java网页数据抓取实例
在很多行业中,要对行业数据进行分类汇总,及时分析行业数据,对于公司未来的发展,有很好的参照和横向对比。所以,在实际工作,我们可能要遇到数据采集这个概念,数据采集的最终目的就是要获得数据,提取有用的数据进行数据提取和数据分类汇总。
很多人在第一次了解数据采集的时候,可能无从下手,尤其是作为一个新手,更是感觉很是茫然,所以,在这里分享一下自己的心得,希望和大家一起分享技术,如果有什么不足,还请大家指正。写出这篇目的,就是希望大家一起成长,我也相信技术之间没有高低,只有互补,只有分享,才能使彼此更加成长。
在网页数据采集的时候,我们往往要经过这几个大的步骤:
①通过URL地址读取目标网页②获得网页源码③通过网页源码抽取我们要提取的目的数据④对数据进行格式转换,获得我们需要的数据。
这是一个示意图,希望大家了解
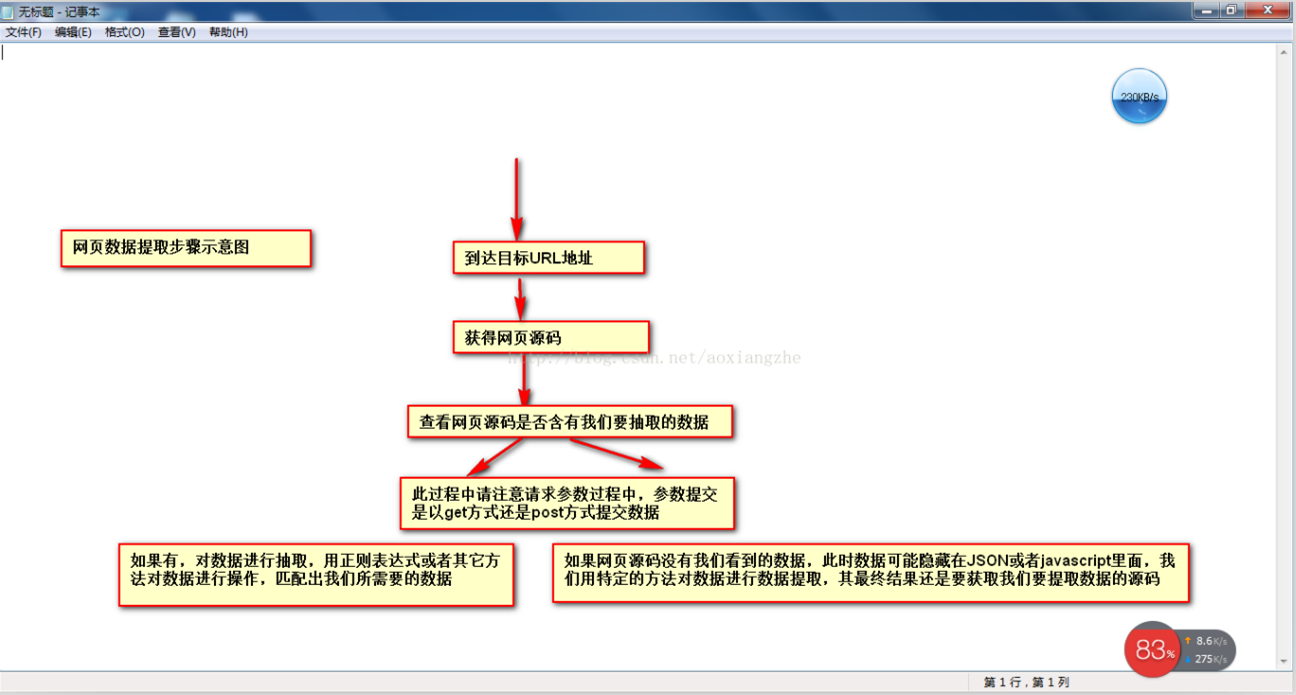
了解了基本流程,下来,我以一个案例具体实现如何提取我们需要的数据,对于数据提取可以用正则表达式进行提取,也可以用httpclient+jsoup进行提取,此处,暂且不讲解httpclient+jsou提取网页数据的做法,以后会对httpclient+jsoup进行专门的讲解,此处,先开始讲解如何用正则表达式对数据进行提取。
我在这里找到一个网站:http://www.ic.NET.cn/userSite/publicQuote/quotes_list.PHP 我们要对里面的数据进行提取操作,我们要提取的最终结果是产品的型号、数量、报价、供应商,首先,我们看到这个网站整个页面预览

其次我们看网页源码结构:
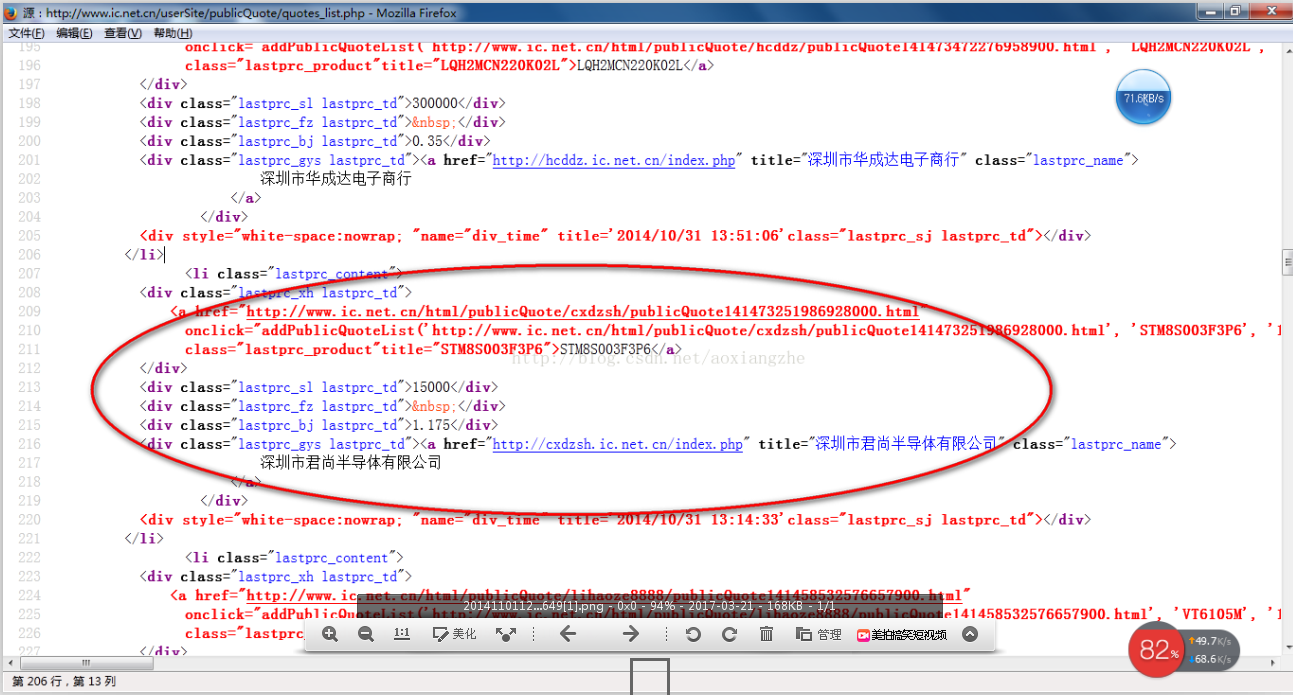
上面源码可以很清楚的可以看到整个网页源码结构,下来我们就对整个网页数据进行提取
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern; public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/publicQuote/quotes_list.php","utf-8");
}
public static List<Product> getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("</?a[^>]*>", "");
