stl vector、红黑树、set、multiset、map、multimap、迭代器失效、哈希表(hash_table)、hashset、hashmap、unordered_map、list
stl:即标准模板库,该库包含了诸多在计算机科学领域里所常用的基本数据结构和基本算法
六大组件:
容器、迭代器、算法、仿函数、空间配置器、迭代适配器
迭代器:迭代器(iterator)是一种抽象的设计理念,通过迭代器可以在不了解容器内部原理的情况下遍历容器。除此之外,STL中迭代器一个最重要的作用就是作为容器(vector,list等)与STL算法的粘结剂,只要容器提供迭代器的接口,同一套算法代码可以利用在完全不同的容器中,这是抽象思想的经典应用。迭代器是STL中行为类似指针的设计模式,它可以提供了一种对容器中的对象的访问方法。
Vector是顺序容器,Map是关联容器,Set是关联容器
和顺序容器不同,关联容器是通过键值对的方式存储数据的,可以通过键来读取数据。关联容器的优点是:它提供了对元素的快速访问。例如(最大匹配分词时,查字典效率更高)
所有容器的底层实现总结:https://blog.csdn.net/single_wolf_wolf/article/details/52854015
vector:
简单理解,就是vector是利用上述三个指针来表示的:
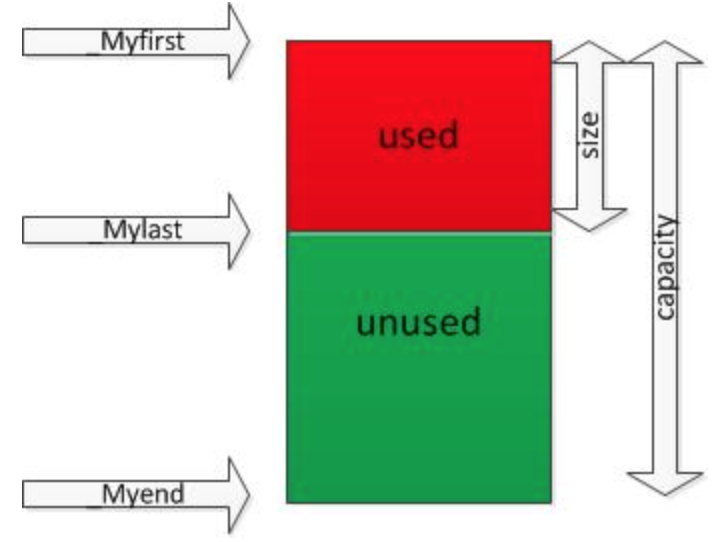
vector简单的讲就是一个动态的数组,里面有一个指针指向一片连续的内存空间,当空间装不下的时候会自动申请一片更大的空间(空间配置器)将原来的数据拷贝到新的空间,然后就会释放旧的空间。当删除的时候空间并不会被释放只是清空了里面的数据。因此,vector的运用对于内存的合理利用与运用的灵活性有很大的帮助,我们不必害怕空间不足而一开始就开辟一块很大的内存。
1.vector与数组array:array分配的空间是静态的,分配之后不能被改变,如果要增容的话,就要把数据搬到新的数组里面,然后再把原来的空间释放掉还给操作系统;
vector动态分配存储空间,在堆上分配内存,会自动重分配(扩展)空间
在一般情况下,其访问速度同一般数组,只有在重新分配发生时,其性能才会下降。它的内部使用allocator类进行内存管理,程序员不需要自己操作内存。
2.vector如何扩展内存:vector内存用完了,会以当前size大小重新申请2*size的内存,但并不是在原有的空间上持续增加成新的空间(无法保证原空间的后面还有可供配置的空间),而是以原大小的两倍另外配置一块较大的空间,然后把原来的元素复制过去,把新元素插上,然后释放原来的内存。这个大大影响了vector的效率,并且,由于vector 空间的重新配置,导致旧vector的所有迭代器都失效了。(内存为0的时候申请1,之后都是2倍)
3.使用capacity看当前保留的内存,使用swap来减少它使用的内存,clear只是清空vector的元素,不能释放内存
4.性能的优缺点:优点:它拥有一段连续的内存空间,并且起始地址不变,因此它能非常好的支持随即存取,即[]操作符,时间复杂度O(1)
缺点:1.它的内存空间是连续的,所以在中间进行插入和删除会需要移动内存,如果你的元素是结构或是类,那么移动的同时还会进行构造和析构操作,所以性能不高 (最好将结构或类的指针放入vector中,而不是结构或类本身,这样可以避免移动时的构造与析构);
2.另外,当该数组后的内存空间不够时,需要重新申请一块足够大的内存并进行内存的拷贝,这些都大大影响了vector的效率。
所以vector常用来保存需要经常进行随机访问的内容,并且不需要经常对中间元素进行添加删除操作。使用vector的时候需要注意内存的使用,如果频繁地进行内存的重新分配,会导致效率低下。
例子:
#include <iostream>
#include <vector>
using namespace std; int main()
{
vector<int> v; //初始时无元素,容量为0
cout << v.capacity() << endl;
