Celery -- 分布式任务队列 及实例
Celery 使用场景及实例
- Celery介绍和基本使用
- 在项目中如何使用celery
- 启用多个workers
- Celery 定时任务
- 与django结合
- 通过django配置celery periodic task
一、Celery介绍和基本使用
Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery, 举几个实例场景中可用的例子:
- 你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情。
- 你想做一个定时任务,比如每天检测一下你们所有客户的资料,如果发现今天 是客户的生日,就给他发个短信祝福
Celery 在执行任务时需要通过一个消息中间件来接收和发送任务消息,以及存储任务结果, 一般使用rabbitMQ or Redis,后面会讲
1.1 Celery有以下优点:
- 简单:一单熟悉了celery的工作流程后,配置和使用还是比较简单的
- 高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
- 快速:一个单进程的celery每分钟可处理上百万个任务
- 灵活: 几乎celery的各个组件都可以被扩展及自定制
Celery基本工作流程图:

1.2 Celery安装使用
Celery的默认broker是RabbitMQ, 仅需配置一行就可以
broker_url = 'amqp://guest:guest@localhost:5672//'rabbitMQ 没装的话请装一下,安装看这里 http://docs.celeryproject.org/en/latest/getting-started/brokers/rabbitmq.html#id3
使用Redis做broker也可以
安装redis组件
$ pip install -U "celery[redis]"配置
Configuration is easy, just configure the location of your Redis database:
app.conf.broker_url = 'redis://localhost:6379/0'
Where the URL is in the format of:
redis://:password@hostname:port/db_number
all fields after the scheme are optional, and will default to localhost on port 6379, using database 0.
如果想获取每个任务的执行结果,还需要配置一下把任务结果存在哪
If you also want to store the state and return values of tasks in Redis, you should configure these settings:
app.conf.result_backend = 'redis://localhost:6379/0'
1. 3 开始使用Celery啦
安装celery模块
$ pip install celery创建一个celery application 用来定义你的任务列表
创建一个任务文件就叫task.py !!!
from celery import Celery
import subprocess
# 注意 下方的 ‘tasks’ 可以是任意名称 并不是必须保持任务脚本名一样
app = Celery('tasks',
broker='redis://192.168.14.234',
backend='redis://192.168.14.234')
@app.task
def add(x, y):
print("running...", x, y)
return x + y
@app.task
def run_cmd(cmd):
cmd_obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)启动Celery Worker来开始监听并执行任务
$ celery -A task worker --loglevel=info注意:这里的 ‘task’要和你的任务文件名一致!!!
操作的时候,如果需要重启worker 可以按两次Ctrl+C。
调用任务
再打开一个终端, 进行命令行模式,调用任务
>>> from tasks import add
>>> add.delay(4, 4)看你的worker终端会显示收到 一个任务,此时你想看任务结果的话,需要在调用 任务时 赋值个变量
>>> result = add.delay(4, 4)The ready() method returns whether the task has finished processing or not:
用来检测任务结果是否实行完毕,即任务执行结果是否准备好。
>>> result.ready()
FalseYou can wait for the result to complete, but this is rarely used since it turns the asynchronous call into a synchronous one:
# get参数可以设置超时时间,如下,如果设置为1,则表示1秒之内没有收到结果,就会报接收超时。
>>> result.get(timeout=1)
8In case the task raised an exception, get() will re-raise the exception, but you can override this by specifying the propagate argument:
# propagate=False 默认值为True,设置为False作用:可以对异常信息进行格式化输出。
>>> result.get(propagate=False)If the task raised an exception you can also gain access to the original traceback:
# traceback用于追踪错误信息,用于调试的时候,定位错误信息位置。
>>> result.traceback上述实例练习截图:(调用’df -h’命令 查看磁盘空间)
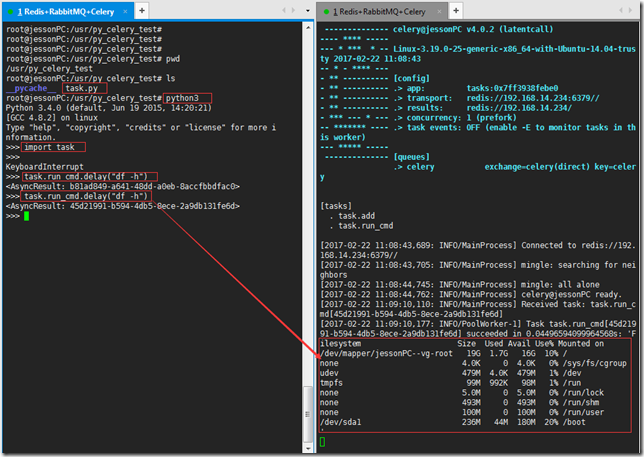
二、在项目中如何使用celery
可以把celery配置成一个应用,实现配置文件和任务文件的分离。
目录格式如下:
proj/__init__.py
/celery.py
/tasks.pyproj/celery.py内容
下方的broker 和 backend 设置,根据自己的环境写,可以用RabbitMQ,amqp,Redis等;
broker='amqp://',
backend='amqp://',
from __future__ import absolute_import, unicode_literals
from celery import Celery
app = Celery('proj',
broker='amqp://',
backend='amqp://',
include=['proj.tasks'])
