【RabbitMQ学习记录】- 消息队列存储机制源码分析
本文来自 网易云社区 。
RabbitMQ在金融系统,OpenStack内部组件通信和通信领域应用广泛,它部署简单,管理界面内容丰富使用十分方便。笔者最近在研究RabbitMQ部署运维和代码架构,本篇文章主要记录下RabbitMQ存储机制相关内容和源码分析。
一、RabbitMQ进程架构
Erlang是基于Actor模型的一门天然多进程、分布式和高并发的语言。一个Erlang虚拟机对应一个操作系统进程,一个Erlang进程调度器对应一个操作系统线程,一般来说,有多少个CPU核就有多少个调度器。
RabbitMQ是基于Erlang语言实现的一个分布式消息中间件。下图是RabbitMQ基本的进程模型:
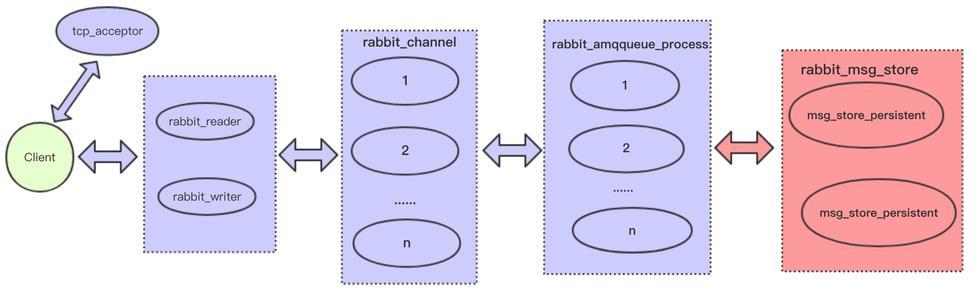
- tcp_acceptor:负责接受客户端连接,然后为客户端连接创建rabbit_reader、rabbit_writer、rabbit_channel进程
- rabbit_reader:负责解析客户端AMQP帧,然后将请求发送给rabbit_channel进程
- rabbit_writer:负责向客户端返回数据
- rabbit_channel:负责解析AMQP方法,以及对消息进行路由,然后发送给对应的队列进程。
- rabbit_amqqueue_process:rabbit队列进程,该进程一般在rabbitmq创建队列时被创建,其主要负责消息的接收/投递逻辑
- rabbit_msg_store:存储服务器进程,主要负责消息的持久化存储
上述进程中,tcp_acceptor和rabbit_msg_store只会有一个,rabbit_amqqueue_process进程的数量则和队列数量保持一致,每个客户端连接对应一个rabbit_reader和rabbit_writer进程,每一个连接的通道对应一个rabbit_channel进程。
通常来说,客户端发起一条连接的同时,可以打开多条channel,相对连接的open/close来说,对channel进行open和close的操作开销会更小。最佳实践是一个生产者/消费者进程对应一个connection,具体发送一个线程对应一个channel即可。
二、消息存在哪里
RabbitMQ的消息持久化实际包括两部分:队列索引(rabbit_queue_index)和消息存储(rabbit_msg_store)。rabbit_queue_index负责维护队列中落盘消息的信息,包括消息的存储地点、是否已经被交付给消费者、是否已被消费者ack等,每个队列都有一个与之对应的rabbit_queue_index。
rabbit_msg_store以键值对的形式存储消息,每个节点有且只有一个,所有队列共享。从技术层面讲rabbit_msg_store又可以分为msg_store_persistent和msg_store_transient,其中msg_store_persistent负责持久化消息的存储,不会丢失,而msg_store_transient负责非持久化消息的存储,重启后消息会丢失。
通过配置环境变量RABBITMQ_MNESIA_BASE可以指定存储目录,一般配置RABBITMQ_MNESIA_BASE=/srv/rabbitmq。
- $ cd /srv/rabbitmq/var/lib/rabbitmq/mnesia/rabbit@node1
- $ ls -l
- drwxr-xr-x 2 nqs nqs 12288 Jun 1 14:43 msg_store_persistent
- drwxr-xr-x 2 nqs nqs 4096 Jul 25 2016 msg_store_transient
- drwxr-xr-x 4 nqs nqs 4096 Jul 27 2016 queues
- ...