v.push_back() ; //容量不够,分配1个元素内存
cout << v.capacity() << endl;
v.push_back(); //容量不够,分配2个元素内存
cout << v.capacity() << endl;
v.push_back(); //容量不够,分配4个元素内存
cout << v.capacity() << endl;
v.push_back();
v.push_back(); //容量不够,分配8个元素内存
cout << v.capacity() << endl;
v.push_back();
v.push_back();
v.push_back();
v.push_back(); //容量不够,分配16个元素内存
cout << v.capacity() << endl; return ;
}
注意:vector的size()和capacity()是不同的,前者表示数组中元素的多少,后者表示数组有多大的容量
reserve和resize区别: 两个什么时候使用呢?
reserve函数:
void reserve(size_type size);
reserve( )函数为当前vector预留至少能容纳size个元素的空间。(实际空间可能大于size)
resize函数
void resize(size_type size,TYPE val);resize( )函数改变当前vector的大小为size,且对新创建的元素赋值val
最根本的:reserve扩充capacity,resize扩充size
reserve:预留一定的空间
1.reserve是直接扩充到已经确定的大小,可以减少多次开辟、释放空间的问题,就可以提高效率,其次还可以减少多次要拷贝数据的问题。
2.reserve只是保证vector中的空间大小(capacity)最少达到参数所指定的大小n,只有当所申请的容量大于vector的当前容量时才会重新为vector分配存储空间,小于当前容量则没有影响
3.在区间[0,n]的范围内,如果下标是index,vector[index]有可能是合法的,也有可能是非法的,具体视情况而定。
4.reserve方法对于vector元素大小没有任何影响,不创建对象。
resize: 重新分配大小
1.若要开辟的空间的size大于原来的size,那么resize之后要存放的数据就放在原size后的位置上,使得vector的大小变为n,在这里,如果为resize方法指定了第二个参数,则会把后插入的元素值初始化为该指定值,如果没有为resize指定第二个参数,则会把新插入的元素初始化为默认的初始值
2.如果resize所指定的n不仅大于vector中当前的元素数量,还大于vector当前的capacity容量值时,则会自动为vector重新分配存储空间
3.若要开辟的空间小于原来的size,保留前n个数据,会删除vector中多于n的元素,使vector得大小变为n
为了实现resize的语义,resize的接口做了两个保证:
1、保证区间[0, newsize]范围内的数据是有效的,下标index在这个区间内的话,那么vector[index]就是有效的。
2、保证区间[0, newsize]范围外的数据是无效的,下标index在这个区间外的话,那么vector[index]就是无效的。
https://blog.csdn.net/ypt523/article/details/79651084
二叉搜索树(二叉查找树、二叉排序树) --- avl(平衡二叉搜索树) --- 平衡二叉树
中序遍历
演进过程:二叉搜索树 ---> avl ---> 红黑树(二叉搜索树不能保证查找、插入、删除的时间复杂度为logn;avl保证了树是平衡的,避免了普通二叉搜索树在极端情况下退化为链表的问题;avl树插入和删除耗时,红黑树解决)
红黑树和avl树区别:
1、调整平衡的实现机制不同:
红黑树根据节点颜色(同一双亲节点出发到哨兵节点,所有路径上的黑色节点数目一样),一些约定和旋转实现;
AVL根据树的平衡因子(所有节点的左右子树高度差的绝对值不超过1)和旋转决定
2、红黑树的插入效率更高!!!
