hadoop-1
结合其他文章
http://weixiaolu.iteye.com/blog/1504898
https://www.cnblogs.com/dycg/p/3934394.html
https://blog.csdn.net/c929833623lvcha/article/details/49052845
和自己看的,记录下
如何用?
实现 VersionedProtocol 定义方法
Server server = new RPC.Builder(conf).setProtocol(TestProtocol.class)
.setInstance(new TestProtocolImpl()).setBindAddress(ADDRESS).setPort(0)
.build();
server.start();
-----------------------------------------------------------------------------------------
TestProtocol proxy = RPC.getProxy(TestProtocol.class,TestProtocol.versionID,addr, conf);
proxy.调用定义的方法
如何实现?
Service:
先从启动看起,包含了Responder/Listener/Handler[],他们分别处理Nio过程中的不同步骤
public synchronized void start() {
responder.start();
listener.start();
handlers = new Handler[handlerCount];
for (int i = 0; i < handlerCount; i++) {
handlers[i] = new Handler(i);
handlers[i].start();
}
}
觉得别人写的不错,抄自:https://www.cnblogs.com/zhixingheyi2016/p/8781006.html
服务端使用了四组线程
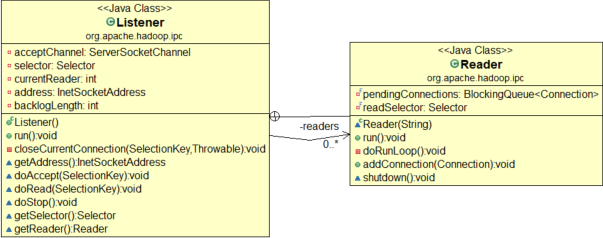
Listener:
单个线程,用于监听连接,持有selector ,然后从 Reader[]线程组内挑选一个线程接受监听好的SelectionKey
// create a selector;
selector= Selector.open();
readers = new Reader[readThreads];
for (int i = 0; i < readThreads; i++) {
Reader reader = new Reader(
"Socket Reader #" + (i + 1) + " for port " + port);
readers[i] = reader;
reader.start();
}
Reader[]:
reader 线程组负责读取连接上的读请求,并传递给 Handler线程组,每个线程持有一个readSelector
void doRead(SelectionKey key) throws InterruptedException {
int count;
Connection c = (Connection)key.attachment();
......try {
//处理读
count = c.readAndProcess();
} catch (InterruptedException ieo) {
}
private void processOneRpc(ByteBuffer bb)
throws IOException, InterruptedException {try {
......
callId = header.getCallId();
......final RpcCall call = new RpcCall(this, callId, retry);
setupResponse(call,
rse.getRpcStatusProto(), rse.getRpcErrorCodeProto(), null,
t.getClass().getName(), t.getMessage());
sendResponse(call);
}
}
Handler[]:
hander 线程组负责处理请求并返回响应,未能成功返回的响应交Responder
private class Handler extends Thread {
public Handler(int instanceNumber) {
this.setDaemon(true);
this.setName("IPC Server handler "+ instanceNumber + " on " + port);
}
@Override
public void run() {
LOG.debug(Thread.currentThread().getName() + ": starting");
SERVER.set(Server.this);
while (running) {
TraceScope traceScope = null;
try {
final Call call = callQueue.take(); // pop the queue; maybe blocked here
...
call.run();
}
}
}
}
Responder:
持有一个writeSelector,监听写事件

对于其中的Call对象 :该类封装了一个RPC请求,它主要包含唯一标识id,函数调用信息、函数执行返回值value,异常信息error和执行完成标识done。由于HadoopRPCServer采用了异步方式处理客户端请求,这使得远程过程调用的发生顺序与结果返回顺序无直接关系,而Client端正是通过id识别不同的函数调用。当客户端向服务端发送请求时,只需要填充id和param这两个变量,而剩下的三个变量:value,error,done,则由服务端根据函数执行情况填充.

