MapReduce程序的工作过程
转自:http://www.aboutyun.com/thread-15494-1-2.html
问题导读
1、HDFS框架组成是什么?
2、HDFS文件的读写过程是什么?
3、MapReduce框架组成是什么?
4、MapReduce工作原理是什么?
5、什么是Shuffle阶段和Sort阶段?
还记得2.5年前就搭建好了Hadoop伪分布式集群,安装好Eclipse后运行成功了WordCount.java,然后学习Hadoop的步伐就变得很慢了,相信有很多小伙伴和我一样。自己对MR程序(特指Hadoop 1.x版本)的工作过程一直都不是很清楚,现在重点总结一下,为MR编程打好基础。由于MapReduce是基于HDFS的操作,因此要想深入理解MapReduce(解决的是分布式计算问题),首先得深入理解HDFS(解决的是分布式存储问题)。
一. HDFS框架组成
<ignore_js_op>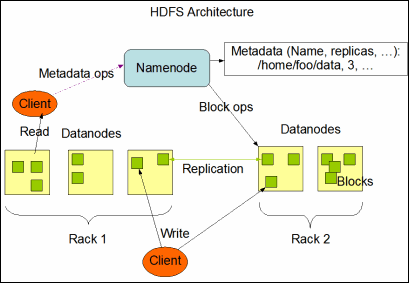
HDFS采用master/slaver的主从架构,一个HDFS集群包括一个NameNode节点(主节点)和多个DataNode节点(从节点),并提供应用程序的访问接口。NameNode,DataNode和Client的解释,如下所示:
- NameNode负责文件系统名字空间的管理与维护,同时负责客户端文件操作(比如打开,关闭,重命名文件或目录等)的控制及具体存储任务的管理与分配(比如确定数据块到具体DataNode节点的映射等);
- DataNode负责处理文件系统客户端的读写请求,提供真实文件数据的存储服务;
- Client是客户端,一般指的是访问HDFS接口的应用程序,或者HDFS的Web服务(就是让用户通过浏览器来查看HDFS的运行状况)等。
1. 文件的读取
Client与之交互的HDFS、NameNode、DataNode文件的读取流程,如下所示: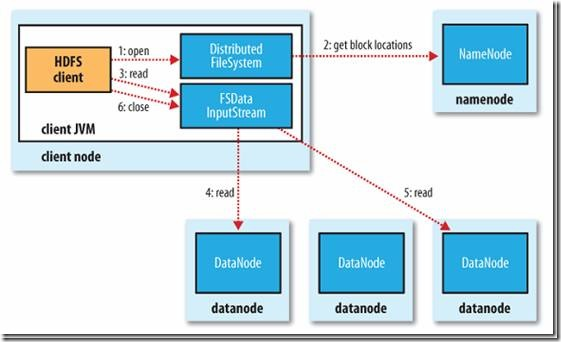
- Client向远程的NameNode发起RPC请求;(1)
- NameNode会返回文件的部分或者全部Block列表,对于每个Block,NameNode都会返回该Block副本的DataNode地址;(2)
- Client会选择与其最接近的DataNode来读取Block,如果Client本身就是DataNode,那么将从本地直接读取数据;(3)
- 读完当前Block后,关闭与当前的DataNode连接,并为读取下一个Block寻找最近的DataNode;(4)
- 读完Block列表后,并且文件读取还没有结束,Client会继续向NameNode获取下一批Block列表;(5)
- 读完一个Block都会进行Cheeksum验证,如果读取DataNode时出现错误,Client会通知NameNode,然后从该Block的另外一个最近邻DataNode继续读取数据。Client读取数据完毕之后,关闭数据流。(6)
2. 文件的写入
Client与之交互的HDFS、NameNode、DataNode文件的写入流程,如下所示:
<ignore_js_op>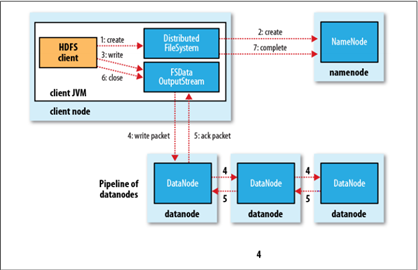
- Client向远程的NameNode发起RPC请求;(1)
- NameNode便会检查要创建的文件是否已经存在,创建者是否有权限进行操作等,如果满足相关条件,就会创建文件,否则会让Client抛出异常;(2)
- 在Client开始写入文件的时候,开发库(即DFSOutputStream)会将文件切分成一个个的数据包,并写入”数据队列“,然后向NameNode申请新的Block,从而得到用来存储复本(默认为3)的合适的DataNode列表,每个列表的大小根据NameNode中对replication的设置而定;(3)