红黑树是用非严格的平衡来换取增删节点时候旋转次数的降低,任何不平衡都会在三次旋转之内解决,红黑树并不追求“完全平衡”,它只要求部分地达到平衡要求,降低了对旋转的要求,所以红黑树的插入删除效率更高,查找操作效率比avl低。AVL是严格平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多。
红黑树的查找、插入和删除时间复杂度都为O(log2N)
红黑树和avl应用场景:
AVL查找效率高
如果你的应用中,搜索的次数远远大于插入和删除,那么选择AVL树;如果搜索,插入删除次数几乎差不多,应选择红黑树
二叉搜索树对于某个节点而言,其左子树的节点关键值都小于该节点关键值,右子树的所有节点关键值都大于该节点关键值。二叉搜索树作为一种数据结构,其查找、插入和删除操作的时间复杂度都为O(logn),底数为2。但是我们说这个时间复杂度是在平衡的二叉搜索树上体现的,也就是如果插入的数据是随机的,则效率很高,但是如果插入的数据是有序的,比如从小到大的顺序[10,20,30,40,50]插入到二叉搜索树中:
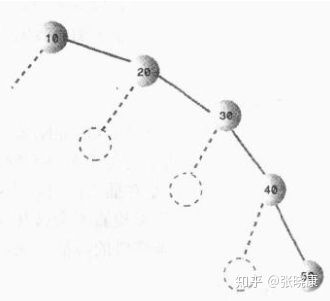
从大到小就是全部在右边,这和链表没有任何区别了,这种情况下查找的时间复杂度为O(N),而不是O(logN),当然这是在最不平衡的条件下。实际情况下,二叉搜索树的效率应该在O(N)和O(logN)之间,这取决于树的不平衡程度。
红黑树是一种特殊的二叉查找树,红黑树的每个节点上都有存储位表示节点的颜色(红黑)
红黑树特性:
- 结点是红色或黑色
- 根结点始终是黑色
- 叶子结点(NIL 结点)都是黑色
- 红色结点的两个直接孩子结点都是黑色(即从叶子到根的所有路径上不存在两个连续的红色结点)
- 从任一结点到每个叶子的所有简单路径都包含相同数目的黑色结点
这些约束的好处是:保持了树的相对平衡,同时又比AVL的插入删除操作的复杂性要低许多
自平衡策略:变色、左旋、右旋
set:集合,具有唯一性,即每个元素只出现一次,经常用于判断一个集合内元素的有无和去重。
是关联容器,set中每个元素只包含一个关键字。set支持高效的关键字查询操作:检查一个给定的关键字是否在set中。set也是以红黑树的结构实现,支持高效插入、删除等操作。
set的key与value是相同的!!!
特性:1.唯一性
2.根据元素的值自动进行排序,默认从小到大
3.不能直接改变元素值,因为那样会打乱原本正确的顺序,要改变元素值必须先删除旧元素,则插入新元素
4.不提供直接存取元素的任何操作函数,只能通过迭代器进行间接存取,而且从迭代器角度来看,元素值是常数
5.set.find(x):在 set 中查找值为 x 的元素,并返回指向该元素的迭代器,若不存在,返回 set.end()
set通过compare函数判断两个元素是否相等,同时利用set内部默认的compare函数,可以将整数从小到大排序,将字符串按字母序进行排序。
可以通过定义结构体(或类),并在其中重载()运算符,来自定义排序函数。然后,在定义set的时候,将结构体加入其中例如如下代码中的set<int, intComp>和set<string, strComp >。示例:
#include <iostream>
#include <string>
#include <set>
using namespace std; struct intComp {
bool operator() (const int& lhs, const int& rhs) const{
return lhs > rhs;
}
}; struct strComp
{
bool operator() (const string& str1, const string& str2) const {
return str1.length() < str2.length();
}
}; int main() {
int a[] = {, , , , };
set<int, intComp> s1(a, a + );
for (auto it = s1.cbegin(); it != s1.cend(); it++)
{
cout << *it << " ";
}
cout << endl; string b[] = {"apple", "banana", "pear", "orange", "strawberry"};
set<string, strComp > s2(b, b + );
for (auto it = s2.cbegin(); it != s2.cend(); it++)
{
cout << *it << " ";
}
cout << endl;
system("pause");
return ;
}
1.为何map和set的插入删除效率比用其他序列容器高?
