分布式监控系统开发【day37】:监控数据如何存储(七)
一、如何存储

二、目录结构
三、代码调用逻辑关系

四、实现代码
1、data_optimization
1、存筛选出来符合条件的数据
def get_data_slice(self,lastest_data_key,optimization_interval):
'''
:param optimization_interval: e.g: 600, means get latest 10 mins real data from redis
:return:
'''
all_real_data = self.redis_conn_obj.lrange(lastest_data_key,1,-1)
#print("get data range of:",lastest_data_key,optimization_interval)
#print("get data range of:",all_real_data[-1])
data_set = [] #存筛选出来符合条件的数据
for item in all_real_data:
#print(json.loads(item))
data = json.loads(item.decode())
if len(data) ==2:
#print("real data item:",data[0],data[1])
service_data, last_save_time = data
#print('time:',time.time(), time.time()- last_save_time, optimization_interval)
if time.time() - last_save_time <= optimization_interval:# fetch this data point out
#print(time.time()- last_save_time, optimization_interval)
data_set.append(data)
else:
pass
#print('data set:--->',data_set)
return data_set
2、优化筛选出来的数据
def process_and_save(self):
'''
processing data and save into redis
:return:
'''
print("\033[42;1m---service data-----------------------\033[0m")
#print( self.client_id,self.service_name,self.data)
if self.data['status'] ==0:# service data is valid
for key,data_series_val in settings.STATUS_DATA_OPTIMIZATION.items():
data_series_optimize_interval,max_data_point = data_series_val
data_series_key_in_redis = "StatusData_%s_%s_%s" %(self.client_id,self.service_name,key)
#print(data_series_key_in_redis,data_series_val)
last_point_from_redis = self.redis_conn_obj.lrange(data_series_key_in_redis,-1,-1)
if not last_point_from_redis: #this key is not exist in redis
# 第一次汇报时会执行这段
#so initialize a new key ,the first data point in the data set will only be used to identify that when \
#the data got saved last time
self.redis_conn_obj.rpush(data_series_key_in_redis,json.dumps([None,time.time()] )) if data_series_optimize_interval == 0:#this dataset is for unoptimized data, only the latest data no need to be optimized
self.redis_conn_obj.rpush(data_series_key_in_redis,json.dumps([self.data, time.time()]))
#不需要优化,直接存
else: #data might needs to be optimized
#print("*****>>",self.redis_conn_obj.lrange(data_series_key_in_redis,-2,-1))
last_point_data,last_point_save_time = \
json.loads(self.redis_conn_obj.lrange(data_series_key_in_redis,-1,-1)[0].decode()) if time.time() - last_point_save_time >= data_series_optimize_interval: # reached the data point update interval ,
lastest_data_key_in_redis = "StatusData_%s_%s_latest" %(self.client_id,self.service_name)
print("calulating data for key:\033[31;1m%s\033[0m" %data_series_key_in_redis )
#最近n分钟的数据 已经取到了,放到了data_set里 data_set = self.get_data_slice(lastest_data_key_in_redis,data_series_optimize_interval) #拿到要优化的数据
print('--------------------------len dataset :',len(data_set))
if len(data_set)>0:
#接下来拿这个data_set交给下面这个方法,让它算出优化的结果 来
optimized_data = self.get_optimized_data(data_series_key_in_redis, data_set)
if optimized_data:
self.save_optimized_data(data_series_key_in_redis, optimized_data)
#同时确保数据在redis中的存储数量不超过settings中指定 的值
if self.redis_conn_obj.llen(data_series_key_in_redis) >= max_data_point:
self.redis_conn_obj.lpop(data_series_key_in_redis) #删除最旧的一个数据
#self.redis_conn_obj.ltrim(data_series_key_in_redis,0,data_series_val[1])
else:
print("report data is invalid::",self.data)
raise ValueError
3、把数据存储到redis
def save_optimized_data(self,data_series_key_in_redis, optimized_data):
'''
save the optimized data into db
:param optimized_data:
:return:
'''
self.redis_conn_obj.rpush(data_series_key_in_redis, json.dumps([optimized_data, time.time()]))
4、存储临时数据并计算最大值、最小值、平均值
def get_optimized_data(self,data_set_key, raw_service_data):
'''
calculate out avg,max,min,mid value from raw service data set
:param data_set_key: where the optimized data needed to save to in redis db
:param raw_service_data: raw service data data list
:return:
'''
#index_init =[avg,max,min,mid]
print("get_optimized_data:",raw_service_data[0] )
service_data_keys = raw_service_data[0][0].keys() #[iowait, idle,system...]
