Deep learning with Python 学习笔记(5)
本节讲深度学习用于文本和序列
用于处理序列的两种基本的深度学习算法分别是循环神经网络(recurrent neural network)和一维卷积神经网络(1D convnet)
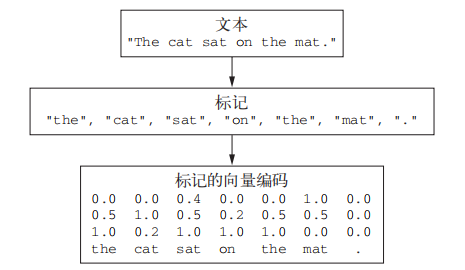
与其他所有神经网络一样,深度学习模型不会接收原始文本作为输入,它只能处理数值张量。文本向量化(vectorize)是指将文本转换为数值张量的过程。它有多种实现方法
- 将文本分割为单词,并将每个单词转换为一个向量
- 将文本分割为字符,并将每个字符转换为一个向量
- 提取单词或字符的 n-gram,并将每个 n-gram 转换为一个向量。n-gram 是多个连续单词或字符的集合(n-gram 之间可重叠)
将文本分解而成的单元(单词、字符或 n-gram)叫作标记(token),将文本分解成标记的过程叫作分词(tokenization)。所有文本向量化过程都是应用某种分词方案,然后将数值向量与生成的标记相关联。这些向量组合成序列张量,被输入到深度神经网络中
n-gram 是从一个句子中提取的 N 个(或更少)连续单词的集合。这一概念中的“单词”也可以替换为“字符”
The cat sat on the mat 分解为二元语法(2-gram)的集合
{"The", "The cat", "cat", "cat sat", "sat", "sat on", "on", "on the", "the", "the mat", "mat"}
分解为三元语法(3-gram)的集合
{"The", "The cat", "cat", "cat sat", "The cat sat",
"sat", "sat on", "on", "cat sat on", "on the", "the",
"sat on the", "the mat", "mat", "on the mat"}
这样的集合分别叫作二元语法袋(bag-of-2-grams)及三元语法袋(bag-of-3-grams)。这里袋(bag)这一术语指的是,我们处理的是标记组成的集合。这一系列分词方法叫作词袋(bag-of-words)。词袋是一种不保存顺序的分词方法,因此它往往被用于浅层的语言处理模型,而不是深度学习模型
将向量与标记相关联的方法
对标记做 one-hot 编码(one-hot encoding)与标记嵌入[token embedding,通常只用于单词,叫作词嵌入(word embedding)]
one-hot 编码是将标记转换为向量的最常用、最基本的方法
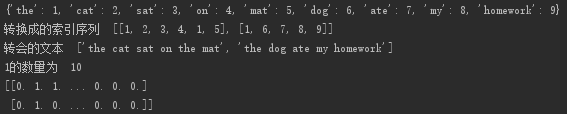
它将每个单词与一个唯一的整数索引相关联,然后将这个整数索引 i 转换为长度为 N 的二进制向量(N 是词表大小),这个向量只有第 i 个元素是 1,其余元素都为 0 (也可以进行字符级的 one-hot 编码)
Keras one-hot编码Demo
from keras.preprocessing.text import Tokenizer
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
# 只考虑前1000个最常见的单词
tokenizer = Tokenizer(num_words=1000)
# 构建单词索引
tokenizer.fit_on_texts(samples)
# 找回单词索引
word_index = tokenizer.word_index
print(word_index)
# 将字符串转换为整数索引组成的列表
sequences = tokenizer.texts_to_sequences(samples)
print("转换成的索引序列 ", sequences)
text = tokenizer.sequences_to_texts(sequences)
print("转会的文本 ", text)
# 得到 one-hot 二进制表示
one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')
one_num = 0
for items in one_hot_results:
for item in items:
if item == 1:
one_num += 1
print("1的数量为 ", one_num)
print(one_hot_results)
结果
one-hot 编码的一种变体是所谓的 one-hot 散列技巧(one-hot hashing trick),如果词表中唯
一标记的数量太大而无法直接处理,就可以使用这种技巧
将单词散列编码为固定长度的向量,通常用一个非常简单的散列函数来实现
这种方法的主要优点在于,它避免了维护一个显式的单词索引,从而节省内存并允许数据的在线编码,缺点就是可能会出现散列冲突
词嵌入
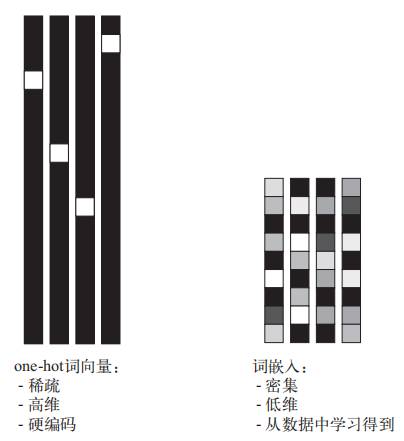
one-hot 编码得到的向量是二进制的、稀疏的、维度很高的(维度大小等于词表中的单词个数),而词嵌入是低维的浮点数向量。与 one-hot 编码得到的词向量不同,词嵌入是从数据中学习得到的。常见的词向量维度是 256、512 或 1024(处理非常大的词表时)。与此相对,onehot 编码的词向量维度通常为 20 000 或更高。因此,词向量可以将更多的信息塞入更低的维度中
获取词嵌入有两种方法
- 在完成主任务(比如文档分类或情感预测)的同时学习词嵌入。在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,其学习方式与学习神经网络的权重相同
- 在不同于待解决问题的机器学习任务上预计算好词嵌入,然后将其加载到模型中。这些词嵌入叫作预训练词嵌入(pretrained word embedding)
利用 Embedding 层学习词嵌入
词嵌入的作用应该是将人类的语言映射到几何空间中,我们希望任意两个词向量之间的几何距离)应该和这两个词的语义距离有关。可能还希望嵌入空间中的特定方向也是有意义的
Embedding 层的输入是一个二维整数张量,其形状为 (samples, sequence_length),它能够嵌入长度可变的序列,不过一批数据中的所有序列必须具有相同的长度
简单Demo
from keras.datasets import imdb
from keras import preprocessing
