[转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
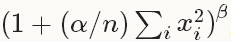 ,得到归一化后的输出
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
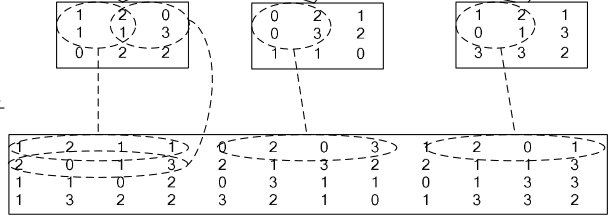
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
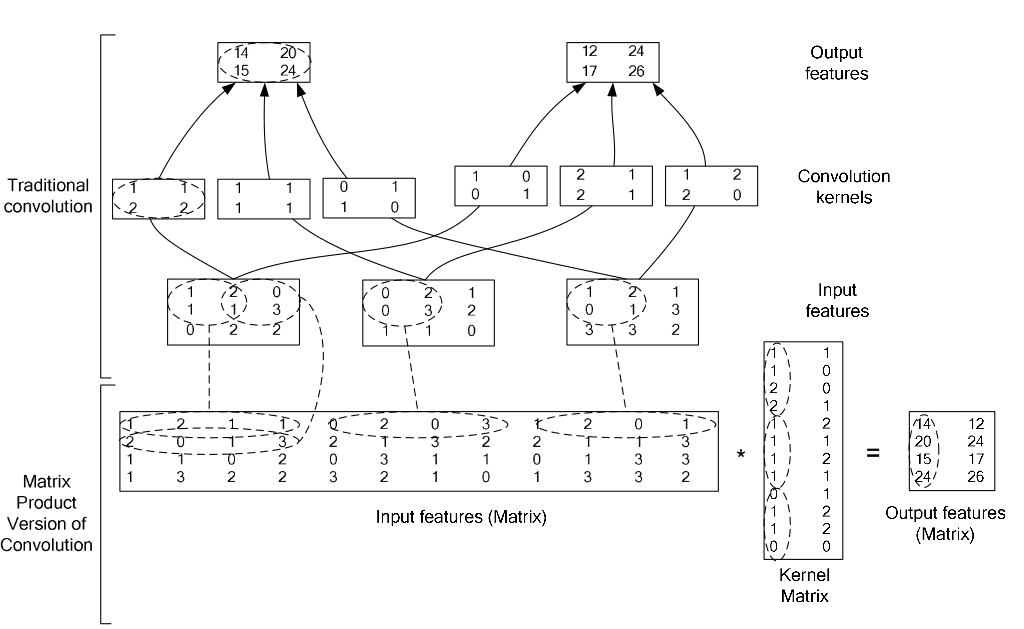
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
原文:http://www.cnblogs.com/denny402/p/5071126.html
[转] caffe视觉层Vision Layers 及参数的更多相关文章
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 【转】Caffe初试(五)视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. ...
- caffe(3) 视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN)局部相应归一化, im2 ...
- caffe学习系列(4):视觉层介绍
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 这里介绍下conv层. layer { name: & ...
- 1、Caffe数据层及参数
要运行Caffe,需要先创建一个模型(model),每个模型由许多个层(layer)组成,每个层又都有自己的参数, 而网络模型和参数配置的文件分别是:caffe.prototxt,caffe.solv ...
- caffe 每层结构
如何在Caffe中配置每一个层的结构 最近刚在电脑上装好Caffe,由于神经网络中有不同的层结构,不同类型的层又有不同的参数,所有就根据Caffe官网的说明文档做了一个简单的总结. 1. Vision ...
- Caffe 激励层(Activation)分析
Caffe_Activation 一般来说,激励层的输入输出尺寸一致,为非线性函数,完成非线性映射,从而能够拟合更为复杂的函数表达式激励层都派生于NeuronLayer: class XXXlayer ...
- Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
随机推荐
- Java之流的分类
Java I/O流分类:
- 新版 Chrome Ajax 跨域调试
一.前言 web 开发中 Ajax 是十分常见的技术,但是在前后端使用接口对接的调试过程中不可避免会碰到跨域问题.今天我给大家介绍一个十分简单有效的方法. 跨域经典错误 二.Chrome 跨域设置 首 ...
- 【bzoj3881】[Coci2015]Divljak AC自动机+树链的并+DFS序+树状数组
题目描述 Alice有n个字符串S_1,S_2...S_n,Bob有一个字符串集合T,一开始集合是空的. 接下来会发生q个操作,操作有两种形式: “1 P”,Bob往自己的集合里添加了一个字符串P. ...
- PL/SQL如何设置当前格局确保每次打开都给关闭前一样
打开plsql --> windows-->save layout 即可
- (转)远程连接webservice遇到无法访问的问题解决办法
原帖:http://stu-xu.i.sohu.com/blog/view/170429191.htm 如果在本地测试webservice可以运行,在远程却显示“测试窗体只能用于来自本地计算机的请求” ...
- POJ2125 Destroying The Graph
题目链接:ヾ(≧∇≦*)ゝ 大致题意: 给出一个有向图D=(V,E).对于每个点U,定义两种操作a(u),b(u) 操作a(u):删除点U的所有出边,即属于E,操作花费为Ca(u). 操作b(u):删 ...
- 基于Spark Mllib的文本分类
基于Spark Mllib的文本分类 文本分类是一个典型的机器学习问题,其主要目标是通过对已有语料库文本数据训练得到分类模型,进而对新文本进行类别标签的预测.这在很多领域都有现实的应用场景,如新闻网站 ...
- 【COGS1752】 BOI2007—摩基亚Mokia
http://cogs.pro/cogs/problem/problem.php?pid=1752 (题目链接) 题意 给出$n*n$的棋盘,单点修改,矩阵查询. Solution 离线以后CDQ分治 ...
- ElasticStack系列之十九 & bulk时 index 和 create 的区别
区别: 两篇文章 id 都一样的情况下,index 是将第二篇文章覆盖第一篇:create 是在第二篇插入的时候抛出一个已经存在的异常 解释: 在批量请求的时候最好使用 create 方式进行导入.假 ...
- node的path.join 和 path.resolve的区别
直接上图: join resolve 明显可以看出,join只会帮你把路径连接起来,而resolve会以当前路径为父路径来把你提供的路径连接起来