因为对于关联容器来说,不需要做内存拷贝和内存移动。插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了;删除的时候,稍做变换后把指向删除节点的指针指向其他节点。这里的一切操作就是指针换来换去,和内存移动没有关系。
2.set底层实现:红黑树
3.为什么用红黑? 红黑树能提供set所需的排序功能,且查找速度快 。
4.set的底层实现为什么不用hash?首先set,不像map那样是key-value对,它的key与value是相同的。关于set有两种说法,第一个是STL中的set,用的是红黑树;第二个是hash_set,底层用得是hash table。红黑树与hash table最大的不同是,红黑树是有序结构,而hash table不是。但不是说set就不能用hash,如果只是判断set中的元素是否存在,那么hash显然更合适,因为set 的访问操作时间复杂度是log(N)的,而使用hash底层实现的hash_set是近似O(1)的。然而,set应该更加被强调理解为“集合”,而集合所涉及的操作并、交、差等,即STL提供的如交集set_intersection()、并集set_union()、差集set_difference()和对称差集set_symmetric_difference(),都需要进行大量的比较工作,那么使用底层是有序结构的红黑树就十分恰当了,这也是其相对hash结构的优势所在。
multiset:
set和multiset会根据特定的排序原则将元素排序。两者不同之处在于,multisets允许元素重复,而set不允许重复。两者的底层实现都是红黑树,它们支持的函数基本相同
map:字典,关联容器,以唯一键值对的形式进行存储(即关键字-值,key-value),关键字起到索引的作用,方便进行查找,key 和 value可以是任意你需要的类型
map的建立:map<int, string> t;
底层实现:红黑树,查找插入删除等操作时间复杂度都为O(logn)
特点:1.唯一键,唯一键的键值对
2.有序。自动排序,且是自动按key升序排序。这个排序函数和set一样可以重载,自己定义。
具体操作:
a.查找:
在map中,由key查找value时,首先要判断map中是否包含key。如果不检查且map不包含key,使用下标有一个危险的副作用,会在map中插入一个key的元素,value取默认值,返回value。也就是说,map[key]不可能返回null。
b.是否包含key:
两种方式,m.count(key)、m.find(key)。
m.count(key):为0不包含,m.count(key)为1包含;
m.find(key):返回迭代器,返回null不存在( iter!=m.end() ),返回key存在
c.删除:
https://www.cnblogs.com/blueoverflow/p/4923523.html#_label0
注意删除会导致被删除的节点的迭代器失效
https://www.cnblogs.com/nzbbody/p/3409298.html
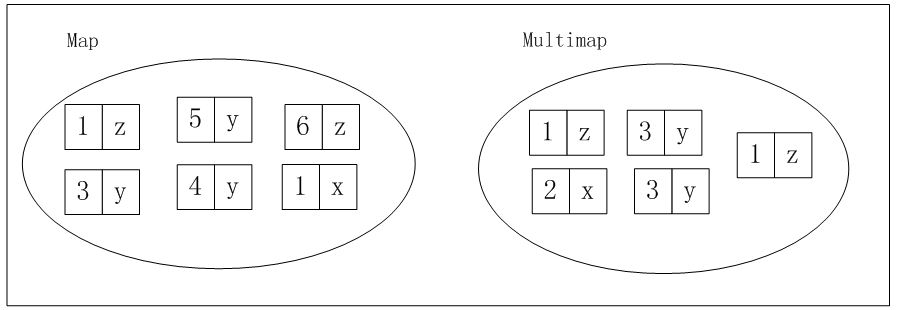
multimap:
与map的区别,允许重复键,如下图
迭代器失效:
set、map区别:
map的节点是一对数据,key-value
set的节点是一个数据
哈希表:也叫散列表,也叫hashtable,主要作用在于高效查找。在编程实现中,常常面临着两个问题:存储和查找,存储和查找的效率往往决定了整个程序的效率。
背景:先说说存储结构,实际上在我们学过的数据结构可以归结为两类:连续的的存储结构和不联系的存储结构,其代表分别为数组和链表。而我们学过的堆栈,队列,树,图,都可以用这两种结构来实现。连续的存储结构——数组,在数据的查找和修改上具有很好的优点,很方便,时间复杂度很小。但是在数据的增添和删除上则显得很麻烦,空间复杂度很大。而非连续,非顺序的存储结构——链表恰和数组相反,数据的增添和删除容易,空间复杂度很小,查找和修改复杂,时间复杂度很大。那么有没有一种数据结构能折衷一下数组和
链表的优缺点呢?那就是——哈希表,既满足了数据的查找和修改很容易,同时又不占用很多空间的特点。
总结:
数组的特点是:寻址容易,插入和删除困难;
链表的特点是:寻址困难,插入和删除容易。
哈希表简单来说可以看作是是对数组的升级,(也有不少人认为哈希表的本质就是数组),那么哈希表和数组的具体联系和区别在哪里呢?
