Deep Learning深入浅出
链接:https://www.zhihu.com/question/26006703/answer/129209540
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
关于深度学习,网上的资料很多,不过貌似大部分都不太适合初学者。 这里有几个原因:1.深度学习确实需要一定的数学基础。如果不用深入浅出地方法讲,有些读者就会有畏难的情绪,因而容易过早地放弃。2.中国人或美国人写的书籍或文章,普遍比较难一些。我不太清楚为什么,不过确实是这样子的。
深度学习,确实需要一定的数学基础,但真的那么难么?这个,还真没有。不信?听我来给你侃侃。看完,你也会觉得没那么难了。
本文是针对初学者,高手可以无视,有不对的地方,还请多多批评指正。
这里,先推荐一篇非常不错的文章:《1天搞懂深度学习》,300多页的ppt,台湾李宏毅教授写的,非常棒。不夸张地说,是我看过最系统,也最通俗易懂的,关于深度学习的文章。
这是slideshare的链接:http://www.slideshare.net/tw_dsconf/ss-62245351?qid=108adce3-2c3d-4758-a830-95d0a57e46bc&v=&b=&from_search=3
没梯子的同学,可以从我的网盘下:链接:http://pan.baidu.com/s/1nv54p9R 密码:3mty
要说先准备什么,私以为,其实只需要知道导数和相关的函数概念就可以了。高等数学也没学过?很好,我就是想让文科生也能看懂,您只需要学过初中数学就可以了。
其实不必有畏难的情绪,个人很推崇李书福的精神,在一次电视采访中,李书福说:谁说中国人不能造汽车?造汽车有啥难的,不就是四个轮子加两排沙发嘛。当然,他这个结论有失偏颇,不过精神可嘉。
导数是什么,无非就是变化率呗,王小二今年卖了100头猪,去年卖了90头,前年卖了80头。。。变化率或者增长率是什么?每年增长10头猪,多简单。这里需要注意有个时间变量---年。王小二卖猪的增长率是10头/年,也就是说,导数是10.函数y=f(x)=10x+30,这里我们假设王小二第一年卖了30头,以后每年增长10头,x代表时间(年),y代表猪的头数。当然,这是增长率固定的情形,现实生活中,很多时候,变化量也不是固定的,也就是说增长率也不是恒定的。比如,函数可能是这样: y=f(x)=5x²+30,这里x和y依然代表的是时间和头数,不过增长率变了,怎么算这个增长率,我们回头再讲。或者你干脆记住几个求导的公式也可以。
深度学习还有一个重要的数学概念:偏导数,偏导数的偏怎么理解?偏头疼的偏,还是我不让你导,你偏要导?都不是,我们还以王小二卖猪为例,刚才我们讲到,x变量是时间(年),可是卖出去的猪,不光跟时间有关啊,随着业务的增长,王小二不仅扩大了养猪场,还雇了很多员工一起养猪。所以方程式又变了:y=f(x)=5x₁²+8x₂ + 35x₃ +30这里x₂代表面积,x₃代表员工数,当然x₁还是时间。上面我们讲了,导数其实就是变化率,那么偏导数是什么?偏导数无非就是多个变量的时候,针对某个变量的变化率呗。在上面的公式里,如果针对x₃求偏导数,也就是说,员工对于猪的增长率贡献有多大,或者说,随着(每个)员工的增长,猪增加了多少,这里等于35---每增加一个员工,就多卖出去35头猪. 计算偏导数的时候,其他变量都可以看成常量,这点很重要,常量的变化率为0,所以导数为0,所以就剩对35x₃ 求导数,等于35. 对于x₂求偏导,也是类似的。求偏导我们用一个符号 表示:比如 y/ x₃ 就表示y对 x₃求偏导。