//这里是对样式进行处理
line = line.replaceAll("<(\\w+)[^>]*>", "<$1>");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("<div>(.*?)</div>\\s*<div>(.*?)</div>\\s*<div>(.*?)</div>\\s*<div>(.*?)</div>\\s*<div>(.*?)</div>", Pattern.DOTALL);
private static List<Product> getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("</li>");
List<Product> list = new ArrayList<Product>();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
} public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() { }
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
} }
好了,运行上面程序,我们得到下面的数据,就是我们要获得的最终数据

获得数据成功,这就是我们要获得最终的数据结果,最后我要说的是,此处这个网页算是比较简单的,而且,网页源码可以看到源数据,并且此方式是以get方式进行数据提交,真正采集的时候,有些网页结构比较复杂,可能会存在着源码里面没有我们所要提取的数据,关于这一点的解决方式,以后给大家进行介绍。还有,我在采集这个页面的时候,只是采集了当前页面的数据,它还有分页的数据,关于这个我此处不做讲解,只是提示一点,我们可以采用多线程对所有分页的当前数据进行采集,通过线程一个采集当前页面数据,一个进行翻页动作,就可以采集完所有数据。
我们匹配的数据可能在项目实际开发中,要求我们对所提取的数据要进行数据储存,方便我们下一次进行数据的查询操作。
java网页数据抓取实例的更多相关文章
- 爬虫---selenium动态网页数据抓取
动态网页数据抓取 什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页 ...