其中msg_store_transient、queues和msg_store_persistent就是实际消息的存储目录。
2.1 rabbit_msg_store存储
RabbitMQ通过配置queue_index_embed_msgs_below可以指定根据消息存储位置,默认queue_index_embed_msgs_below是4096字节(包含消息体、属性及headers),小于该值的消息存在rabbit_queue_index中。
- $ ls msg*
- msg_store_persistent:
- 82680.rdq 97666.rdq
- msg_store_transient:
- 0.rdq
经过rabbit_msg_store处理的消息都会以追加的方式写入到文件中,文件名从0开始累加,后缀是.rdq,当一个文件的大小超过指定的限制(file_size_limit)后,关闭这个文件再创建一个新的文件存储。 消息以以下格式存在于文件中:
- <<Size:64, MsgId:16/binary, MsgBody>>
MsgId为RabbitMQ通过rabbit_guid:gen()每一个消息生成的GUID,MsgBody会包含消息对应的exchange,routing_keys,消息的内容,消息对应的协议版本,消息内容格式。
在进行消息存储时,RabbitMQ会在ETS表中记录消息在文件中的位置映射和文件的相关信息。读取消息的时候先根据消息的msg_id找到对应的文件,如果文件存在且未被锁住则直接打开文件,如果文件不存在或者锁住了则发请求到rabbit_msg_store处理。
2.2 索引文件
查看索引信息
- $ cd queues/DMX3PGVA4ZG3HHCXA0ULNIM6P
- $ ls
- 70083.idx 70084.idx 88155.idx journal.jif
rabbit_queue_index顺序存储段文件,文件编号从0开始,后缀.idx,且每个段文件包含固定的SEGMENT_ENTRY_COUNT条记录。SEGMENT_ENTRY_COUNT默认是16384,每个rabbit_queue_index从磁盘读取消息的时候至少读取一个段文件。
2.3 过期消息删除
消息的删除只是从ETS表删除执行消息的相关信息,同时更新对应的存储文件的相关信息,并不立即对文件中的消息进程删除,后续会有专门的垃圾回收进程负责合并待回收消息文件。
当所有文件中的垃圾消息(已经被删除的消息)比例大于阈值(GARBAGE_FRACTION = 0.5)时,会触发文件合并操作(至少有三个文件存在的情况下),以提高磁盘利用率。
publish消息时写入内容,ack消息时删除内容(更新该文件的有用数据大小),当一个文件的有用数据等于0时,删除该文件。
三、消息存储过程源码分析
消息流转示意图:

rabbit_channel进程确定了消息将要投递的目标队列,rabbit_amqqueue_process是队列进程,每个队列都有一个对应的进程,实际上rabbit_amqqueue_process进程只是提供了逻辑上对队列的相关操作,他的真正操作是通过调用指定的backing_queue模块提供的相关接口实现的,默认情况该backing_queue的实现模块为rabbit_variable_queue。 RabbitMQ队列中的消息随着系统的负载会不断的变化,一个消息可能会处于以下4种状态:
- %% Definitions:
- %%
- %% alpha: this is a message where both the message itself, and its
- %% position within the queue are held in RAM(消息本身和消息位置索引都只在内存中)
- %%
- %% beta: this is a message where the message itself is only held on
- %% disk (if persisted to the message store) but its position
- %% within the queue is held in RAM.(消息本身存储在磁盘中,但是消息的位置索引存在内存中)
- %%
- %% gamma: this is a message where the message itself is only held on
- %% disk, but its position is both in RAM and on disk.(消息本身存储在磁盘中,但是消息的位置索引存在内存中和磁盘中)
- %%
- %% delta: this is a collection of messages, represented by a single
- %% term, where the messages and their position are only held on
- %% disk.(消息本身和消息的位置索引都值存储在磁盘中)
对于普通的没有设置优先级和镜像的队列来说,backing_queue的默认实现是rabbit_variable_queue,其内部通过5个子队列Q1、Q2、Delta、Q3和Q4来实现这4个状态的转换,其关系如下图所示:

其中Q1、Q4只包含alpha状态的消息,Q2和Q3包含Beta和gamma状态的消息,Delta只包含delta状态的消息。具体消息的状态转换后续会进行源码分析。
3.1 消息入队分析
rabbit_amqqueue_process对消息的主要处理逻辑位于deliver_or_enqueue函数,该方法将消息直接传递给消费者,或者将消息存储到队列当中。
整体处理逻辑如下:
- 首先处理消息的mandory标志,和confirm属性。mandatory标志告诉服务器至少将该消息route到一个队列中,否则将消息返还给生产者。confirm则是消息的发布确认。
- 然后判断队列中是否有消费者正在等待,如果有则直接调用backing_queue的接口给客户端发送消息。
- 如果队列上没有消费者,根据当前相关设置判断消息是否需要丢弃,不需要丢弃的情况下调用backing_queue的接口将消息入队。
deliver_or_enqueue函数代码:
- deliver_or_enqueue(Delivery = #delivery{message = Message,