- 首先把一个数据包以流的方式写入第一个DataNode,其次将其传递给在此管线中的下一个DataNode,然后直到最后一个DataNode,这种写数据的方式呈流水线的形式;(假设复本为3,那么管线由3个DataNode节点构成,即Pipeline of datanodes)(4)
- 当最后一个DataNode完成之后,就会返回一个确认包,在管线里传递至Client,开发库(即DFSOutputStream)也维护着一个”确认队列”,当成功收到DataNode发回的确认包后便会从“确认队列”中删除相应的包;(5)
- 如果某个DataNode出现了故障,那么DataNode就会从当前的管线中删除,剩下的Block会继续在余下的DataNode中以管线的形式传播,同时NameNode会再分配一个新的DataNode,以保持replication设定的数量。Client写入数据完毕之后,关闭数据流。(6)
说明:HDFS默认Block的大小为64M,提供SequenceFile和MapFile二种类型的文件。
二. MapReduce框架组成
MapReduce框架的主要组成部分和它们之间的相关关系,如下所示:
<ignore_js_op>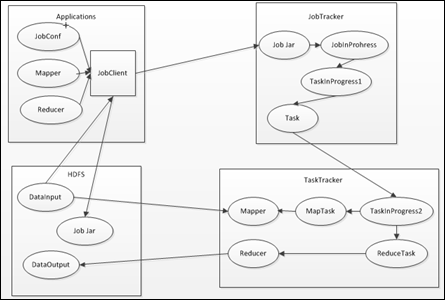
上述过程包含4个实体,各实体的功能,如下所示:
- Client:提交的MapReduce作业,比如,写的MR程序,或者CLI执行的命令等;
- JobTracker:协调作业的运行,本质是一个管理者;
- TaskTracker:运行作业划分后的任务,本质就是一个执行者;
- HDFS:用来在集群间共享存储的一种抽象文件系统。
直观来说,NameNode就是一个元数据仓库,就像Windows中的注册表一样。SecondaryNameNode可以看成NameNode的备份。DataNode可以看成是用来存储作业划分后的任务。在通常搭建的3台Hadoop分布式集群中,Master是NameNode,SecondaryNameNode,JobTracker,其它2台Slaver都是TaskTracker,DataNode,并且TaskTracker都需要运行在HDFS的DataNode上面。
上述用到的类,或者进程的功能,如下所示:
- Mapper和Reducer
基于Hadoop的MapReduce应用程序最今本的组成部分包括:一个Mapper抽象类,一个Reducer抽象类,一个创建JobConf的执行程序。 - JobTracker
JobTracker属于master,一般情况应该部署在单独的机器上,它的功能就是接收Job,负责调度Job的每一个子任务Task运行在TaskTracker上,并且监控它们,如果发现有失败的Task就重启它即可。 - TaskTracker
TaskTracker是运行于多节点的slaver服务,它的功能是主动通过心跳与JobTracker进行通信接收作业,并且负责执行每一个任务。 - JobClient
JobClient的功能是在Client提交作业后,把一些文件上传到HDFS,比如作业的jar包(包括应用程序以及配置参数)等,并且把路径提交到JobTracker,然后由JobTracker创建每一个Task(即MapTask和ReduceTask)并将它们分别发送到各个TaskTracker上去执行。 - JobInProgress
JobClient提交Job后,JobTracker会创建一个JobInProgress来跟踪和调度这个Job,并且把它添加到Job队列中。JobInProgress根据提交的Job Jar中定义的输入数据集(已分解成FileSplit)创建对应的一批TaskInProgress1用于监控和调度Task。 - TaksInProgress2
JobTracker通过每一个TaskInProgress1来运行Task,这时会把Task对象(即MapTask和ReduceTask)序列化写入相应的TaskTracker中去,TaskTracker会创建对应的TaskInProgress2用于监控和调度该MapTask和ReduceTask。 - MapTask和ReduceTask