first_service_data_point = raw_service_data[0][0] # use this to build up a new empty dic
#print("--->",service_data_keys)
optimized_dic = {} #set a empty dic, will save optimized data later
if 'data' not in service_data_keys: #means this dic has no subdic, works for service like cpu,memory
for key in service_data_keys:
optimized_dic[key] = []
#optimized_dic = optimized_dic.fromkeys(first_service_data_point,[])
tmp_data_dic = copy.deepcopy(optimized_dic) #为了临时存最近n分钟的数据 ,把它们按照每个指标 都 搞成一个一个列表 ,来存最近N分钟的数据
print("tmp data dic:",tmp_data_dic)
for service_data_item,last_save_time in raw_service_data: #loop 最近n分钟的数据
#print(service_data_item)
for service_index,v in service_data_item.items(): #loop 每个数据点的指标service_index=iowait , v=33
#print(service_index,v)
try:
tmp_data_dic[service_index].append(round(float(v),2)) #把这个点的当前这个指标 的值 添加到临时dict中
except ValueError as e:
pass
#print(service_data_item,last_save_time)
#算临时字典里每个指标数据的平均值,最大值。。。,然后存到 optimized_dic 里
for service_k,v_list in tmp_data_dic.items():
print(service_k, v_list)
avg_res = self.get_average(v_list)
max_res = self.get_max(v_list)
min_res = self.get_min(v_list)
mid_res = self.get_mid(v_list)
optimized_dic[service_k]= [avg_res,max_res,min_res,mid_res]
print(service_k, optimized_dic[service_k]) else: # has sub dic inside key 'data', works for a service has multiple independent items, like many ethernet,disks...
#print("**************>>>",first_service_data_point )
for service_item_key,v_dic in first_service_data_point['data'].items():
#service_item_key 相当于lo,eth0,... , v_dic ={ t_in:333,t_out:3353}
optimized_dic[service_item_key] = {}
for k2,v2 in v_dic.items():
optimized_dic[service_item_key][k2] = [] #{etho0:{t_in:[],t_out:[]}} tmp_data_dic = copy.deepcopy(optimized_dic)
if tmp_data_dic: #some times this tmp_data_dic might be empty due to client report err
print('tmp data dic:', tmp_data_dic)
for service_data_item,last_save_time in raw_service_data:#loop最近n分钟数据
for service_index,val_dic in service_data_item['data'].items():
#print(service_index,val_dic)
#service_index这个值 相当于eth0,eth1...
for service_item_sub_key, val in val_dic.items():
#上面这个service_item_sub_key相当于t_in,t_out
#if service_index == 'lo':
#print(service_index,service_item_sub_key,val)
tmp_data_dic[service_index][service_item_sub_key].append(round(float(val),2))
#上面的service_index变量相当于 eth0...