- sender = SenderPid,
- flow = Flow},
- Delivered, State = #q{backing_queue = BQ,
- backing_queue_state = BQS}) ->
- %% 如果当前消息mandatory字段为true,则立刻通知该消息对应的rabbit_channel进程
- send_mandatory(Delivery), %% must do this before confirms
- %% 消息队列记录要confirm的消息,如果confirm为false,则不记录要confirm(如果消息需要进行confirm,则将该消息的信息存入msg_id_to_channel字段中)
- {Confirm, State1} = send_or_record_confirm(Delivery, State),
- %% 得到消息特性特性数据结构
- Props = message_properties(Message, Confirm, State1),
- %% 让backing_queue去判断当前消息是否重复(rabbit_variable_queue没有实现,直接返回的false)
- {IsDuplicate, BQS1} = BQ:is_duplicate(Message, BQS),
- State2 = State1#q{backing_queue_state = BQS1},
- case IsDuplicate orelse attempt_delivery(Delivery, Props, Delivered,
- State2) of
- true ->
- State2;
- %% 已经将消息发送给消费者的情况
- {delivered, State3} ->
- State3;
- %% The next one is an optimisation
- %% 没有消费者来取消息的情况(discard:抛弃)
- %% 当前消息没有发送到对应的消费者,同时当前队列中设置的消息过期时间为0,同时重新发送的exchange交换机为undefined,则立刻将该消息丢弃掉
- {undelivered, State3 = #q{ttl = 0, dlx = undefined,
- backing_queue_state = BQS2,
- msg_id_to_channel = MTC}} ->
- %% 直接将消息丢弃掉,如果需要confirm的消息则立刻通知rabbit_channel进程进行confirm操作
- {BQS3, MTC1} = discard(Delivery, BQ, BQS2, MTC),
- State3#q{backing_queue_state = BQS3, msg_id_to_channel = MTC1};
- %% 没有消费者来取消息的情况
- {undelivered, State3 = #q{backing_queue_state = BQS2}} ->
- %% 将消息发布到backing_queue中
- BQS3 = BQ:publish(Message, Props, Delivered, SenderPid, Flow, BQS2),
- %% 判断当前队列中的消息数量超过上限或者消息的占的空间大小超过上限
- {Dropped, State4 = #q{backing_queue_state = BQS4}} =
- maybe_drop_head(State3#q{backing_queue_state = BQS3}),
- %% 得到当前队列中的消息数量
- QLen = BQ:len(BQS4),
- %% optimisation: it would be perfectly safe to always
- %% invoke drop_expired_msgs here, but that is expensive so
- %% we only do that if a new message that might have an
- %% expiry ends up at the head of the queue. If the head
- %% remains unchanged, or if the newly published message
- %% has no expiry and becomes the head of the queue then
- %% the call is unnecessary.
- case {Dropped, QLen =:= 1, Props#message_properties.expiry} of
- %% 该情况是头部没有变化,同时消息队列消息树立不为一,则不管当前加入的消息是否设置有超时时间,都不执行drop_expired_msgs函数
- {false, false, _} -> State4;
- %% 有丢弃消息,同时当前队列中只有当前这个新的消息,同时消息自己的特性过期时间没有定义,则不检查消息过期
- %% 此时消息的头部有变化,但是消息队列中只有一个消息,该消息还没有设置超时时间,则不执行drop_expired_msgs函数
- {true, true, undefined} -> State4;
- %% 当向队列中插入消息后需要做检查消息过期,同时设置定时器的操作只有三种情况
- %% 1.当消息头部根据队列上限有变化,同时消息插入后当前队列消息数量为一,且该消息设置有过期时间,则需要做一次操作(该情况是消息头部有删除消息,都会进行一次消息过期检查)
- %% 2.当消息头部根据队列上限有变化,同时消息插入后当前队列消息数量不为一,且该消息设置有过期时间,则需要做一次操作(该情况是消息头部有删除消息,都会进行一次消息过期检查)
- %% 3.当消息头部根据队列上限没有变化,同时消息插入后当前队列消息数量为一,不管消息有没有过期时间,都要做一次操作(该情况下是当前队列进入第一条消息)
- %% 最重要的是只要消息队列的头部消息有变化,则立刻执行drop_expired_msgs函数,将队列头部超时的消息删除掉
- {_, _, _} -> drop_expired_msgs(State4)
- end
- end.