from keras.models import Sequential
from keras.layers import Flatten, Dense, Embedding
import matplotlib.pyplot as plt
max_features = 10000
maxlen = 20
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features, path='E:\\study\\dataset\\imdb.npz')
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
model = Sequential()
model.add(Embedding(10000, 8, input_length=maxlen))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary()
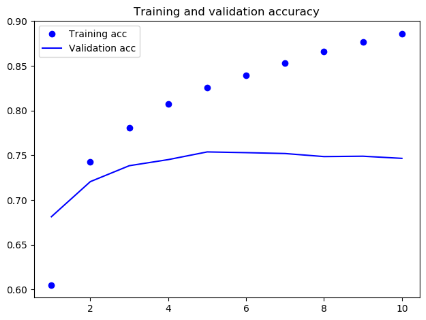
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
结果
当可用的训练数据很少,以至于只用手头数据无法学习适合特定任务的词嵌入,你可以从预计算的嵌入空间中加载嵌入向量,而不是在解决问题的同时学习词嵌入。有许多预计算的词嵌入数据库,你都可以下载并在 Keras 的 Embedding 层中使用,word2vec 就是其中之一。另一个常用的是 GloVe(global vectors for word representation,词表示全局向量)
没有足够的数据来自己学习真正强大的特征,但你需要的特征应该是非常通用的,比如常见的视觉特征或语义特征
新闻情感分类Demo,使用GloVe预训练词
import os
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
import matplotlib.pyplot as plt
imdb_dir = 'E:\\study\\dataset\\aclImdb'
train_dir = os.path.join(imdb_dir, 'train')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname))
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
# 对 IMDB 原始数据的文本进行分词
maxlen = 100
training_samples = 200
validation_samples = 10000
max_words = 10000
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.asarray(labels)
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
# 打乱数据
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + validation_samples]
# 解析 GloVe 词嵌入文件
glove_dir = 'E:\\study\\models\\glove.6B'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'))
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
# 准备 GloVe 词嵌入矩阵(max_words, embedding_dim)
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
if i < max_words:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
# 模型定义
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
# 将预训练的词嵌入加载到 Embedding 层中,并冻结
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
# 训练与评估
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
model.save_weights('pre_trained_glove_model.h5')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
# 对测试集数据进行分词
test_dir = os.path.join(imdb_dir, 'test')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(test_dir, label_type)
for fname in sorted(os.listdir(dir_name)):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname))
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
sequences = tokenizer.texts_to_sequences(texts)
x_test = pad_sequences(sequences, maxlen=maxlen)
y_test = np.asarray(labels)
# 在测试集上评估模型
model.load_weights('pre_trained_glove_model.h5')
model.evaluate(x_test, y_test)
数据下的时间太长放弃了,233
Deep learning with Python 学习笔记(6)
Deep learning with Python 学习笔记(4)
Deep learning with Python 学习笔记(5)的更多相关文章
- Deep learning with Python 学习笔记(11)
总结 机器学习(machine learning)是人工智能的一个特殊子领域,其目标是仅靠观察训练数据来自动开发程序[即模型(model)].将数据转换为程序的这个过程叫作学习(learning) 深 ...