for service_k,v_dic in tmp_data_dic.items():
for service_sub_k,v_list in v_dic.items():
print(service_k, service_sub_k, v_list)
avg_res = self.get_average(v_list)
max_res = self.get_max(v_list)
min_res = self.get_min(v_list)
mid_res = self.get_mid(v_list)
optimized_dic[service_k][service_sub_k] = [avg_res,max_res,min_res,mid_res]
print(service_k, service_sub_k, optimized_dic[service_k][service_sub_k]) else:
print("\033[41;1mMust be sth wrong with client report data\033[0m")
print("optimized empty dic:", optimized_dic) return optimized_dic
临时数据如何存储
5、获取平均值
def get_average(self,data_set):
'''
calc the avg value of data set
:param data_set:
:return:
'''
if len(data_set) >0:
return round(sum(data_set) /len(data_set),2)
else:
return 0
6、获取最大值
def get_max(self,data_set):
'''
calc the max value of the data set
:param data_set:
:return:
'''
if len(data_set) >0:
return max(data_set)
else:
return 0
7、获取最小值
def get_min(self,data_set):
'''
calc the minimum value of the data set
:param data_set:
:return:
'''
if len(data_set) >0:
return min(data_set)
else:
return 0
8、获取中位数
def get_mid(self,data_set):
'''
calc the mid value of the data set
:param data_set:
:return:
'''
data_set.sort()
#[1,4,99,32,8,9,4,5,9]
#[1,3,5,7,9,22,54,77]
if len(data_set) >0:
return data_set[ int(len(data_set)/2) ]
else:
return 0
9、完整代码
#from s15CrazyMonitor import settings
from django.conf import settings
import time ,json
import copy class DataStore(object):
'''
processing the client reported service data , do some data optimiaztion and save it into redis DB
'''
def __init__(self, client_id,service_name, data,redis_obj):
''' :param client_id:
:param service_name:
:param data: the client reported service clean data ,
:return:
'''
self.client_id = client_id
self.service_name = service_name
self.data = data
self.redis_conn_obj = redis_obj
self.process_and_save() def get_data_slice(self,lastest_data_key,optimization_interval):
'''
:param optimization_interval: e.g: 600, means get latest 10 mins real data from redis
:return:
'''
all_real_data = self.redis_conn_obj.lrange(lastest_data_key,1,-1)
#print("get data range of:",lastest_data_key,optimization_interval)
#print("get data range of:",all_real_data[-1])
data_set = [] #存筛选出来符合条件的数据
for item in all_real_data:
#print(json.loads(item))
data = json.loads(item.decode())
if len(data) ==2:
#print("real data item:",data[0],data[1])
service_data, last_save_time = data
#print('time:',time.time(), time.time()- last_save_time, optimization_interval)
if time.time() - last_save_time <= optimization_interval:# fetch this data point out
#print(time.time()- last_save_time, optimization_interval)
data_set.append(data)
else:
pass
#print('data set:--->',data_set)
return data_set def process_and_save(self):
'''
processing data and save into redis
:return:
'''
print("\033[42;1m---service data-----------------------\033[0m")
#print( self.client_id,self.service_name,self.data)
if self.data['status'] ==0:# service data is valid
for key,data_series_val in settings.STATUS_DATA_OPTIMIZATION.items():
data_series_optimize_interval,max_data_point = data_series_val
data_series_key_in_redis = "StatusData_%s_%s_%s" %(self.client_id,self.service_name,key)
#print(data_series_key_in_redis,data_series_val)
last_point_from_redis = self.redis_conn_obj.lrange(data_series_key_in_redis,-1,-1)
if not last_point_from_redis: #this key is not exist in redis
# 第一次汇报时会执行这段
#so initialize a new key ,the first data point in the data set will only be used to identify that when \
#the data got saved last time
self.redis_conn_obj.rpush(data_series_key_in_redis,json.dumps([None,time.time()] )) if data_series_optimize_interval == 0:#this dataset is for unoptimized data, only the latest data no need to be optimized
self.redis_conn_obj.rpush(data_series_key_in_redis,json.dumps([self.data, time.time()]))
#不需要优化,直接存
else: #data might needs to be optimized
#print("*****>>",self.redis_conn_obj.lrange(data_series_key_in_redis,-2,-1))
last_point_data,last_point_save_time = \
json.loads(self.redis_conn_obj.lrange(data_series_key_in_redis,-1,-1)[0].decode()) if time.time() - last_point_save_time >= data_series_optimize_interval: # reached the data point update interval ,
lastest_data_key_in_redis = "StatusData_%s_%s_latest" %(self.client_id,self.service_name)
print("calulating data for key:\033[31;1m%s\033[0m" %data_series_key_in_redis )
#最近n分钟的数据 已经取到了,放到了data_set里 data_set = self.get_data_slice(lastest_data_key_in_redis,data_series_optimize_interval) #拿到要优化的数据
print('--------------------------len dataset :',len(data_set))
if len(data_set)>0:
#接下来拿这个data_set交给下面这个方法,让它算出优化的结果 来
optimized_data = self.get_optimized_data(data_series_key_in_redis, data_set)
if optimized_data:
self.save_optimized_data(data_series_key_in_redis, optimized_data)
#同时确保数据在redis中的存储数量不超过settings中指定 的值
if self.redis_conn_obj.llen(data_series_key_in_redis) >= max_data_point:
self.redis_conn_obj.lpop(data_series_key_in_redis) #删除最旧的一个数据
#self.redis_conn_obj.ltrim(data_series_key_in_redis,0,data_series_val[1])
else:
print("report data is invalid::",self.data)
raise ValueError def save_optimized_data(self,data_series_key_in_redis, optimized_data):
'''
save the optimized data into db
:param optimized_data:
:return:
'''
self.redis_conn_obj.rpush(data_series_key_in_redis, json.dumps([optimized_data, time.time()]) ) def get_optimized_data(self,data_set_key, raw_service_data):
'''
calculate out avg,max,min,mid value from raw service data set
:param data_set_key: where the optimized data needed to save to in redis db
:param raw_service_data: raw service data data list
:return:
'''
#index_init =[avg,max,min,mid]
print("get_optimized_data:",raw_service_data[0] )
service_data_keys = raw_service_data[0][0].keys() #[iowait, idle,system...]