如果调用到该方法的BQ:publish则说明当前队列没有消费者正在等待,消息将进入到队列。backing_queue实现了消息的存储,他会尽力会durable=true的消息做持久化存储。初始默认情况下,非持久化消息直接进入内存队列,此时效率最高,当内存占用逐渐达到一个阈值时,消息和消息索引逐渐往磁盘中移动,随着消费者的不断消费,内存占用的减少,消息逐渐又从磁盘中被转到内存队列中。
消息在这些Queue中传递的"一般"过程q1->q2->delta->q3->q4,一般负载较轻的情况消息不需要走完每个Queue,大部分都可以跳过。rabbit_variable_queue中消息的入队接口源码如下:
- %% 消息的发布接口
- publish(Msg = #basic_message { is_persistent = IsPersistent, id = MsgId },
- MsgProps = #message_properties { needs_confirming = NeedsConfirming },
- IsDelivered, _ChPid, _Flow,
- State = #vqstate { q1 = Q1, q3 = Q3, q4 = Q4,
- next_seq_id = SeqId,
- in_counter = InCount,
- durable = IsDurable,
- unconfirmed = UC }) ->
- %% 只有持久化队列和消息持久化才会对消息进行持久化
- IsPersistent1 = IsDurable andalso IsPersistent,
- %% 组装消息状态(该数据结构是实际存储在队列中的数据)
- MsgStatus = msg_status(IsPersistent1, IsDelivered, SeqId, Msg, MsgProps),
- %% 如果队列和消息都是持久化类型,则将消息内容和消息在队列中的索引写入磁盘
- {MsgStatus1, State1} = maybe_write_to_disk(false, false, MsgStatus, State),
- %% 将消息状态数据结构存入内存(如果Q3队列不为空,则将新消息存入Q1队列,如果为空则将新消息存入Q4队列)
- State2 = case ?QUEUE:is_empty(Q3) of
- %% 如果Q3队列不为空,则将当前的消息写入Q1队列
- false -> State1 #vqstate { q1 = ?QUEUE:in(m(MsgStatus1), Q1) };
- %% 如果Q3队列为空,则将当前的消息写入Q4队列
- true -> State1 #vqstate { q4 = ?QUEUE:in(m(MsgStatus1), Q4) }
- end,
- %% 进入队列中的消息数量加一
- InCount1 = InCount + 1,
- %% 如果消息需要确认,将该消息加入unconfirmed字段
- UC1 = gb_sets_maybe_insert(NeedsConfirming, MsgId, UC),
- %% 更新队列进程中的状态信息
- State3 = stats({1, 0}, {none, MsgStatus1},
- %% 更新下一个消息在消息中的位置
- State2#vqstate{ next_seq_id = SeqId + 1,
- in_counter = InCount1,
- unconfirmed = UC1 }),
- %% RabbitMQ系统中使用的内存过多,此操作是将内存中的队列数据写入到磁盘中
- a(reduce_memory_use(maybe_update_rates(State3))).
消息入队时先判断Q3是否为空,如果Q3为空,则直接进入Q4,否则进入Q1,这里思考下为什么?
假如Q3为空,Delta一定为空,因为假如Delta不为空,那么Q3取出最后一个消息的时候Delta已经把消息转移到Q3了,这样Q3就不是空了,前后矛盾因此Delta一定是空的。同理可以推测出Q2、Q1都是空的,直接把消息放入Q4即可。
消息入队后,需要判断内存使用,调用reduce_memory_use函数:
- reduce_memory_use(State = #vqstate {
- ram_pending_ack = RPA,
- ram_msg_count = RamMsgCount,
- target_ram_count = TargetRamCount,
- rates = #rates { in = AvgIngress,
- out = AvgEgress,
- ack_in = AvgAckIngress,
- ack_out = AvgAckEgress } }) ->
- State1 = #vqstate { q2 = Q2, q3 = Q3 } =
- %% 得到当前在内存中的数量超过允许在内存中的最大数量的个数
- case chunk_size(RamMsgCount + gb_trees:size(RPA), TargetRamCount) of
- 0 -> State;
- %% Reduce memory of pending acks and alphas. The order is
- %% determined based on which is growing faster. Whichever
- %% comes second may very well get a quota of 0 if the
- %% first manages to push out the max number of messages.
- S1 -> Funs = case ((AvgAckIngress - AvgAckEgress) >
- (AvgIngress - AvgEgress)) of
- %% ack操作进入的流量大于消息进入的流量,则优先将等待ack的消息写入磁盘文件
- true -> [
- %% 限制内存中的等待ack的消息(将消息内容在内存中的等待ack的消息的消息内容写入磁盘文件)
- fun limit_ram_acks/2,
- %% 将Quota个alphas类型的消息转化为betas类型的消息(Q1和Q4队列都是alphas类型的消息)
- fun push_alphas_to_betas/2
- ];
- %% 消息进入的流量大于ack操作进入的消息流量,则优先将非等待ack的消息写入磁盘文件
- false -> [
- %% 将Quota个alphas类型的消息转化为betas类型的消息(Q1和Q4队列都是alphas类型的消息)
- fun push_alphas_to_betas/2,
- %% 限制内存中的等待ack的消息(将消息内容在内存中的等待ack的消息的消息内容写入磁盘文件)
- fun limit_ram_acks/2
- ]
- end,
- %% 真正执行转化的函数
- {_, State2} = lists:foldl(fun (ReduceFun, {QuotaN, StateN}) ->
- ReduceFun(QuotaN, StateN)
- end, {S1, State}, Funs),
- State2
- end,
- %% 当前beta类型的消息大于允许的beta消息的最大值,则将beta类型多余的消息转化为deltas类型的消息
- case chunk_size(?QUEUE:len(Q2) + ?QUEUE:len(Q3),
- permitted_beta_count(State1)) of
- S2 when S2 >= ?IO_BATCH_SIZE ->
- %% 将S2个betas类型的消息转化为deltas类型的消息
- push_betas_to_deltas(S2, State1);
- _ ->
- State1
- end.
