Row_Number() over( PARTITION By cno ...)
转自:https://blog.csdn.net/qq_25237107/article/details/64442969
1.在 MSSQL,oracle 有partition by 的用法
create table score
(
sno varchar(20) ,
cno varchar(20),
degree int
) insert into score (sno ,cno ,degree ) values ('001','a',100)
insert into score (sno ,cno ,degree ) values ('002','a',99)
insert into score (sno ,cno ,degree ) values ('003','a',98)
insert into score (sno ,cno ,degree ) values ('004','a',97)
insert into score (sno ,cno ,degree ) values ('001','b',100)
insert into score (sno ,cno ,degree ) values ('002','b',100)
insert into score (sno ,cno ,degree ) values ('003','b',99)
insert into score (sno ,cno ,degree ) values ('004','b',98)
insert into score (sno ,cno ,degree ) values ('001','c',100)
insert into score (sno ,cno ,degree ) values ('002','c',100)
insert into score (sno ,cno ,degree ) values ('003','c',99)
insert into score (sno ,cno ,degree ) values ('004','c',98) select * from
(
select *,ROW_NUMBER () over(PARTITION BY cno order by degree desc) as pm from score
) x
where x.pm <=3 select * from
(
select *,rank () over(PARTITION BY cno order by degree desc) as pm from score
) x
where x.pm <=3 select * from
(
select *,dense_rank () over(PARTITION BY cno order by degree desc) as pm from score
) x
where x.pm <=3 2.在 mysql中 没有 ROW_NUMBER()over(partition by ... order by ...) 这种写法
需要用其他 替代方法:
方法一:
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`subject_id` char(10) DEFAULT NULL,
`student_id` char(10) DEFAULT NULL,
`score` float DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8;
INSERT INTO score
select NULL,'1','001',100
UNION
SELECT NULL,'1','002',90
UNION
SELECT null,'1','003',80
UNION
select null,'1','004',99
UNION
select null,'1','005',78
UNION
select null,'1','006',89
UNION
select NULL,'1','001',100
UNION
SELECT NULL,'1','002',90
UNION
SELECT null,'1','003',80
UNION
select null,'1','004',99
UNION
select null,'1','005',78
UNION
select null,'1','006',89
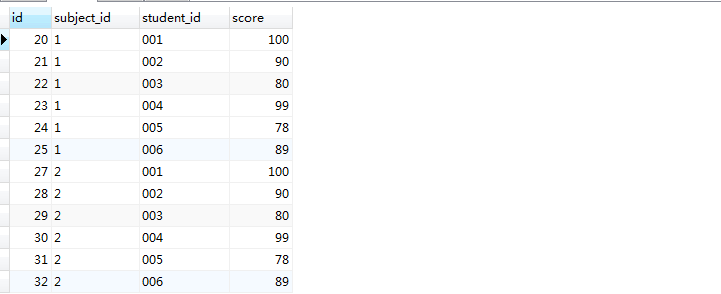
2.
相当于自身全连接:
SELECT AA.*,BB.* FROM score AA JOIN score BB
on AA.subject_id=BB.subject_id AND AA.score>=BB.score
ORDER BY AA.subject_id,AA.score DESC
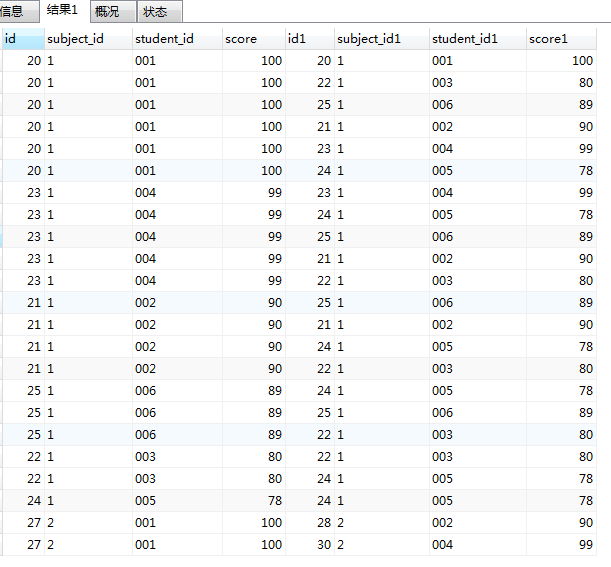
3. group by 之
SELECT AA.*,BB.* FROM score AA JOIN score BB
on AA.subject_id=BB.subject_id AND AA.score>=BB.score
GROUP BY AA.student_id,AA.subject_id,AA.score
ORDER BY AA.subject_id,AA.score DESC
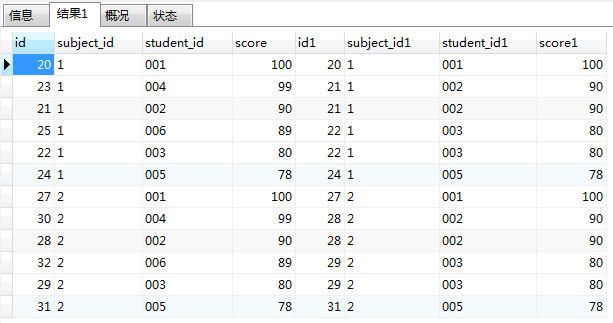
4.having 之
SELECT AA.id,AA.student_id,AA.subject_id,AA.score FROM score AA JOIN score BB