我们在利用数组存储数据的时候,记录在数组中的位置是随机的,位置和记录的关键字之间不存在确定的关系。
联系:哈希表是由数组实现的。
区别:数组中存储的元素的和数组下标没有确定的关系,而哈希表中存储的元素和数组的下标有一个确定的关系。
定义:哈希表是根据关键码值(Key value)去寻找值的数据结构。建立关键字k和元素的存储位置p之间建立一个对应关系f,即p=f(k),这里的对应关系f称为哈希函数(散列函数)。采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。创建哈希表时,关键字为k通过哈希函数,计算出对应的函数值(哈希地址),以这个值作为数据元素的地址,并将数据元素存入到相应地址的存储单元中;查找关键字为k的元素时,再利用哈希函数计算出该元素的存储位置p=f(k),然后直接到相应的存储单元中去取要找的数据元素即可。
时间复杂度:O(1)
哈希表构造:1.直接地址法:H(Key) = a * Key + b;这个“a,b”是常量。
2.除留余数法:H(Key) = key % p (p ≤ m)
取关键字除以p的余数作为哈希地址,p最好选择一个小于或等于m(哈希地址集合的个数)的某个最大素数
3.数字分析法
4.平方取中法
冲突解决:
冲突:不同的数据元素的哈希值相同,或者说由关键字得到的哈希地址上已经有记录存在
解决办法:
还可以用再散列,散列一次之后的值再继续散列
1.开放地址法:
a.线性探测法。这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表,若整个空间都找遍仍然找不到空余的地址,产生溢出。
b.二次探测法。冲突发生时,在表的左右进行跳跃式探测
2.链地址法:将哈希值相同的数据元素存放在一个链表中,在查找哈希表的过程中,当查找到这个链表时,必须采用线性查找方法。
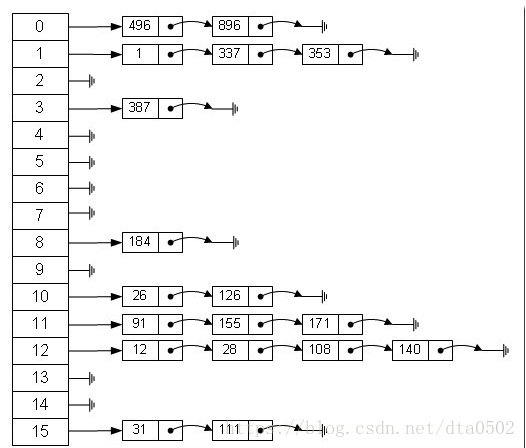
hashtable是可能存在冲突的(多个key通过计算映射到同一个位置),在同一个位置的元素会按顺序链在后面。所以把这个位置称为一个bucket是十分形象的(像桶子一样,可以装多个元素)
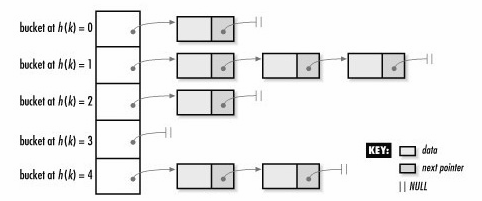
所以unordered_map内部其实是由很多哈希桶组成的,每个哈希桶中可能没有元素,也可能有多个元素。
hashset:
1.hashset的元素不会排序,set的元素会排序,因为hashset使用哈希表实现,set使用红黑树实现
2.hash_set的使用方式,与set完全相同
3.依旧保证了set的唯一性,因为是一个集合
4.哈希表是键值,set只有一个关键字,hashset的键值就是元素本身。
5.set用哈希表来实现,个人觉得是为了高效检索
hashmap:
1.hashmap无序,map按key值排序,因为hashmap使用哈希表实现,map使用红黑树实现
2.hash_map的使用方式,与map差不多
3.hashmap,键就是键,值就是值
4.hashmap数据存储、查找速度比map快。询时间复杂度是O(1)
注意我的前提:“在不碰撞的情况下”,其实换句话说,就是要有足够好的hash函数,它要能使key到value的映射足够均匀,否则,在最坏的情况下,它的计算量就退化到O(N)级,变成和链表一样。
unordered_map: C++11推出unordered_map,用途比原来的hashmap要广,因为不单只支持一些简单的类型了。
特点:1.key-value,键唯一,键和映射值的类型可能不同
2.无序,底层由哈希表实现,时间复杂度0(1)
3.unordered_map要求传入的数据能够进行大小比较,“==”关系比较,可能需要重载operator==,但是很多系统内置的数据类型都自带这些
与map区别:1.map有序,底层由红黑树实现;unordered_map无序,底层由哈希表实现
2.map查找、插入、删除时间复杂度都是O(logn),unordered_map查找时间复杂度0(1)