废话半天,这些跟深度学习到底有啥关系?有关系,我们知道,深度学习是采用神经网络,用于解决线性不可分的问题。关于这一点,我们回头再讨论,大家也可以网上搜一下相关的文章。我这里主要讲讲数学与深度学习的关系。先给大家看几张图:
<img src="https://pic3.zhimg.com/v2-91704850c698cbe0cdfd0af76d328ebe_b.png" data-rawwidth="631" data-rawheight="488" class="origin_image zh-lightbox-thumb" width="631" data-original="https://pic3.zhimg.com/v2-91704850c698cbe0cdfd0af76d328ebe_r.png">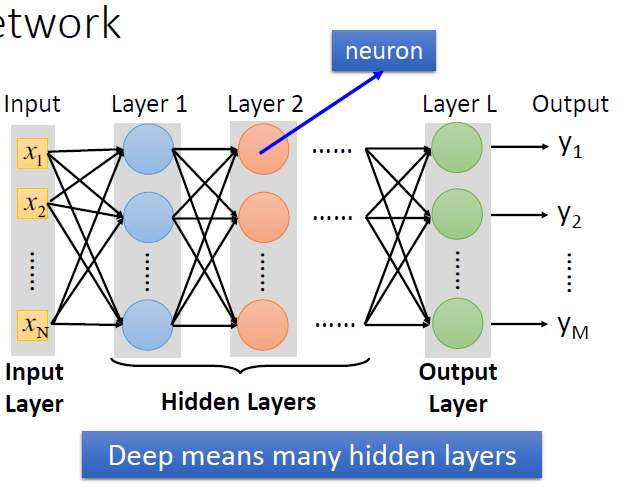
图1. 所谓深度学习,就是具有很多个隐层的神经网络。
<img src="https://pic4.zhimg.com/v2-7875411304340d5accd6d800be9f933b_b.jpg" data-rawwidth="432" data-rawheight="576" class="origin_image zh-lightbox-thumb" width="432" data-original="https://pic4.zhimg.com/v2-7875411304340d5accd6d800be9f933b_r.jpg">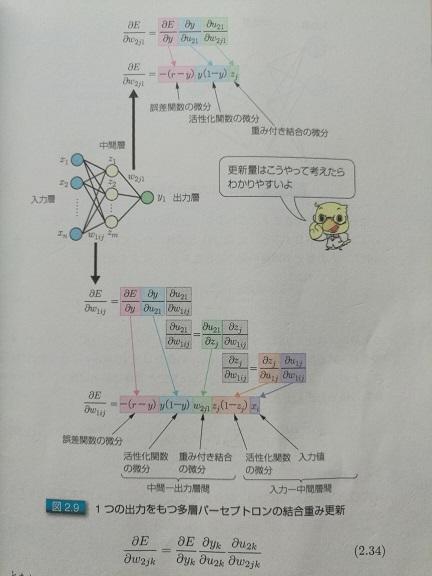
图2.单输出的时候,怎么求偏导数
<img src="https://pic2.zhimg.com/v2-c52b1fcdd42c3ac413120b56e40a8619_b.jpg" data-rawwidth="432" data-rawheight="576" class="origin_image zh-lightbox-thumb" width="432" data-original="https://pic2.zhimg.com/v2-c52b1fcdd42c3ac413120b56e40a8619_r.jpg">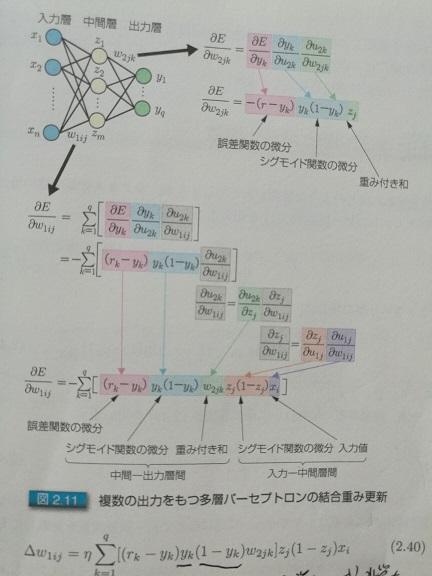
图3.多输出的时候,怎么求偏导数。后面两张图是日语的,这是日本人写的关于深度学习的书。感觉写的不错,把图盗来用一下。所谓入力层,出力层,中间层,分别对应于中文的:输入层,输出层,和隐层。
大家不要被这几张图吓着,其实很简单的。干脆再举一个例子,就以撩妹为例。男女恋爱我们大致可以分为三个阶段:1.初恋期。相当于深度学习的输入层。别人吸引你,肯定是有很多因素,比如:身高,身材,脸蛋,学历,性格等等,这些都是输入层的参数,对每个人来说权重可能都不一样。2.热恋期。我们就让它对应于隐层吧。这个期间,双方各种磨合,柴米油盐酱醋茶。3.稳定期。对应于输出层,是否合适,就看磨合得咋样了。
