python开发_pickle
pickle模块使用的数据格式是python专用的,并且不同版本不向后兼容,同时也不能被其他语言说识别。要和其他语言交互,可以使用内置的json包使用pickle模块你可以把Python对象直接保存到文件,而不需要把他们转化为字符串,也不用底层的文件访问操作把它们写入到一个二进制文件里。 pickle模块会创建一个python语言专用的二进制格式,你基本上不用考虑任何文件细节,它会帮你干净利落地完成读写独享操作,唯一需要的只是一个合法的文件句柄。
pickle模块中的两个主要函数是dump()和load()。dump()函数接受一个文件句柄和一个数据对象作为参数,把数据对象以特定的格式保存到给定的文件中。当我们使用load()函数从文件中取出已保存的对象时,pickle知道如何恢复这些对象到它们本来的格式。
dumps()函数执行和dump() 函数相同的序列化。取代接受流对象并将序列化后的数据保存到磁盘文件,这个函数简单的返回序列化的数据。
loads()函数执行和load() 函数一样的反序列化。取代接受一个流对象并去文件读取序列化后的数据,它接受包含序列化后的数据的str对象, 直接返回的对象。
cPickle是pickle得一个更快得C语言编译版本。
pickle和cPickle相当于java的序列化和反序列化操作
以上来源:http://www.2cto.com/kf/201009/74973.html
下面是python的API中的Example:
# Simple example presenting how persistent ID can be used to pickle
# external objects by reference. import pickle
import sqlite3
from collections import namedtuple # Simple class representing a record in our database.
MemoRecord = namedtuple("MemoRecord", "key, task") class DBPickler(pickle.Pickler): def persistent_id(self, obj):
# Instead of pickling MemoRecord as a regular class instance, we emit a
# persistent ID.
if isinstance(obj, MemoRecord):
# Here, our persistent ID is simply a tuple, containing a tag and a
# key, which refers to a specific record in the database.
return ("MemoRecord", obj.key)
else:
# If obj does not have a persistent ID, return None. This means obj
# needs to be pickled as usual.
return None class DBUnpickler(pickle.Unpickler): def __init__(self, file, connection):
super().__init__(file)
self.connection = connection def persistent_load(self, pid):
# This method is invoked whenever a persistent ID is encountered.
# Here, pid is the tuple returned by DBPickler.
cursor = self.connection.cursor()
type_tag, key_id = pid
if type_tag == "MemoRecord":
# Fetch the referenced record from the database and return it.
cursor.execute("SELECT * FROM memos WHERE key=?", (str(key_id),))
key, task = cursor.fetchone()
return MemoRecord(key, task)
else:
# Always raises an error if you cannot return the correct object.
# Otherwise, the unpickler will think None is the object referenced
# by the persistent ID.
raise pickle.UnpicklingError("unsupported persistent object") def main():
import io
import pprint # Initialize and populate our database.
conn = sqlite3.connect(":memory:")
cursor = conn.cursor()
cursor.execute("CREATE TABLE memos(key INTEGER PRIMARY KEY, task TEXT)")
tasks = (
'give food to fish',
'prepare group meeting',
'fight with a zebra',
)
for task in tasks:
cursor.execute("INSERT INTO memos VALUES(NULL, ?)", (task,)) # Fetch the records to be pickled.
cursor.execute("SELECT * FROM memos")
memos = [MemoRecord(key, task) for key, task in cursor]
# Save the records using our custom DBPickler.
file = io.BytesIO()
DBPickler(file).dump(memos) print("Pickled records:")
pprint.pprint(memos) # Update a record, just for good measure.
cursor.execute("UPDATE memos SET task='learn italian' WHERE key=1") # Load the records from the pickle data stream.
file.seek(0)
memos = DBUnpickler(file, conn).load() print("Unpickled records:")
pprint.pprint(memos) if __name__ == '__main__':
main()
运行效果:
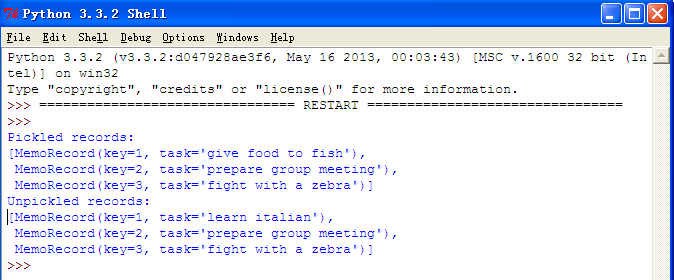
python开发_pickle的更多相关文章
- python开发环境搭建
虽然网上有很多python开发环境搭建的文章,不过重复造轮子还是要的,记录一下过程,方便自己以后配置,也方便正在学习中的同事配置他们的环境. 1.准备好安装包 1)上python官网下载python运 ...
