词向量( Distributed Representation)工作原理是什么
原文:http://www.zhihu.com/question/21714667
4 个回答

一种最简单的词向量方式是 one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量的分量只有一个 1,其他全为 0, 1 的位置对应该词在词典中的位置。但这种词表示有两个缺点:(1)容易受维数灾难的困扰,尤其是将其用于 Deep Learning 的一些算法时;(2)不能很好地刻画词与词之间的相似性(术语好像叫做“词汇鸿沟”)。
另一种就是你提到 Distributed Representation 这种表示,它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的缺点。其基本想法是:
通过训练将某种语言中的每一个词映射成一个固定长度的短向量(当然这里的“短”是相对于 one-hot representation 的“长”而言的),将所有这些向量放在一起形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。
为更好地理解上述思想,我们来举一个通俗的例子:假设在二维平面上分布有 N 个不同的点,给定其中的某个点,现在想在平面上找到与这个点最相近的一个点,我们是怎么做的呢?首先,建立一个直角坐标系,基于该坐标系,其上的每个点就唯一地对应一个坐标 (x,y);接着引入欧氏距离;最后分别计算这个词与其他 N-1 个词之间的距离,对应最小距离值的那个词便是我们要找的词了。
上面的例子中,坐标(x,y) 的地位相当于词向量,它用来将平面上一个点的位置在数学上作量化。坐标系建立好以后,要得到某个点的坐标是很容易的,然而,在 NLP 任务中,要得到词向量就复杂得多了,而且词向量并不唯一,其质量也依赖于训练语料、训练算法和词向量长度等因素。
一种生成词向量的途径是利用神经网络算法,当然,词向量通常和语言模型捆绑在一起,即训练完后两者同时得到。用神经网络来训练语言模型的思想最早由百度 IDL (深度学习研究院)的徐伟提出。 这方面最经典的文章要数 Bengio 于 2003 年发表在 JMLR 上的 A Neural Probabilistic Language Model,其后有一系列相关的研究工作,其中包括谷歌 Tomas Mikolov 团队的 word2vec (word2vec - Tool for computing continuous distributed representations of words.)。
最近了解到词向量在机器翻译领域的一个应用,报道(机器翻译领域的新突破)是这样的:
谷歌的 Tomas Mikolov 团队开发了一种词典和术语表的自动生成技术,能够把一种语言转变成另一种语言。该技术利用数据挖掘来构建两种语言的结构模型,然后加以对比。每种语言词语之间的关系集合即“语言空间”,可以被表征为数学意义上的向量集合。在向量空间内,不同的语言享有许多共性,只要实现一个向量空间向另一个向量空间的映射和转换,语言翻译即可实现。该技术效果非常不错,对英语和西语间的翻译准确率高达 90%。
我读了一下那篇文章(http://arxiv.org/pdf/1309.4168.pdf),引言中介绍算法工作原理的时候举了一个例子,我觉得它可以帮助我们更好地理解词向量的工作原理,特介绍如下:
考虑英语和西班牙语两种语言,通过训练分别得到它们对应的词向量空间 E 和 S。从英语中取出五个词 one,two,three,four,five,设其在 E 中对应的词向量分别为 v1,v2,v3,v4,v5,为方便作图,利用主成分分析(PCA)降维,得到相应的二维向量 u1,u2,u3,u4,u5,在二维平面上将这五个点描出来,如下图左图所示。类似地,在西班牙语中取出(与 one,two,three,four,five 对应的) uno,dos,tres,cuatro,cinco,设其在 S 中对应的词向量分别为 s1,s2,s3,s4,s5,用 PCA 降维后的二维向量分别为 t1,t2,t3,t4,t5,将它们在二维平面上描出来(可能还需作适当的旋转),如下图右图所示: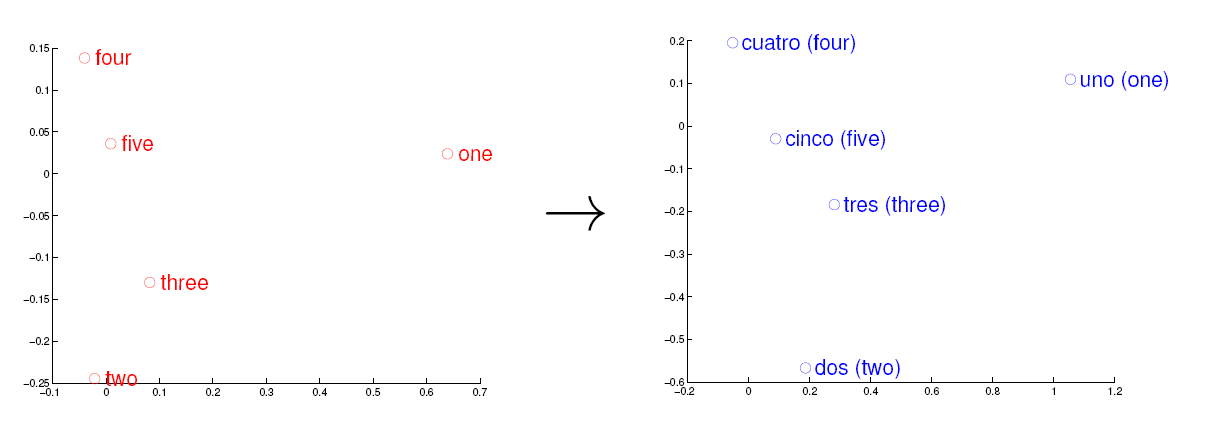 观察左、右两幅图,容易发现:五个词在两个向量空间中的相对位置差不多,这说明两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间相似性的合理性。