- %% 将Quota个alphas类型的消息转化为betas类型的消息(Q1和Q4队列都是alphas类型的消息)
- push_alphas_to_betas(Quota, State) ->
- %% 将Q1队列中消息转化为betas类型的消息
- %% 如果磁盘中没有消息,则将Q1中的消息存储到Q3队列,如果磁盘中有消息则将Q3队列中的消息存储到Q2队列(将Q1队列头部的元素放入到Q2或者Q3队列的尾部)
- {Quota1, State1} =
- push_alphas_to_betas(
- fun ?QUEUE:out/1,
- fun (MsgStatus, Q1a,
- %% 如果delta类型的消息的个数为0,则将该消息存入存入Q3队列
- State0 = #vqstate { q3 = Q3, delta = #delta { count = 0 } }) ->
- State0 #vqstate { q1 = Q1a, q3 = ?QUEUE:in(MsgStatus, Q3) };
- %% 如果delta类型的消息个数不为0,则将该消息存入Q2队列
- (MsgStatus, Q1a, State0 = #vqstate { q2 = Q2 }) ->
- State0 #vqstate { q1 = Q1a, q2 = ?QUEUE:in(MsgStatus, Q2) }
- end,
- Quota, State #vqstate.q1, State),
- %% 将Q4队列中消息转化为betas类型的消息(Q4 -> Q3)(将Q4队列尾部的元素不断的放入到Q3队列的头部)
- {Quota2, State2} =
- push_alphas_to_betas(
- fun ?QUEUE:out_r/1,
- fun (MsgStatus, Q4a, State0 = #vqstate { q3 = Q3 }) ->
- State0 #vqstate { q3 = ?QUEUE:in_r(MsgStatus, Q3), q4 = Q4a }
- end,
- Quota1, State1 #vqstate.q4, State1),
- {Quota2, State2}.
- %% 限制内存中的等待ack的消息(将消息内容在内存中的等待ack的消息的消息内容写入磁盘文件)
- limit_ram_acks(0, State) ->
- {0, State};
- limit_ram_acks(Quota, State = #vqstate { ram_pending_ack = RPA,
- disk_pending_ack = DPA }) ->
- case gb_trees:is_empty(RPA) of
- true ->
- {Quota, State};
- false ->
- %% 拿到队列索引最大的消息
- {SeqId, MsgStatus, RPA1} = gb_trees:take_largest(RPA),
- %% 内存不足,强制性的将等待ack的SeqId消息内容写入磁盘
- {MsgStatus1, State1} =
- maybe_write_to_disk(true, false, MsgStatus, State),
- %% 如果成功的将消息写入磁盘,则将内存中的消息体字段清空
- MsgStatus2 = m(trim_msg_status(MsgStatus1)),
- %% 更新存储在磁盘中等待ack的消息字段disk_pending_ack,将刚才从存储在内存中等待ack的消息字段ram_pending_ack中的SeqId存储到disk_pending_ack字段中
- DPA1 = gb_trees:insert(SeqId, MsgStatus2, DPA),
- %% 更新队列状态,同时更新最新的ram_pending_ack和disk_pending_ack字段
- limit_ram_acks(Quota - 1,
- %% 主要是更新内存中保存的消息大小(ram_bytes减去当前写入磁盘的消息的大小)
- stats({0, 0}, {MsgStatus, MsgStatus2},
- State1 #vqstate { ram_pending_ack = RPA1,
- disk_pending_ack = DPA1 }))
- end.
每次入队消息后,判断RabbitMQ系统中使用的内存是否过多,此操作是尝试将内存中的队列数据写入到磁盘中.
内存中的消息数量(RamMsgCount)及内存中的等待ack的消息数量(RamAckIndex)的和大于允许的内存消息数量(TargetRamCount)时,多余数量的消息内容会被写到磁盘中.
