HDFS写入和读取流程
HDFS写入和读取流程
一、HDFS
HDFS全称是Hadoop Distributed System。HDFS是为以流的方式存取大文件而设计的。适用于几百MB,GB以及TB,并写一次读多次的场合。而对于低延时数据访问、大量小文件、同时写和任意的文件修改,则并不是十分适合。
目前HDFS支持的使用接口除了Java的还有,Thrift、C、FUSE、WebDAV、HTTP等。HDFS是以block-sized chunk组织其文件内容的,默认的block大小为64MB,对于不足64MB的文件,其会占用一个block,但实际上不用占用实际硬盘上的64MB,这可以说是HDFS是在文件系统之上架设的一个中间层。之所以将默认的block大小设置为64MB这么大,是因为block-sized对于文件定位很有帮助,同时大文件更使传输的时间远大于文件寻找的时间,这样可以最大化地减少文件定位的时间在整个文件获取总时间中的比例 。
二、HDFS的体系结构
构成HDFS主要是Namenode(master)和一系列的Datanode(workers)。Namenode是管理HDFS的目录树和相关的文件元数据,这些信息是以"namespace image"和"edit log"两个文件形式存放在本地磁盘,但是这些文件是在HDFS每次重启的时候重新构造出来的。Datanode则是存取文件实际内容的节点,Datanodes会定时地将block的列表汇报给Namenode。
由于Namenode是元数据存放的节点,如果Namenode挂了那么HDFS就没法正常运行,因此一般使用将元数据持久存储在本地或远程的机器上,或者使用secondary namenode来定期同步Namenode的元数据信息,secondary namenode有点类似于MySQL的Master/Salves中的Slave,"edit log"就类似"bin log"。如果Namenode出现了故障,一般会将原Namenode中持久化的元数据拷贝到secondary namenode中,使secondary namenode作为新的Namenode运行起来。
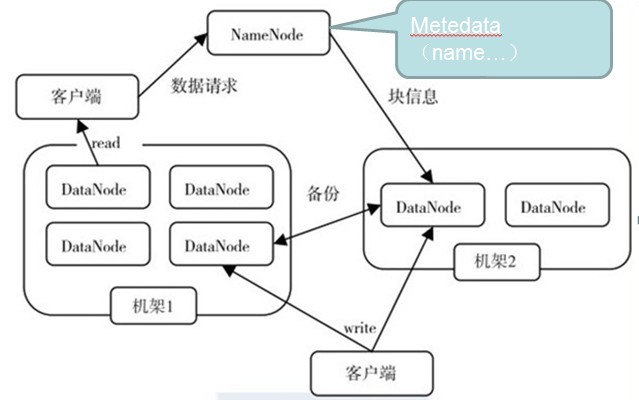
三、读写流程
GFS论文提到的文件读取简单流程:
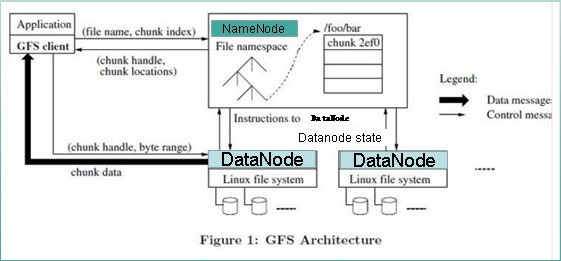
详细流程:
文件读取的过程如下:
- 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
- Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的DataNode地址;
- 客户端开发库Client会选取离客户端最接近的DataNode来读取block;如果客户端本身就是DataNode,那么将从本地直接获取数据.
- 读取完当前block的数据后,关闭与当前的DataNode连接,并为读取下一个block寻找最佳的DataNode;
- 当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
- 读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
GFS论文提到的写入文件简单流程:
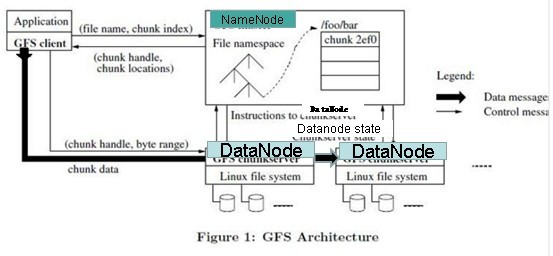
详细流程:
写入文件的过程比读取较为复杂:
- 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
- Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
- 当客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以数据队列"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
- 开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
- 最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
- 如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。
HDFS写入和读取流程的更多相关文章
- 8.hbase写入流程和读取流程
1 hbase写入流程 hbase中无论是新增数据还是修改已有行,其内部流程都是一样的,hbase执行写入时会写到两个地方,write-ahead log 简称wal 也叫hlog 预写式日志 和 M ...