观察左、右两幅图,容易发现:五个词在两个向量空间中的相对位置差不多,这说明两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间相似性的合理性。
Deep learning for signal and information Processing
“Distributed representation: a representation of the observed data in such a way that they are
modeled as being generated by the interactions of many hidden factors. A particular factor learned from configurations of other factors can often generalize well. Distributed representations form the basis of deep learning”
 li Eta,Machine Learning, Optimization, Comput…
li Eta,Machine Learning, Optimization, Comput…Distributed Representation:一般不是One-hot representation其实基本都是Distributed Representation,只是一类表示学习方法的总称。
词向量:只要是用于表示词语的向量都可以称作词向量,这类方法中word2vec比较出名,其实One-hot representation也可以作为词向量。
那就举个通俗的例子。
现代人看到宝马,奔驰这两个词,第一眼的反应多数都是汽车。但是如果拿给古人看,古人一定想不到汽车。
为什么呢,因为古人没有相关知识,只能从字面上去理解这两个词,即<宝,马>,<奔,驰>。
拿给计算机,计算机看到的也是字面上的意思,这两个字串是八竿子打不着(要是给计算机宝马和宝剑,它倒是能发现这俩词有点像)。
那怎么才能让计算机把这俩词关系起来呢,这就是统计学习干的事了,因为我们有很多资源可以利用,计算机可以利用一些算法从这些资源中学习到词之间的关系,就像人类一样,天天听别人说这车是宝马,那车是奔驰,久了就知道这俩东西都是车了。但是宝马在有些语境里也未必是车,比如小说中xx身跨xx宝马,这是宝马指的是动物。
我们可以对词汇引入一种向量表示,比如:
<汽车,奢侈品,动物,动作,美食>
统计学习的方法可以学习到每个词的这种表示。它学到的可能是
宝马 = <0.5, 0.2, 0.2, 0.0, 0.1>
奔驰 = <0.7, 0.2, 0.0, 0.1, 0.0>
这样,两个字面上无关的词汇,就连接起来了。
至于怎么学来的,两大常用方法:
统计共同出现的次数(LDA,一种贝叶斯概率模型)。
根据相似的上下文(word2vec,即NN)。
到这已偏题。
词向量( Distributed Representation)工作原理是什么的更多相关文章
- Deep Learning In NLP 神经网络与词向量
0. 词向量是什么 自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化. NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representati ...