first_service_data_point = raw_service_data[0][0] # use this to build up a new empty dic
#print("--->",service_data_keys)
optimized_dic = {} #set a empty dic, will save optimized data later
if 'data' not in service_data_keys: #means this dic has no subdic, works for service like cpu,memory
for key in service_data_keys:
optimized_dic[key] = []
#optimized_dic = optimized_dic.fromkeys(first_service_data_point,[])
tmp_data_dic = copy.deepcopy(optimized_dic) #为了临时存最近n分钟的数据 ,把它们按照每个指标 都 搞成一个一个列表 ,来存最近N分钟的数据
print("tmp data dic:",tmp_data_dic)
for service_data_item,last_save_time in raw_service_data: #loop 最近n分钟的数据
#print(service_data_item)
for service_index,v in service_data_item.items(): #loop 每个数据点的指标service_index=iowait , v=33
#print(service_index,v)
try:
tmp_data_dic[service_index].append(round(float(v),2)) #把这个点的当前这个指标 的值 添加到临时dict中
except ValueError as e:
pass
#print(service_data_item,last_save_time)
#算临时字典里每个指标数据的平均值,最大值。。。,然后存到 optimized_dic 里
for service_k,v_list in tmp_data_dic.items():
print(service_k, v_list)
avg_res = self.get_average(v_list)
max_res = self.get_max(v_list)
min_res = self.get_min(v_list)
mid_res = self.get_mid(v_list)
optimized_dic[service_k]= [avg_res,max_res,min_res,mid_res]
print(service_k, optimized_dic[service_k]) else: # has sub dic inside key 'data', works for a service has multiple independent items, like many ethernet,disks...
#print("**************>>>",first_service_data_point )
for service_item_key,v_dic in first_service_data_point['data'].items():
#service_item_key 相当于lo,eth0,... , v_dic ={ t_in:333,t_out:3353}
optimized_dic[service_item_key] = {}
for k2,v2 in v_dic.items():
optimized_dic[service_item_key][k2] = [] #{etho0:{t_in:[],t_out:[]}} tmp_data_dic = copy.deepcopy(optimized_dic)
if tmp_data_dic: #some times this tmp_data_dic might be empty due to client report err
print('tmp data dic:', tmp_data_dic)
for service_data_item,last_save_time in raw_service_data:#loop最近n分钟数据
for service_index,val_dic in service_data_item['data'].items():
#print(service_index,val_dic)
#service_index这个值 相当于eth0,eth1...
for service_item_sub_key, val in val_dic.items():
#上面这个service_item_sub_key相当于t_in,t_out
#if service_index == 'lo':
#print(service_index,service_item_sub_key,val)
tmp_data_dic[service_index][service_item_sub_key].append(round(float(val),2))
#上面的service_index变量相当于 eth0...
