大数据(11) - kafka的安装与使用
一、Kafka概述
1.Kafka是什么
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
1)Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn公司开发,并于 2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3)Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
4)无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
2. 消息队列内部实现原理
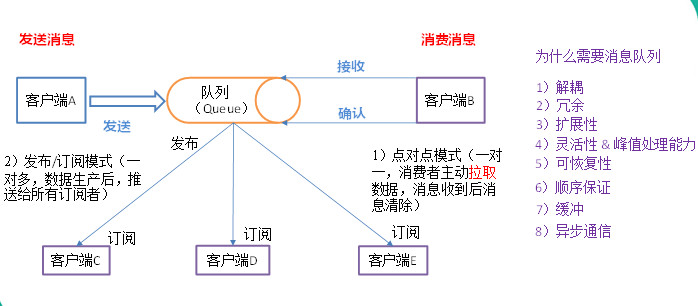
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
(2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
3. 为什么需要消息队列
1)解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3)扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4)灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6)顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性)
7)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8)异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
二、Kafka部署
1.成功安装部署zookeeper
2.解压
$ tar -zxf ~/softwares/installations/kafka_2.11-0.11.0.2.tgz -C ~/modules/
3. 修改配置文件
vim ~/modules/kafka_2.11-0.11.0.2/config/server.properties 修改以下内容 broker.id=0 delete.topic.enable=true
log.dirs=/home/admin/modules/kafka_2.11-0.11.0.2/kafka-logs
zookeeper.connect=linux01:2181,linux02:2181,linux03:2181 zookeeper.connection.timeout.ms=60000
4.分发
$ scp -r kafka_2.11-0.11.0.2/ linux02:/home/admin/modules/
$ scp -r kafka_2.11-0.11.0.2/ linux03:/home/admin/modules/
5.修改另外两台机器的broker.id,3台机器的broker.id分别为0,1,2
6.启动kafka集群(3台机器分别执行,必须先把zookeeper启动起来!!)
$ bin/kafka-server-start.sh config/server.properties
kafka的broker进程,是一个前台占用进程。如果想后台运行,则在末尾加上"&"符号
$ bin/kafka-server-start.sh config/server.properties &
大数据(11) - kafka的安装与使用的更多相关文章
- 【大数据之数据仓库】安装部署GreenPlum集群
本篇将向大家介绍如何快捷的安装部署GreenPlum测试集群,大家可以跟着我一块儿实践一把^_^ 1.主机资源 申请2台网易云主机,操作系统必须是RedHat或者CentOS,配置尽量高一点.如果是s ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 大数据Spark+Kafka实时数据分析案例
本案例利用Spark+Kafka实时分析男女生每秒购物人数,利用Spark Streaming实时处理用户购物日志,然后利用websocket将数据实时推送给浏览器,最后浏览器将接收到的数据实时展现, ...
- 大数据-12-Spark+Kafka构建实时分析Dashboard
转自 http://dblab.xmu.edu.cn/post/8274/ 0.案例概述 本案例利用Spark+Kafka实时分析男女生每秒购物人数,利用Spark Streaming实时处理用户购物 ...
- 【大数据】Kafka学习笔记
第1章 Kafka概述 1.1 消息队列 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息 ...
- 大数据(9) - Flume的安装与使用
Flume简介 --(实时抽取数据的工具) 1) Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集.聚集.移动的服务,Flume只能在Unix环境下运行. 2) Flume基于流式架构 ...
- 【大数据作业九】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 4.简述Hadoop平台的起源.发展历史与应用现状. 列举发展过程中 ...
- 大数据之Kafka史上最详细原理总结
Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实 ...
- 大数据入门:Hadoop安装、环境配置及检测
目录 1.导包Hadoop包 2.配置环境变量 3.把winutil包拷贝到Hadoop bin目录下 4.把Hadoop.dll放到system32下 5.检测Hadoop是否正常安装 5.1在ma ...
随机推荐
- magento 12 配置安装教程
Magento (麦进斗) 是一套专业开源的电子商务系统.Magento设计得非常灵活,具有模块化架构体系和丰富的功能.易于与第三方应用系统无缝集成.其面向企业级应用,可处理各方面的需求,以及建设一个 ...
- JQuery 控制div滚动条保持最下
$("#session_show").animate({ scrollTop: $("#session_show").scrollHeight },1000); ...
- Discuz常见小问题-如何发布站点公告
运营-站点公告,可以管理或添加新的公告 如果要添加要把这个终止时间设置的远一点,不然一个月之后就自动消失了 完成之后可以在首页,帖子的常规地方看到这些公告
- Discuz常见小问题-如何删除用户
用户-用户管理,直接拉到底部点搜索 切换到最后一页,然后勾选要删除的用户(最后一页就是最新注册的用户) 要勾选两个选项,删除过程比较长,不要中途退出,等待删除完毕 再次搜索用户就少一个了
- 关于ActiveMQ的配置
http://www.cnblogs.com/CopyPaster/archive/2012/04/27/2473179.html
- Simple drag and drop
In computer graphical user interfaces, drag-and-drop is the action of (or support for the action of) ...
- Guava ---- Ordering排序工具
使用Guava的排序工具类, 高速实现对象的单变量排序和多变量排序, 让你的开发效率爆炸... import com.google.common.collect.Lists; import com.g ...
- springmvc sitemesh json问题
参考: 解决方法: <sitemesh> <mapping path="/*" decorator="/WEB-INF/views/template/t ...
- 阿里云rds linux平台使用wget 工具下载备份与日志文件
1. 获取备份下载地址 RDS 控制台 备份恢复 数据备份,选择需要下载的备份集,点击“下载”. 点击“复制内网地址” 或 “复制外网地址” 来获取备份的 内网 或 外网 下载地址. 日志备份的地 ...
- 工作总结 Rezor 里面的一些小知识----自定义类型 放在标签值中 会直接跳过去
0 的时候不报错 1 的时候 报错了 原因 是 imagesname[i] 索引超出了 为什么在 上面 报错呢? 不在这里报错呢? 说明了 Rezor 对于 自定义的变量 放在标签值里的时候,调 ...