- 【paddle学习】词向量
http://spaces.ac.cn/archives/4122/ 关于词向量讲的很好 上边的形式表明,这是一个以2x6的one hot矩阵的为输入.中间层节点数为3的全连接神经网络层,但你看右 ...
- 【word2vec】Distributed Representation——词向量
Distributed Representation 这种表示,它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的缺点. 其基本想法是: 通过训 ...
- 词向量之Word2vector原理浅析
原文地址:https://www.jianshu.com/p/b2da4d94a122 一.概述 本文主要是从deep learning for nlp课程的讲义中学习.总结google word2v ...
- DNN模型训练词向量原理
转自:https://blog.csdn.net/fendouaini/article/details/79821852 1 词向量 在NLP里,最细的粒度是词语,由词语再组成句子,段落,文章.所以处 ...
- word2vec生成词向量原理
假设每个词对应一个词向量,假设: 1)两个词的相似度正比于对应词向量的乘积.即:$sim(v_1,v_2)=v_1\cdot v_2$.即点乘原则: 2)多个词$v_1\sim v_n$组成的一个上下 ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- 学习笔记CB009:人工神经网络模型、手写数字识别、多层卷积网络、词向量、word2vec
人工神经网络,借鉴生物神经网络工作原理数学模型. 由n个输入特征得出与输入特征几乎相同的n个结果,训练隐藏层得到意想不到信息.信息检索领域,模型训练合理排序模型,输入特征,文档质量.文档点击历史.文档 ...
- word2vec词向量训练及中文文本类似度计算
本文是讲述怎样使用word2vec的基础教程.文章比較基础,希望对你有所帮助! 官网C语言下载地址:http://word2vec.googlecode.com/svn/trunk/ 官网Python ...
随机推荐
- 洛谷P2761 软件补丁问题 [状压DP,SPFA]
题目传送门 软件补丁问题 题目描述 T 公司发现其研制的一个软件中有 n 个错误,随即为该软件发放了一批共 m 个补丁程序.每一个补丁程序都有其特定的适用环境,某个补丁只有在软件中包含某些错误而同时又 ...
- python3 怎么爬取新闻网站?
先开个坑,以后再填吧....... import requests from bs4 import BeautifulSoup def content(url): text = requests.ge ...
- 【LeetCode two_pointer】11. Container With Most Water
Given n non-negative integers a1, a2, ..., an, where each represents a point at coordinate (i, ai). ...
- Linux-数据库3
外键约束 如果表A的主关键字是表B中的字段,则该字段称为表B的外键,表A称为主表,表B称为从表. 外键是用来实现参照完整性的,不同的外键约束方式将可以使两张表紧密的结合起来,特别是修改或者删除的级联操 ...
- 导航控制器(UINavigationController)
导航控制器管理一系列显示层次型信息的场景.它创建一个视图管理器"栈",栈底为根视图控制器,用户在场景间切换时,依次将试图控制器压入栈中,且当前场景的试图控制器位于栈顶.要返回上一级 ...
- Django Restframework 实践(二)
按照自己的方法来写接口 ''' @api_view([ 'POST','GET',]) 允许请求的是get或post方法,这里去掉get那么就不能用get方法请求 @permission_classe ...
- 使用matplotlib绘图(二)之柱状图
# 使用matplotlib绘制柱状图 import numpy as np import matplotlib.pyplot as plt # 设置全局字体,以支持中文 plt.rcParams[' ...
- 扩展gcd codevs 1200 同余方程
codevs 1200 同余方程 2012年NOIP全国联赛提高组 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题目描述 Description 求关 ...
- Codeforces Round #346 (Div. 2) A. Round House 水题
A. Round House 题目连接: http://www.codeforces.com/contest/659/problem/A Description Vasya lives in a ro ...
- ROS知识(5)----消息与服务的示例
ROS中已经定义了较多的标准类型的消息,你可以用在这些标准类型的消息上再自定义自己的消息类型.这个在复杂数据传输很有用,例如节点和服务器进行交互时,就可能用到传输多个参数到服务器,并返回相应的结果.为 ...