POC索引
最近在看窗口函数,接触到了POC索引,所以借此机会好好研究一下索引。
一般支持窗口函数的索引指南都遵循POC的概念,也就是Partitioning(分区)、Ordering(排序)和Covering(覆盖)的简称,有时也称为POCo。POC索引的键应该是窗口分区列紧接着窗口的排序,索引还应包含查询引用的页级中的其余列。索引的包含列要么通过非聚集索引的显式INCLUDE子句来实现或聚集索引方式实现——这种情况下,他需要包含叶级中的所有列。
select actid,tranid,val
row_number() over(partition by actid order by val) as rownum
from Transactions
create index idx_actid_val_i_tranid
on Transactions(actid /* P */,val /* O */)
include(tranid /* C */)
先来了解几个基本概念
【覆盖查询】当索引包含查询引用的所有列时,它通常称为“覆盖查询”。
【索引覆盖】如果返回的数据列就包含于索引的键值中,或者包含于索引的键值+聚集索引的键值中,那么就不会发生Bookup Lookup,因为找到索引项,就已经找到所需的数据了,没有必要再到数据行去找了。这种情况,叫做索引覆盖;
【复合索引】和复合索引相对的就是单一索引了,就是索引只包含一个字段,所以复合索引就是包含两个或者多个字段的索引;
【非键列】键列就是在索引中所包含的列,当然非键列就是该索引之外的列了;
【摘要1】

* 它们可以是不允许作为索引键列的数据类型。
* 在计算索引键列数或索引键大小时,数据库引擎不考虑它们。
当查询中的所有列都作为键列或非键列包含在索引中时,带有包含性非键列的索引可以显著提高查询性能。这样可以实现性能提升,因为查询优化器可以在索引中找到所有列值;不访问表或聚集索引数据,从而减少磁盘 I/O 操作。
说明:第一:只能是针对非聚集索引;第二:比起复合索引是有性能上的提升的,因为索引的大小变小了;
【摘要2】
说明:这就表现为包含与不包含的关系了。有关索引级别的详细信息,请参阅表组织和索引组织。
【摘要3】
可以将非键列包含在非聚集索引中,以避免超过当前索引大小的限制(最大键列数为 16,最大索引键大小为 900 字节)。数据库引擎计算索引键列数或索引键大小时,不考虑非键列。
例如,假设要为 AdventureWorks 示例数据库的 Document 表中的以下列建立索引:
Title nvarchar(50)
Revision nchar(5)
FileName nvarchar(400)
因为 nchar 和 nvarchar 数据类型的每个字符需要 2 个字节,所以包含这三列的索引将超出 900 字节的大小限制 10 个字节 (455 * 2)。使用 CREATE INDEX 语句的 INCLUDE 子句,可以将索引键定义为 (Title, Revision),将 FileName 定义为非键列。这样,索引键大小将为 110 个字节 (55 * 2),并且索引仍将包含所需的所有列。下面的语句就创建了这样的索引。
说明:当你把一个nvarchar(500)的字段设置为主键的时候,你就可以看到不能超出900字节的提示了。一般来说我们是不太会做这些操作的,所以那个错误提示也是不常见的,也许你可能还见过。
一个数据页的大小才8k,所以我们合理的设置每个字段的大小,不要浪费太多的空间,这样对查询也是有好处的,这个include就比较好的的解决了索引和空间的问题,虽然那些include的数据也会占用空间。
虽然可以设置include,但是也尽量不要使用太多的字段作为索引包含的非键列。
【摘要4】
设计带有包含性列的非聚集索引时,请考虑下列准则:
* 在 CREATE INDEX 语句的 INCLUDE 子句中定义非键列。
* 只能对表或索引视图的非聚集索引定义非键列。
* 除 text、ntext 和 image 之外,允许所有数据类型。
* 精确或不精确的确定性计算列都可以是包含性列。有关详细信息,请参阅为计算列创建索引。
* 与键列一样,只要允许将计算列数据类型作为非键索引列,从 image、ntext 和 text 数据类型派生的计算列就可以作为非键(包含性)列。
* 不能同时在 INCLUDE 列表和键列列表中指定列名。
* INCLUDE 列表中的列名不能重复。
说明:include不能使用在聚集索引中。后面的两点,这个在实际中很难想象会有这样的需求要把重复列放到一个索引中。如果有朋友遇到过这样的需求可以告知一些,不胜感激。那如果有是否可以通过不同的列名(其实保存是同样的值)来解决这个问题呢??