大家都知道,磨合很重要,怎么磨合呢?就是不断学习训练和修正的过程嘛!比如女朋友喜欢草莓蛋糕,你买了蓝莓的,她的反馈是negative,你下次就别买了蓝莓,改草莓了。------------------------------------------------------------------------------------------------看完这个,有些小伙可能要开始对自己女友调参了。有点不放心,所以补充一下。撩妹和深度学习一样,既要防止欠拟合,也要防止过拟合。所谓欠拟合,对深度学习而言,就是训练得不够,数据不足,就好比,你撩妹经验不足,需要多学着点,送花当然是最基本的了,还需要提高其他方面,比如,提高自身说话的幽默感等,因为本文重点并不是撩妹,所以就不展开讲了。这里需要提一点,欠拟合固然不好,但过拟合就更不合适了。过拟合跟欠拟合相反,一方面,如果过拟合,她会觉得你有陈冠希老师的潜质,更重要的是,每个人情况不一样,就像深度学习一样,训练集效果很好,但测试集不行!就撩妹而言,她会觉得你受前任(训练集)影响很大,这是大忌!如果给她这个映象,你以后有的烦了,切记切记!------------------------------------------------------------------------------------------------
深度学习也是一个不断磨合的过程,刚开始定义一个标准参数(这些是经验值。就好比情人节和生日必须送花一样),然后不断地修正,得出图1每个节点间的权重。为什么要这样磨合?试想一下,我们假设深度学习是一个小孩,我们怎么教他看图识字?肯定得先把图片给他看,并且告诉他正确的答案,需要很多图片,不断地教他,训练他,这个训练的过程,其实就类似于求解神经网络权重的过程。以后测试的时候,你只要给他图片,他就知道图里面有什么了。
所以训练集,其实就是给小孩看的,带有正确答案的图片,对于深度学习而言,训练集就是用来求解神经网络的权重的,最后形成模型;而测试集,就是用来验证模型的准确度的。
对于已经训练好的模型,如下图所示,权重(w1,w2...)都已知。
<img src="https://pic1.zhimg.com/v2-8521e1fa289e08dbbab5aa63b6527bd4_b.png" data-rawwidth="940" data-rawheight="736" class="origin_image zh-lightbox-thumb" width="940" data-original="https://pic1.zhimg.com/v2-8521e1fa289e08dbbab5aa63b6527bd4_r.png">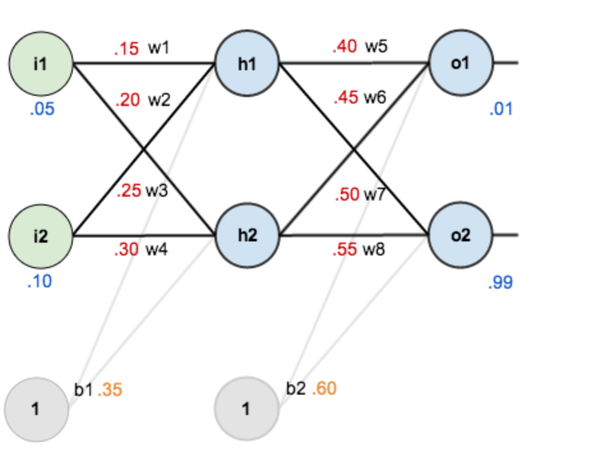
图4
<img src="https://pic4.zhimg.com/v2-ef5ad0d06a316f762f0625b2468e2f43_b.png" data-rawwidth="776" data-rawheight="174" class="origin_image zh-lightbox-thumb" width="776" data-original="https://pic4.zhimg.com/v2-ef5ad0d06a316f762f0625b2468e2f43_r.png">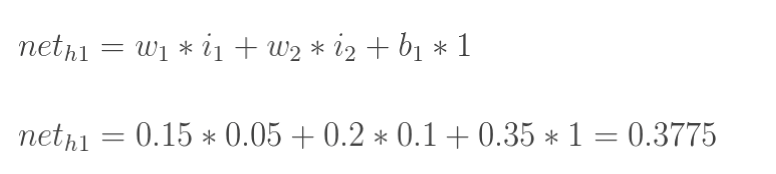
图5
我们知道,像上面这样,从左至右容易算出来。但反过来呢,我们上面讲到,测试集有图片,也有预期的正确答案,要反过来求w1,w2......,怎么办?