# Optional configuration, see the application user guide.
app.conf.update(
result_expires=3600,
)
if __name__ == '__main__':
app.start()proj/tasks.py中的内容
from __future__ import absolute_import, unicode_literals
from .celery import app
@app.task
def add(x, y):
return x + y
@app.task
def mul(x, y):
return x * y
@app.task
def xsum(numbers):
return sum(numbers)启动worker (注意:这里启动的任务名称,要用项目名:proj,而不是上边的单独任务文件名!!!)
$ celery -A proj worker -l info输出:
-------------- celery@jessonPC v4.0.2 (latentcall)
---- **** -----
--- * *** * -- Linux-3.19.0-25-generic-x86_64-with-Ubuntu-14.04-trusty 2017-02-22 12:55:17
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: proj:0x7fb1183dbdd8
- ** ---------- .> transport: redis://192.168.14.234:6379//
- ** ---------- .> results: redis://192.168.14.234/
- *** --- * --- .> concurrency: 1 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery后台启动worker
In the background
In production you’ll want to run the worker in the background, this is described in detail in the daemonization tutorial.
The daemonization scripts uses the celery multi command to start one or more workers in the background:
# 开启后台多个任务进程
$ celery multi start w1 -A proj -l info
celery multi v4.0.0 (latentcall)
> Starting nodes...
> w1.halcyon.local: OKYou can restart it too:
# restart 重启相关的任务进程
$ celery multi restart w1 -A proj -l info
celery multi v4.0.0 (latentcall)
> Stopping nodes...
> w1.halcyon.local: TERM -> 64024
> Waiting for 1 node.....
> w1.halcyon.local: OK
> Restarting node w1.halcyon.local: OK
celery multi v4.0.0 (latentcall)
> Stopping nodes...
> w1.halcyon.local: TERM -> 64052or stop it: # stop终止相关的任务进程
$ celery multi stop w1 # 后边的参数可以省略 -A proj -l infoThe stop command is asynchronous so it won’t wait for the worker to shutdown. You’ll probably want to use the stopwait command instead, this ensures all currently executing tasks is completed before exiting:
$ celery multi stopwait w1 -A proj -l info三、Celery 定时任务
celery支持定时任务,设定好任务的执行时间,celery就会定时自动帮你执行, 这个定时任务模块叫celery beat。
写一个脚本:periodic_task.py
from celery import Celery
from celery.schedules import crontab
app = Celery()
@app.on_after_configure.connect
def setup_periodic_tasks(sender, **kwargs):
# Calls test('hello') every 10 seconds.
sender.add_periodic_task(10.0, test.s('hello'), name='add every 10')
# Calls test('world') every 30 seconds
sender.add_periodic_task(30.0, test.s('world'), expires=10)
# Executes every Monday morning at 7:30 a.m.
sender.add_periodic_task(
crontab(hour=7, minute=30, day_of_week=1),
test.s('Happy Mondays!'),
)
@app.task
def test(arg):
print(arg)add_periodic_task 会添加一条定时任务
上面是通过调用函数添加定时任务,也可以像写配置文件 一样的形式添加, 下面是每30s执行的任务。
app.conf.beat_schedule = {
'add-every-30-seconds': {
'task': 'tasks.add',
'schedule': 30.0,
'args': (16, 16)
},
}
app.conf.timezone = 'UTC'任务添加好了,需要让celery单独启动一个进程来定时发起这些任务, 注意, 这里是发起任务,不是执行,这个进程只会不断的去检查你的任务计划, 每发现有任务需要执行了,就发起一个任务调用消息,交给celery worker去执行。
启动任务调度器 celery beat
$ celery -A periodic_task beat输出like below
celery beat v4.0.2 (latentcall) is starting.