对于Connection, 用于Client与每个Server之间维护一个通信连接。该连接相关的基本信息及操作被封装到Connection类中,其中基本信息主要包括:通信连接唯一标识remoteId,与Server端通信的Socket,网络输入流in,网络输出流out,保存RPC请求的哈希表calls等.
public class Connection {
private Socket socket;private LinkedList<RpcCall> responseQueue;
......
Invoker的invoke方法
val = (RpcWritable.Buffer) client.call(RPC.RpcKind.RPC_PROTOCOL_BUFFER,
new RpcProtobufRequest(rpcRequestHeader, theRequest), remoteId,
fallbackToSimpleAuth);
客户端设计
client.call
Writable call(RPC.RpcKind rpcKind, Writable rpcRequest,
ConnectionId remoteId, int serviceClass,
AtomicBoolean fallbackToSimpleAuth) throws IOException {
final Call call = createCall(rpcKind, rpcRequest);
final Connection connection = getConnection(remoteId, call, serviceClass,
fallbackToSimpleAuth); connection.sendRpcRequest(call); // send the rpc request
对于客户端和服务端的交互
Invoker :动态代理,起始就是为了在invoke中实现具体的客户端访问逻辑,实现网络调用
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
try {
value = (ObjectWritable)
client.call(RPC.RpcKind.RPC_WRITABLE, new Invocation(method, args),
remoteId, fallbackToSimpleAuth);
} finally {
if (traceScope != null) traceScope.close();
}

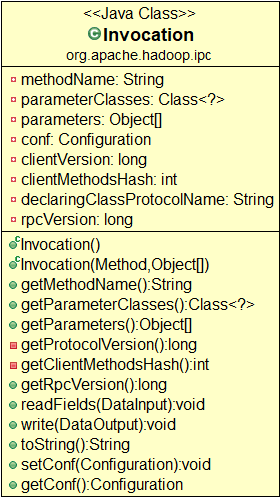
Invocation :用于封装方法名和参数,作为数据传输层
hadoop-1的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 程序员必须要知道的Hadoop的一些事实
程序员必须要知道的Hadoop的一些事实.现如今,Apache Hadoop已经无人不知无人不晓.当年雅虎搜索工程师Doug Cutting开发出这个用以创建分布式计算机环境的开源软...... 1: ...
- Hadoop 2.x 生态系统及技术架构图
一.负责收集数据的工具:Sqoop(关系型数据导入Hadoop)Flume(日志数据导入Hadoop,支持数据源广泛)Kafka(支持数据源有限,但吞吐大) 二.负责存储数据的工具:HBaseMong ...
- Hadoop的安装与设置(1)
在Ubuntu下安装与设置Hadoop的主要过程. 1. 创建Hadoop用户 创建一个用户,用户名为hadoop,在home下创建该用户的主目录,就不详细介绍了. 2. 安装Java环境 下载Lin ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
随机推荐
- 【ZZ】Linux常用指令
linux常用指令 - 个人文章 - SegmentFault 思否 https://segmentfault.com/a/1190000011068772 查看目录下有什么文件信息 ls //lis ...
- 网站首页多URL可访问,如何集中首页网站权重?
原文地址:http://ask.seowhy.com/question/8573 百度站长平台Lee在文章<建立符合搜索引擎抓取习惯>一文中提出:唯一性网站中同一内容页只与唯一一个url相 ...
- opencv mser算法框出图片文字区域
MSER(Maximally Stable Extrernal Regions)是区域检测中影响最大的算法 1. 原理 MSER基于分水岭的概念:对图像进行二值化,二值化阈值取[0, 255],这样二 ...
- docker构建tomcat镜像
下载centos镜像 # docker pull daocloud.io/centos:7 [root@localhost ~]# docker pull daocloud.io/centos: : ...
- PopupWindows 在2.3.3下报java.lang.NullPointerException
03-05 01:20:56.040: E/AndroidRuntime(1396): java.lang.NullPointerException 03-05 01:20:56.040: E/And ...
- vue 双向数据绑定 Vue事件介绍 以及Vue中的ref获取dom节点
<template> <div id="app"> <h2>{{msg}}</h2> <input type="te ...
- 第6章 静态路由和动态路由(4)_OSPF动态路由协议
6. OSPF动态路由协议 6.1 OSPF协议(Open Shortest Path First,OSPF开放式最短路径优先协议) (1)通过路由器之间通告链路的状态来建立链路状态数据库,网络中所有 ...
- System.Drawing.Graphics.FromImage(Image image)引发内存不足
原因:图片位深度导致的,c# gui 应该无法将32位jpg格式的图片load到内存中 通过对比可成功处理的图片 和 不能处理的图片,发现 CMYK(印刷格式)的图片是无法处理的,具体需要深入 .ne ...
- 百度翻译API(C#)
百度翻译开放平台:点击打开链接 1. 定义类用于保存解析json得到的结果 public class Translation { public string Src { get; set; } pub ...
- flask 之cbv ,flash闪现,Flask_Session,WTForms - MoudelForm
1.CBV : from flask import views class LoginView(views.MethodView): def get(self): return def ...