for service_k,v_dic in tmp_data_dic.items():
for service_sub_k,v_list in v_dic.items():
print(service_k, service_sub_k, v_list)
avg_res = self.get_average(v_list)
max_res = self.get_max(v_list)
min_res = self.get_min(v_list)
mid_res = self.get_mid(v_list)
optimized_dic[service_k][service_sub_k] = [avg_res,max_res,min_res,mid_res]
print(service_k, service_sub_k, optimized_dic[service_k][service_sub_k]) else:
print("\033[41;1mMust be sth wrong with client report data\033[0m")
print("optimized empty dic:", optimized_dic) return optimized_dic def get_average(self,data_set):
'''
calc the avg value of data set
:param data_set:
:return:
'''
if len(data_set) >0:
return round(sum(data_set) /len(data_set),2)
else:
return 0 def get_max(self,data_set):
'''
calc the max value of the data set
:param data_set:
:return:
'''
if len(data_set) >0:
return max(data_set)
else:
return 0 def get_min(self,data_set):
'''
calc the minimum value of the data set
:param data_set:
:return:
'''
if len(data_set) >0:
return min(data_set)
else:
return 0
def get_mid(self,data_set):
'''
calc the mid value of the data set
:param data_set:
:return:
'''
data_set.sort()
#[1,4,99,32,8,9,4,5,9]
#[1,3,5,7,9,22,54,77]
if len(data_set) >0:
return data_set[ int(len(data_set)/2) ]
