sort-uniq-cut-join命令练习
Werkzeug 是一个WSGI工具包,也可以作为一个Web框架的底层库。
先从一份示例代码理解:
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return ['Hello World!']
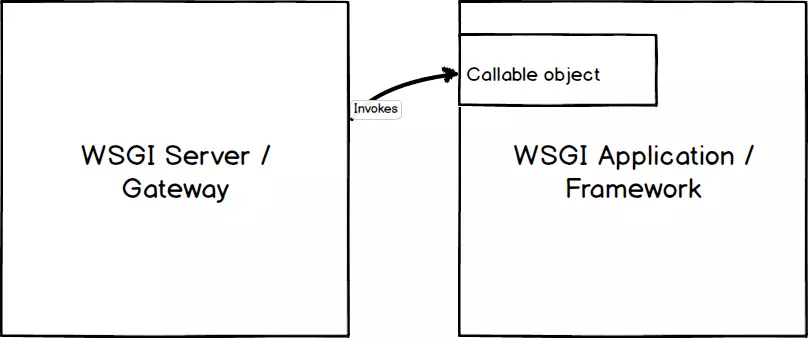
一个最基本的 WSGI 应用就是如上所示,定义了一个 application 函数(callable object),callable object(可调用对象) 包括: 一个函数、方法、类或一个实现了__call__的实例都可以用作应用程序对象。这个函数接受两个参数,分别是environ和start_response。
- environ是一个字典包含了CGI中的环境变量
- start_response也是一个callable,接受两个必须的参数,status(HTTP状态)和response_headers(响应消息的头)
通过回调函数(start_response)将响应状态和响应头返回给 server,同时返回响应正文(response body),响应正文是可迭代的、并包含了多个字符串。
Werkzeug
首先,先向大家介绍一下什么是 werkzeug,Werkzeug是一个WSGI工具包,他可以作为一个Web框架的底层库。这里稍微说一下, werkzeug 不是一个web服务器,也不是一个web框架,而是一个工具包,官方的介绍说是一个 WSGI 工具包,它可以作为一个 Web 框架的底层库,因为它封装好了很多 Web 框架的东西,例如 Request,Response 等等。
例如我最常用的 Flask 框架就是一 Werkzeug 为基础开发的,这也是我要解析一下 Werkzeug 底层的原因,因为我想知道 Flask 的实现逻辑以及底层控制。这篇文章没有涉及到 Flask 的相关内容,只是以 Werkzeug 创建一个简单的 Web 应用,然后以这个 Web 应用为例剖析请求的处理以及响应的产生过程。
下面我们以一个简短的例子开始,先看看怎么使用 werkzeug,然后再逐步刨析 werkzeug 的实现原理。
werkzeug 提供了 python web WSGI 开发相关的功能:
- 路由处理:如何根据请求 URL 找到对应的视图函数
- request 和 response 封装: 提供更好的方式处理request和生成response对象
- 自带的 WSGI server: 测试环境运行WSGI应用
具体创建一个 WSGI 应用请查看文档,后面会陆续提到Flask框架中使用到Werkzeug的数据结构。这里贴一些官方文档的例子,使用werkzeug创建一个web 应用:
import os
import redis
import urlparse
from werkzeug.wrappers import Request, Response
from werkzeug.routing import Map, Rule
from werkzeug.exceptions import HTTPException, NotFound
from werkzeug.wsgi import SharedDataMiddleware
from werkzeug.utils import redirect
from jinja2 import Environment, FileSystemLoader class Shortly(object):
"""
Shortly 是一个实际的 WSGI 应用,通过 __call__ 方法直接调 用 wsgi_app,
同时通过一个可选设置创建一个中间件,将static文件夹暴露给用户:
"""
def __init__(self, config):
self.redis = redis.Redis(config['redis_host'], config['redis_port']) def dispatch_request(self, request):
return Response('Hello World!') def wsgi_app(self, environ, start_response):
request = Request(environ)
response = self.dispatch_request(request)
return response(environ, start_response) def __call__(self, environ, start_response):
return self. wsgi_app(environ, start_response) def create_app(redis_host='localhost', redis_port=6379, with_static=True):
app = Shortly({
'redis_host': redis_host,
'redis_port': redis_port
})
if with_static:
app.wsgi_app = SharedDataMiddleware(app.wsgi_app, {
'/static': os.path.join(os.path.dirname(__file__), 'static')
})
return app if __name__ == '__main__':
from werkzeug.serving import run_simple
app = create_app()
run_simple('127.0.0.1', 5000, app, use_debugger=True, use_reloader=True)
__call__ 方法直接调用 wsgi_app 。这样做我们可以装饰 wsgi_app 调用中间件,就像我们在 create_app 函数中做的一样。 wsgi_app 实际上创建了一个 Request 对象,之后通过 dispatch_request 调用 Request 对象然后给 WSGI 应用返回一个 Response 对象。正如你看到的:无论是创建 Shortly 类,还是创建 Werkzeug Request 对象来执行 WSGI 接口。最终结果只是从 dispatch_request 方法返回另一个 WSGI 应用。这部分解释来源于官方文档的中文版。Flask---werkzeug请求、响应源码分析
from werkzeug.wrappers import Request, Response
from werkzeug.serving import run_simple #方式一
application1 = Response('Hello World application1!') #方式二