- Deep learning with Python 学习笔记(10)
生成式深度学习 机器学习模型能够对图像.音乐和故事的统计潜在空间(latent space)进行学习,然后从这个空间中采样(sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品 ...
- Deep learning with Python 学习笔记(9)
神经网络模型的优化 使用 Keras 回调函数 使用 model.fit()或 model.fit_generator() 在一个大型数据集上启动数十轮的训练,有点类似于扔一架纸飞机,一开始给它一点推 ...
- Deep learning with Python 学习笔记(8)
Keras 函数式编程 利用 Keras 函数式 API,你可以构建类图(graph-like)模型.在不同的输入之间共享某一层,并且还可以像使用 Python 函数一样使用 Keras 模型.Ker ...
- Deep learning with Python 学习笔记(7)
介绍一维卷积神经网络 卷积神经网络能够进行卷积运算,从局部输入图块中提取特征,并能够将表示模块化,同时可以高效地利用数据.这些性质让卷积神经网络在计算机视觉领域表现优异,同样也让它对序列处理特别有效. ...
- Deep learning with Python 学习笔记(6)
本节介绍循环神经网络及其优化 循环神经网络(RNN,recurrent neural network)处理序列的方式是,遍历所有序列元素,并保存一个状态(state),其中包含与已查看内容相关的信息. ...
- Deep learning with Python 学习笔记(4)
本节讲卷积神经网络的可视化 三种方法 可视化卷积神经网络的中间输出(中间激活) 有助于理解卷积神经网络连续的层如何对输入进行变换,也有助于初步了解卷积神经网络每个过滤器的含义 可视化卷积神经网络的过滤 ...
- Deep learning with Python 学习笔记(3)
本节介绍基于Keras的使用预训练模型方法 想要将深度学习应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络.预训练网络(pretrained network)是一个保存好的网络,之前已在 ...
- Deep learning with Python 学习笔记(2)
本节介绍基于Keras的CNN 卷积神经网络接收形状为 (image_height, image_width, image_channels)的输入张量(不包括批量维度),宽度和高度两个维度的尺寸通常 ...
随机推荐
- VBA 代码
Private Declare PtrSafe Function ShellExecute Lib "shell32.dll" Alias "ShellExecuteA& ...
- FFmpeg4.0笔记:rtsp2rtmp
Github https://github.com/gongluck/FFmpeg4.0-study.git #include <iostream> using namespace std ...
- C#中类的属性的获取
/// <summary> /// 将多个实体转换成一个DataTable /// </summary> /// <typeparam name="T" ...
- Unity相机跟随-----根据速度设置偏移量
这里假设在水中的船,船有惯性,在不添加前进动力的情况下会继续移动,但是船身是可以360度自由旋转,当船的运动速度在船的前方的时候,相机会根据向前的速度的大小,设置相机的偏移量,从而提高游戏的动态带感. ...
- PowerDesigner执行脚本 name/comment/stereotype互转
执行方法:工具栏->Tools -> Execute Commands -> Edit/Run Script (Ctrl+Shift+X) 如下图所示: 1.Name转到Commen ...
- 浅谈react受控组件与非受控组件
引言 最近在使用蚂蚁金服出品的一条基于react的ant-design UI组件时遇到一个问题,编辑页面时input输入框会展示保存前的数据,但是是用defaultValue就是不起作用,输入框始终为 ...
- “全栈2019”Java多线程第三十三章:await与signal/signalAll
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- 18_python_类关系
一.类与类之间的关系 1.依赖关系 class Elephant: def __init__(self, name): self.name = name def open(self, ...
- 基本数据类型补充 set集合 深浅拷贝
一.基本数据类型补充 1,关于int和str在之前的学习中已经介绍了80%以上了,现在再补充一个字符串的基本操作: li = ['李嘉诚','何炅','海峰','刘嘉玲'] s = "_&q ...
- VS 快捷键设置
工具 --> 选项 --> 环境 --> 键盘