- 网页数据抓取工具,webscraper 最简单的数据抓取教程,人人都用得上
Web Scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据.例如知乎回答列表.微博热门.微博评论.淘宝.天猫.亚马逊等电商 ...
- Android登录client,验证码的获取,网页数据抓取与解析,HttpWatch基本使用
大家好,我是M1ko.在互联网时代的今天,假设一个App不接入互联网.那么这个App一定不会有长时间的生命周期,因此Android网络编程是每个Android开发人员必备的技能.博主是在校大学生,自学 ...
- 【Android 我的博客APP】1.抓取博客首页文章列表内容——网页数据抓取
打算做个自己在博客园的博客APP,首先要能访问首页获取数据获取首页的文章列表,第一步抓取博客首页文章列表内容的功能已实现,在小米2S上的效果图如下: 思路是:通过编写的工具类访问网页,获取页面源代码, ...
- 网页数据抓取(B/S)
C# 抓取网页内容(转) 1.抓取一般内容 需要三个类:WebRequest.WebResponse.StreamReader 所需命名空间:System.Net.System.IO 核心代码: We ...
- Web网页数据抓取(C/S)
通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析系统在根据得到的数据进行数据分析.为业务提供参考数据. 为了完成以上的需求,我们 ...
- Python爬虫之-动态网页数据抓取
什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新.这意 ...
- java 网页页面抓取标题和正文
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import ...
- Java HTML页面抓取实例
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import ...
随机推荐
- C#基础篇三流程控制2
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace P01R ...
- Linux 数据重定向
名称 描述 代码 表示 stdin 标准输入 0 < 或 << stdout 标准输出 1 > 或 >> stderr 标准错误输出 2 2> 或 2> ...
- CentOS7安装sogou输入法
centos7中自带的ibus用起来相当不爽,就决定自己换个搜狗,遇到阻力不少,在此记下,防止下次不会也给大家提供一些参考.(参见<kali下安装中文输入法>) 准备阶段: 安装fcitx ...
- PHP MYSQL登陆和模糊查询
PHP MYSQL登陆和模糊查询 PHP版本 5.5.12 MYSQL版本 5.6.17 Apache 2.4.9 用的wampserver 一.PHPMYSQL实现登陆: 一共含有两个 ...
- 深度理解C# 的执行原理
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由鹅厂优文发表于云+社区专栏 从编译原理说起 虚拟机是什么 C# 是什么,IL 又是什么 .Net Framework vs Mono ...
- java多线程总结:线程的两种创建方式及优劣比较
1.通过实现Runnable接口线程创建 (1).定义一个类实现Runnable接口,重写接口中的run()方法.在run()方法中加入具体的任务代码或处理逻辑. (2).创建Runnable接口实现 ...
- C++ STL 学习
/* algorithm-算法 */ .copy() //此函数用在vector中只做拷贝使用,它不能让vector有自动扩充作用.如果vector的容量小于它拷贝的数据量将会报错. /* itera ...
- 版本管理(二)之Git和GitHub的连接和使用
首先需要注册登录GitHub:https://github.com 然后 ①:下载Git 先从Git官网,由于我的系统是64位的所以选择64-bit Git for Windows Setup htt ...
- Spring基础(8) : 延迟加载,Bean的作用域,Bean生命周期
1.延迟加载 <bean id="p" class="com.Person" lazy-init="true"/> @Confi ...
- Nodejs+Express构建网站
1.预先安装(系统环境widows): nodejs 可在官网下载安装 https://nodejs.org/en/ visual studio code 可在官网下载安装 http://co ...