3.2 消息出队源码分析
获取消息:
- 尝试从q4队列中获取一个消息,如果成功,则返回获取到的消息,如果失败,则尝试通过试用fetch_from_q3/1从q3队列获取消息,成功则返回,如果为空则返回空;
- 注意fetch_from_q3从Q3获取消息,如果Q3为空,则说明整个队列都是空的,无消息,消费者等待即可。
取出消息后:
- 如果Q4不为空,取出消息后直接返回;
- 如果Q4为空,Q3不为空,从Q3取出消息后,判断Q3是否为空,如果Q3为空,Delta不为空,则将Delta中的消息转移到Q3中,下次直接从Q3消费;
- 如果Q3和Delta都是空的,则可以任务Delta和Q2的消息都是空的,此时将Q1的消息转移到Q4,下次直接从Q4消费即可。
- %% 从队列中获取消息
- queue_out(State = #vqstate { q4 = Q4 }) ->
- %% 首先尝试从Q4队列中取得元素(Q4队列中的消息类型为alpha)
- case ?QUEUE:out(Q4) of
- {empty, _Q4} ->
- %% 如果Q4队列为空则从Q3队列中取得元素(如果Q3也为空,则直接返回空)
- case fetch_from_q3(State) of
- {empty, _State1} = Result -> Result;
- {loaded, {MsgStatus, State1}} -> {{value, MsgStatus}, State1}
- end;
- {{value, MsgStatus}, Q4a} ->
- {{value, MsgStatus}, State #vqstate { q4 = Q4a }}
- end.
- %% 从队列Q3中读取消息
- fetch_from_q3(State = #vqstate { q1 = Q1,
- q2 = Q2,
- delta = #delta { count = DeltaCount },
- q3 = Q3,
- q4 = Q4 }) ->
- %% 先从Q3队列中取元素(如果为空,则直接返回为空)
- case ?QUEUE:out(Q3) of
- {empty, _Q3} ->
- {empty, State};
- {{value, MsgStatus}, Q3a} ->
- State1 = State #vqstate { q3 = Q3a },
- State2 = case {?QUEUE:is_empty(Q3a), 0 == DeltaCount} of
- {true, true} ->
- %% 当这两个队列都为空时,可以确认q2也为空,也就是这时候,q2,q3,delta,q4都为空,那么,q1队列的消息可以直接转移到q4,下次获取消息时就可以直接从q4获取
- %% q3 is now empty, it wasn't before;
- %% delta is still empty. So q2 must be
- %% empty, and we know q4 is empty
- %% otherwise we wouldn't be loading from
- %% q3. As such, we can just set q4 to Q1.
- %% 当Q3队列为空,且磁盘中的消息数量为空,则断言Q2队列为空
- true = ?QUEUE:is_empty(Q2), %% ASSERTION
- %% 当Q3队列为空,且磁盘中的消息数量为空,则断言Q4队列为空
- true = ?QUEUE:is_empty(Q4), %% ASSERTION
- %% 从Q3队列中取走消息后发现Q3队列为空,同时磁盘中没有消息,则将Q1队列中的消息放入Q4队列
- State1 #vqstate { q1 = ?QUEUE:new(), q4 = Q1 };
- {true, false} ->
- %% 从Q3队列中取走消息后发现Q3队列为空,q3空,delta非空,这时候就需要从delta队列(内容与索引都在磁盘上,通过maybe_deltas_to_betas/1调用)读取消息,并转移到q3队列
- maybe_deltas_to_betas(State1);
- {false, _} ->
- %% q3非空,直接返回,下次获取消息还可以从q3获取
- %% q3 still isn't empty, we've not
- %% touched delta, so the invariants
- %% between q1, q2, delta and q3 are
- %% maintained
- State1
- end,
- {loaded, {MsgStatus, State2}}
- end.