def application2(environ, start_response):
request = Request(environ)
response = Response("Hello %s!" % request.args.get('name', 'World!'))
return response(environ, start_response) #方式三
@Request.application
def hello(request):
return Response('Hello World Request!') if __name__ == '__main__':
# run_simple('localhost', 4000, application1) # run_simple('localhost', 4000, application2)
run_simple('localhost', 4000, hello)
我们在浏览器输入http://localhost:4000/就会得到response信息
接下来我们就简单的分析下,该模块的请求、响应流程
源码分析
我们首先werkzeug包下的__init__.py模块,看看初始化做了什么操作
all_by_module = {
'werkzeug.serving': ['run_simple'],
'werkzeug.wsgi': ['get_current_url', 'get_host', 'pop_path_info',
'peek_path_info', 'SharedDataMiddleware',
'DispatcherMiddleware', 'ClosingIterator', 'FileWrapper',
'make_line_iter', 'LimitedStream', 'responder',
'wrap_file', 'extract_path_info'],
'werkzeug.http': ['parse_etags', 'parse_date', 'http_date', 'cookie_date',
'parse_cache_control_header', 'is_resource_modified',
'parse_accept_header', 'parse_set_header', 'quote_etag',
'unquote_etag', 'generate_etag', 'dump_header',
'parse_list_header', 'parse_dict_header',
'parse_authorization_header',
'parse_www_authenticate_header', 'remove_entity_headers',
'is_entity_header', 'remove_hop_by_hop_headers',
'parse_options_header', 'dump_options_header',
'is_hop_by_hop_header', 'unquote_header_value',
'quote_header_value', 'HTTP_STATUS_CODES'],
'werkzeug.wrappers': ['BaseResponse', 'BaseRequest', 'Request', 'Response',
'AcceptMixin', 'ETagRequestMixin',
'ETagResponseMixin', 'ResponseStreamMixin',
'CommonResponseDescriptorsMixin', 'UserAgentMixin',
'AuthorizationMixin', 'WWWAuthenticateMixin',
'CommonRequestDescriptorsMixin'],
'werkzeug.security': ['generate_password_hash', 'check_password_hash'],
# the undocumented easteregg ;-)
'werkzeug._internal': ['_easteregg']
}
werkzeug->__init__.py
object_origins = {}
for module, items in iteritems(all_by_module):
for item in items:
object_origins[item] = module
ps:all_by_module 字典数据我删除了一部分
通过上述遍历循环字典,重新构造object_origins字典数据格式,该字典类型格式如下,我列举出来一些元素,以下是键值对形式
# BaseResponse - --- werkzeug.wrappers
# BaseRequest - --- werkzeug.wrappers
# Request - --- werkzeug.wrappers
# Response - --- werkzeug.wrappers
该字典的键是werkzeug下的某模块中的函数、方法,值是werkzeug下的某模块中
我们回头看我们的demo示例,在文件起始处我们引入了from werkzeug.serving import run_simple
我们跟踪代码去看下serving.py模块下的run_simple函数
def run_simple(hostname, port, application, use_reloader=False,
use_debugger=False, use_evalex=True,
extra_files=None, reloader_interval=1,
reloader_type='auto', threaded=False,
processes=1, request_handler=None, static_files=None,
passthrough_errors=False, ssl_context=None)
简单说下参数的意思
hostname:应用程序的主机
port:端口
application:WSGI应用程序
use_reloader:如果程序代码修改,是否需要自动启动服务
use_debugger:程序是否要使用工具和调试系统
use_evalex:应用是否开启异常评估
extra_files:重载器应该查看的文件列表附加到模块。例如配置文件夹
reloader_interval:秒重载器的间隔
reloader_type:重载器的类型
threaded:进程是否处理单线程的每次请求
processes:如果大于1,则在新进程中处理每个请求。达到这个最大并发进程数