Mapper根据Job Jar中定义的输入数据<key1, value1>读入,生成临时的<key2, value2>,如果定义了Combiner,MapTask会在Mapper完成后调用该Combiner将相同Key的值做合并处理,目的是为了减少输出结果。MapTask全部完成后交给ReduceTask进程调用Reducer处理,生成最终结果<key3, value3>。具体过程可以参见[4]。
三. MapReduce工作原理
整个MapReduce作业的工作工程,如下所示:
<ignore_js_op>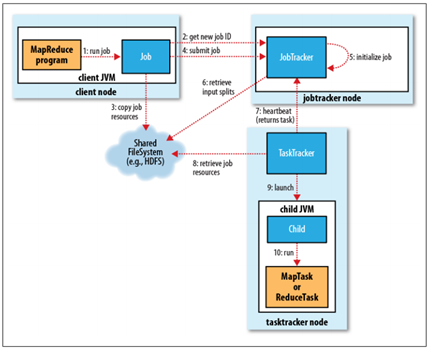
1. 作业的提交
JobClient的submitJob()方法实现的作业提交过程,如下所示:
- 通过JobTracker的getNewJobId()请求一个新的作业ID;(2)
- 检查作业的输出说明(比如没有指定输出目录或输出目录已经存在,就抛出异常);
- 计算作业的输入分片(当分片无法计算时,比如输入路径不存在等原因,就抛出异常);
- 将运行作业所需的资源(比如作业Jar文件,配置文件,计算所得的输入分片等)复制到一个以作业ID命名的目录中。(集群中有多个副本可供TaskTracker访问)(3)
- 通过调用JobTracker的submitJob()方法告知作业准备执行。(4)
2. 作业的初始化
- JobTracker接收到对其submitJob()方法的调用后,就会把这个调用放入一个内部队列中,交由作业调度器(比如先进先出调度器,容量调度器,公平调度器等)进行调度;(5)
- 初始化主要是创建一个表示正在运行作业的对象——封装任务和记录信息,以便跟踪任务的状态和进程;(5)
- 为了创建任务运行列表,作业调度器首先从HDFS中获取JobClient已计算好的输入分片信息(6)。然后为每个分片创建一个MapTask,并且创建ReduceTask。(Task在此时被指定ID,请区分清楚Job的ID和Task的ID)。
3. 任务的分配
- TaskTracker定期通过“心跳”与JobTracker进行通信,主要是告知JobTracker自身是否还存活,以及是否已经准备好运行新的任务等;(7)
- JobTracker在为TaskTracker选择任务之前,必须先通过作业调度器选定任务所在的作业;
- 对于MapTask和ReduceTask,TaskTracker有固定数量的任务槽(准确数量由TaskTracker核的数量和内存大小来决定)。JobTracker会先将TaskTracker的MapTask填满,然后分配ReduceTask到TaskTracker;
- 对于MapTrask,JobTracker通过会选取一个距离其输入分片文件最近的TaskTracker。对于ReduceTask,因为无法考虑数据的本地化,所以也没有什么标准来选择哪个TaskTracker。
4. 任务的执行
- TaskTracker分配到一个任务后,通过从HDFS把作业的Jar文件复制到TaskTracker所在的文件系统(Jar本地化用来启动JVM),同时TaskTracker将应用程序所需要的全部文件从分布式缓存复制到本地磁盘;(8)
- TaskTracker为任务新建一个本地工作目录,并把Jar文件中的内容解压到这个文件夹中;
- TaskTracker启动一个新的JVM(9)来运行每个Task(包括MapTask和ReduceTask),这样Client的MapReduce就不会影响TaskTracker守护进程(比如,导致崩溃或挂起等);
- 子进程通过umbilical接口与父进程进行通信,Task的子进程每隔几秒便告知父进程它的进度,直到任务完成。
5. 进程和状态的更新
一个作业和它的每个任务都有一个状态信息,包括作业或任务的运行状态,Map和Reduce的进度,计数器值,状态消息或描述(可以由用户代码来设置)。这些状态信息在作业期间不断改变,它们是如何与Client通信的呢?