map空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
unordered_map的初始化比较耗时,红黑树初始化时,节点只需要一个,后续的插入只是插入新的节点;哈希表初始化时需要申请一个数组,数组的每个元素都指向一条链表,所以初始化时需要申请很多内存,相比于map,的确更耗时
list:列表
序列式容器。实际上,list容器就是一个双向链表,可以高效地进行插入删除元素,但不能提供随机访问功能。当删除其中一个元素,指向其他元素的迭代器依然有效。对于任何位置的元素插入或移除,list永远是常数时间
函数:
push_back()和push_front():使用list的成员函数push_back和push_front插入一个元素到list中。其中push_back()是从list的末端插入,而push_front()是从list的头部插入。
resize():调用resize(n)将list的长度改为只容纳n个元素,超出的元素将被删除。如果n比list原来的长度长,那么默认超出的部分元素置为0。也可以用resize(n, m)的方式
将超出的部分赋值为m。
list<int>b{, , , };
b.resize();
list中输出元素:,
b.resize();
list中输出元素:,,,,,
b.resize(,);
list中输出元素:,,,,,
list与vector区别:
List封装了链表,Vector封装了数组
1.vector是一段连续的内存空间,并且起始地址不变,因此能高效的进行随机存取,时间复杂度为o(1);list是由双向链表实现的,因此内存空间是不连续的,只能通过指针访问数据,所以list的随机存取非常没有效率,时间复杂度为o(n);
2.vector在进行插入和删除操作时,当向vector插入或者删除一个元素时,需要复制移动待插入元素右边的所有元素,时间复杂度为o(n);list因为不用考虑内存的连续,能高效地进行插入和删除。当数值内存不够时,vector会重新申请一块足够大的连续内存,把原来的数据拷贝到新的内存里面;list因为不用考虑内存的连续,因此新增开销比vector小
3.迭代器不同:vector中,iterator支持 ”+“、”+=“,”<"等操作,而list中则不支持
4.vector不能在头进行push和pop,list可以
deque是在功能上合并了vector和list,支持随机存取
应用:1. 如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector
2. 如果你需要大量的插入和删除,而不关心随即存取,则应使用list
3. 如果你需要随即存取,而且关心两端数据的插入和删除,则应使用deque
stl vector、红黑树、set、multiset、map、multimap、迭代器失效、哈希表(hash_table)、hashset、hashmap、unordered_map、list的更多相关文章
- STL vector+sort排序和multiset/multimap排序比较
由 www.169it.com 搜集整理 在C++的STL库中,要实现排序可以通过将所有元素保存到vector中,然后通过sort算法来排序,也可以通过multimap实现在插入元素的时候进行排序.在 ...
- STL set multiset map multimap unordered_set unordered_map example
I decide to write to my blogs in English. When I meet something hard to depict, I'll add some Chines ...
- stuff about set multiset map multimap
A lot of interviewers like to ask the candidates the difference between set and multiset(map and mul ...