on AA.subject_id=BB.subject_id AND AA.score>=BB.score
GROUP BY AA.student_id,AA.subject_id,AA.score
HAVING count(AA.subject_id)>=4
ORDER BY AA.subject_id,AA.score DESC
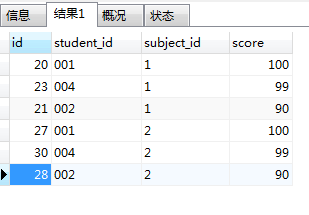
注意: mysql 与 MSsql 之 group by 是不相同的
mysql 使用 group by 后 select 可以 全部字段. mssql 是不行的
方法二:
Mysql 分组聚合实现 over partition by 功能
转自:https://www.cnblogs.com/zhwbqd/p/4205821.html
https://blog.csdn.net/zzm628/article/details/52181382
mysql中没有类似oracle和postgreSQL的 OVER(PARTITION BY)功能. 那么如何在MYSQL中搞定分组聚合的查询呢
先说结论: 利用 group_concat + substr等函数处理
例如: 订单表一张, 只保留关键字段
| id | user_id | money | create_time |
| 1 | 1 | 50 | 1420520000 |
| 2 | 1 | 100 | 1420520010 |
| 3 | 2 | 100 | 1420520020 |
| 4 | 2 | 200 | 1420520030 |
业务: 查找每个用户的最近一笔消费金额
单纯使用group by user_id, 只能按user_id 将money进行聚合, 是无法将最近一单的金额筛选出来的, 只能满足这些需求, 例如: 每个用户的总消费金额 sum(money), 最大消费金额 max(money), 消费次数count(1) 等
但是我们有一个group_concat可以用, 思路如下:
1. 查找出符合条件的记录, 按user_id asc, create_time desc 排序;
select ord.user_id, ord.money, ord.create_time from orders ord where ord.user_id > 0 and create_time > 0 order by ord.user_id asc , ord.create_time desc
| user_id | money | create_time |
| 1 | 100 | 1420520010 |
| 1 | 50 | 1420520000 |
| 2 | 200 | 1420520030 |
| 2 | 100 | 1420520020 |
2. 将(1)中记录按user_id分组, group_concat(money);
select t.user_id, group_concat( t.money order by t.create_time desc ) moneys from (select ord.user_id, ord.money, ord.create_time from orders ord where ord.user_id > 0 and ord.create_time > 0 order by ord.user_id asc , ord.create_time desc) t group by t.user_id
| user_id | moneys |
| 1 | 100,50 |
| 2 | 200,100 |
3. 这时, 如果用户有多个消费记录, 就会按照时间顺序排列好, 再利用 subString_index 函数进行切分即可
完整SQL, 注意group_concat的内排序, 否则顺序不保证, 拿到的就不一定是第一个了
select t.user_id, substring_index(group_concat( t.money order by t.create_time desc ),',',1) lastest_money from (select ord.user_id, ord.money, ord.create_time from orders ord where ord.user_id > 0 and create_time > 0 order by user_id asc , create_time desc) t group by user_id ;
| user_id | moneys |
| 1 | 100 |
| 2 | 200 |
利用这个方案, 以下类似业务需求都可以这么做, 如:
1. 查找每个用户过去10个的登陆IP
2. 查找每个班级中总分最高的两个人
补充: 如果是只找出一行记录, 则可以直接只用聚合函数来进行
select t.user_id, t.money from (select ord.user_id, ord.money, ord.create_time from orders ord where ord.user_id > 0 and create_time > 0 order by user_id asc , create_time desc) t group by user_id ;
前提一定是(1) 只需要一行数据, (2) 子查询中已排好序, (3) mysql关闭 strict-mode
参考资料:
http://dev.mysql.com/doc/refman/5.0/en/sql-mode.html#sql-mode-strict
http://dev.mysql.com/doc/refman/5.0/en/group-by-functions.html#function_group-concat
有任何问题请不吝赐教, 谢谢!
