一致性哈希与java实现
一致性哈希算法是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
因此,引入了一致性哈希算法:
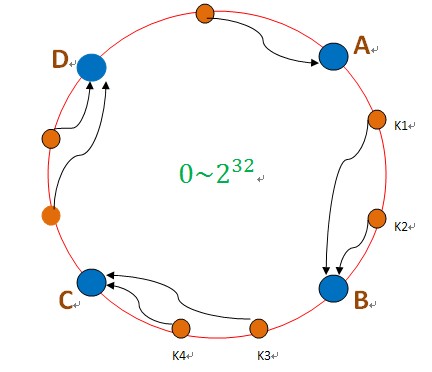
把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如k1对应到了图中所示的位置,然后沿顺时针找到一个机器节点B,将k1存储到B这个节点中。
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
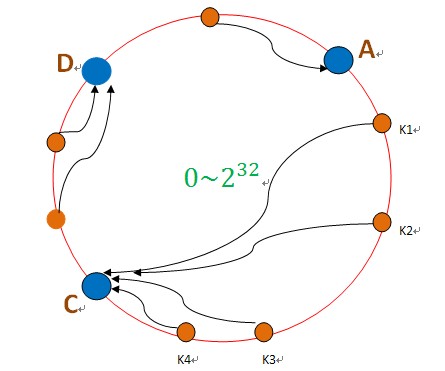
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
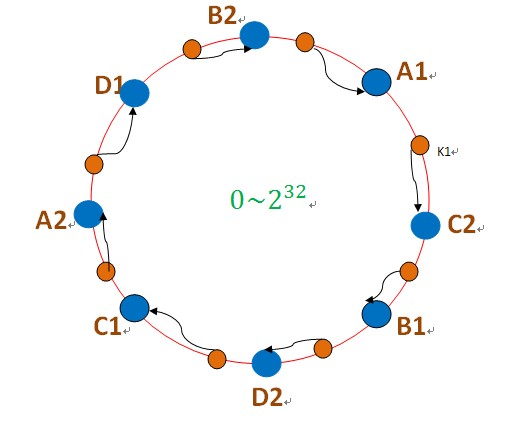
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。







Java实现:
- public class Shard<S> { // S类封装了机器节点的信息 ,如name、password、ip、port等
- private TreeMap<Long, S> nodes; // 虚拟节点
- private List<S> shards; // 真实机器节点
- private final int NODE_NUM = 100; // 每个机器节点关联的虚拟节点个数
- public Shard(List<S> shards) {
- super();
- this.shards = shards;
- init();
- }
- private void init() { // 初始化一致性hash环
- nodes = new TreeMap<Long, S>();
- for (int i = 0; i != shards.size(); ++i) { // 每个真实机器节点都需要关联虚拟节点
- final S shardInfo = shards.get(i);
- for (int n = 0; n < NODE_NUM; n++)
- // 一个真实机器节点关联NODE_NUM个虚拟节点
- nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
- }
- }
- public S getShardInfo(String key) {
- SortedMap<Long, S> tail = nodes.tailMap(hash(key)); // 沿环的顺时针找到一个虚拟节点
- if (tail.size() == 0) {
- return nodes.get(nodes.firstKey());
- }
- return tail.get(tail.firstKey()); // 返回该虚拟节点对应的真实机器节点的信息
- }
- /**
- * MurMurHash算法,是非加密HASH算法,性能很高,
- * 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免)
- * 等HASH算法要快很多,而且据说这个算法的碰撞率很低.
- * http://murmurhash.googlepages.com/
- */
- private Long hash(String key) {
- ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
- int seed = 0x1234ABCD;
- ByteOrder byteOrder = buf.order();
- buf.order(ByteOrder.LITTLE_ENDIAN);
- long m = 0xc6a4a7935bd1e995L;
- int r = 47;
- long h = seed ^ (buf.remaining() * m);
- long k;
- while (buf.remaining() >= 8) {
- k = buf.getLong();
- k *= m;
- k ^= k >>> r;
- k *= m;
- h ^= k;
- h *= m;
- }
- if (buf.remaining() > 0) {
- ByteBuffer finish = ByteBuffer.allocate(8).order(
- ByteOrder.LITTLE_ENDIAN);
- // for big-endian version, do this first:
- // finish.position(8-buf.remaining());
- finish.put(buf).rewind();
- h ^= finish.getLong();
- h *= m;
- }
- h ^= h >>> r;
- h *= m;
- h ^= h >>> r;
- buf.order(byteOrder);
- return h;
- }
- }
一致性哈希与java实现的更多相关文章
- [转载] 应用于负载均衡的一致性哈希及java实现
转载自http://blog.csdn.net/haitao111313/article/details/7537799 这几天看了几遍一致性哈希的文章,但是都没有比较完整的实现,因此试着实现了一下, ...