- iBinary C++STL模板库关联容器之map/multimap
目录 一丶关联容器map/multimap 容器 二丶代码例子 1.map的三种插入数据的方法 3.map集合的遍历 4.验证map集合数据是否插入成功 5.map数据的查找 6.Map集合删除元素以 ...
- STL Vector使用
http://blog.163.com/zhoumhan_0351/blog/static/399542272010225104536463 Vector 像一个快速的数组,其具有数组的快速索引方式. ...
- 阿里面试题:为什么Map桶中个数超过8才转为红黑树
(为什么一个是8一个是6:防止频繁来回转换小消耗性能) 这是笔者面试阿里时,被问及的一个问题,应该不少人看到这个问题都会一面懵逼.因为,大部分的文章都是分析链表是怎么转换成红黑树的,但是并没有说明为什 ...
- SGI STL红黑树中迭代器的边界值分析
前言 一段程序最容易出错的就是在判断或者是情况分类的边界地方,所以,应该对于许多判断或者是情况分类的边界要格外的注意.下面,就分析下STL中红黑树的迭代器的各种边界情况.(注意:分析中STL使用的版本 ...
- 为什么Map桶中个数超过8才转为红黑树
这是笔者一个好友面试阿里时,被问及的一个问题,应该不少人看到这个问题都会一面懵逼.因为,大部分的文章都是分析链表是怎么转换成红黑树的,但是并没有说明为什么当链表长度为8的时候才做转换动作.笔者第一反应 ...
- AVL树与红黑树(R-B树)的区别与联系
AVL树(http://baike.baidu.com/view/593144.htm?fr=aladdin),又称(严格)高度平衡的二叉搜索树.其他的平衡树还有:红黑树.Treap.伸展树.SBT. ...
随机推荐
- Java - “JUC”锁
[Java并发编程实战]-----“J.U.C”:锁,lock 在java中有两种方法实现锁机制,一种是在前一篇博客中([java7并发编程实战]-----线程同步机制:synchronized) ...
- Unix环境高级编程:fork, vfork, clone
fork fork产生的子进程是传统意义上的进程,fork之后执行路径就互不关联了,一旦fork返回后面的代码就在不用的进程上下文中执行了.到底是子进程先执行还是父进程先执行一般是随机的或者依赖实现的 ...
- linux上SVN服务器搭建后windows无法连接到服务器
忙了一天,linux搭建svn服务器,搭建好后windows一直无法连接,总觉得自己对: 原因: 1.以后禁止用sublime在本地编辑好后用XFTP上传到服务器(这样会导致文件权限问题,不能替换成功 ...
- js-函数柯里化
内容来自曾探,<JavaScript设计模式与开发实践>,P49 函数柯里化(function currying)又称部分求值.一个currying的函数首先会接受一些参数,接受了这些参数 ...
- Maven学习(四)eclipse创建maven项目
eclipse创建Maven web项目 1.创建新项目 选择File -> New ->Project 选择New Project窗口中选择 Maven -> Maven Proj ...
- ES6 箭头函数下的this指向
在javscript中,this 是在函数运行时自动生成的一个内部指针,它指向函数的调用者. 箭头函数有些不同,它的this是继承而来, 默认指向在定义它时所处的对象(宿主对象),而不是执行时的对象. ...
- 在Android Studio中调用so中的方法
本节用的so是上节用Android Studio创建的so.想在Android Studio中调用so中的方法,需要先引用so.Android Studio中引用so的方法有二种,下面开始介绍. 一 ...
- Node.js+Ajax实现物流小工具
半年过去了,好像什么也没干,好像什么也干了. 最近在网易云课堂上看到了这个课程,觉得很有意思,就跟着课程做了一遍,课程地址:http://study.163.com/course/courseMain ...
- HDFS Lease Recovey 和 Block Recovery
这篇分析一下Lease Recovery 和 Block Recovery hdfs支持hflush后,需要保证hflush的数据被读到,datanode重启不能简单的丢弃文件的最后一个block,而 ...
- Percona Xtradb Cluster的设计与实现
Percona Xtradb Cluster的设计与实现 Percona Xtradb Cluster的实现是在原mysql代码上通过Galera包将不同的mysql实例连接起来,实现了multi ...