__ - ... __ - _
LocalTime -> 2017-02-08 18:39:31
Configuration ->
. broker -> redis://localhost:6379//
. loader -> celery.loaders.app.AppLoader
. scheduler -> celery.beat.PersistentScheduler
. db -> celerybeat-schedule
. logfile -> [stderr]@%WARNING
. maxinterval -> 5.00 minutes (300s)此时还差一步,就是还需要启动一个worker,负责执行celery beat发起的任务。
启动celery worker来执行任务
$ celery -A periodic_task worker
-------------- celery@Alexs-MacBook-Pro.local v4.0.2 (latentcall)
---- **** -----
--- * *** * -- Darwin-15.6.0-x86_64-i386-64bit 2017-02-08 18:42:08
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x104d420b8
- ** ---------- .> transport: redis://localhost:6379//
- ** ---------- .> results: redis://localhost/
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celeryOK,此时观察worker的输出,是不是每隔一小会,就会执行一次定时任务呢!
注意:Beat needs to store the last run times of the tasks in a local database file (named celerybeat-schedule by default), so it needs access to write in the current directory, or alternatively you can specify a custom location for this file:
$ celery -A periodic_task beat -s /home/celery/var/run/celerybeat-schedule更复杂的定时配置
上面的定时任务比较简单,只是每多少s执行一个任务,但如果你想要每周一三五的早上8点给你发邮件怎么办呢?哈,其实也简单,用crontab功能,跟linux自带的crontab功能是一样的,可以个性化定制任务执行时间:
linux crontab http://www.cnblogs.com/peida/archive/2013/01/08/2850483.html
from celery.schedules import crontab
app.conf.beat_schedule = {
# Executes every Monday morning at 7:30 a.m.
'add-every-monday-morning': {
'task': 'tasks.add',
'schedule': crontab(hour=7, minute=30, day_of_week=1),
'args': (16, 16),
},
}上面的这条意思是每周1的早上7.30执行tasks.add任务
还有更多定时配置方式如下:
| Example | Meaning |
crontab() |
Execute every minute. |
crontab(minute=0, hour=0) |
Execute daily at midnight. |
crontab(minute=0, hour='*/3') |
Execute every three hours: midnight, 3am, 6am, 9am, noon, 3pm, 6pm, 9pm. |
|
Same as previous. |
crontab(minute='*/15') |
Execute every 15 minutes. |
crontab(day_of_week='sunday') |
Execute every minute (!) at Sundays. |
|
Same as previous. |
|
Execute every ten minutes, but only between 3-4 am, 5-6 pm, and 10-11 pm on Thursdays or Fridays. |
crontab(minute=0,hour='*/2,*/3') |
Execute every even hour, and every hour divisible by three. This means: at every hour except: 1am, 5am, 7am, 11am, 1pm, 5pm, 7pm, 11pm |
crontab(minute=0, hour='*/5') |
Execute hour divisible by 5. This means that it is triggered at 3pm, not 5pm (since 3pm equals the 24-hour clock value of “15”, which is divisible by 5). |
crontab(minute=0, hour='*/3,8-17') |
Execute every hour divisible by 3, and every hour during office hours (8am-5pm). |
crontab(0, 0,day_of_month='2') |
Execute on the second day of every month. |
|
Execute on every even numbered day. |
|
Execute on the first and third weeks of the month. |
|
Execute on the eleventh of May every year. |
|
Execute on the first month of every quarter. |
上面能满足你绝大多数定时任务需求了,甚至还能根据潮起潮落来配置定时任务, 具体看 http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html#solar-schedules
四、最佳实践之与django结合
django 可以轻松跟celery结合实现异步任务,只需简单配置即可
If you have a modern Django project layout like:
- proj/
- proj/__init__.py
- proj/settings.py
- proj/urls.py
- manage.py
django + celery 配置注意事项
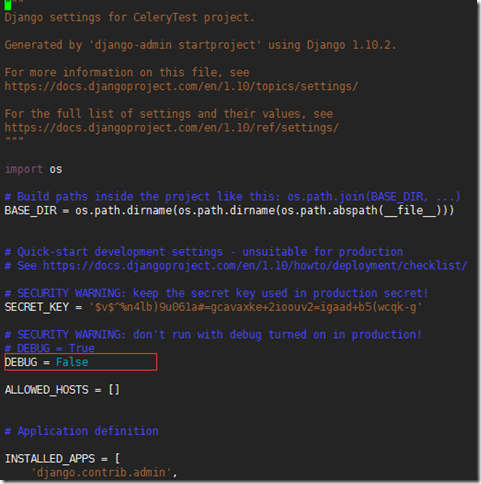
说生产环境中不建议 django项目的settings文件开启debug模式,因为这样可能会导致服务器内存泄露。
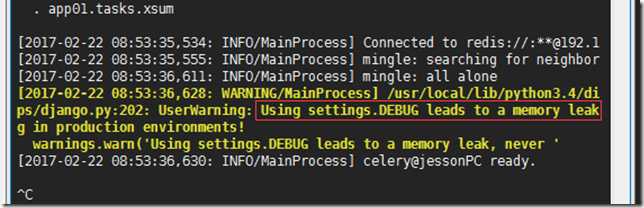
修改建议:将django settings中的DEBUG参数设置为False
Celery -- 分布式任务队列 及实例的更多相关文章
- Celery 分布式任务队列快速入门
Celery 分布式任务队列快速入门 本节内容 Celery介绍和基本使用 在项目中如何使用celery 启用多个workers Celery 定时任务 与django结合 通过django配置cel ...