绕了半天,终于该求偏导出场了。目前的情况是:
1.我们假定一个神经网络已经定义好,比如有多少层,都什么类型,每层有多少个节点,激活函数(后面讲)用什么等。这个没办法,刚开始得有一个初始设置(大部分框架都需要define-and-run,也有部分是define-by-run)。你喜欢一个美女,她也不是刚从娘胎里出来的,也是带有各种默认设置的。至于怎么调教,那就得求偏导。
2.我们已知正确答案,比如图2和3里的r,训练的时候,是从左至右计算,得出的结果为y,r与y一般来说是不一样的。那么他们之间的差距,就是图2和3里的E。这个差距怎么算?当然,直接相减是一个办法,尤其是对于只有一个输出的情况,比如图2; 但很多时候,其实像图3里的那样,那么这个差距,一般可以这样算,当然,还可以有其他的评估办法,只是函数不同而已,作用是类似的:
<img src="https://pic4.zhimg.com/v2-e5ddd26d65aa04ed82f2a51fc8212427_b.png" data-rawwidth="484" data-rawheight="102" class="origin_image zh-lightbox-thumb" width="484" data-original="https://pic4.zhimg.com/v2-e5ddd26d65aa04ed82f2a51fc8212427_r.png">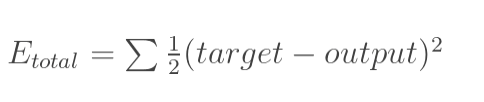
不得不说,理想跟现实还是有差距的,我们当然是希望差距越小越好,怎么才能让差距越来越小呢?得调整参数呗,因为输入(图像)确定的情况下,只有调整参数才能改变输出的值。怎么调整,怎么磨合?刚才我们讲到,每个参数都有一个默认值,我们就对每个参数加上一定的数值∆,然后看看结果如何?如果参数调大,差距也变大,你懂的,那就得减小∆,因为我们的目标是要让差距变小;反之亦然。所以为了把参数调整到最佳,我们需要了解误差对每个参数的变化率,这不就是求误差对于该参数的偏导数嘛。
关键是怎么求偏导。图2和图3分别给了推导的方法,其实很简单,从右至左挨个求偏导就可以。相邻层的求偏导其实很简单,因为是线性的,所以偏导数其实就是参数本身嘛,就跟求解x₃的偏导类似。然后把各个偏导相乘就可以了。
这里有两个点:
这里有两个点:一个是激活函数,这主要是为了让整个网络具有非线性特征,因为我们前面也提到了,很多情况下,线性函数没办法对输入进行适当的分类(很多情况下识别主要是做分类),那么就要让网络学出来一个非线性函数,这里就需要激活函数,因为它本身就是非线性的,所以让整个网络也具有非线性特征。另外,激活函数也让每个节点的输出值在一个可控的范围内,这样计算也方便。
貌似这样解释还是很不通俗,其实还可以用撩妹来打比方;女生都不喜欢白开水一样的日子,因为这是线性的,生活中当然需要一些浪漫情怀了,这个激活函数嘛,我感觉类似于生活中的小浪漫,小惊喜,是不是?相处的每个阶段,需要时不时激活一下,制造点小浪漫,小惊喜,比如;一般女生见了可爱的小杯子,瓷器之类都迈不开步子,那就在她生日的时候送一个特别样式,要让她感动得想哭。前面讲到男人要幽默,这是为了让她笑;适当的时候还要让她激动得哭。一哭一笑,多整几个回合,她就离不开你了。因为你的非线性特征太强了。
当然,过犹不及,小惊喜也不是越多越好,但完全没有就成白开水了。就好比每个layer都可以加激活函数,当然,不见得每层都要加激活函数,但完全没有,那是不行的。
由于激活函数的存在,所以在求偏导的时候,也要把它算进去,激活函数,一般用sigmoid,也可以用Relu等。激活函数的求导其实也非常简单:
<img src="https://pic2.zhimg.com/v2-a9311523c35a3558844d1edc22cee9ed_b.jpg" data-rawwidth="257" data-rawheight="159" class="content_image" width="257">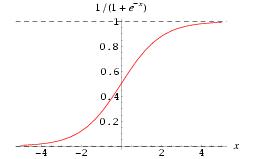
求导: f'(x)=f(x)*[1-f(x)]这个方面,有时间可以翻看一下高数,没时间,直接记住就行了。至于Relu,那就更简单了,就是f(x) 当x<0的时候y等于0,其他时候,y等于x。当然,你也可以定义你自己的Relu函数,比如x大于等于0的时候,y等于0.01x,也可以。
另一个是学习系数,为什么叫学习系数?刚才我们上面讲到∆增量,到底每次增加多少合适?是不是等同于偏导数(变化率)?经验告诉我们,需要乘以一个百分比,这个就是学习系数,而且,随着训练的深入,这个系数是可以变的。
当然,还有一些很重要的基本知识,比如SGD(随机梯度下降),mini batch 和 epoch(用于训练集的选择),限于篇幅,以后再侃吧。其实参考李宏毅的那篇文章就可以了。
这篇拙文,算是对我另一个回答的补充吧:深度学习入门必看的书和论文?有哪些必备的技能需学习? - jacky yang 的回答
其实上面描述的,主要是关于怎么调整参数,属于初级阶段。上面其实也提到,在调参之前,都有默认的网络模型和参数,如何定义最初始的模型和参数?就需要进一步深入了解。不过对于一般做工程而言,只需要在默认的网络上调参就可以了,相当于用算法;对于学者和科学家而言,他们会发明算法,难度还是不小的。向他们致敬!