request_handler:可以自定义替换BaseHTTPRequestHandler
static_files:静态文件路径的列表或DICT
passthrough_errors:将此设置为“真”以禁用错误捕获。这意味着服务器会因错误而死亡
ssl_context:如何进行传输数据加密,可以设置的环境
use_reloader我们按false来举例,run_simple函数中,通过if use_reloader判断,会执行inner()方法,
def inner():
try:
fd = int(os.environ['WERKZEUG_SERVER_FD'])
except (LookupError, ValueError):
fd = None
srv = make_server(hostname, port, application, threaded,
processes, request_handler,
passthrough_errors, ssl_context,
fd=fd)
if fd is None:
log_startup(srv.socket)
srv.serve_forever()
通过make_server方法,跟进我们在初始化__init__中的参数,去构造server服务
def make_server(host=None, port=None, app=None, threaded=False, processes=1,
request_handler=None, passthrough_errors=False,
ssl_context=None, fd=None):
"""Create a new server instance that is either threaded, or forks
or just processes one request after another.
"""
if threaded and processes > 1:
raise ValueError("cannot have a multithreaded and "
"multi process server.")
elif threaded:
return ThreadedWSGIServer(host, port, app, request_handler,
passthrough_errors, ssl_context, fd=fd)
elif processes > 1:
return ForkingWSGIServer(host, port, app, processes, request_handler,
passthrough_errors, ssl_context, fd=fd)
else:
return BaseWSGIServer(host, port, app, request_handler,
passthrough_errors, ssl_context, fd=fd)
然后在inner方法中,srv.serve_forever()是服务运行起来
我们看下我们的示例中,最简单那个例子
application1 = Response('Hello World application1!')
为什么设置run_simple('localhost', 4000, application1),当接受请求时,为什么会执行application1的对象内方法,并且返回给浏览器
因为所有的 python web 框架都要遵循 WSGI 协议,WSGI 中有一个非常重要的概念:每个 python web 应用都是一个可调用(callable)的对象,要运行 web 应用,必须有 web server,在werkzeug中提供了 WSGIServer,
Server 和 Application 之间怎么通信,就是 WSGI 的功能
wsgi有两方,服务器方 和 应用程序
①服务器方:其调用应用程序,给应用程序提供(环境信息)和(回调函数), 这个回调函数是用来将应用程序设置的http header和status等信息传递给服务器方.
②应用程序:用来生成返回的header,body和status,以便返回给服务器方。
所以在我们示例代码中,当run_simple('localhost', 4000, hello)执行后,当http://localhost:4000/请求时,就会触发application1 = Response('Hello World application1!')
我们接下来看下werkzeug.wrappers.py模块下的Response类
class Response(BaseResponse, ETagResponseMixin, ResponseStreamMixin,
CommonResponseDescriptorsMixin,
WWWAuthenticateMixin):
该类是多重继承类,这里主要看下BaseResponse,先看下初始方法
def __init__(self, response=None, status=None, headers=None,
mimetype=None, content_type=None, direct_passthrough=False):
if isinstance(headers, Headers):
self.headers = headers
elif not headers:
self.headers = Headers()
else:
self.headers = Headers(headers) if content_type is None:
if mimetype is None and 'content-type' not in self.headers:
mimetype = self.default_mimetype
if mimetype is not None:
mimetype = get_content_type(mimetype, self.charset)
content_type = mimetype
if content_type is not None:
self.headers['Content-Type'] = content_type
if status is None:
status = self.default_status
if isinstance(status, integer_types):
self.status_code = status
else:
self.status = status self.direct_passthrough = direct_passthrough
self._on_close = [] # we set the response after the headers so that if a class changes