else:
return 0
data_optimization
2、redis_conn
import redis def redis_conn(django_settings):
#print(django_settings.REDIS_CONN)
pool = redis.ConnectionPool(host=django_settings.REDIS_CONN['HOST'],
port=django_settings.REDIS_CONN['PORT'],
db=django_settings.REDIS_CONN['DB'])
r = redis.Redis(connection_pool=pool)
return r
3、api_views
from django.shortcuts import render,HttpResponse
import json
from django.views.decorators.csrf import csrf_exempt
from monitor.backends import data_optimization
from monitor.backends import redis_conn
from django.conf import settings REDIS_OBJ = redis_conn.redis_conn(settings) print(REDIS_OBJ.set("test",32333)) from monitor.serializer import ClientHandler
# Create your views here. def client_config(request,client_id): config_obj = ClientHandler(client_id)
config = config_obj.fetch_configs() if config:
return HttpResponse(json.dumps(config))
@csrf_exempt
def service_report(request):
print("client data:",request.POST) if request.method == 'POST':
#REDIS_OBJ.set("test_alex",'hahaha')
try:
print('host=%s, service=%s' %(request.POST.get('client_id'),request.POST.get('service_name') ) )
data = json.loads(request.POST['data'])
#print(data)
#StatusData_1_memory_latest
client_id = request.POST.get('client_id')