Row_Number() over( PARTITION By cno ...)的更多相关文章
- sql 分组取最新的数据sqlserver巧用row_number和partition by分组取top数据
SQL Server 2005后之后,引入了row_number()函数,row_number()函数的分组排序功能使这种操作变得非常简单 分组取TOP数据是T-SQL中的常用查询, 如学生信息管理系 ...
- ROW_NUMBER()与PARTITION BY 实例
环境:SQL Server 2008 R2 数据表结构 SELECT A.* FROM [tbiz_AssScoreWeidu] A SELECT A.* ,ROW_NUMBER() OVER ( P ...
- row_number和partition by分组取top数据
分组取TOP数据是T-SQL中的常用查询, 如学生信息管理系统中取出每个学科前3名的学生.这种查询在SQL Server 2005之前,写起来很繁琐,需要用到临时表关联查询才能取到.SQL Serve ...
- 去重 ROW_NUMBER() OVER(PARTITION BY 分组字段 ORDER BY 排序字段) RN
关键字 ROW_NUMBER() OVER(PARTITION BY 分组字段 ORDER BY 排序字段) RN 按照分组字段进行排序并标编号 ROW_NUMBER() OVER(PARTITIO ...
- row_number()over(partition by 字段 order by 字段)ID,修改重复行的字段值。
案例分析: 现在要查询一个表单里面的运费结果,但是他还有分录,为了显示分录,必须把表头显示出来,问题是,他要查询运费的合计, 但是这样就会导致重复行也加进去了,这样显然数据不准,为此,可以把重复的行设 ...
- row_number() OVER(PARTITION BY)函数介绍
OVER(PARTITION BY)函数介绍 开窗函数 Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个 ...
- sqlserver巧用row_number和partition by分组取top数据
SELECT * FROM( SELECT orderid,createtime, ROW_NUMBER() over(PARTITION by orderid order by createtime ...
- SQL技术内幕-4 row_number() over( partition by XX order by XX)的用法(区别于group by 和order by)
partition by关键字是分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,partition by用于给结果集分组,如果没有指 ...
- row_number() OVER (PARTITION BY COL1 ORDER BY COL2)
select *,ROW_NUMBER() over(partition by deviceID order by RecordDate desc row_number() OVER (PARTITI ...
随机推荐
- ssh登录服务器
ssh -i /home/zhangsuosheng/mykey.pub myusername@111.111.111.111
- win32调试工具原理OutputDebugString以及如何获取输出信息
在应用程序和调试器之间传递数据是通过一个 4KB 大小的共享内存块完成的,并有一个互斥量和两个事件对象用来保护对他的访问.下面就是相关的四个内核对象: 对象名称 对象类型 DBWinMutex Mut ...
- jango模板语言初识
一.Django框架简介 1.MVC框架 MVC,全名是Model View Controller,是软件工程中的一种软件架构模式,把软件系统分为三个基本部分:模型(Model).视图(View)和控 ...
- 设计模式C++实现——适配器模式
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/walkerkalr/article/details/29863177 模式定义: 适 ...
- 0606-Zuul构建API Gateway-Zuul过滤器以及禁用Zuul过滤器
一.概述 针对Spring Cloud的Zuul配备了许多在代理和服务器模式下默认启用的ZuulFilter bean. 有关启用的可能过滤器,请参阅zuul过滤器包. 二.Zuul过滤器使用 2.1 ...
- 深入理解Flink核心技术(转载)
作者:李呈祥 Flink项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多的人关注Flink项目.本文将深入分析Flink一些关键的技术与特性,希望能够帮助读者 ...
- mysql构建一张百万级别数据的表信息测试
表信息: CREATE TABLE dept( /*部门表*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ dname VARCHAR(2 ...
- oracle 查看隐藏参数
隐藏参数 (hidden parameters) ,由oracle内部使用,以 '_' 开头. 可以通过以下两种方式查看所有隐藏参数: SELECT i.ksppinm name, i.ksppd ...
- A class for dynamic icons in Windows
A class for dynamic icons in Windows #include <windows.h> class DynamicIcon {public: DynamicI ...
- phpMyAdmin的安装配置
找到$cfg['blowfish_secret'] = '',将其值改为你自己想要的任意字符,如$cfg['blowfish_secret'] = 'owndownd': 找到$cfg['Server ...