# the charset attribute, the data is set in the correct charset.
if response is None:
self.response = []
elif isinstance(response, (text_type, bytes, bytearray)):
self.set_data(response)
else:
self.response = response
BaseResponse->__init__
在BaseResponse类__init__初始方法中,我们定义了返回的Headers、content_type、状态码status,最后通过self.set_data(response),跟踪代码如下:
def set_data(self, value):
if isinstance(value, text_type):
value = value.encode(self.charset)
else:
value = bytes(value)
self.response = [value]
if self.automatically_set_content_length:
self.headers['Content-Length'] = str(len(value))
将我们示例中的application1 = Response('Hello World application1!')参数字符串,进行bytes类型转换进行传输,
然后执行对象(),在调用__call__方法,
def __call__(self, environ, start_response):
print(start_response)
app_iter, status, headers = self.get_wsgi_response(environ)
start_response(status, headers)
return app_iter
这里要先介绍一个environ参数,
在我们的示例中有3种方法来实现,而我利用了最简单的方式1去讲解,然而方式1参数中没有涉及到environ参数
#方式一
application1 = Response('Hello World application1!') #方式二
def application2(environ, start_response):
request = Request(environ)
response = Response("Hello %s!" % request.args.get('name', 'World!'))
return response(environ, start_response) #方式三
@Request.application
def hello(request):
return Response('Hello World Request!')
以上方式2中涉及到了environ,其实这个environ参数是包含了请求的所有信息,
让我们在看下__call__方法中, app_iter, status, headers = self.get_wsgi_response(environ)输出
通过请求系列参数,获取最后要返回的get_wsgi_response,输出如下:
<werkzeug.wsgi.ClosingIterator object at 0x0589C0B0> --- 200 OK --- [('Content-Type'\\\省略]
然后在start_response(status, headers)代码中,start_response 是 application 处理完之后需要调用的函数,参数是状态码、响应头部还有错误信息
让我们来看下start_response输出,
<function WSGIRequestHandler.run_wsgi.<locals>.start_response at 0x05A32108>
跟踪代码如下start_response:
def start_response(status, response_headers, exc_info=None):
if exc_info:
try:
if headers_sent:
reraise(*exc_info)
finally:
exc_info = None
elif headers_set:
raise AssertionError('Headers already set')
headers_set[:] = [status, response_headers]
return write
start_response返回write方法,然后跟踪该方法
def write(data):
assert headers_set, 'write() before start_response'
if not headers_sent:
status, response_headers = headers_sent[:] = headers_set
try:
code, msg = status.split(None, 1)
except ValueError:
code, msg = status, ""
code = int(code)
self.send_response(code, msg)
header_keys = set()
for key, value in response_headers:
self.send_header(key, value)
key = key.lower()
header_keys.add(key)
if not ('content-length' in header_keys or
environ['REQUEST_METHOD'] == 'HEAD' or
code < 200 or code in (204, 304)):
self.close_connection = True
self.send_header('Connection', 'close')
if 'server' not in header_keys:
self.send_header('Server', self.version_string())
if 'date' not in header_keys:
self.send_header('Date', self.date_time_string())
self.end_headers() assert isinstance(data, bytes), 'applications must write bytes'
self.wfile.write(data)
self.wfile.flush()
最后就输出到浏览器
以上就是简单的请求、响应流程
Flask示例
我们在Flask中会按着如下使用
from flask import Flask
app = Flask(__name__)
@app.route('/index')
def index():
return 'Hello World'
if __name__ == '__main__':
app.run() # run_simple(host,port,app)
跟进run方法
def run(self, host=None, port=None, debug=None, **options):
from werkzeug.serving import run_simple
if host is None:
host = '127.0.0.1'
if port is None:
server_name = self.config['SERVER_NAME']
if server_name and ':' in server_name:
port = int(server_name.rsplit(':', 1)[1])
else:
port = 5000
if debug is not None:
self.debug = bool(debug)
options.setdefault('use_reloader', self.debug)
options.setdefault('use_debugger', self.debug)
try:
run_simple(host, port, self, **options)
finally:
self._got_first_request = False
我们看到最后依然是执行的run_simple(host, port, self, **options),也就是werkzeug.serving.py下的run_simple方法
sort-uniq-cut-join命令练习的更多相关文章
- linux sort,uniq,cut,wc命令详解
linux sort,uniq,cut,wc命令详解 sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些 ...