service_name = request.POST.get('service_name')
#把数据存下来
data_saveing_obj = data_optimization.DataStore(client_id,service_name,data,REDIS_OBJ) #redis_key_format = "StatusData_%s_%s_latest" %(client_id,service_name)
#data['report_time'] = time.time()
#REDIS_OBJ.lpush(redis_key_format,json.dumps(data)) except IndexError as e:
print('----->err:',e) return HttpResponse(json.dumps("---report success---"))
api_views
4、settings
REDIS_CONN = {
'HOST':'192.168.16.126',
'PORT':6379,
'DB':0,
}
STATUS_DATA_OPTIMIZATION = {
'latest':[0,20], #0 存储真实数据,600个点
'10mins':[600,4320], #1m, 每600s进行一次优化,存最大600个点
'30mins':[1800,4320],#3m
'60mins':[3600,8760], #365days
}
五、测试截图
0、获取所有的key
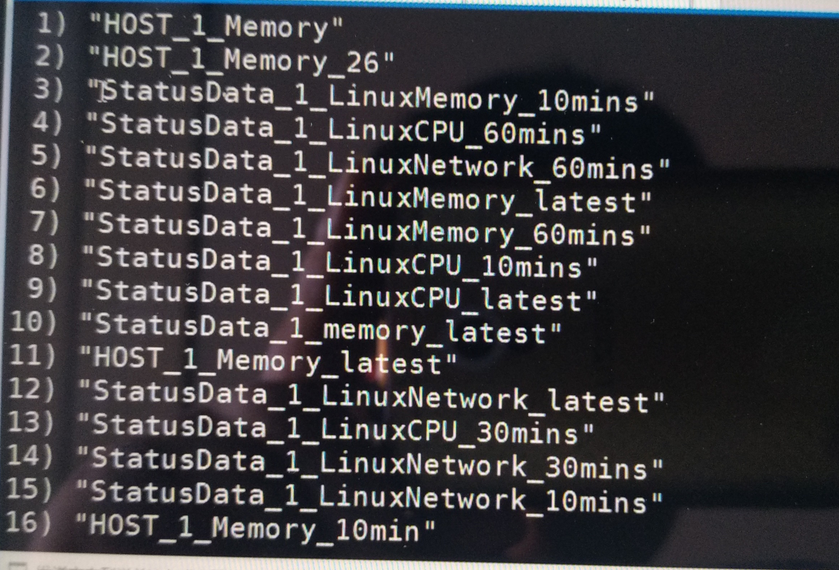
1、已经有key列表说明数据写到redis

2、cpu已经有2个数据了
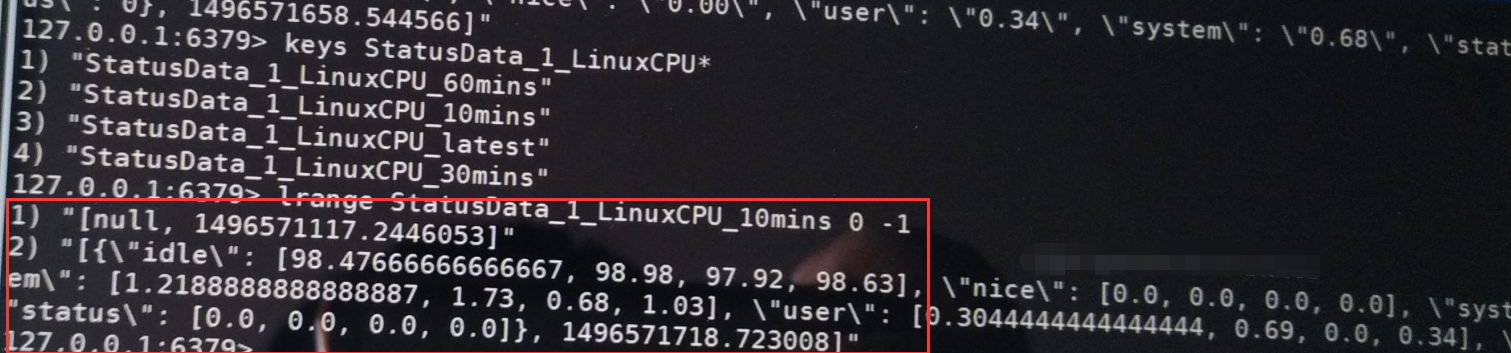
3、控制台获取到数据

4、删除左边第一个值更新最后一个值
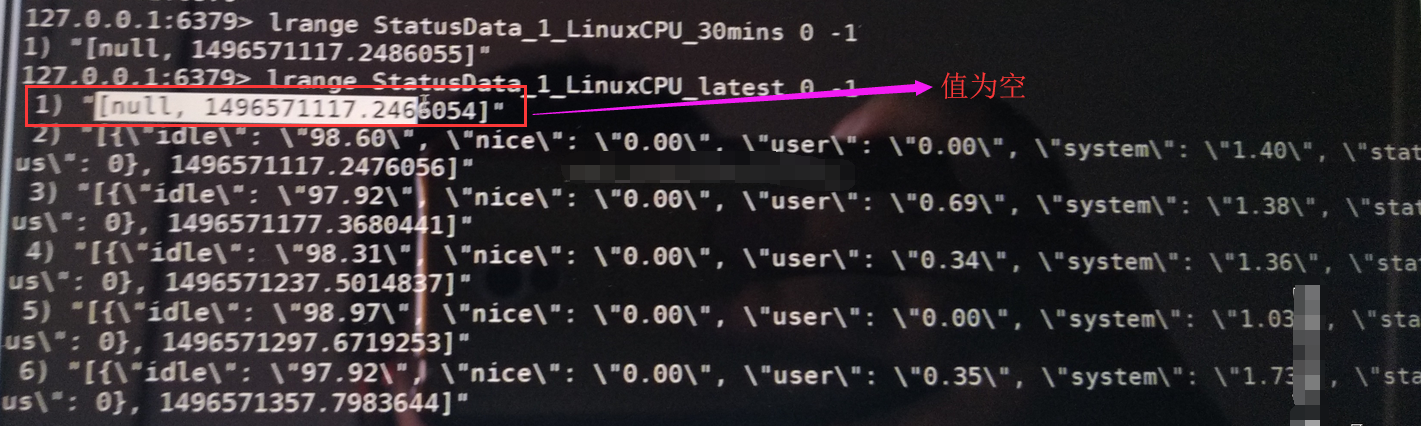
已经更新
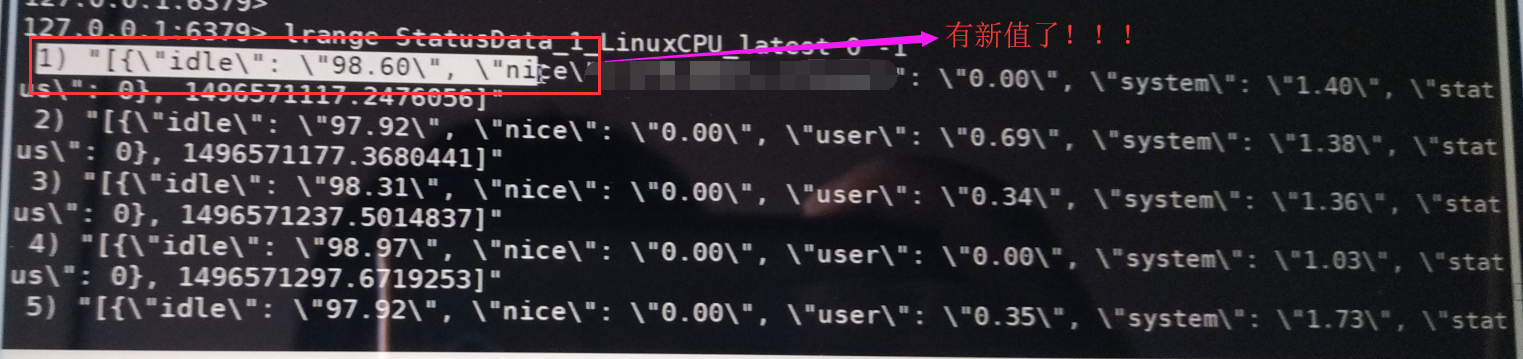
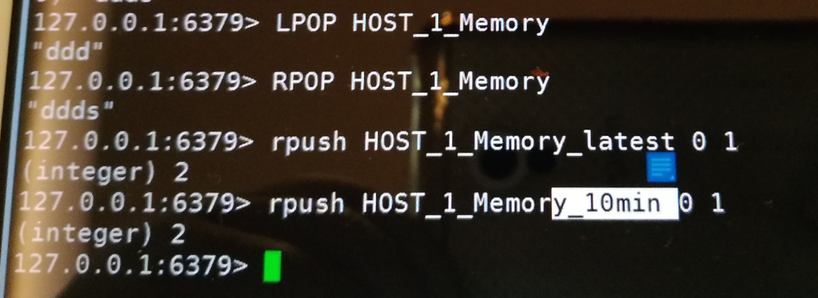
5、redis常用命令操作
分布式监控系统开发【day37】:监控数据如何存储(七)的更多相关文章
- Python之路,Day20 - 分布式监控系统开发
Python之路,Day20 - 分布式监控系统开发 本节内容 为什么要做监控? 常用监控系统设计讨论 监控系统架构设计 监控表结构设计 为什么要做监控? –熟悉IT监控系统的设计原理 –开发一个 ...
- day26 分布式监控系统开发
本节内容 为什么要做监控? 常用监控系统设计讨论 监控系统架构设计 监控表结构设计 为什么要做监控? –熟悉IT监控系统的设计原理 –开发一个简版的类Zabbix监控系统 –掌握自动化开发项目的程序设 ...
