七牛云账号 2.七牛云进入控制面板 3创建存储空间 4创建好了空间拿七牛给你了测试域名(但只可以使用30天)所以绑定自定义域名(这个必须是备案过的) 5.设置自定义域名(加速域名 ...
- webstorm配置scss的小结
1)安装ruby 2)安装sass 3)配置webstorm 打开webstrom ->file->setting->Tools->file watcher 添加scss pr ...
- requireJS的使用说明
RequireJS的目标是鼓励代码的模块化,它使用了不同于传统<script>标签的脚本加载步骤.可以用它来加速.优化代码,但其主要目的还是为了代码的模块化 requireJS 加载代码的 ...
- 在vue中无论使用router-link 还是 @click事件,发现都没法从列表页点击跳转到内容页去
在vue中如论使用router-link 还是 @click事件,发现都没法从列表页点击跳转到内容页去,以前都是可以的,想着唯一不同的场景就是因为运用了scroll组件(https://ustbhua ...
- 常见企业IT支撑【5、内网DNS cache轻量服务dnsmasq】
可参考http://www.centoscn.com/CentosServer/dns/2014/0113/2355.html 布署keepalive高可用方式 此方案只适合小型企业,规模少的情况下使 ...
- 基于STL优先队列和邻接表的dijkstra算法
首先说下STL优先队列的局限性,那就是只提供入队.出队.取得队首元素的值的功能,而dijkstra算法的堆优化需要能够随机访问队列中某个节点(来更新源点节点的最短距离). 看似可以用vector配合m ...
- 【学习笔记】dp入门
知识点 动态规划(简称dp),可以说是各种程序设计中遇到的第一个坎吧,这篇博文是我对dp的一点点理解,希望可以帮助更多人dp入门. 先看看这段话 动态规划(dynamic programming) ...
- verilog 之数字电路 寄存器,触发器。
我一直听说没有由code到circuit就只是入门了.实在没办法了.我想了一招,一个一个的写,然后看RTL,然后分析.这是第一篇. 1.触发器. 没有复位,置位.posedge clk 是触发沿时钟. ...
- thymeleaf switch在表格中的使用,遇到的空行问题
switch在表格中的使用时 如果把<td>写在<div th:switch="${data.isShow}"> 里面导致外面出现很多空的<div&g ...