- HDFS 03 - 你能说说 HDFS 的写入和读取过程吗?
目录 1 - HDFS 文件的写入 1.1 写入过程 1.2 写入异常时的处理 1.3 写入的一致性 2 - HDFS 文件的读取 2.1 读取过程 2.2 读取异常时的处理 版权声明 1 - HDF ...
- 从HDFS的写入和读取中,我发现了点东西
摘要:从HDFS的写入和读取中,我们能学习到什么? 本文分享自华为云社区<从HDFS的写入和读取中,我们能学习到什么>,作者: breakDawn . 最近开发过程涉及了一些和文件读取有关 ...
- HDFS追本溯源:HDFS操作的逻辑流程与源码解析
本文主要介绍5个典型的HDFS流程,这些流程充分体现了HDFS实体间IPC接口和stream接口之间的配合. 1. Client和NN Client到NN有大量的元数据操作,比如修改文件名,在给定目录 ...
- hadoop学习笔记(六):HDFS文件的读写流程
一.HDFS读取文件流程: 详解读取流程: Client调用FileSystem.open()方法: 1 FileSystem通过RPC与NN通信,NN返回该文件的部分或全部block列表(含有blo ...
- hadoop学习笔记(三):hdfs体系结构和读写流程(转)
原文:https://www.cnblogs.com/codeOfLife/p/5375120.html 目录 HDFS 是做什么的 HDFS 从何而来 为什么选择 HDFS 存储数据 HDFS 如何 ...
- Hadoop(8)-HDFS的读写数据流程以及机架感知
1. HDFS的写数据流程 1.客户端通过fs模块向NameNode申请文件上传,NameNode检查请求是否合法,如用户权限,目标文件是否已存在,父目录是否存在等等 2.NameNode返回是否可以 ...
- 大数据学习笔记——HDFS写入过程源码分析(2)
HDFS写入过程注释解读 & 源码分析 此篇博客承接上一篇未讲完的内容,将会着重分析一下在Namenode获取到元数据后,具体是如何向datanode节点写入真实的数据的 1. 框架图展示 在 ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
随机推荐
- TCP状态转换机说明
建立一个 TCP 连接TCP 是一个面向连接的协议,无论哪一方向另一方发送数据之前,都必须先在双方之间建立一条连接.本节将详细讨论一个TCP 连接是如何建立的以及通信结束后是如何终止的. TCP使用三 ...
- python 序列(list,tuple,str)基本操作
添加元素: mylist.append() mylist.extend([1, 2]) mylist.insert(1, "pos") 删除元素: mylist.remove(va ...
- c/c++ double的数字 转成字符串后 可以有效的避免精度要求不高的数
char n[100]; sprintf(n,"%lf",db);
- WINFORM Tootip使用小结
toolTip1.Active = true; //激活工具提示,只有激活才会显示提示 toolTip1.IsBalloon = true; //toolTip以气泡形式出现 toolTip ...
- iOS:ABPeoplePickerNavigationController系统通讯录使用
昨天因项目需求要访问系统通讯录获取电话号码,于是乎从一无所知,开始倒腾,倒腾了一下午,总算了弄好了.写这边博客是为了记录一下,自己下一次弄的时候就别在出错了.同时,有和我一样的菜鸟能够避免走一下弯路. ...
- 移动端纯原生JS不依赖ajax后台服务器实现省市县三级联动
最近好多天没有更新文章,是因为公司的项目忙的不行.今天有点时间,就突然想起在移动端项目中遇到三级联动的问题,网上查了很多资料,都是依赖各种插件,或者晦涩难于理解.于是,自己决定写一个出来. 当然,没有 ...
- BZOJ 3224: Tyvj 1728 普通平衡树(BST)
treap,算是模板题了...我中间还一次交错题... -------------------------------------------------------------------- #in ...
- [NOIP2012提高组] CODEVS 1200 同余方程(扩展欧几里德算法)
数论题..所有数论对我来说都很恶心..不想再说什么了.. ------------------------------------------------ #include<iostream&g ...
- javascript实现的功能--二级联动
<head> <meta http-equiv="Content-Type" content="text/html;charset=UTF-8" ...
- Java算法——O(n)查询数列中出现超过半数的元素
主要思想: 相邻元素两两比较,如果相同存入新数组,不同二者都删除.如果 某数出现次数超高n/2,则最后剩下的1元素为所求. public static int findMostElem(final A ...