【摘要5】
* 必须至少定义一个键列。最大非键列数为 1023 列。也就是最大的表列数减 1。
* 索引键列(不包括非键)必须遵守现有索引大小的限制(最大键列数为 16,总索引键大小为 900 字节)。
* 所有非键列的总大小只受 INCLUDE 子句中所指定列的大小限制;例如,varchar(max) 列限制为 2 GB。
说明:varchar(max)这样的定义是在2005之后才有的,所以这些数值也是对2005后的版本才生效的。
最大的表列数为:1024
最大非键列数为:1023
【摘要6】
* 除非先删除索引,否则无法从表中删除非键列。
* 除进行下列更改外,不能对非键列进行其他更改:
o 将列的为空性从 NOT NULL 改为 NULL。
o 增加 varchar、nvarchar 或 varbinary 列的长度。
* 这些列修改限制也适用于索引键列。
说明:这些细小的东西一直没有注意过。所以要记录下来,用来“防身”,呵呵。
【摘要7】
重新设计索引键大小较大的非聚集索引,以便只有用于搜索和查找的列为键列。将覆盖查询的所有其他列设置为包含性非键列。这样,将具有覆盖查询所需的所有列,但索引键本身较小,而且效率高。
说明:也就是说把常用的where后面的条件查询的字段作为索引的键列,而需要返回的字段就作为索引包含的非键列。
如果where的是两个或两个以上的谓词的话,这个索引就可以创建为复合索引了。以前天真的认为要返回的字段只能通过在复合索引中入这些字段,不管它是否会用来做谓词。看到这篇文章,才有了豁然开朗的感觉。
【摘要8】
GO
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
说明:这个是使用include的语法,在表的设计中的索引设计中是没有办法选择的;
【摘要9】
避免添加不必要的列。添加过多的索引列(键列或非键列)会对性能产生下列影响:
* 一页上能容纳的索引行将更少。这样会使 I/O 增加并降低缓存效率。
* 需要更多的磁盘空间来存储索引。特别是,将 varchar(max)、nvarchar(max)、varbinary(max) 或 xml 数据类型添加为非键索引列会显著增加磁盘空间要求。这是因为列值被复制到了索引叶级别。因此,它们既驻留在索引中,也驻留在基表中。
* 索引维护可能会增加对基础表或索引视图执行修改、插入、更新或删除操作所需的时间。
您应该确定修改数据时在查询性能上的提升是否超过了对性能的影响,以及是否需要额外的磁盘空间要求。有关评估查询性能的详细信息,请参阅查询优化。
说明:“这是因为列值被复制到了索引叶级别”这句很好的说明了物理上的存储结构和原理。
【图片解析】
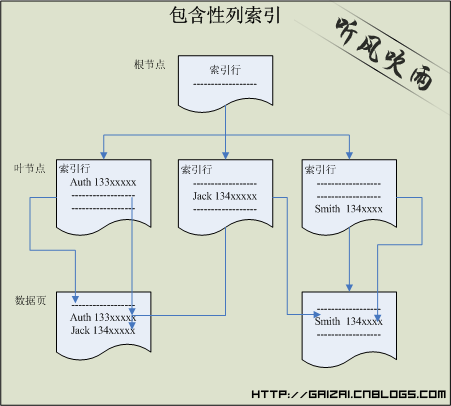
上图也说明了为什么不能在聚集索引中建立具有包含性列的索引,因为非聚集索引的叶层是由索引页而不是由数据页组成,这就得说到聚集和非聚集索引的的物理存储了,聚集索引的顺序排序和存储就是基表的顺序和存储结构。
【一个例子】
SELECT UserName,Password,RealName,Mobile,Age FROM bw_Users WHERE UserName = XXX AND Age = XX
说明:
- 这是一个我们很常见的查询语句,我们如何提高查询效率呢?
- 首先我们来看看谓词,这条语句是通过UserName = XXX AND Age = XX作为条件的,那么我们就应该建立一个组合索引,也称为复合索引,注意索引中的键列的位置,先UserName后Age;
- 其实上面那个是一个非聚集索引,那我们就可以把Password,RealName,Mobile这三列作为索引包含列;
- 所以,最终就是建立一个以UserName 和 Age做为键列、Password,RealName,Mobile作为非键列的非聚集索引;
- 通常来说我们系统的用户表并不是很大,所以这样的优化起不了很明显的效果,如果有兴趣的可以使用大表进行性能测试;
后面的部分摘抄自大神的博客http://www.cnblogs.com/gaizai/archive/2010/01/11/1644358.html
POC索引的更多相关文章
- sql返回前N行
场景:返回每个客户最近的3个订单. 假设我们已经有一个POC索引(详情见http://www.cnblogs.com/xiaopotian/p/6821502.html),有两种策略来完成该任务:一种 ...