- Java_一致性哈希算法与Java实现
摘自:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 一致性哈希算法学习及JAVA代码实现分析
1,对于待存储的海量数据,如何将它们分配到各个机器中去?---数据分片与路由 当数据量很大时,通过改善单机硬件资源的纵向扩充方式来存储数据变得越来越不适用,而通过增加机器数目来获得水平横向扩展的方式则 ...
- 一致性哈希算法原理及Java实现
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简 单 ...
- 一致性哈希java实现
值得注意的点 哈希函数的选择 murmur哈希函数 该函数是非加密型哈希,性能高,且发生哈希碰撞的概率据说很低 md5 SHA 可以选择guava包,提供了丰富的哈希函数的API 支持虚拟节点+加权, ...
- 一致性哈希算法原理、避免数据热点方法及Java实现
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简 单 ...
- 一致性哈希算法与Java实现
原文:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 一致性哈希Java源码分析
首次接触一致性哈希是在学习memcached的时候,为了解决分布式服务器的负载均衡或者说选路的问题,一致性哈希算法不仅能够使memcached服务器被选中的概率(数据分布)更加均匀,而且使得服务器的增 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
随机推荐
- Jenkins学习之——(1)Jenkins的安装与配置
1.最近公司要求做自动化部署,于是自学了jenkins.这个参考书很少,网上的文章也讲得很模糊,于是打算把自己学习东西记下来,希望对大家有所帮助. 一.jenkins的安装 到jenkins官网(ht ...
- iOS 使用GitHub托管代码(github desktop使用)
iOS 使用GitHub托管代码 代码托管 1.首先得有一个GitHub的账号,没有的话就去https://github.com注册一个吧. 2.下载GitHub Mac客户端:http://mac. ...
- [JavaScript] 判断键盘同时按某些键时执行操作。
前言:之前知乎上看到过一个介绍国外炫酷网站的,其中一个敏感网站用同时按住"q.a.p.l" 才能观看视频 放手则立即强制停止 (手动斜眼).这个功能的实际用处,我认为是可以在做一些 ...
- static静态类与非静态类的区别
static静态类与非静态类的区别 1.在非静态类中可以有实例成员也可以有静态成员 2.在调用的时候需要使用对像名.实例成员调用(先要实例化,如person ps=new person(); ps. ...
- Oracle—用户管理的备份(二)
在用户管理的备份(一)中(详见:Oracle—用户管理的备份)对用户管理备份几种情况进行了说明:接下来说明几种特别情况和DBverify的使用. 一.如果在表空间在备份模式下,主机发生了异常关闭,会出 ...
- pcduino连接OTG登录远程桌面
由于没有HDMI的显示屏,为了方便起见,使用了pcduino的OTG来连接到虚拟桌面,可是发现连接上虚拟桌面后,电脑的外网就断了.下面这个方法让你既可以连接到pcduino,又可以让电脑能上外网. 打 ...
- GridView 中Item项居中显示
直接在GridView中设置 android:gravity="center"这个属性是不起作用的.要在你adapter中的布局文件中设 置android:layout_gravi ...
- jquery.mmenu
http://mmenu.frebsite.nl/ 左右滑动效果 http://blog.sina.com.cn/s/blog_6a0a183f0100zsfk.html js的左右滑动触屏事件,主要 ...
- 使用脚本管理IIS
参考资料https://technet.microsoft.com/zh-cn/library/cc779108(WS.10).aspxhttps://technet.microsoft.com/zh ...
- python sqlite3使用
python sqlite3文档地址:http://docs.python.org/2/library/sqlite3.html The sqlite3 module was written by G ...