- (转)linux sort,uniq,cut,wc命令详解
linux sort,uniq,cut,wc命令详解 sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些 ...
- [转]linux sort,uniq,cut,wc命令详解
sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序. sort语法 ...
- Linux之 sort,uniq,cut,wc命令详解
sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序. sort语法 ...
- Ubuntu 14.10 下sort,uniq,cut,wc命令详解
sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序. sort语法 ...
- linux sort,uniq,cut,wc命令详解 (转)
sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序. sort语法 ...
- sort,uniq,cut,wc命令详解
sortsort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序. sort语法 s ...
- (F) linux sort,uniq,cut,wc命令详解
F:http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2858385.html sort sort 命令对 File 参数指定的文件中的行排序,并 ...
- 【转帖】linux sort,uniq,cut,wc,tr,xargs命令详解
linux sort,uniq,cut,wc,tr,xargs命令详解 http://embeddedlinux.org.cn/emb-linux/entry-level/201607/21-5550 ...
- linux sort,uniq,cut,wc,tr命令详解
sort是在Linux里非常常用的一个命令,对指定文件进行排序.去除重复的行 sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sor ...
随机推荐
- Android -- 重写BaseAdapter以及对ListView的优化
背景 对于ListView.GridView.Gallery.Spinner等等,它是它们的适配器,直接继承自接口类Adapter的,使用BaseAdapter时需要重写很多方法,其中最重要的当属ge ...
- 【Networking】Libevent客户端例子
[原]Libevent客户端例子 时间 -- :: luotuo44的专栏 原文 http://blog.csdn.net/luotuo44/article/details/34416429 主题 l ...
- Thinkphp学习笔记-模板赋值
如果要在模板中输出变量,必须在在控制器中把变量传递给模板,系统提供了assign方法对模板变量赋值,无论何种变量类型都统一使用assign赋值. $this->assign('name',$va ...
- [Firebase] 1. AngularFire, $save, $add and $remove, Forge
Basic angularFire options: $save, $add and $remove. The way connect firebase: var app = angular.modu ...
- C++ 中特殊的用法
1.反斜杠 a.转义字符 b.强制换行,当一行代码很长时,在这一行中间加上反斜杠,分成两行,反斜杠前后不能有空格.在预编译的的时候,会合成一行. 2.String^ 表明String是一个托管类型的指 ...
- python xlrd简单读取excel
import xlrd #打开文件 book = xlrd.open_workbook ('Status.xlsx') #获取数据表 table1 = book.sheets()[0] table2 ...
- Linux 内存泄露小结
本文仅限记录自己的一次 内存泄露追踪小记. 可能并不十分适用与大家的情况.而且方法也并不是很smart.仅做记录,能提供个思路更好. 一. 要问调试程序遇到什么问题最头疼, 内存泄露肯定 ...
- Java中字符串相等与大小比較
在C++中,两个字符串比較的代码能够为: (string1==string2) 但在java中,这个代码即使在两个字符串全然同样的情况下也会返回false Java中必须使用string1.equal ...
- ionic的加载功能
下面是代码(黄色背景的是加载功能的代码): <html ng-app="ionicApp"> <head> <meta charset="u ...
- Visual studio中后期生成事件命令使用
在做项目是总要把发布后的一些dll拷贝的根网站的bin目录下,为了避免每次都需要手动拷贝可以在 项目的生成事件中写入bat命令,下面的命令只在项目使用的发布配置时执行拷贝, (在生成->配置管理 ...