<ignore_js_op>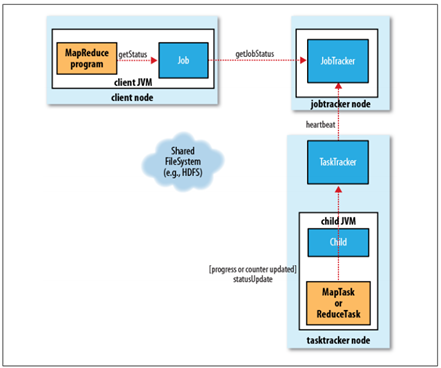
- 任务在运行时,对其进度(即任务完成的百分比)保持追踪。对于MapTask,任务进度是已处理输入所占的比例。对于ReduceTask,情况稍微有点复杂,但系统仍然会估计已处理Reduce输入的比例;
- 这些消息通过一定的时间间隔由Child JVM—>TaskTracker—>JobTracker汇聚。JobTracker将产生一个表明所有运行作业及其任务状态的全局视图。可以通过Web UI查看。同时JobClient通过每秒查询JobTracker来获得最新状态,并且输出到控制台上。
6. 作业的完成
当JobTracker收到作业最后一个任务已完成的通知后,便把作业的状态设置为"成功"。然后,在JobClient查询状态时,便知道作业已成功完成,于是JobClient打印一条消息告知用户,最后从runJob()方法返回。
四. Shuffle阶段和Sort阶段
Shuffle阶段是指从Map的输出开始,包括系统执行排序以及传送Map输出到Reduce作为输入的过程。Sort阶段是指对Map端输出的Key进行排序的过程。不同的Map可能输出相同的Key,相同的Key必须发送到同一个Reduce端处理。Shuffle阶段可以分为Map端的Shuffle和Reduce端的Shuffle。Shuffle阶段和Sort阶段的工作过程,如下所示:
<ignore_js_op>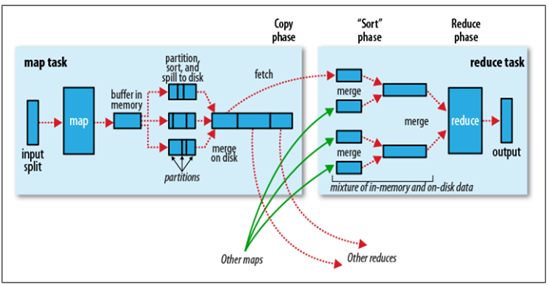
如果说以上是从物理实体的角度来讲解MapReduce的工作原理,那么以上便是从逻辑实体的角度来讲解MapReduce的工作原理,如下所示:
1. Map端的Shuffle
- Map函数开始产生输出时,并不是简单地把数据写到磁盘,因为频繁的磁盘操作会导致性能严重下降。它的处理过程更复杂,数据首先写到内存中的一个缓冲区,并做一些预排序,以提升效率;
- 每个MapTask都有一个用来写入输出数据的循环内存缓冲区(默认大小为100MB),当缓冲区中的数据量达到一个特定阈值时(默认是80%)系统将会启动一个后台线程把缓冲区中的内容写到磁盘(即spill阶段)。在写磁盘过程中,Map输出继续被写到缓冲区,但如果在此期间缓冲区被填满,那么Map就会阻塞直到写磁盘过程完成;
- 在写磁盘前,线程首先根据数据最终要传递到的Reducer把数据划分成相应的分区(partition)。在每个分区中,后台线程按Key进行排序(快速排序),如果有一个Combiner(即Mini Reducer)便会在排序后的输出上运行;
- 一旦内存缓冲区达到溢出写的阈值,就会创建一个溢出写文件,因此在MapTask完成其最后一个输出记录后,便会有多个溢出写文件。在在MapTask完成前,溢出写文件被合并成一个索引文件和数据文件(多路归并排序)(Sort阶段);
- 溢出写文件归并完毕后,Map将删除所有的临时溢出写文件,并告知TaskTracker任务已完成,只要其中一个MapTask完成,ReduceTask就开始复制它的输出(Copy阶段);
- Map的输出文件放置在运行MapTask的TaskTracker的本地磁盘上,它是运行ReduceTask的TaskTracker所需要的输入数据,但是Reduce输出不是这样的,它一般写到HDFS中(Reduce阶段)。
2. Reduce端的Shuffle
- Copy阶段:Reduce进程启动一些数据copy线程,通过HTTP方式请求MapTask所在的TaskTracker以获取输出文件。
- Merge阶段:将Map端复制过来的数据先放入内存缓冲区中,Merge有3种形式,分别是内存到内存,内存到磁盘,磁盘到磁盘。默认情况下第一种形式不启用,第二种Merge方式一直在运行(spill阶段)直到结束,然后启用第三种磁盘到磁盘的Merge方式生成最终的文件。
- Reduce阶段:最终文件可能存在于磁盘,也可能存在于内存中,但是默认情况下是位于磁盘中的。当Reduce的输入文件已定,整个Shuffle就结束了,然后就是Reduce执行,把结果放到HDFS中。
五. 其它
HDFS和MapReduce是Hadoop的基础架构。除了上述讲解之外,还有MapReduce容错机制,任务JVM重用,作业调度器等都还没有总结。彻底理解了MapReduce的工作原理之后就可以大量的MapReduce编程了,计划将Hadoop自带实例看完后,再研读《Mahout实战》,同步学习《Hadoop技术内幕:深入解析YARN架构设计与实现原理》,正式迈入Hadoop 2.x版本的大门。
参考文献:
[1] 《Hadoop权威指南》(第二版)
[2] 《Hadoop应用开发技术详解》
[3] Hadoop 0.18文档:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html
[4] WordCount源码剖析:http://blog.csdn.net/recommender_system/article/details/42029311
[5] 外部排序技术之多路归并排序:http://blog.chinaunix.net/uid-25324849-id-2182916.html
MapReduce程序的工作过程的更多相关文章
- hadoop平台上HDFS和MAPREDUCE的功能、工作原理和工作过程
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce ...