- Celery 分布式任务队列快速入门 以及在Django中动态添加定时任务
Celery 分布式任务队列快速入门 以及在Django中动态添加定时任务 转自 金角大王 http://www.cnblogs.com/alex3714/articles/6351797.html ...
- 【转】Celery 分布式任务队列快速入门
Celery 分布式任务队列快速入门 本节内容 Celery介绍和基本使用 在项目中如何使用celery 启用多个workers Celery 分布式 Celery 定时任务 与django结合 通过 ...
- day21 git & github + Celery 分布式任务队列
参考博客: git & github 快速入门http://www.cnblogs.com/alex3714/articles/5930846.html git@github.com:liyo ...
- celery --分布式任务队列
一.介绍 celery是一个基于python开发的分布式异步消息任务队列,用于处理大量消息,同时为操作提供维护此类系统所需的工具. 它是一个任务队列,专注于实时处理,同时还支持任务调度.如果你的业务场 ...
- Celery 分布式任务队列入门
一.Celery介绍和基本使用 Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery ...
- celery分布式任务队列的使用
一.Celery介绍和基本使用 Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery ...
- Celery分布式任务队列快速入门
本节内容 1. Celery介绍和基本使用 2. 项目中使用Celery 3. Celery定时任务 4. Celery与Django结合 5. Django中使用计划任务 一 Celery介绍和基 ...
- 分布式任务队列 Celery —— Task对象
转载至 JmilkFan_范桂飓:http://blog.csdn.net/jmilk 目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继 ...
随机推荐
- java equals重写
@Override public boolean equals(Object obj) { if(this == obj) { return true; ...
- hibernate添加数据报错:Could not execute JDBC batch update
报错如下图所示: 报错原因:在配置文件或注解里设置了字段关联,但数据却没有关联. 解决方法:我的错误是向一个多对多的关联表里插入数据,由于表中一个字段的数据是从另一张表里get到的,通过调试发现,从以 ...
- Oracle 导出错误 EXP-00000~EXP-00107
EXP-00000: Export terminated unsuccessfully Cause: Export encountered an Oracle error. Action: Look ...
- 利用url传多个参数
刚开始接触jsp,比较偏向于用button标签的onclick方法进行页面的跳转.但是关于页面跳转的各种问题真是叫人头大,以下记录,仅仅为自己以后查看. Qone 用url传参的时候遇到中文怎么办 编 ...
- CodeForces 235E Number Challenge (莫比乌斯反演)
题意:求,其中d(x) 表示 x 的约数个数. 析:其实是一个公式题,要知道一个结论 知道这个结论就好办了. 然后就可以解决这个问题了,优化就是记忆化gcd. 代码如下: #pragma commen ...
- mouseover和mouseout事件的相关元素
在发生mouseover和mouseout事件时,还会涉及更多的元素,这两个事件都会涉及把鼠标指针从一个元素的边界之内移动到另一个元素的边界之内.对mouseover事件而言,事件的主目标获得光标元素 ...
- kettle之时间字段默认值为空或’0000-00-00’问题
今天使用kettle从mysql导数到oracle,发现只导了7行后,数据传输就终止了,查看日志信息,报错如下: 报:Couldn't get row from result set问题. 发现从这行 ...
- Python之turtle库
在命令行下```python -m pip install turtle``` 大致有两种命令: 运动命令: forward(distance) #向前移动距离distance代表距离 backwar ...
- noip第11课资料
- CAD:计算三角形的外接圆圆心
条件:三个定点不共线