- 转移Delta消息到Q3源码分析:
- %% 从磁盘中读取队列数据到内存中来(从队列消息中最小索引ID读取出一个索引磁盘文件大小的消息索引信息)
- %% 从队列索引的磁盘文件将单个磁盘文件中的消息索引读取出来
- %% 该操作是将单个队列索引磁盘文件中的deltas类型消息转换为beta类型的消息
- maybe_deltas_to_betas(State = #vqstate {
- q2 = Q2,
- delta = Delta,
- q3 = Q3,
- index_state = IndexState,
- ram_msg_count = RamMsgCount,
- ram_bytes = RamBytes,
- ram_pending_ack = RPA,
- disk_pending_ack = DPA,
- qi_pending_ack = QPA,
- disk_read_count = DiskReadCount,
- transient_threshold = TransientThreshold }) ->
- #delta { start_seq_id = DeltaSeqId,
- count = DeltaCount,
- end_seq_id = DeltaSeqIdEnd } = Delta,
- %% 根据delta中的开始DeltaSeqId得到存在索引磁盘的最小的磁盘索引号
- DeltaSeqId1 =
- lists:min([rabbit_queue_index:next_segment_boundary(DeltaSeqId),
- DeltaSeqIdEnd]),
- %% 从队列索引中读取消息索引(从队列索引的磁盘文件将单个磁盘文件中的消息索引读取出来)
- {List, IndexState1} = rabbit_queue_index:read(DeltaSeqId, DeltaSeqId1,
- IndexState),
- %% 过滤掉从rabbit_queue_index中读取过来的消息队列索引(如果该消息不是持久化的则需要删除掉),最后得到当前内存中准备好的消息个数以及内存中的消息的总的大小
- {Q3a, RamCountsInc, RamBytesInc, IndexState2} =
- %% RabbitMQ系统关闭以前非持久化消息存储到磁盘中的索引信息再从磁盘读取出来的时候必须将他们彻底从RabbitMQ系统中删除
- betas_from_index_entries(List, TransientThreshold,
- RPA, DPA, QPA, IndexState1),
- %% 更新队列消息索引结构,内存中队列中的消息个数,队列内存中消息占的大小,以及从磁盘文件读取的次数
- State1 = State #vqstate { index_state = IndexState2,
- ram_msg_count = RamMsgCount + RamCountsInc,
- ram_bytes = RamBytes + RamBytesInc,
- disk_read_count = DiskReadCount + RamCountsInc},
- case ?QUEUE:len(Q3a) of
- 0 ->
- %% we ignored every message in the segment due to it being
- %% transient and below the threshold
- %% 如果读取的当前消息队列索引磁盘文件中的操作项为空,则继续读下一个消息索引磁盘文件中的操作项
- maybe_deltas_to_betas(
- State1 #vqstate {
- delta = d(Delta #delta { start_seq_id = DeltaSeqId1 })});
- Q3aLen ->
- %% 将从索引中读取出来的消息索引存储到Q3队列(将新从磁盘中读取的消息队列添加到老的Q3队列的后面)
- Q3b = ?QUEUE:join(Q3, Q3a),
- case DeltaCount - Q3aLen of
- 0 ->
- %% 如果读取出来的长度和队列索引的总长度相等,则delta信息被重置为消息个数为0,同时q2中的消息转移到q3队列
- %% delta is now empty, but it wasn't before, so
- %% can now join q2 onto q3
- State1 #vqstate { q2 = ?QUEUE:new(),
- delta = ?BLANK_DELTA,
- %% 如果磁盘中已经没有消息,则将Q2队列中的消息放入Q3队列
- q3 = ?QUEUE:join(Q3b, Q2) };
- N when N > 0 ->
- %% 得到最新的队列消息磁盘中的信息
- Delta1 = d(#delta { start_seq_id = DeltaSeqId1,
- count = N,
- end_seq_id = DeltaSeqIdEnd }),
- %% 更新最新的q3队列和磁盘信息结构
- State1 #vqstate { delta = Delta1,
- q3 = Q3b }
- end
- end.
问题1:为什么Q4,Q3空,队列就为空?
消费Q3最后一条消息的时候,会调用函数maybe_deltas_to_betas,将磁盘上Delta状态的消息转移到Q3,现在Q3是空的,那么Delta状态的消息一定是空的,否则消息会转移到Q3;
Delta消息是空的,上述代码中:
- State1 #vqstate { q2 = ?QUEUE:new(),
- delta = ?BLANK_DELTA,
- %% 如果磁盘中已经没有消息,则将Q2队列中的消息放入Q3队列
- q3 = ?QUEUE:join(Q3b, Q2) };
会将Q2队列的消息转移到Q3,现在Q3是空的,那么Q2中消息肯定是空的;
现在Q2、Q3、Delta和Q4都是空的,看代码:
- State2 = case {?QUEUE:is_empty(Q3a), 0 == DeltaCount} of
- {true, true} ->
- true = ?QUEUE:is_empty(Q2),
- true = ?QUEUE:is_empty(Q4),
- %% 从Q3队列中取走消息后发现Q3队列为空,同时磁盘中没有消息,则将Q1队列中的消息放入Q4队列
- State1 #vqstate { q1 = ?QUEUE:new(), q4 = Q1 };
会将Q1消息转移到Q4,现在Q4是空的,Q1肯定没有消息了。
综上所述,Q3和Q4都是空的,那该队列无消息!
问题2:为什么q4,q3,delta为空的时候,q2必空?
在问题1中已经分析了,Delta消息为空的时候会将Q2放入Q3中,现在Q3是空的,可以反向推出Q2肯定是空的。
问题3:为什么Q4、Q3和delta为空的时候,q1不为空会直接转移到q4?