- 从零开始学习Hadoop--第2章 第一个MapReduce程序
1.Hadoop从头说 1.1 Google是一家做搜索的公司 做搜索是技术难度很高的活.首先要存储很多的数据,要把全球的大部分网页都抓下来,可想而知存储量有多大.然后,要能快速检索网页,用户输入几个 ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
- MapReduce程序(一)——wordCount
写在前面:WordCount的功能是统计输入文件中每个单词出现的次数.基本解决思路就是将文本内容切分成单词,将其中相同的单词聚集在一起,统计其数量作为该单词的出现次数输出. 1.MapReduce之w ...
- 在Hadoop上运行基于RMM中文分词算法的MapReduce程序
原文:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-count-on-hadoop/ 在Hadoop上运行基于RMM中文分词 ...
- hadoop开发MapReduce程序
准备工作: 1.设置HADOOP_HOME,指向hadoop安装目录 2.在window下,需要把hadoop/bin那个目录替换下,在网上搜一个对应版本的 3.如果还报org.apache.hado ...
- 第一个MapReduce程序——WordCount
通常我们在学习一门语言的时候,写的第一个程序就是Hello World.而在学习Hadoop时,我们要写的第一个程序就是词频统计WordCount程序. 一.MapReduce简介 1.1 MapRe ...
- 《CPU的工作过程》
本文转载自inter官方网址:https://software.intel.com/zh-cn/articles/book-Processor-Architecture_CPU_work_proces ...
- Nginx reopen reload作用及工作过程
http://www.iigrowing.cn/nginx-reopen-reload-zuo-yong-ji-gong-zuo-guo-cheng.html Nginx reopen reload作 ...
随机推荐
- linux嵌入式系统交叉开发环境
交叉开发的特点是使用交叉开发环境编译出目标机上可以运行的二进制程序. tool chain就是一整套的交叉开发工具,包括cross assembler.cross compiler. cross li ...
- mvn 编译错误java.lang.NoSuchMethodError: org.objectweb.asm.ClassWriter. <init>(Z)V
Spring+struts2 +hibernate3集成,在后台测试时报的错,报错的这句话: Exception in thread "main" java.lang.NoSuch ...
- UNIX网络编程读书笔记:字节操纵函数
#include <strings.h> void bzero(void *dest, size_t nbytes); void bcopy(const void *src, void * ...
- java泛型通配符?
转自:http://www.linuxidc.com/Linux/2013-10/90928.htm T 有类型 ? 未知类型 一.通配符的上界 既然知道List<Cat>并不是Lis ...
- react-router-dom Link search 传参
<Link> 和之前版本没太大区别,重点看下组件属性: to(string/object):要跳转的路径或地址: replace(bool):为 true 时,点击链接后将使用新地址替换掉 ...
- sublime配置
官网:http://www.sublimetext.com/3 下载:Windows 64 bit - also available as a portable version 安装插件:https: ...
- OpenERP7.0中非admin帐号新增其它用户问题
在OpenERP7.0中,通过admin新增了一个管理员帐号,然后登录管理员帐号,再新增其它用户时提示错误,系统提示对users没有create权限. 经测试了解,是因为安装了多公司模块后,在记录规则 ...
- [Swift A]-问号&感叹号
1.必须赋值的变量,或普通变量 var month:Int println("month:\(month)") 上面这2句代码会提示报错,因为没有赋值 2.再看看如下写法 var ...
- Android SDK 更新和下载慢怎么办?
博客搬家:因为各种原因,我如今的博客将首发于blog.mojijs.com, 能够百度搜索 "姜哥的墨迹技术博客" , 或者 点击这里 本文地址 http://blog.mojij ...
- js与jQuery方法对比
javascript与jQuery方法对比jquery对象转dom对象 // 方式一(推荐使用) $("input")[0] // 方式二 $("input" ...