- .NET Core微服务系列基础文章索引(目录导航Final版)
一.为啥要总结和收集这个系列? 今年从原来的Team里面被抽出来加入了新的Team,开始做Java微服务的开发工作,接触了Spring Boot, Spring Cloud等技术栈,对微服务这种架构有 ...
- CVE2016-8863libupnp缓冲区溢出漏洞原理分析及Poc
1.libupnp问题分析: (1)问题简述: 根据客户给出的报告,通过设备安装的libupnp软件版本来判断,存在缓冲区溢出漏洞:CVE-2016-8863. (2)漏洞原理分析: 该漏洞发生在up ...
- Android签名验证漏洞POC及验证
poc实际上就是一段漏洞利用代码,以下是最近炒得很火Android签名验证漏洞POC,来自https://gist.github.com/poliva/36b0795ab79ad6f14fd8 #!/ ...
- 转:SIP相关的RFC文档索引
索引来源于http://www.packetizer.com/ipmc/sip/standards.html SIP Standards Core SIP Documents RFC Document ...
- .NET Core微服务架构学习与实践系列文章索引目录
一.为啥要总结和收集这个系列? 今年从原来的Team里面被抽出来加入了新的Team,开始做Java微服务的开发工作,接触了Spring Boot, Spring Cloud等技术栈,对微服务这种架构有 ...
- 用一个性能提升了666倍的小案例说明在TiDB中正确使用索引的重要性
背景 最近在给一个物流系统做TiDB POC测试,这个系统是基于MySQL开发的,本次投入测试的业务数据大概10个库约900张表,最大单表6千多万行. 这个规模不算大,测试数据以及库表结构是用Dump ...
- 【.net 深呼吸】细说CodeDom(7):索引器
在开始正题之前,先补充一点前面的内容. 在方法中,如果要引用方法参数,前面的示例中,老周使用的是 CodeVariableReferenceExpression 类,它用于引用变量,也适用于引用方法参 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
随机推荐
- java内存占用问题(一)
Nocturne 2012-12-24 java数组内存占用问题. 30 Contact[] ca = new Contact[10]; while(x<10){ ca[x]=new ...
- 配置PHP,Apache
安装完windows 2003 server以后,还是个裸机,在安装limesurvey总是会有些问题,还好,问题都解决了,下面讲下配置的步骤: 第一步:先装上apache服务 apache服务启动以 ...
- 实现Runnable接口和继承Thread类
如果欲创建的线程类已经有一个父类了,就不能再继承Thread类了,java不支持多继承. 实现Runnable接口: package multyThread; public class MyRuna ...
- 分析java类的初始化契机
分析java类的静态成员变量初始化先于非静态成员变量 依上图中当class字节码文件被jvm虚拟机加载到内存中依次经过 连接 验证:对字节码进行验证 准备:给静态变量分配内存并赋予变量类型各自的默 ...
- Java 排序(快排,归并)
Java 排序有Java.util.Arrays的sort方法,具体查看JDK API(一般都是用快排实现的,有的是用归并) package yxy; import java.util.Arrays; ...
- Tkinter tkMessageBox
Tkinter tkMessageBox: tkMessageBox模块用于显示在您的应用程序的消息框.此模块提供了一个功能,您可以用它来显示适当的消息 tkMessageBox模块 ...
- Linux下编译、安装php
一.apache环境下php的安装步骤如下:[注意:编译安装php前,应先安装好apache,因为编译php时要用到apache的路径] 1. 在http://www.php.net/download ...
- mongodb分片(七)
1.插入负载技术分片架构图 2.片键的概念和用处 看下面这个普通的集合和分片后的结果 3.什么时候用到分片呢? 3.1机器的磁盘空间不足 3.2单个的mongoDB服务器已经不能满足大量的插入操作 3 ...
- Django admin 使用多个数据库
admin是django自带的一个app,那它涉及的是对Model的所有对象进行增删改查,如果model来自多个数据库如何处理呢? 重写admin.ModelAdmin的如下几个方法就好了: clas ...
- TBluetoothLEDevice.UpdateOnReconnect
System.Bluetooth.TBluetoothLEDevice.UpdateOnReconnect Description Indicates whether the manager auto ...