根据定义Q1和Q4存储的消息是处于内存中的alpha状态的消息,这时候直接从Q1转到Q4就不需要经过磁盘,减少IO延迟;
rabbit_variable_queue.erl源码关于转换状态还有很多细节,这里不再介绍。后续深入学习源码后再分析。
四、总结
节点消息堆积较多时,这些堆积的消息很快就会进入很深的队列中去,这样会增加处理每个消息的平均开销,整个系统的处理能力就会降低。因为要花更多的时间和资源处理堆积的消息,后流入的消息又被挤压到很深的队列中了,系统负载越来越恶化。
因此RabbitMQ使用时一定要注意磁盘占用监控和流控监控,这些在控制台上都可以看到,一般来说如果消息堆积过多建议增加消费者或者增强每个消费者的消费能力(比如调高prefetch_count消费者一次收到的消息可以提高单个消费者消费能力)。
参考文章:
RabbitMQ源码分析 - 队列机制
本文已由作者李海燕授权网易云社区发布。
【RabbitMQ学习记录】- 消息队列存储机制源码分析的更多相关文章
- 消息队列中间件 RocketMQ 源码分析 —— Message 存储
- 阿里消息队列中间件 RocketMQ 源码分析 —— Message 拉取与消费(上)
- memcached学习笔记——存储命令源码分析上篇
原创文章,转载请标明,谢谢. 上一篇分析过memcached的连接模型,了解memcached是如何高效处理客户端连接,这一篇分析memcached源码中的process_update_command ...
- memcached学习笔记——存储命令源码分析下篇
上一篇回顾:<memcached学习笔记——存储命令源码分析上篇>通过分析memcached的存储命令源码的过程,了解了memcached如何解析文本命令和mencached的内存管理机制 ...
- Springboot学习04-默认错误页面加载机制源码分析
Springboot学习04-默认错误页面加载机制源码分析 前沿 希望通过本文的学习,对错误页面的加载机制有这更神的理解 正文 1-Springboot错误页面展示 2-Springboot默认错误处 ...
- Android事件分发机制源码分析
Android事件分发机制源码分析 Android事件分发机制源码分析 Part1事件来源以及传递顺序 Activity分发事件源码 PhoneWindow分发事件源码 小结 Part2ViewGro ...
- ApplicationEvent事件机制源码分析
<spring扩展点之三:Spring 的监听事件 ApplicationListener 和 ApplicationEvent 用法,在spring启动后做些事情> <服务网关zu ...
- 延迟队列DelayQueue take() 源码分析
延迟队列DelayQueue take() 源码分析 在工作中使用了延迟队列,对其内部的实现很好奇,于是就研究了一下其运行原理,在这里就介绍一下take()方法的源码 1 take()源码 如下所示 ...
- Spring Cloud 学习 之 Spring Cloud Eureka(源码分析)
Spring Cloud 学习 之 Spring Cloud Eureka(源码分析) Spring Boot版本:2.1.4.RELEASE Spring Cloud版本:Greenwich.SR1 ...
随机推荐
- nginx实现多个域名共享80端口
server { listen 80; server_name server8085.duchong.cn; location / { proxy_pass http://127.0.0.1:8085 ...
- shell编程——变量子串的常用操作
${#字符串} 返回字符串的长度 [root@localhost ~]# a=length [root@localhost ~]# echo ${#a} 6 ${字符串:位置x} 从位置x开始往后截取 ...
- C# 调用动态代码
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- Visual Studio Find All no results.
重装WDK什么的有时候有bug....写下面注册表修复 Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\Wow6432Node\CLSI ...
- GetHashCode()
[GetHashCode] GetHashCode 方法的默认实现不保证针对不同的对象返回唯一值.而且,.NET Framework 不保证 GetHashCode 方法的默认实现以及它所返回的值在不 ...
- ElasticSearch的java api
pom <dependencies> <dependency> <groupId>org.elasticsearch.client</groupId> ...
- [bzoj2212]Tree Rotations(线段树合并)
解题关键:线段树合并模板题.线段树合并的题目一般都是权值线段树,因为结构相同,求逆序对时,遍历权值线段树的过程就是遍历所有mid的过程,所有能求出所有逆序对. #include<iostream ...
- zabbix自动发现监控mysql
一. 数据库给只读权限 1.1 grant usage on *.* to 'zabbix'@'127.0.0.1' identified by 'zabbix'; flush privileges; ...
- 安装运行okvis odometry
源码链接https://github.com/ethz-asl/okvis 1. 安装依赖项 sudo apt-get install cmake sudo apt-get install libgo ...
- [C++] Vtable(虚函数表)
Vtable(虚函数表)