- 分布式监控系统开发【day37】:监控数据如何优化(六)
一.数据如何存储方案讨论 1.一个服务存所有主机 2.一台主机的所有服务 3.所有的服务一分钟存一次? 数据量大,浏览器会卡住, 4.最终方案如下 二.解决方案存在问题 1.只能存7天如何处理? 超过 ...
- 分布式监控系统开发【day37】:需求讨论(一)
本节内容 为什么要做监控? 常用监控系统设计讨论 监控需求讨论 如何实现监控服务器的水平扩展? 监控系统架构设计 一.为什么要做监控? 熟悉IT监控系统的设计原理 开发一个简版的类Zabbix监控系统 ...
- Python之分布式监控系统开发
为什么要做监控? –熟悉IT监控系统的设计原理 –开发一个简版的类Zabbix监控系统 –掌握自动化开发项目的程序设计思路及架构解藕原则 常用监控系统设计讨论 Zabbix Nagios 监控系统需求 ...
- 基于类和redis的监控系统开发
最近学习python运维开发,编写得一个简单的监控系统,现记录如下,仅供学习参考. 整个程序分为7个部分: 第一个部分根据监控架构设计文档架构如下: .├── m_client│ ├── conf ...
- 分布式监控系统Zabbix3.2监控数据库的连接数
在 分布式监控系统Zabbix3.2跳坑指南 和 分布式监控系统Zabbix3.2给异常添加邮件报警 已经介绍了如何安装以及报警.此篇通过介绍监控数据库的3306端口连接数来了解如何监控其它端口和配置 ...
- 基于SkyWalking的分布式跟踪系统 - 微服务监控
上一篇文章我们搭建了基于SkyWalking分布式跟踪环境,今天聊聊使用SkyWalking监控我们的微服务(DUBBO) 服务案例 假设你有个订单微服务,包含以下组件 MySQL数据库分表分库(2台 ...
- 移动物体监控系统-sprint3移动监控主系统设计与开发
一.移动监控的原理 通过获取摄像头图像,比较前后每一帧的图像数据,从而实现移动物体监控.所有移动监控原理都是这样,只是图像帧的对比的算法不一样. 二.移动物体监控系统的实现 选择开源的移动监控软件mo ...
随机推荐
- 2.airflow参数简介
比较重要的参数: 参数 默认值 说明 airflow_home /home/airflow/airflow01 airflow home,由环境变量$AIRFLOW_HOME决定 dags_folde ...
- LeetCode 888. Fair Candy Swap(C++)
题目: Alice and Bob have candy bars of different sizes: A[i] is the size of the i-th bar of candy that ...
- 20135313_exp5
课程:Java程序与设计 班级:1353 姓 名:吴子怡 学号:20135313 小组成员: 20135113肖昱 成绩: 指导教师:娄嘉鹏 实验日期:2 ...
- Codeforces Round #345 (Div. 1) C. Table Compression dp+并查集
题目链接: http://codeforces.com/problemset/problem/650/C C. Table Compression time limit per test4 secon ...
- PAT 甲级 1008 Elevator
https://pintia.cn/problem-sets/994805342720868352/problems/994805511923286016 The highest building i ...
- crontab部署定时任务
1.安装cron工具:apt-getinstall cron 2.开启定时任务:crontab –e 定时任务语句格式为:执行周期+命令. 周期有5个域,分别是分,时,日(day of month), ...
- BER-TLV数据结构【转】
转自:https://www.cnblogs.com/SCPlatform/p/5076935.html 为了便于后文的引用说明,先列出一段TLV结构的数据: [6F] 4D │ ├─[84] 07 ...
- 在DBGrid中实现多选功能
1.首先把DBGrid->options-dgMulitSelect设为True. dgRowSelect也设为True,此属性设为true后,DBGrid将不能编辑,如何实现能否编辑代码如下 ...
- Netty系列学习
Netty系列之Netty高性能之道 Netty系列之Netty线程模型 Netty系列之Netty 服务端创建 Netty系列之Netty编解码框架分析 Netty系列之Netty百万级推送服务设计 ...
- Struts创建流程
1.启动服务,加载web.xml 并实例化StrutsPrepareAndExecuteFilter过滤器 2.在实例化StrutsPrepareAndExecuteFilter的时候会执行过滤器中的 ...