写得很辛苦,觉得好就给我点个赞吧:)
------------------------------------------------------------------------------------------------
关于求偏导的推导过程,我尽快抽时间,把数学公式用通俗易懂的语言详细描述一下,前一段时间比较忙,抱歉:)
------------------------------------------------------------------------------------------------
Deep Learning深入浅出的更多相关文章
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- 学习Data Science/Deep Learning的一些材料
原文发布于我的微信公众号: GeekArtT. 从CFA到如今的Data Science/Deep Learning的学习已经有一年的时间了.期间经历了自我的兴趣.擅长事务的探索和试验,有放弃了的项目 ...
- deep learning新征程
deep learning新征程(一) zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2015-11-26 声明: 1 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- Deep Learning 经典网路回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
#Deep Learning回顾#之LeNet.AlexNet.GoogLeNet.VGG.ResNet 深入浅出——网络模型中Inception的作用与结构全解析 图像识别中的深度残差学习(Deep ...
- Deep Learning 教程翻译
Deep Learning 教程翻译 非常激动地宣告,Stanford 教授 Andrew Ng 的 Deep Learning 教程,于今日,2013年4月8日,全部翻译成中文.这是中国屌丝军团,从 ...
- [置顶]
Deep Learning 资料库
一.文章来由 网络好文章太多,而通过转载文章做资料库太麻烦,直接更新这个博文. 二.汇总 1.台大李宏毅老师的课 正片:http://speech.ee.ntu.edu.tw/~tlkagk/cour ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
随机推荐
- Spring笔记(二)
1. SPRING aop入门 Aop 面向切面编程 在一个大型的系统中,会写很多的业务类--业务方法 同时,一个大型的系统中,还有很多公共的功能:比如事务管理.日志处理.缓存处理..... 1.1 ...
- 关于JavaScript对象中的一切(二) -- 继承
先上一张我制作的思维导图.
- Commons之Commons-io
转载自(https://my.oschina.net/u/2000201/blog/480071) 1 概述 Commons IO是针对开发IO流功能的工具类库. 主要包括六个区域: 工具类——使用 ...
- Azure Active Directory配置java应用的单点登录
下载应用:https://github.com/Azure-Samples/active-directory-java-webapp-openidconnect(普通项目,集成了特殊配置接入微软的注册 ...
- Hive中的数据倾斜
Hive中的数据倾斜 hive 1. 什么是数据倾斜 mapreduce中,相同key的value都给一个reduce,如果个别key的数据过多,而其他key的较少,就会出现数据倾斜.通俗的说,就是我 ...
- webservice的cxf和spring整合客户端开发
1.新建一个java项目 2.导入cxf相关的jar包,并部署到项目中 3.用命令生成客户端使用说明文档 wsdl2java -p com.xiaostudy -d . http://127.0.0. ...
- mysql_fetch_assoc查询多行数据
每次从查询结果中返回一行数据,作为关联数组,类似于一个游标,第一次是返回第一行,第二次迭代就是第二行,以此类推 如果返回多行,使用如下方法就可以了 while($row = $db->fetch ...
- CDN方式使用iview
如果没有使用webpack,可以使用我们提供的工具iview-theme来编译 首先需要安装主体生成工具,从npm全局活在项目中局部安装 以全局安装为例: npm install iview-them ...
- 关于IIS权限问题(Selenium WebDriver调用出错记录)
本地VS调试过程中用Selenium WebDriver打开FF浏览器可以正常工作,项目部署至IIS后请求调用浏览器一直提示超时,异常如下: 因为本地调试可以成功,首先排除组件版本问题和浏览器兼容问题 ...
- python调用虹软2.0(全网首发)-更新中
python调用虹软2.0目前没有任何demo可以参考,自己研究了2个晚上终于把第一步做出来了,使用了opencv来加载和显示图片,龟速更新中 这一版作废,新版已发出:https://www.cnbl ...