- 【Machine Learning】Python开发工具:Anaconda+Sublime
Python开发工具:Anaconda+Sublime 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现 ...
- Python开发工具PyCharm个性化设置(图解)
Python开发工具PyCharm个性化设置,包括设置默认PyCharm解析器.设置缩进符为制表符.设置IDE皮肤主题等,大家参考使用吧. JetBrains PyCharm Pro 4.5.3 中文 ...
- Python黑帽编程1.2 基于VS Code构建Python开发环境
Python黑帽编程1.2 基于VS Code构建Python开发环境 0.1 本系列教程说明 本系列教程,采用的大纲母本为<Understanding Network Hacks Atta ...
- Eclipse中Python开发环境搭建
Eclipse中Python开发环境搭建 目 录 1.背景介绍 2.Python安装 3.插件PyDev安装 4.测试Demo演示 一.背景介绍 Eclipse是一款基于Java的可扩展开发平台. ...
- Python开发:环境搭建(python3、PyCharm)
Python开发:环境搭建(python3.PyCharm) python3版本安装 PyCharm使用(完全图解(最新经典))
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
随机推荐
- thinkphp 漂亮的分页样式
---恢复内容开始--- 首先:需要两个文件 page.class.php page.css 1.在TP原有的 page.class.php 文件稍作修改几条代码就可以了, 修改过的地方我会注释, 2 ...
- Callback2.0
Callback定义? a callback is a piece of executable code that is passed as an argument to other code, wh ...
- linux 查看内存和cpu占用比较多的进程
1.可以使用一下命令查使用内存最多的10个进程 ps -aux | sort -k4nr | head -n 102. 可以使用一下命令查使用CPU最多的10个进程 ps ...
- 135.Candy---贪心
题目链接 题目大意:分糖果,每个小朋友都有一个ratings值,且每个小朋友至少都要有一个糖果,而且每个小朋友的ratings值如果比左右邻舍的小朋友的ratings值高,则其糖果数量也比邻舍的小朋友 ...
- [写出来才有价值系列:node.js]node.js 02-,learnyounode
安装learnyounode: npm install g learnyounode 官方说直接 但是我发现不行,很慢几乎就是死在那里了 还好有淘宝的东西给我们用https://npm.taobao. ...
- centos7下vi的用法
vi编辑器是所有Unix及Linux系统下标准的编辑器,它的强大不逊色于任何最新的文本编辑器,这里只是简单地介绍一下它的用法和一小部分指令.由于对Unix及Linux系统的任何版本,vi编辑器是完全相 ...
- python基础(9)--递归、二叉算法、多维数组、正则表达式
1.递归 在函数内部,可以调其他函数,如果一个函数在内部调用它本身,这个函数就是递归函数.递归算法对解决一大类问题是十分有效的,它往往使算法的描述简洁而且易于裂解 递归算法解决问题的特点: 1)递归是 ...
- Funny Car Racing(最短路变形)
描述 There is a funny car racing in a city with n junctions and m directed roads. The funny part is: e ...
- 第六章:加载或保存JSON数据
加载或保存JSON数据 Knockout可以实现很复杂的客户端交互,但是几乎所有的web应用程序都要和服务器端交换数据(至少为了本地存储需要序列化数据),交换数据最方便的就是使用JSON格式 – 大多 ...
- 【WPF】RenderTransform和LayoutTransform
布局系统 在WPF中,许多绘图任务通过使用变换(transform)可以变得更加简单——变换是通过不加通告地切换形状或元素使用的坐标系统来改变形状或元素绘制方式的对象.在WPF中,变换的一些类大多继承 ...